


Riva は、リアルタイム音声 AI サービスのために NVIDIA によって開始された SDK です。これは高度にカスタマイズ可能なツールであり、GPU アクセラレーションを使用します。多くの事前トレーニング済みモデルが NGC で提供されており、これらのモデルはすぐに使用でき、Riva が提供する ASR および TTS ソリューションを使用して直接デプロイできます。
特定の分野のニーズを満たすため、またはカスタマイズされた機能を開発するために、ユーザーは NeMo を使用してこれらのモデルを再トレーニングまたは微調整することもできます。これにより、モデルのパフォーマンスがさらに向上し、ユーザーのニーズにより適応できるようになります。
Riva+Skills は、GPU を活用してリアルタイムのストリーミング音声認識と音声合成を高速化し、数千の同時リクエストを同時に処理できる、高度にカスタマイズ可能なツールです。ローカル、クラウド、エンドサイドを含む複数の導入プラットフォームをサポートします。

音声認識に関して、Riva は Citrinet、Conformer、NeMo が自社開発した FastConformer などの高精度の SOTA モデルを使用します。現在、Riva は 10 を超える単一言語モデルをサポートしており、英語 - スペイン語、英語 - 中国語、英語 - 日本語の音声認識を含む多言語音声認識もサポートしています。
カスタマイズ機能により、モデルの精度をさらに向上させることができます。たとえば、特定の業界用語、アクセントや方言のサポート、騒がしい環境向けのカスタマイズは、音声認識パフォーマンスの向上に役立ちます。
Riva の全体的なフレームワークは、顧客サービスや会議システムなどのさまざまなシナリオに適用できます。一般的なシナリオに加えて、Riva のサービスは、CSP、教育、金融、その他の業界など、さまざまな業界のニーズに応じてカスタマイズすることもできます。
Riva ASR のプロセス全体には、難易度に応じて 3 つのカテゴリに分類できるカスタマイズ可能なモジュールがいくつかあります。

まず、オレンジ色のボックスは、推論プロセス中にクライアントで実行できるカスタマイズです。たとえば、ホットワード機能をサポートしており、推論プロセス中に製品名や固有名詞を追加することで、音声モデルはこれらの特定の単語をより正確に識別できます。この機能は Riva によってネイティブにサポートされており、モデルの再トレーニングや Riva サーバーの再起動を行わずにカスタマイズできます。
紫色のボックスには、デプロイ時に実行できるいくつかのカスタマイズが含まれています。たとえば、Riva のストリーミング認識には、レイテンシの最適化とスループットの最適化の 2 つのモードが用意されており、ビジネス ニーズに応じて選択して、より優れたパフォーマンスを得ることができます。さらに、展開プロセス中に、発音辞書をカスタマイズすることもできます。カスタマイズされた発音辞書を使用すると、特定の用語、名前、業界用語の正しい発音を保証し、音声認識の精度を向上させることができます。
緑色のボックスはトレーニングプロセス中に実行できるカスタマイズ、つまりサーバー側で実行されるトレーニングと調整です。たとえば、トレーニングの開始時のテキストの正則化フェーズでは、特定のテキストの処理を追加できます。さらに、音響モデルを微調整または再トレーニングして、特定のビジネス シナリオにおけるアクセントやノイズなどの問題を解決し、モデルをより堅牢にすることができます。言語モデルの再トレーニング、句読点モデルの微調整、逆テキスト正則化なども行うことができます。
上記はRivaのカスタマイズ可能な部分です。

