

仕事を辞めた後のイリヤの最初の行動: この論文が気に入ったので、ネチズンは急いで読みました

Ilya Sutskever が OpenAI からの辞任を正式に発表して以来、彼の次の行動がみんなの注目を集めています。
彼の一挙手一投足に注目する人もいます。
いいえ、イリヤは新しい論文を気に入っただけです -
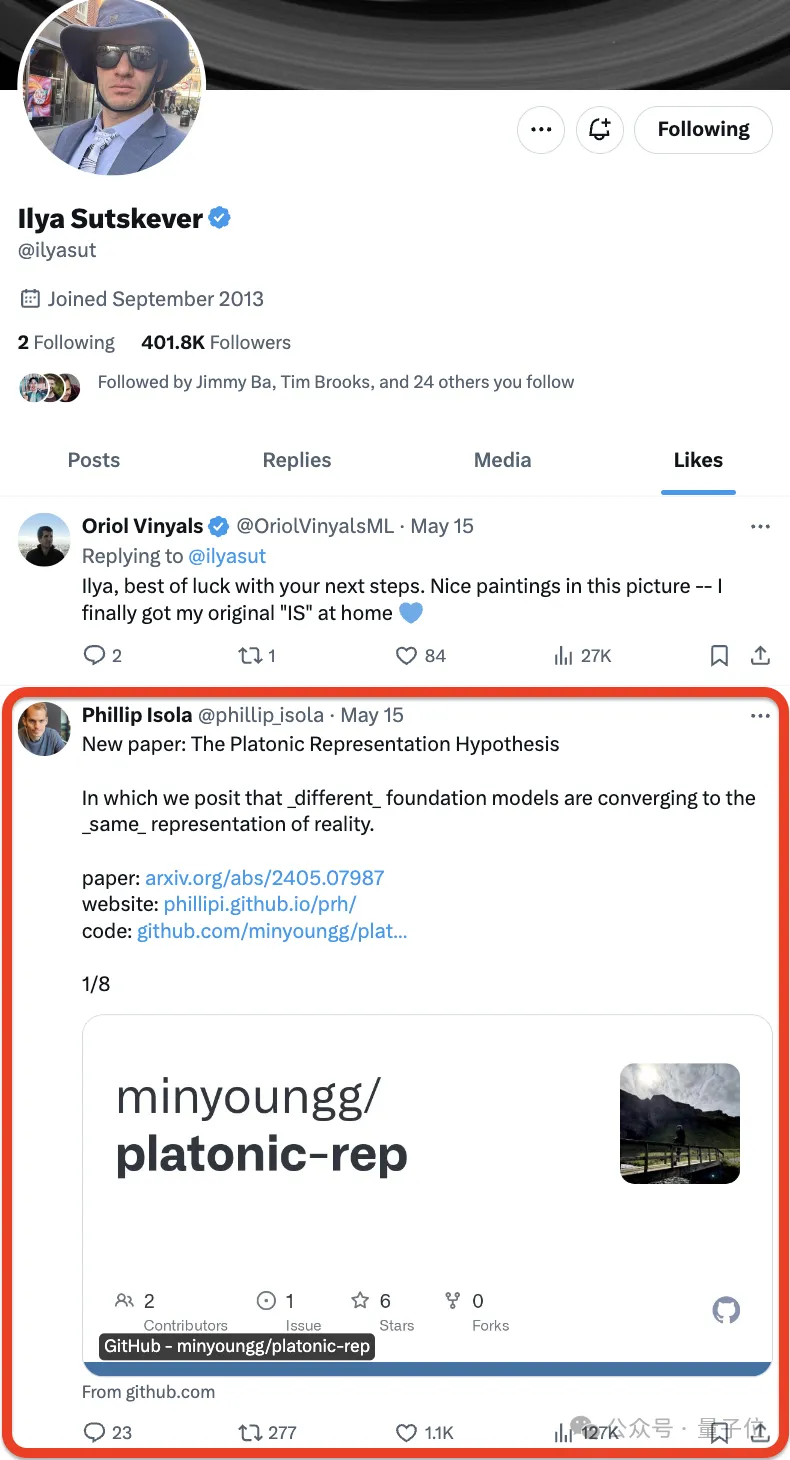 - そしてネチズンは急いでそれを気に入りました:
- そしてネチズンは急いでそれを気に入りました:

 その論文はMITからのもので、著者は仮説を提案しました。次のような一文に要約できます:
その論文はMITからのもので、著者は仮説を提案しました。次のような一文に要約できます:
現実世界の統計モデル内に共有表現空間を形成する傾向があります。
 彼らは、プラトンの洞窟の寓意と理想的現実の性質についての彼の考えにちなんで、この推測を
彼らは、プラトンの洞窟の寓意と理想的現実の性質についての彼の考えにちなんで、この推測を
と名付けました。
 一部のネチズンは、それを読んだ後、これを今年見た中で最高の論文だと呼びました:
一部のネチズンは、それを読んだ後、これを今年見た中で最高の論文だと呼びました:
 それを読んだ後、彼らは「アンナ」を使用しました。要約すると、「カレーニナ」の冒頭の文は次のとおりです。すべての幸福な言語モデルは似ており、すべての不幸な言語モデルには独自の不幸があります。
それを読んだ後、彼らは「アンナ」を使用しました。要約すると、「カレーニナ」の冒頭の文は次のとおりです。すべての幸福な言語モデルは似ており、すべての不幸な言語モデルには独自の不幸があります。
