

YOLOv10が登場しました!真のリアルタイムのエンドツーエンドのターゲット検出

YOLO は、計算コストと検出パフォーマンスの効果的なバランスにより、ここ数年でリアルタイム物体検出の分野で主流のパラダイムになりました。研究者たちは、YOLO の構造設計、最適化目標、データ強化戦略などについて徹底的な調査を実施し、大きな進歩を遂げてきました。ただし、後処理が非最大抑制 (NMS) に依存しているため、YOLO のエンドツーエンド展開が妨げられ、推論レイテンシーに悪影響を及ぼします。さらに、YOLO のさまざまなコンポーネントの設計には包括的かつ徹底的なレビューが欠けており、その結果、大幅な計算冗長性が生じ、モデルのパフォーマンスが制限されます。その結果、効率が最適化されず、パフォーマンスが向上する可能性が非常に大きくなります。この作業では、後処理とモデル アーキテクチャの両方から YOLO のパフォーマンスと効率の境界をさらに前進させることを目指しています。この目的を達成するために、私たちはまず、YOLO の NMS フリー トレーニングのための永続的なデュアル割り当てを提案します。これにより、競争力のあるパフォーマンスとより低い推論レイテンシーが同時に実現されます。さらに、YOLO 向けの包括的な効率と精度を重視したモデル設計戦略を紹介します。効率と精度の観点から YOLO の各コンポーネントを包括的に最適化し、計算オーバーヘッドを大幅に削減し、モデルの機能を強化しました。私たちの努力の結果、リアルタイムのエンドツーエンドの物体検出用に設計された、YOLOv10 と呼ばれる新世代の YOLO シリーズが誕生しました。広範な実験により、YOLOv10 がさまざまなモデル スケールで最先端のパフォーマンスと効率を達成することが示されています。たとえば、COCO データセットでは、YOLOv10-S は同様の AP の下で RT-DETR-R18 よりも 1.8 倍高速ですが、パラメーターと浮動小数点演算 (FLOP) は 2.8 倍削減されます。 YOLOv9-C と比較して、YOLOv10-B は同じパフォーマンスでレイテンシを 46% 削減し、パラメータを 25% 削減します。コードリンク: https://github.com/THU-MIG/yolov10。
YOLOv10 にはどのような改善点がありますか?
まず、NMS フリーの YOLO に対する永続的なデュアル割り当て戦略を提案することで、後処理における冗長予測の問題に対処します。この戦略には、二重ラベルの割り当てと一貫したマッチング メトリックが含まれます。これにより、モデルはトレーニング中に充実した調和のとれた監視を得ることができると同時に、推論中に NMS の必要性がなくなり、高効率を維持しながら競争力のあるパフォーマンスを達成できます。
