

北京大学の研究チームは拡散モデルを使って地球を「複製」した?
世界中のどの場所でも、このモデルは複数の解像度のリモート センシング画像を生成し、豊かで多様な「並列シーン」を作成できます。
そして、地形、気候、植生などの複雑な地理的特徴がすべて考慮されます。

Google Earth に触発されて、北京杭大学の研究チームは、地球全体の衛星リモート センシング画像を俯瞰視点からディープ ニューラル ネットワークに「ロード」しました。
そのようなネットワークに基づいて、チームはグローバルなトップダウンのビジュアル生成モデルである MetaEarth を構築しました。
MetaEarth には 6 億のパラメータがあり、世界中のあらゆる地理的位置をカバーする無制限の複数解像度のリモート センシング画像を生成できます。

先行研究と比較して、世界規模の基本的なビジュアル生成モデルの構築はより困難であり、その過程で多くの困難が克服されてきました。
地球には都市、森林、砂漠、海洋、氷河、雪原などの幅広い地理的特徴があり、これらを理解してモデルで表現する必要があるため、モデルの処理能力が課題となります。
同じ種類の人工地物であっても、緯度、気候、文化環境が異なると大きな違いが見られ、生成されるモデルの能力に高い要求が課せられます。
MetaEarth はこの困難を解決し、さまざまな場所や地形で高解像度かつ大規模なシーンの生成を実現しました。
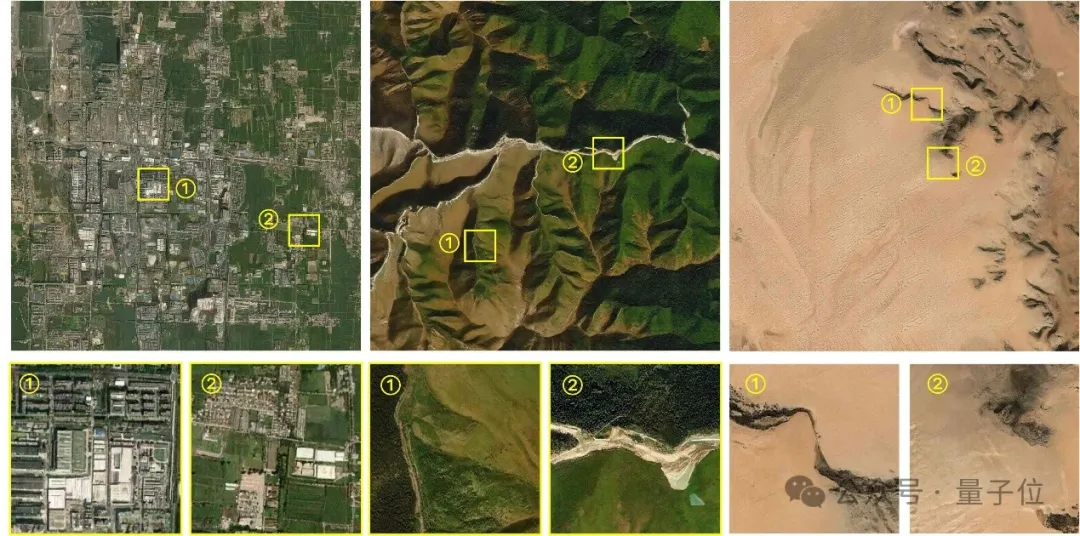
さらに、制御可能な解像度でリモート センシング画像を生成することも課題です。
俯瞰画像の画像処理の過程で、地表フィーチャの表示は解像度に大きく影響されるため、画像解像度が異なると明らかな違いが生じます。指定された解像度 (メートル/ピクセル) で正確に生成することは困難です。能力。
MetaEarth が異なる解像度の画像を生成すると、地上物体の特徴を正確かつ合理的に表現でき、異なる解像度間の相関関係も正確にマッピングされます。