 ホワイトヘッドの有名な言葉を言い換えると、すべての機械学習はプラトンの脚注です。
ホワイトヘッドの有名な言葉を言い換えると、すべての機械学習はプラトンの脚注です。
 私たちも調べました、そして、一般的な内容は次のとおりです:
私たちも調べました、そして、一般的な内容は次のとおりです:
著者はAIシステムの
Representational Convergence(Representational Convergence)、つまり異なるデータポイントの表現を分析しました。ニューラル ネットワーク モデルは、さまざまなモデル アーキテクチャ、トレーニング目標、さらにはデータ モダリティにわたってますます類似してきています。 この収束の原動力は何でしょうか?この傾向は今後も続くのでしょうか?その最終目的地はどこでしょうか?
一連の分析と実験の後、研究者らは、この収束には終点と推進原理があると推測しました:
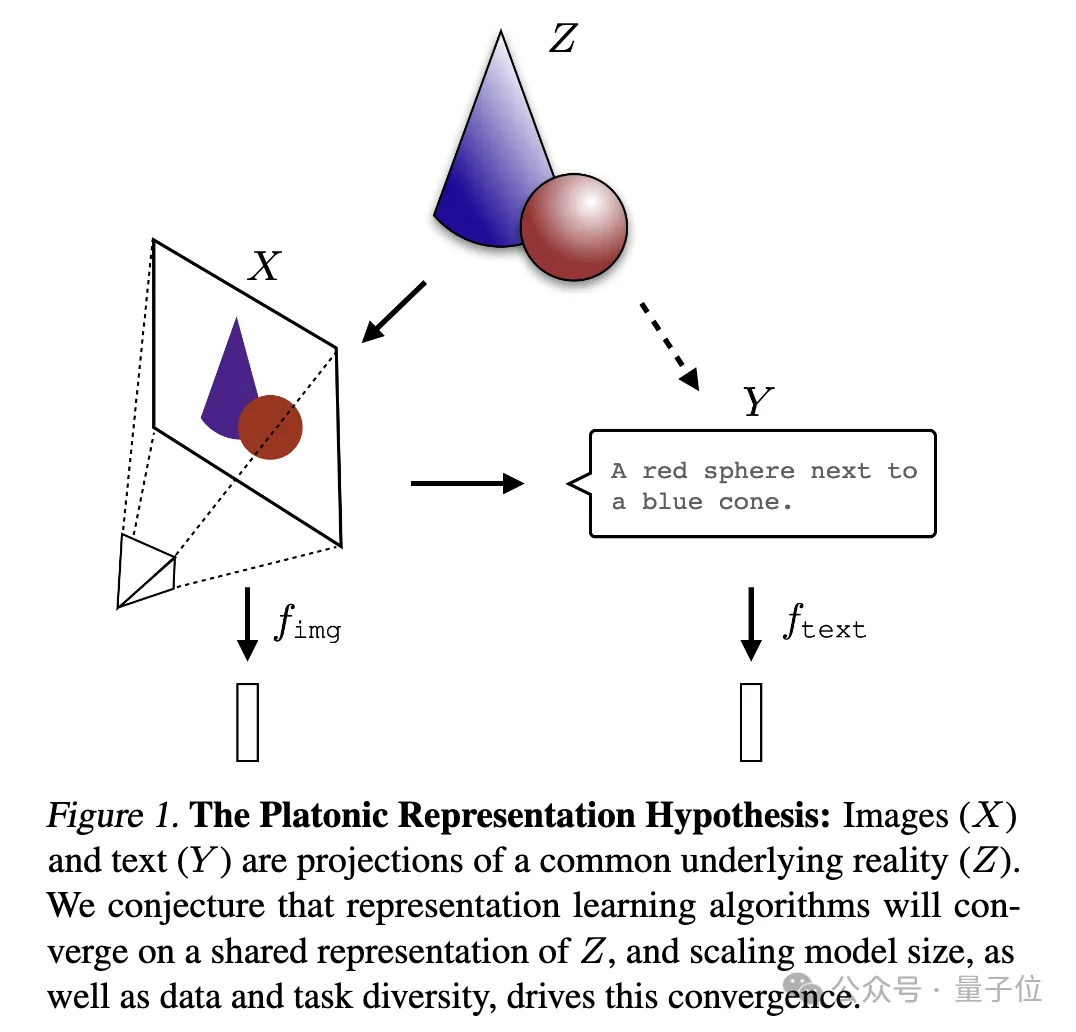
さまざまなモデルが現実の正確な表現を達成しようと努めています。 説明する図:
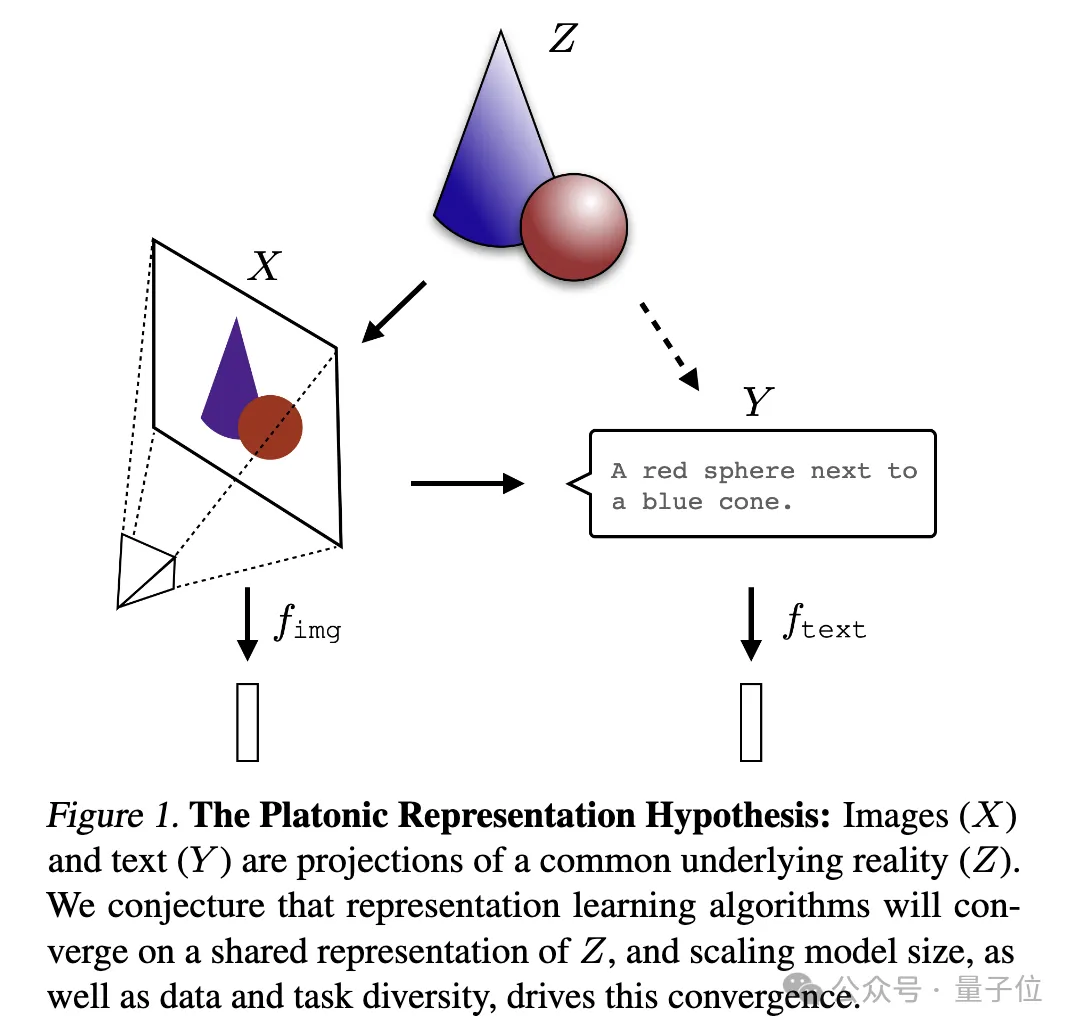 ここで、画像
ここで、画像
とテキスト (Y) は、共通の根底にある現実 (Z) の異なる投影です。研究者らは、表現学習アルゴリズムは Z の統一表現に収束すると考えており、モデル サイズの増大とデータとタスクの多様性がこの収束を促進する重要な要因であると推測しています。 それは確かにイリヤが興味を持っている質問だとしか言えません。深すぎて理解できません。AIに解釈してもらい、みんなで共有しましょう~