今回は、包括的な効率と精度を重視したモデル設計戦略がモデル アーキテクチャに対して提案され、YOLO の各コンポーネントが包括的に検討されます。効率の観点からは、明らかな計算の冗長性を削減し、より効率的なアーキテクチャを実現するために、軽量分類ヘッド、空間チャネル分離ダウンサンプリング、およびランクガイド型ブロック設計が提案されています。
精度の面では、大規模なカーネル畳み込みが調査され、モデルの機能を強化し、低コストでパフォーマンス向上の可能性を引き出す効果的な部分セルフアテンション モジュールが提案されています。
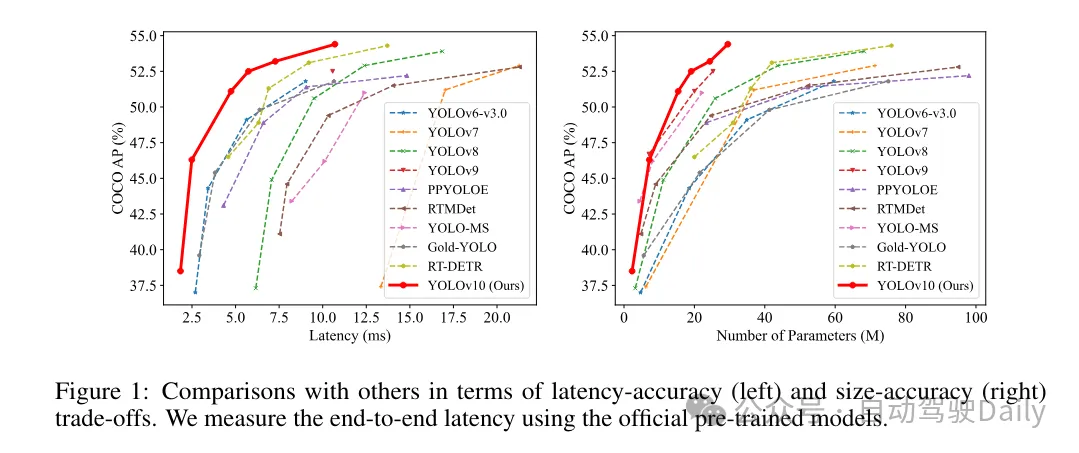
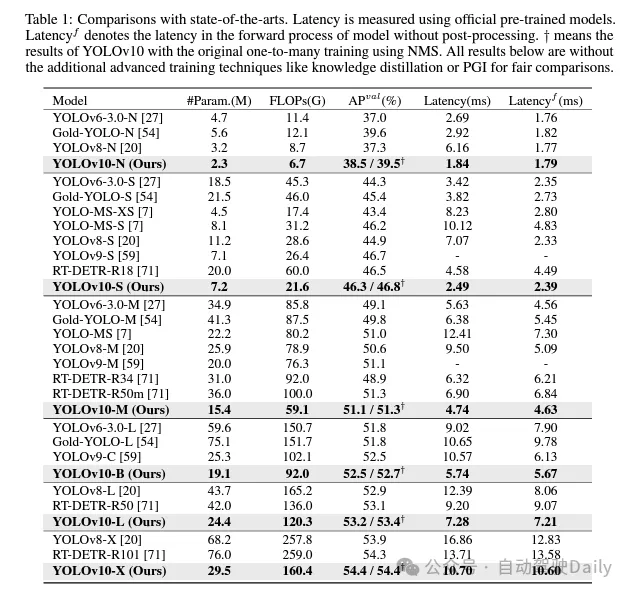
これらの方法に基づいて、著者は、さまざまなモデル サイズ、つまり YOLOv10-N/S/M/B/L/X を使用した一連のリアルタイム エンドツーエンド検出器の実装に成功しました。標準的な物体検出ベンチマークに関する広範な実験により、YOLOv10 がさまざまなモデル サイズでの計算精度のトレードオフの点で、以前の最先端モデルを上回る能力を実証していることが示されています。図 1 に示すように、同様のパフォーマンスでは、YOLOv10-S/X は RT-DETR R18/R101 よりそれぞれ 1.8 倍/1.3 倍高速です。 YOLOv9-C と比較して、YOLOv10-B は同じパフォーマンスで 46% の遅延削減を達成します。また、YOLOv10は非常に高いパラメータ利用効率を示します。 YOLOv10-L/X は、YOLOv8-L/X よりも 0.3 AP と 0.5 AP 高く、パラメーターの数はそれぞれ 1.8 倍と 2.3 倍減少しています。 YOLOv10-M は、パラメータの数をそれぞれ 23% と 31% 削減しながら、YOLOv9-M/YOLO-MS と同様の AP を実現します。
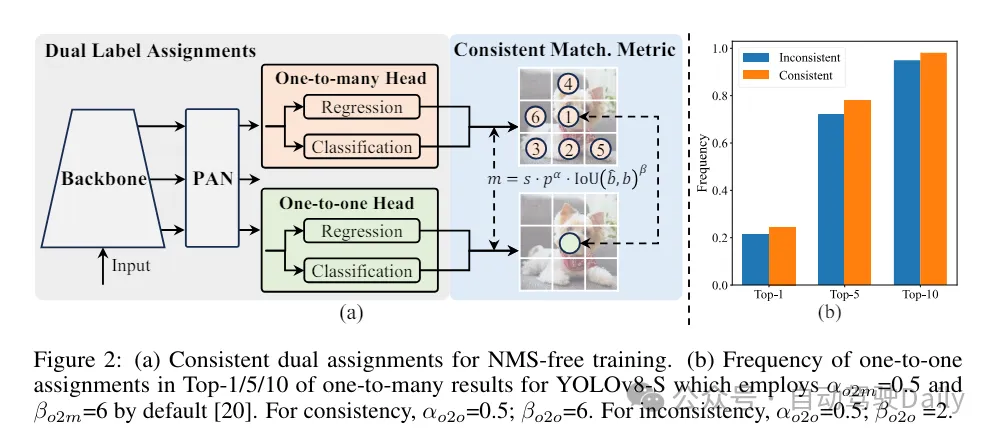
トレーニング プロセス中、YOLO は通常、TAL (タスク割り当て学習) を利用して、複数のサンプルを各インスタンスに割り当てます。 1 対多の割り当て方法を採用すると、豊富な監視信号が生成され、最適化とより強力なパフォーマンスの実現に役立ちます。ただし、これにより、YOLO は NMS (非最大抑制) 後処理に依存する必要が生じ、展開時の推論効率が最適ではなくなります。これまでの研究では、冗長な予測を抑制するために 1 対 1 マッチングのアプローチが検討されてきましたが、推論のオーバーヘッドが追加されたり、最適なパフォーマンスが得られないことがよくありました。 この研究では、二重ラベル割り当てと一貫したマッチングメトリクスを採用し、高い効率と競争力のあるパフォーマンスを達成する、NMS フリーのトレーニング戦略を提案します。この戦略により、当社の YOLO はトレーニングに NMS を必要としなくなり、高い効率と競争力のあるパフォーマンスを実現します。