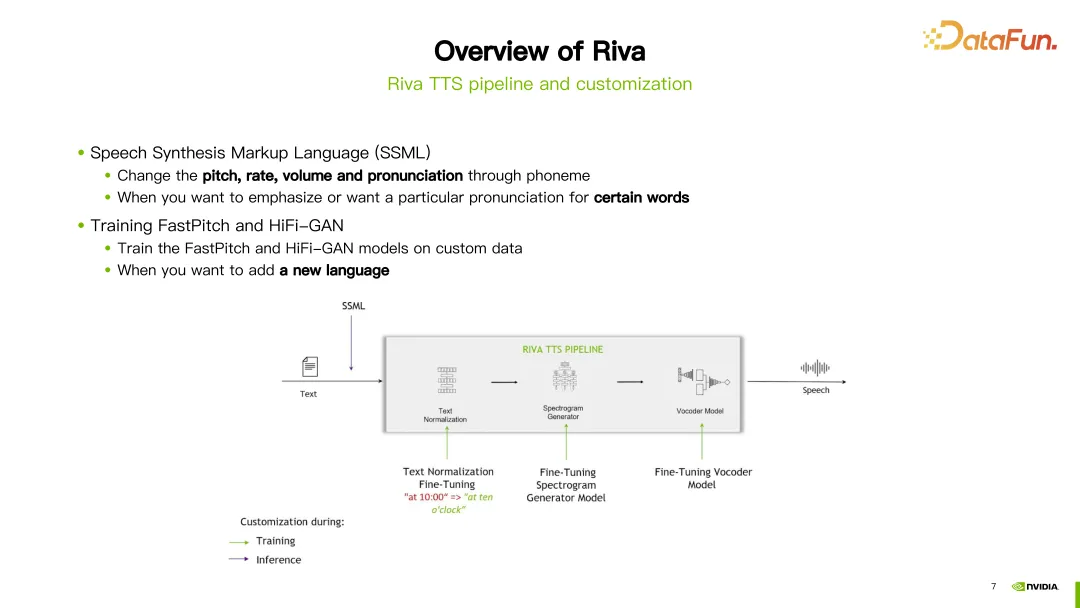
Riva TTS プロセスは上の図の右側に示されており、次のモジュールが含まれています。 上の図では、「Hello World」という文を例として、まずテキスト正規化モジュールに入り、大文字と小文字の正規化など、テキストを標準化します。次に、G2P モジュールに入り、テキストを一連の音素に変換します。次に、スペクトル合成モジュールに入り、ニューラル ネットワークのトレーニングを通じてスペクトルを取得します。最後にボコーダーを入力してスペクトルを最終サウンドに変換します。 Riva は、現在人気のある FastPitch モデルと HiFi-GAN モデルの組み合わせを使用して、ストリーミング TTS サポートを提供します。現在、英語、中国語、スペイン語、イタリア語、ドイツ語を含む複数の言語をサポートしています。 Riva の TTS プロセスでは、カスタマイズのために 2 つのメソッドが提供されています。 1 つ目の方法は、音声合成マークアップ言語 (SSML) を使用する方法です。これはカスタマイズが簡単です。設定によっては、発音のピッチ、スピード、音量などを調整することができます。通常、これは特定の単語の発音を変更する場合に選択されます。 もう 1 つの方法は、FastPitch または HiFi-GAN モデルを微調整または再トレーニングすることです。どちらのモデルも、独自の特定のデータを使用して微調整または再トレーニングできます。 過去 1 年間、Riva は中国語モデルにいくつかのアップデートと改善を加えてきました。ここでは重要なアップデートをいくつか紹介します。 まず、中国語音声認識 (ASR) モデルの最適化を続けます。最新の ASR モデルは、対応するリンクで見つけることができます。 次に、統一モデルのサポートが導入されます。これは、音声認識句読点予測を 1 つの推論で同時に実行できることを意味します。 3 番目に、中国語と英語の混合モデルのサポートが追加されました。これは、モデルが中国語と英語の両方の音声入力を処理できることを意味します。 さらに、いくつかの新しいモジュールと機能のサポートが導入されました。ニューラル ネットワーク ベースの音声アクティビティ検出 (VAD) および話者ダイアライゼーション モジュールが含まれています。中国語逆テキスト正則化機能も紹介されています。これらのモデルの詳細については、対応するリンクを参照してください。 さらに、中国語向けの詳細なチュートリアルも提供しています。最初の部分はワードブースティングに関するチュートリアルです。 ホットワードは、認識中に特定の単語の重みを調整して、単語認識をより正確にします。チュートリアルでは、古代の詩の名前である「王岳」などのホットワードを使用した中国語モデルの例が示されており、この単語に 20 の重みを与えます。次に、Riva が提供する add_word_boosting_to_config メソッドを使用して、クライアントに追加する単語とそのスコアを構成します。次に、構成されたリクエストを ASR サーバーに送信し、ホットワードを追加した後の認識結果を取得します。 ホットワードを設定するときは、boosted_lm_words と boosted_lm_score の 2 つのパラメーターを設定する必要があります。 boosted_lm_words は、認識精度を向上させたい単語のリストです。 Boosted_lm_score はこれらの単語に設定されたスコアで、通常は 20 ~ 100 の間です。 前の基本構成に加えて、Riva のホットワード機能はいくつかの高度な使用法もサポートしています。たとえば、複数の単語の重みを同時に増やすことができます。たとえば、この例では、単語「5 G」と「4 G」にそれぞれ 20 と 30 の重みを設定します。 さらに、単語ブースティングを使用して特定の単語の精度を下げる、つまり負の重みを割り当てることで、単語の出現確率を下げることもできます。たとえば、この例では、「彼女」という漢字が与えられ、そのスコアは -100 に設定されています。このようにして、モデルは漢字を認識しなくなる傾向があります。理論的には、レイテンシに影響を与えることなく、任意の数のホット ワードを設定できます。ブースト プロセスはクライアント側で実装され、サーバー側には影響を与えないことにも注意してください。 