 その証拠。収束の
その証拠。収束の
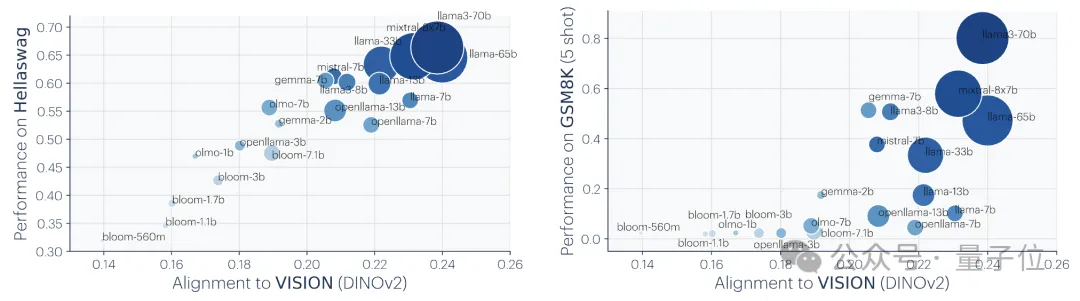
まず第一に、著者は、これまでの多数の関連研究を分析し、また自分自身で実験を行い、収束の一連の証拠を作成し、さまざまなシステムの収束、規模とパフォーマンス、およびクロスモーダル収束を実証しました。モデル。
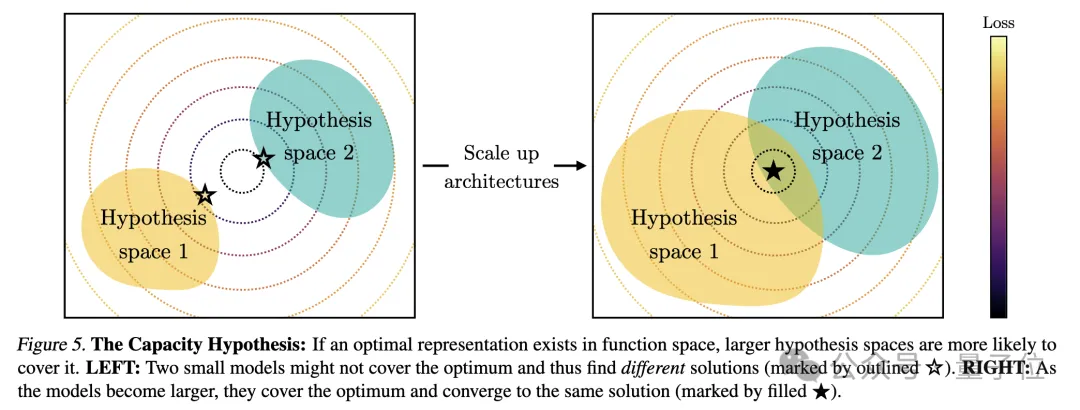
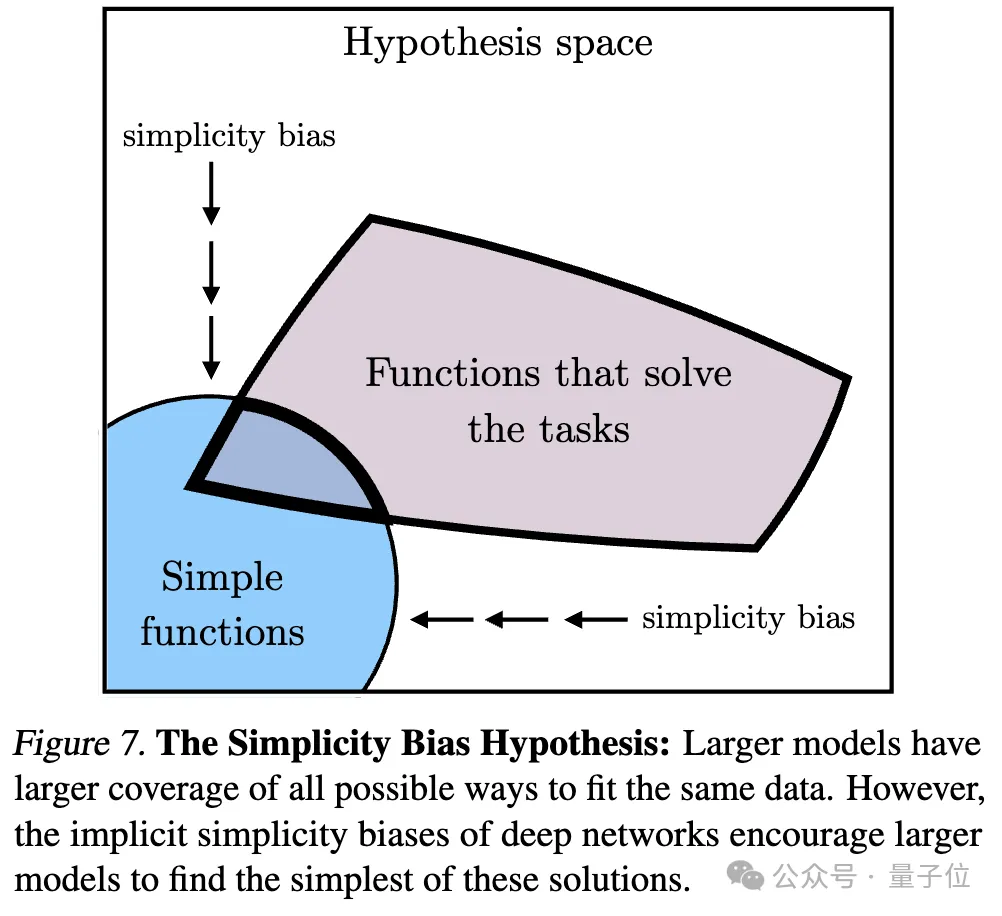
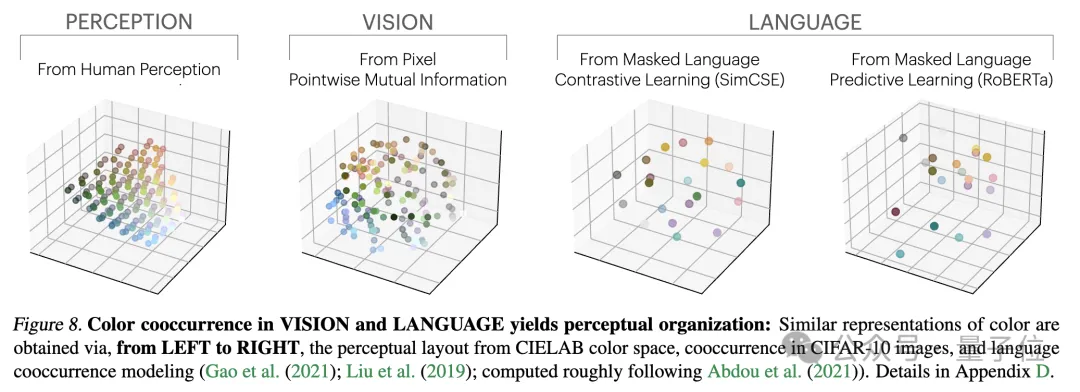
追伸: この研究はベクトル埋め込み表現、つまりデータをベクトル形式に変換し、データ点間の類似性や距離をカーネル関数で記述することに焦点を当てています。この記事における「表現の整合」の概念は、2 つの異なる表現方法が同様のデータ構造を明らかにする場合、2 つの表現は整合しているとみなされることを意味します。1. 異なるモデルの収束。異なるアーキテクチャと目標を持つモデルは、その基礎となる表現が一貫している傾向があります。 事前トレーニングされた基本モデルに基づいて構築されたシステムの数は徐々に増加しており、一部のモデルはマルチタスクの標準コア アーキテクチャになりつつあります。さまざまなアプリケーションにおけるこの幅広い適用性は、データ表現方法における特定の多用途性を反映しています。 