効率重視のモデル設計。 YOLO のコンポーネントには、ステム、ダウンサンプリング レイヤー、基本的な構成要素を含むステージ、およびヘッドが含まれます。バックボーン部分の計算コストは非常に低いため、他の 3 つの部分については効率を重視したモデル設計を実行します。
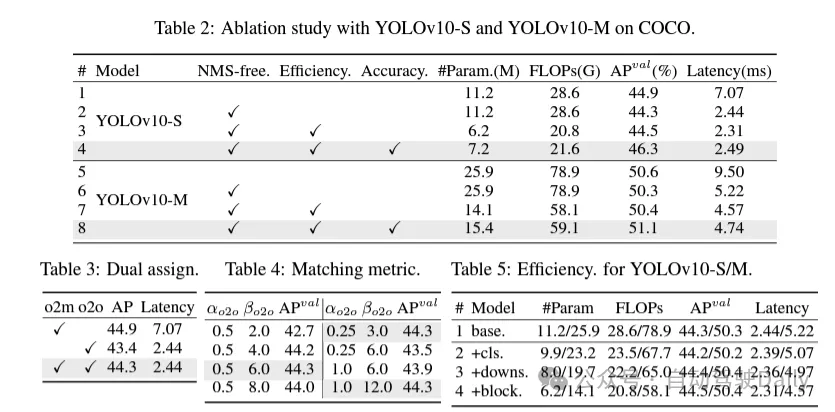
(1) 軽量分類ヘッダー。 YOLO では、通常、分類ヘッドと回帰ヘッドは同じアーキテクチャを持っています。ただし、計算オーバーヘッドには大きな違いがあります。たとえば、YOLOv8-S では、分類ヘッド (5.95G/1.51M) と回帰ヘッド (2.34G/0.64M) の FLOP 数とパラメーターはそれぞれ回帰ヘッドの 2.5 倍と 2.4 倍です。しかし、分類誤差と回帰誤差の影響を分析したところ (表 6 を参照)、回帰頭部が YOLO のパフォーマンスにとってより重要であることがわかりました。したがって、パフォーマンスへの悪影響を心配することなく、分類ヘッダーのオーバーヘッドを削減できます。したがって、カーネル サイズが 3 × 3 で、その後に 1 × 1 カーネルが続く 2 つの深さ方向に分離可能な畳み込みで構成される、軽量の分類ヘッド アーキテクチャを採用するだけです。 上記の改善により、軽量分類ヘッドのアーキテクチャを簡素化できます。このアーキテクチャは、畳み込みカーネル サイズが 3×3 の深さ分離可能な 2 つの畳み込みと、その後に続く 1×1 畳み込みカーネルで構成されます。この簡素化されたアーキテクチャにより、より少ない計算オーバーヘッドとパラメータ数で分類機能を実現できます。
(2) 空間チャネルの分離されたダウンサンプリング。 YOLO は通常、ストライド 2 の通常の 3x3 標準畳み込みを使用し、空間ダウンサンプリング (H × W から H/2 × W/2) とチャネル変換 (C から 2C) を実装します。これにより、無視できない計算コストとパラメータ数が発生します。代わりに、スペース削減とチャネル増加の操作を分離して、より効率的なダウンサンプリングを実現することを提案します。具体的には、最初に点方向の畳み込みを利用してチャネル次元を変調し、次に深さ方向の畳み込みを空間ダウンサンプリングに利用します。これにより、計算コストが に、パラメータ数が に削減されます。同時に、ダウンサンプリング中の情報保持を最大限に高め、競争力のあるパフォーマンスを維持しながら遅延を削減します。