2 番目のチュートリアルは、Conformer 音響モデルを微調整する方法についてです。 ASR の微調整には NeMo ツールを使用します。 NGC アカウントを設定した後、「NGC ダウンロード」コマンドを使用して、Riva が提供する事前トレーニング済み中国語モデルを直接ダウンロードできます。この例では、中国の ASR モデルの 5 番目のバージョンがダウンロードされました。ダウンロードが完了したら、事前トレーニングされたモデルをロードする必要があります。 まず、いくつかのパッケージをインポートする必要があります。パラメーターのモデル パスは、ダウンロードしたばかりのモデルのパスに設定されます。次に、NeMo が提供する ASRModel.restore_from 関数を使用してモデル構成ファイルを取得し、target パラメーターを使用して元の ASR モデルのカテゴリを取得します。次に、import_class_by_path 関数を使用して実際のモデル クラスを取得します。最後に、このカテゴリのモデルのrestore_fromメソッドを使用して、指定されたパスにASRモデルパラメータをロードします。 モデルをロードした後、NeMo が提供するトレーニング スクリプトを使用して微調整できます。この例では、CTC モデルのトレーニングを例として取り上げ、使用されるスクリプトは speech_to_text_ctc.py です。構成する必要があるパラメーターには、トレーニング データの JSON ファイル パスである train_ds.manifest_filepath や、GPU、オプティマイザー、最大反復ラウンド数を使用するかどうかなどがあります。 モデルをトレーニングした後、評価できます。評価するときは、use_cer パラメーターを true に設定することに注意する必要があります。中国語の場合、指標として文字エラー率 (Character Error Rate) が使用されるためです。モデルのトレーニングと評価が完了したら、nemo2riva コマンドを使用して NeMo モデルを Riva モデルに変換できます。次に、Riva のクイックスタート ツールを使用してモデルをデプロイします。
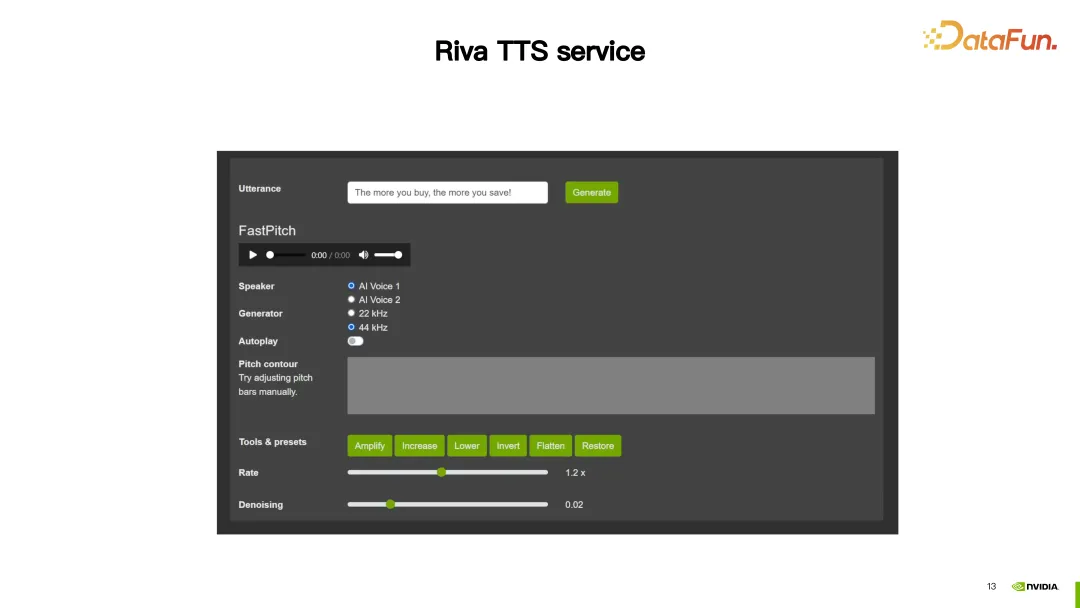
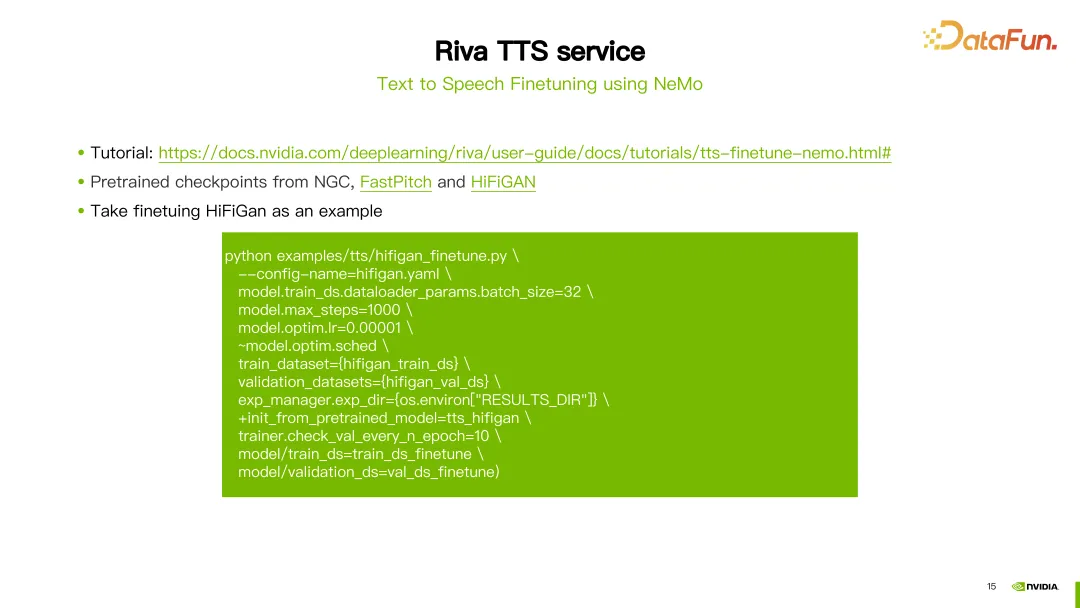
次に、Riva TTS サービスを紹介します。 このデモでは、Riva TTS は合成音声をより自然にするためのカスタマイズ機能を提供します。 次に、Riva TTSが提供する2つのカスタマイズ方法を紹介します。 1 つ目は、スクリプトを通じて設定される前述の SSML (音声合成マークアップ言語) です。 SSML を通じて、ピッチやレートを含む TTS のリズムを調整でき、音量も調整できます。 上の図のように、最初の文「今日は晴れです」では、韻のピッチを2.5に変更します。 2 番目の文では、レートを高く設定する設定と、音量を 1DB 増やす設定の 2 つが作成されました。このようにして、カスタマイズされた結果を得ることができます。 SSML に加えて、NeMo ツールを使用して、Riva TTS の FastPitch または HiFi-GAN モデルを微調整または再トレーニングすることもできます。 Riva は、NGC でチュートリアルといくつかの事前トレーニングされたモデルを提供します (上の画像のリンクを参照)。 写真はHiFi-GANモデルを微調整する例を示しています。 hifigan_finetune.py コマンドを使用して、モデル構成名、バッチ サイズ、最大反復ステップ数、学習率などのパラメーターを構成します。 train_dataset パラメーターを設定して、HiFi-GAN の微調整に必要なデータセット パスを設定します。 NGC から事前トレーニング済みモデルをダウンロードした場合は、init_from_pretrained_model パラメーターを使用して事前トレーニング済みモデルをロードすることもできます。このようにして、HiFi-GAN モデルを再トレーニングできます。 カスタマイズされたモデルは、クイックスタート ツールを使用してデプロイできます。 開始する前に、NGC アカウントを登録し、GPU が Riva をサポートし、Docker 環境がインストールされていることを確認する必要があります。 