この傾向は、AI システムがより小さな基本モデルのセットに収束していることを示唆していますが、異なる基本モデルが同じ表現を形成することを証明するものではありません。 しかし、モデルステッチング(モデルステッチング)に関連するいくつかの最近の研究では、画像分類モデルの中間層表現は、異なるデータセットでトレーニングされた場合でも適切に調整できることがわかりました。 たとえば、いくつかの研究では、ImageNet データセットと Places365 データセットでトレーニングされた畳み込みネットワークの初期層を交換できることがわかり、これらのネットワークが同様の初期視覚表現を学習したことを示しています。多数の「ロゼッタ ニューロン」、つまり、さまざまな視覚モデルで非常に類似した活性化パターンを持つニューロンを発見した研究もあります... 2. モデルのサイズとパフォーマンスが大きいほど、表現は良くなります。アライメントが高くなるほど。 で相互最近傍法を使用して 78 個のモデル のアライメントを測定し、視覚タスク適応ベンチマーク VTAB で下流タスクのパフォーマンスを評価しました。 3. さまざまなモードでのモデル表現の収束。 4. モデルと脳の表現も、おそらく同様のデータとタスクの制約に直面しているため、ある程度の一貫性を示しています。 5. モデル表現の整合度は、下流タスクのパフォーマンスと正の相関があります。 (常識推論) と GSM8K (数学) という 2 つのダウンストリーム タスクを使用してモデルのパフォーマンスを評価しました。また、DINOv2 モデルを参照として使用して、他の言語モデルとビジュアル モデルの整合性を測定します。 