(3) ランクガイダンスに基づいたモジュール設計。 YOLO は通常、YOLOv8 のボトルネック ブロックなど、すべてのステージで同じ基本構成ブロックを使用します。 YOLO のこの同型設計を徹底的に調べるために、固有ランクを利用して各ステージの冗長性を分析します。具体的には、各ステージの最後の基本ブロック内の最後の畳み込みの数値ランクが計算され、しきい値より大きい特異値の数がカウントされます。図 3(a) は YOLOv8 の結果を示しており、深いステージと大規模なモデルがより多くの冗長性を示す可能性が高いことを示しています。この観察は、同じブロック設計をすべてのステージに単純に適用することは、最適な容量効率のトレードオフを達成するには次善であることを示唆しています。この問題を解決するために、ランクベースのモジュール設計スキームが提案されています。これは、コンパクトなアーキテクチャ設計を通じて冗長であることが判明したステージの複雑さを軽減することを目的としています。
最初に、図 3(b) に示すように、空間ミキシングには安価な深さ方向の畳み込みと、チャネル ミキシングにはコスト効率の高い点方向の畳み込みを採用するコンパクトな反転ブロック (CIB) 構造を導入します。これは、たとえば ELAN 構造に埋め込むなど、効果的な基本構成要素として機能します (図 3(b))。次に、競争力を維持しながら最適な効率を達成するために、ランクベースのモジュール割り当て戦略が提唱されています。具体的には、モデルが与えられた場合、すべてのステージをその固有のランクの昇順に従って順序付けします。前段の基本ブロックを CIB に置き換えた後の性能の変化をさらに調べます。指定されたモデルと比較してパフォーマンスの低下がない場合は、次のステージの置き換えを続行します。そうでない場合は、プロセスを停止します。その結果、さまざまな段階やモデル サイズで適応型コンパクト ブロック設計を実装し、パフォーマンスを犠牲にすることなく効率の向上を実現できます。
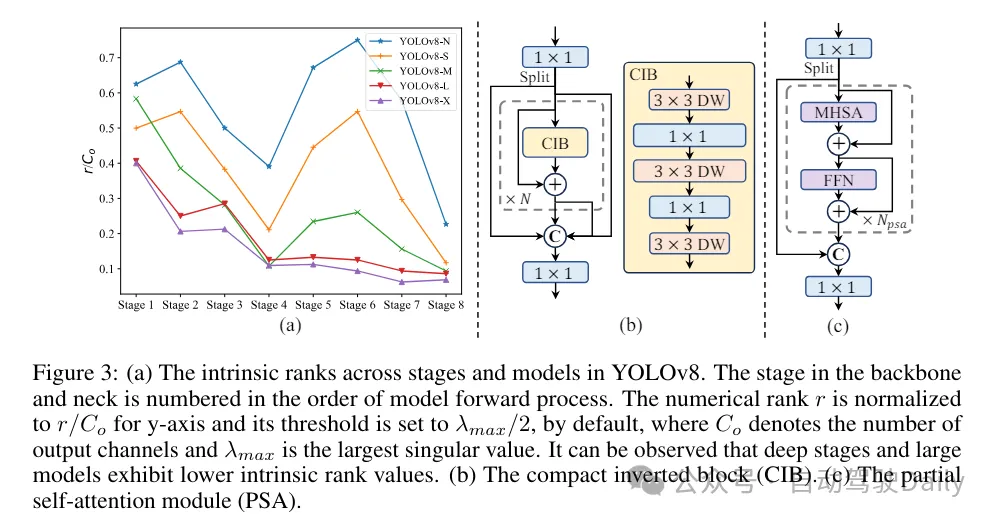
精度重視のモデル設計に基づいています。 この論文では、最小限のコストでパフォーマンスを向上させることを目的として、精度ベースの設計を実現するためのラージカーネル畳み込みとセルフアテンションメカニズムをさらに調査しています。