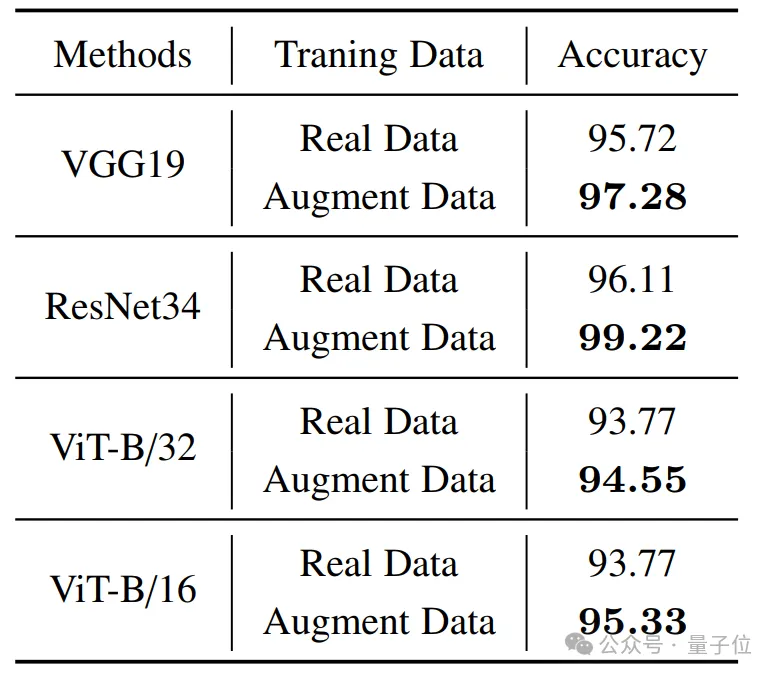
モデルのトレーニングをサポートするために、チームは、世界中のほとんどの地域をカバーする複数の空間解像度の画像とその地理情報 (緯度、経度、解像度) を含む大規模なリモート センシング画像データセットを収集しました。
この研究では、著者らは解像度に基づく自己カスケード生成フレームワークを提案しています。
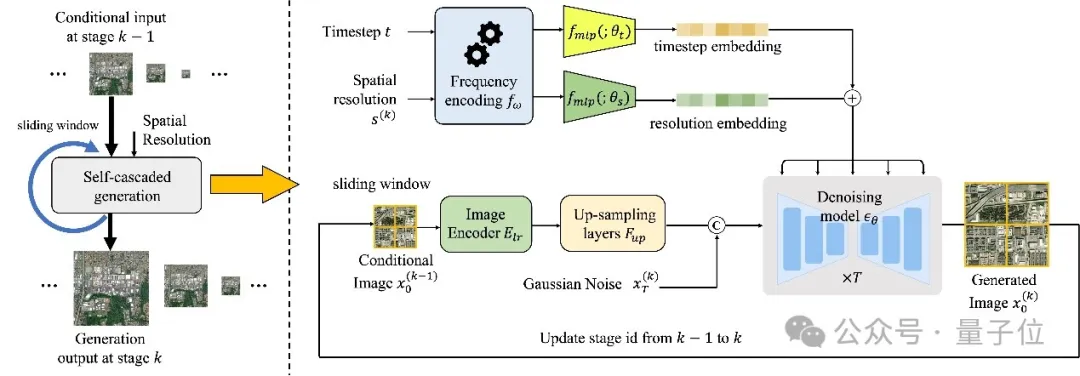
このフレームワークでは、単一のモデルのみを使用して、特定の地理的位置の多重解像度画像生成を実現し、各レベルで豊富で多様な「並列画像」を作成できます。解像度」。
具体的には、これは、低解像度の条件付き画像と空間解像度エンコードをノイズ除去プロセスのタイムステップ埋め込みと組み合わせて、各タイムステップでノイズを予測するコーデック構造のノイズ除去ネットワークであり、画像生成を実装します。
任意のサイズの無制限の画像を生成するために、著者はメモリ効率の高いスライディング ウィンドウ生成方法とノイズ サンプリング戦略も設計しました。
この戦略は、生成された画像を条件として重複する画像ブロックに分割し、特定のノイズ サンプリング戦略を使用して隣接する画像ブロックの共有領域に同様のコンテンツを生成することで、スプライシング ギャップを回避します。
さらに、このノイズ サンプリング戦略により、任意のサイズの無制限の画像を生成する際に、モデルが消費するビデオ メモリ リソースが少なくなります。
この研究の著者は、北京大学の「Learning, Vision and Remote Sensing Laboratory, LEVIR Lab」(LEVIR Lab)の出身です。この研究室は教授が率いています。 Shi Zhenwei、国家優秀若手学者。
ミシガン大学の博士研究員であるShi Zhenwei教授の元博士課程の学生であり、現在研究室のメンバーであるZou Zhengxia教授は、この記事の責任著者です。
論文アドレス: https://www.php.cn/link/31bb2feb402ac789507479daf9713b00
プロジェクトホームページ: https://www.php.cn/link/a0098fd07db7 6 92267fca4f4169c9ba2
以上が地球全体をニューラルネットワークに組み込んで、北杭大学のチームがグローバルリモートセンシング画像生成モデルを立ち上げたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