1. タスク一般性による収束 (タスク一般性による収束) 同様の原理が以前に提案されており、図は次のとおりです。 さらに、簡単なタスクには複数の解決策がありますが、難しいタスクには少数の解決策があります。したがって、タスクの難易度が上がるにつれて、モデルの表現はより良い、より少ない解決策に収束する傾向があります。 2. モデル容量が収束につながる (モデル容量による収束) 研究者らは、全体的に最適な表現がある場合、十分なデータの条件下では、より大きなモデルが得られると指摘しました。より効率的にこの最適解に近づく可能性があります。 したがって、同じトレーニング目標を使用する大規模なモデルは、そのアーキテクチャに関係なく、この最適なソリューションに収束する傾向があります。異なるトレーニング目標に同様の最小値がある場合、より大きなモデルの方がこれらの最小値を見つけるのがより効率的であり、トレーニング タスク全体で同様の解が得られる傾向があります。 図は次のとおりです: 3. 単純性バイアスによる収束 (単純性バイアスによる収束) 収束の理由について、研究者らは仮説も提案しました。深いネットワークでは、データへの単純な適合を求める傾向があり、この固有の単純性バイアスにより、大規模なモデルの表現が単純化される傾向があり、収束につながります。 つまり、大きなモデルはより広い範囲をカバーし、すべての可能な方法で同じデータを当てはめることができます。ただし、深いネットワークの暗黙的な単純さの優先により、大規模なモデルはこれらのソリューションの中で最も単純なものを見つけることが奨励されます。 