(1) 大規模なカーネル畳み込み。ラージカーネルのディープコンボリューションの採用は、受容野を拡大し、モデルの機能を強化する効果的な方法です。ただし、すべての段階で単純にこれらを利用すると、小さなオブジェクトの検出に使用される浅い特徴に汚染が発生する可能性があり、同時に高解像度段階で大幅な I/O オーバーヘッドと遅延が発生する可能性があります。したがって、著者らは、ディープステージのステージ間情報ブロック(CIB)でラージカーネルのディープコンボリューションを利用することを提案しています。ここで、CIB の 2 番目の 3×3 深さ方向の畳み込みのカーネル サイズは 7×7 に増加します。さらに、構造再パラメータ化テクノロジーを採用して別の 3x3 深さの畳み込みブランチを導入し、推論のオーバーヘッドを増加させることなく最適化問題を軽減します。さらに、モデルのサイズが大きくなるにつれて、その受容野は自然に拡大し、大規模なカーネル畳み込みを使用する利点は徐々に減少します。したがって、大規模なカーネルの畳み込みは、小規模なモデル スケールでのみ使用されます。
(2) 部分的自己注意 (PSA)。セルフ アテンション メカニズムは、その優れたグローバル モデリング機能により、さまざまな視覚タスクで広く使用されています。ただし、計算の複雑さとメモリ使用量が高くなります。この問題を解決するために、ユビキタスなアテンションヘッドの冗長性を考慮して、図 3.(c) に示すような効率的な部分セルフアテンション (PSA) モジュール設計を提案します。具体的には、1×1 畳み込み後の特徴はチャネルごとに 2 つの部分に均等に分割されます。機能の一部のみが、マルチヘッド セルフ アテンション モジュール (MHSA) とフィードフォワード ネットワーク (FFN) で構成される NPSA ブロックに入力されます。次に、特徴の 2 つの部分が接続され、1×1 畳み込みによって融合されます。さらに、MHSA のクエリとキーの次元を値の半分に設定し、高速推論のために LayerNorm を BatchNorm に置き換えます。 PSA は、自己注意の 2 次計算の複雑さによって引き起こされる過剰なオーバーヘッドを避けるために、最も低い解像度を持つステージ 4 の後にのみ配置されます。このようにして、グローバル表現学習機能を低い計算コストで YOLO に組み込むことができるため、モデルの機能が大幅に強化され、パフォーマンスが向上します。
実験比較
ここではあまり紹介せず、結果だけを紹介します! ! !レイテンシが短縮され、パフォーマンスが向上し続けます。
以上がYOLOv10が登場しました!真のリアルタイムのエンドツーエンドのターゲット検出の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1673
1673
 14
1429
52
1333
25
1278
29
1257
24
14
1429
52
1333
25
1278
29
1257
24

 エンドツーエンドとはどういう意味ですか?
Sep 27, 2021 pm 12:10 PM
エンドツーエンドとはどういう意味ですか?