準備が完了したら、提供されたリンクから Riva Quickstart をダウンロードします。 NGC CLI が設定されている場合は、NGC CLI を使用して Riva クイックスタートを直接ダウンロードすることもできます。 Riva Quick Start をダウンロードした後、提供されているスクリプトを使用してサーバーを初期化、起動、シャットダウンできます。 最新バージョンの Riva (2.13.1) を例にとると、ダウンロードが完了した後、riva_init.sh、riva_start.sh、または riva_stop.sh を実行するだけで初期化と起動が完了します。そしてサーバーのシャットダウン。 中国語モデルを使用したい場合は、言語コードを zh-CN に設定するだけで、ツールは対応する事前トレーニング済みモデルを自動的にダウンロードします。中国語のASR(自動音声認識)機能やTTS(音声合成)機能を利用するためにサービスを開始できます。 サーバーが正常に起動したら、Riva が提供するスクリプト riva_start_client.sh を使用してサービスを呼び出すことができます。オフライン音声認識が必要な場合は、riva_asr_client コマンドを実行して、認識したい音声ファイルへのパスを指定するだけです。ストリーミング音声認識を実行する場合は、riva_streaming_asr_client コマンドを使用できます。音声合成を実行したい場合は、riva_tts_client コマンドを使用して、処理または合成する音声を起動したばかりのサーバーに送信します。 以下は、Riva 関連のドキュメント リソースの一部です: Riva 公式ドキュメント: このドキュメントでは、インストール、構成、使用ガイドなど、Riva に関する詳細情報が提供されます。ここで Riva の公式ドキュメントを見つけて、Riva についてさらに詳しく知り、Riva のあらゆる側面を学ぶことができます。 Riva クイック スタート ユーザー ガイド: このガイドでは、インストールと構成の手順、およびよくある質問への回答を含む、Riva クイック スタートの詳細な手順をユーザーに提供します。 Riva クイック スタートの使用中に問題が発生した場合は、このユーザー ガイドで解決策を見つけることができます。 Riva リリースノート: このドキュメントには、Riva の最新モデルに関する更新情報が記載されています。各バージョンの新機能と改良点については、ここで確認できます。 上記のリソースは、ユーザーが Riva をよりよく理解し、使用するのに役立ちます。 以上が今回シェアした内容です、皆さんありがとうございました。 A1: はい、Riva は Nvidia Triton の一部の開発に基づいた Nvidia Triton の推論フレームワークを使用しています。 A2: Riva は現在、主に音声 AI の分野に注力する必要があります。 A3: Riva はデプロイメント ソリューションに重点を置いています。Nemo でトレーニングしたモデルを Riva でデプロイすることもでき、その後、適切なモデルを微調整することもできます。リヴァで。 A4: 他のフレームワークを使用したトレーニングは一時的にサポートされていないか、追加の開発作業が必要です。 A5: Riva は現在、Nemo によってトレーニングされたモデルを主にサポートしています。Nemo は実際には PyTorch に基づいて開発されています。 A6: 自社開発モデルの場合、Riva でサポートしたい場合は、追加の開発を行う必要があります。 A7: Riva が提供する適応プラットフォーム関連のドキュメントを参照できます。これには、さまざまな種類の GPU の適応が含まれています。 A8: Riva クイックスタート ツールキットを NGC で直接ダウンロードすることで、Riva を試すことができます。 A9: そうですね。独自の方言の一部でデータを使用できます。 Riva が提供する事前トレーニング済みモデルに基づいて微調整し、Riva にデプロイするだけです。 A10: Riva のアクセラレーションは、実際には Tensor RT を使用しています。Riva は Tensor RT と Triton をベースにした製品です。
5. TTS パイプラインとカスタマイズ
2. 中国語音声認識モデルの最新アップデート
1. 概要