一連の分析と実験の後、冒頭で述べたように、研究者たちはプラトン表現仮説を提案し、この収束の終点について推測しました。 つまり、異なる AI モデルは、異なるデータとターゲットでトレーニングされていますが、その表現空間は、私たちが観察するデータを生成する現実世界を表す共通の統計モデルに収束しています。 彼らはまず、理想化された離散事象世界モデルを構築しました。世界には一連の離散イベント Z が含まれており、各イベントは未知の分布 P(Z) からサンプリングされます。各イベントは、ピクセル、サウンド、テキストなどの観察関数 obs を通じてさまざまな方法で観察できます。 次に、著者は、fX(xa) と fX(xb) の内積が xa に近似し、) の対数オッズと対数の比率を近似するような表現 fX を学習しようとする対照学習アルゴリズムのクラスを検討します。負のサンプルペア (ランダムにサンプリングされた) としての のオッズ。 (PMI) カーネルの表現であるカーネル関数に収束することを著者は発見しました。 fX. 研究者らは、色に関する実証研究を通じてこの理論を検証しました。色の表現が画像のピクセル共起統計から学習されるか、テキストの単語共起統計から学習されるかに関係なく、結果として得られる色の距離は人間の知覚に似ており、モデルのサイズが大きくなるにつれて、この類似性はますます高くなります。 これは理論分析と一致しています。つまり、モデル能力が向上すると、観測データの統計をより正確にモデル化でき、それによって理想的なイベント表現により近い PMI カーネルが得られます。 論文の最後で、著者は AI の分野に対する表現の収束の潜在的な影響と将来の研究の方向性、およびプラトン的表現の仮定に対する潜在的な制限と例外をまとめています。 