Sep 27, 2021 pm 12:10 PM
エンドツーエンドとは「ネットワーク接続」を指します。ネットワークが通信するには、接続を確立する必要があります。ネットワークがどれほど離れていても、中間にマシンが何台あっても、両端間に接続を確立する必要があります。接続が確立されると、つまり、エンドツーエンドは論理リンクです。
 正確なオブジェクト検出のためのマルチグリッド冗長境界ボックス注釈
Jun 01, 2024 pm 09:46 PM
正確なオブジェクト検出のためのマルチグリッド冗長境界ボックス注釈
Jun 01, 2024 pm 09:46 PM
1. はじめに 現在、主要なオブジェクト検出器は、深層 CNN のバックボーン分類器ネットワークを再利用した 2 段階または 1 段階のネットワークです。 YOLOv3 は、入力画像を受け取り、それを等しいサイズのグリッド マトリックスに分割する、よく知られた最先端の 1 段階検出器の 1 つです。ターゲット中心を持つグリッド セルは、特定のターゲットの検出を担当します。今日私が共有するのは、各ターゲットに複数のグリッドを割り当てて正確なタイトフィット境界ボックス予測を実現する新しい数学的手法です。研究者らはまた、ターゲット検出のための効果的なオフラインのコピー&ペーストデータの強化も提案しました。新しく提案された方法は、現在の最先端の物体検出器の一部よりも大幅に性能が優れており、より優れたパフォーマンスが期待されます。 2. バックグラウンドターゲット検出ネットワークは、次のように設計されています。
 エンドツーエンドおよび次世代の自動運転システムと、エンドツーエンドの自動運転に関する誤解について話しましょう。
Apr 15, 2024 pm 04:13 PM
エンドツーエンドおよび次世代の自動運転システムと、エンドツーエンドの自動運転に関する誤解について話しましょう。
Apr 15, 2024 pm 04:13 PM
この 1 か月間、いくつかのよく知られた理由により、私は業界のさまざまな教師やクラスメートと非常に集中的な交流をしてきました。この交換で避けられない話題は当然、エンドツーエンドと人気の Tesla FSDV12 です。この機会に、現時点での私の考えや意見を整理し、皆様のご参考とご議論に役立てたいと思います。エンドツーエンドの自動運転システムをどのように定義するか、またエンドツーエンドで解決することが期待される問題は何でしょうか?最も伝統的な定義によれば、エンドツーエンド システムとは、センサーから生の情報を入力し、関心のある変数をタスクに直接出力するシステムを指します。たとえば、画像認識では、従来の特徴抽出 + 分類子方式と比較して、CNN はエンドツーエンドと言えます。自動運転タスクでは、各種センサー(カメラ/LiDAR)からのデータを入力
 ターゲット検出用の新しい SOTA: YOLOv9 が登場し、新しいアーキテクチャにより従来の畳み込みが復活します
Feb 23, 2024 pm 12:49 PM
ターゲット検出用の新しい SOTA: YOLOv9 が登場し、新しいアーキテクチャにより従来の畳み込みが復活します
Feb 23, 2024 pm 12:49 PM
ターゲット検出の分野では、YOLOv9 は実装プロセスで進歩を続けており、新しいアーキテクチャとメソッドを採用することにより、従来の畳み込みのパラメータ利用を効果的に改善し、そのパフォーマンスが前世代の製品よりもはるかに優れています。 2023 年 1 月に YOLOv8 が正式にリリースされてから 1 年以上が経過し、ついに YOLOv9 が登場しました。 2015 年に Joseph Redmon 氏や Ali Farhadi 氏らが第 1 世代の YOLO モデルを提案して以来、ターゲット検出分野の研究者たちはそれを何度も更新し、反復してきました。 YOLO は画像のグローバル情報に基づく予測システムであり、そのモデルのパフォーマンスは継続的に強化されています。アルゴリズムとテクノロジーを継続的に改善することにより、研究者は目覚ましい成果を上げ、ターゲット検出タスクにおける YOLO をますます強力にしています。
 nuScenes の最新 SOTA | SparseAD: スパース クエリは効率的なエンドツーエンドの自動運転に役立ちます。
Apr 17, 2024 pm 06:22 PM
nuScenes の最新 SOTA | SparseAD: スパース クエリは効率的なエンドツーエンドの自動運転に役立ちます。
Apr 17, 2024 pm 06:22 PM
先頭と開始点に書かれている エンドツーエンドのパラダイムでは、統一されたフレームワークを使用して自動運転システムのマルチタスクを実現します。このパラダイムの単純さと明確さにも関わらず、サブタスクにおけるエンドツーエンドの自動運転手法のパフォーマンスは、依然としてシングルタスク手法に比べてはるかに遅れています。同時に、以前のエンドツーエンド手法で広く使用されていた高密度鳥瞰図 (BEV) 機能により、より多くのモダリティやタスクに拡張することが困難になります。ここでは、スパース検索中心のエンドツーエンド自動運転パラダイム (SparseAD) が提案されています。このパラダイムでは、スパース検索は、高密度の BEV 表現を使用せずに、空間、時間、タスクを含む運転シナリオ全体を完全に表します。具体的には、統合されたスパース アーキテクチャが、検出、追跡、オンライン マッピングなどのタスク認識のために設計されています。さらに、重い
 C++ を使用して高性能の画像追跡とターゲット検出を行うにはどうすればよいですか?