2. Word Boosting


3. Conformer AM の微調整


3. Riva TTS (Text-to-Speech) サービス
1. デモ
2. SSML

3. NeMo を使用した TTS 微調整
4. Riva クイックスタート ツール
1. 準備

2. サーバーの起動とシャットダウン

3. Riva クライアント

5. 参照リソース

6. 質疑応答
Q1: リヴァとトリトンの関係は何ですか?機能的に重複する部分はありますか?
Q2: Riva は実際に RAG 分野に実装されましたか?それともオープンソースプロジェクトでしょうか?
Q3: リヴァとニモの間には何か関係がありますか?
Q4: 他のフレームワークでトレーニングされたモデルは適用できますか?
Q5: Riva は PyTorch または TensorFlow トレーニング フレームワークからモデルをデプロイできますか?
Q6: Nemo で新しいモデルをカスタマイズする場合、Riva でデプロイメント コードを記述する必要がありますか?
Q7: Riva はメモリの小さい GPU でも使用できますか?
Q8: Riva をすぐに試すにはどうすればよいですか?
Q9: Riva が中国語の方言をサポートしたい場合、Riva にはカスタマイズされたトレーニングが必要ですか?
Q10: Riva と Tensor LM の位置付けに重複または相違点はありますか?
以上がNVIDIA Riva を使用して、エンタープライズレベルの中国語音声 AI サービスを迅速に導入し、最適化および高速化します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