Aug 26, 2023 pm 03:25 PM
C++ を使用して高性能の画像追跡とターゲット検出を行うにはどうすればよいですか?
Aug 26, 2023 pm 03:25 PM
C++ を使用して高性能の画像追跡とターゲット検出を行うにはどうすればよいですか?要約: 人工知能とコンピュータビジョン技術の急速な発展に伴い、画像追跡とターゲット検出が重要な研究分野となっています。この記事では、C++ 言語といくつかのオープンソース ライブラリを使用して、高性能の画像追跡とターゲット検出を実現する方法を紹介し、コード例を示します。はじめに: 画像追跡と物体検出は、コンピューター ビジョンの分野における 2 つの重要なタスクです。ビデオ監視、自動運転、高度道路交通システムなど、さまざまな分野で広く使用されています。のために
 複数のSOTA! OV-Uni3DETR: カテゴリ、シーン、モダリティにわたる 3D 検出の汎用性の向上 (清華大学および HKU)
Apr 11, 2024 pm 07:46 PM
複数のSOTA! OV-Uni3DETR: カテゴリ、シーン、モダリティにわたる 3D 検出の汎用性の向上 (清華大学および HKU)
Apr 11, 2024 pm 07:46 PM
この論文では、3D オブジェクト検出の分野、特に Open-Vocabulary の 3D オブジェクト検出について説明します。従来の 3D オブジェクト検出タスクでは、システムは実際のシーン内のオブジェクトの 3D 境界ボックスとセマンティック カテゴリ ラベルの位置を予測する必要があり、通常は点群または RGB イメージに依存します。 2D 物体検出テクノロジはその普及性と速度により優れたパフォーマンスを発揮しますが、関連する調査によると、3D ユニバーサル検出の開発はそれに比べて遅れをとっています。現在、ほとんどの 3D オブジェクト検出方法は依然として完全教師あり学習に依存しており、特定の入力モード下で完全に注釈が付けられたデータによって制限されており、屋内シーンか屋外シーンかにかかわらず、トレーニング中に出現するカテゴリのみを認識できます。この論文では、3D ユニバーサル ターゲット検出が直面する課題は主に次のとおりであると指摘しています。
 2024 年に、中国ではエンドツーエンドの自動運転に大きな進歩と進歩が見られるでしょうか?
May 08, 2024 pm 02:49 PM
2024 年に、中国ではエンドツーエンドの自動運転に大きな進歩と進歩が見られるでしょうか?
May 08, 2024 pm 02:49 PM
Tesla V12 が北米で大規模に発売され、その優れたパフォーマンスによりますます多くのユーザーからの認知を得ていることは、誰もが理解しているわけではありませんが、エンドツーエンドの自動運転は誰もが最も懸念している技術的方向でもあります。自動運転業界について。最近、さまざまな業界の一流のエンジニア、プロダクトマネージャー、投資家、メディア関係者と交流する機会があり、誰もがエンドツーエンドの自動運転に非常に興味を持っていることがわかりました。エンドツーエンドの自動運転に対する基本的な理解については、この種の誤解が依然として存在します。国内一流ブランドの画像ありとなしの都市機能、および FSD V11 と V12 の 2 つのバージョンを経験する幸運に恵まれた者として、ここでは、現段階でのいくつかのことについてお話したいと思います。私の職業上の経歴と、長年にわたるテスラ FSD の進歩の追跡について説明します。