彼らは、モデルのサイズが大きくなるにつれて、表現の収束によって次のような影響が考えられるが、これらに限定されないことを指摘しました。 上記の影響の前提は、実際の世界の統計法則を反映する表現に真に収束するには、将来のモデルのトレーニング データが十分に多様で、ロスレスでなければならないということであると著者は強調しています。 同時に、著者は、異なるモダリティのデータには固有の情報が含まれている可能性があり、モデルのサイズが大きくなっても完全な表現の収束を達成することが困難になる可能性があるとも述べています。さらに、現在、すべての表現が収束しているわけではありません。たとえば、ロボット工学の分野では状態を表現する標準化された方法がありません。研究者やコミュニティの好みにより、モデルが人間の表現に収束し、それによって他の可能な形態の知性が無視される可能性があります。 そして、特定のタスクのために特別に設計されたインテリジェント システムは、一般的なインテリジェンスと同じ表現に収束しない可能性があります。 著者らはまた、表現の整合性を測定する方法には議論の余地があり、異なる測定方法は異なる結論につながる可能性があることも強調しています。たとえ異なるモデルの表現が類似していたとしても、ギャップは説明の余地があり、現時点ではこのギャップが重要かどうかを判断することは不可能です。 詳細と議論方法については、ここに論文を投稿します~ 論文リンク: https://arxiv.org/abs/2405.07987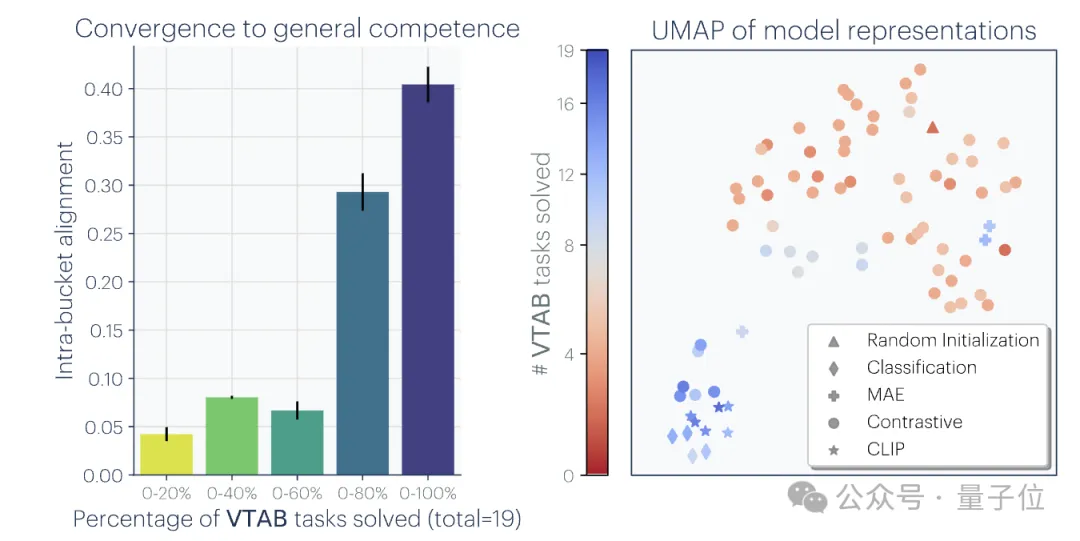






収束の終点




最後にいくつかの考え
以上が仕事を辞めた後のイリヤの最初の行動: この論文が気に入ったので、ネチズンは急いで読みましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7315
7315
 9
1625
14
1348
46
1261
25
1208
29
9
1625
14
1348
46
1261
25
1208
29

 オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!

 超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
 こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
 Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります

 Kuaishou バージョンの Sora「Ke Ling」がテスト用に公開されています。120 秒以上のビデオを生成し、物理学をより深く理解し、複雑な動きを正確にモデル化できます。
Jun 11, 2024 am 09:51 AM
Kuaishou バージョンの Sora「Ke Ling」がテスト用に公開されています。120 秒以上のビデオを生成し、物理学をより深く理解し、複雑な動きを正確にモデル化できます。
Jun 11, 2024 am 09:51 AM
Kuaishou バージョンの Sora「Ke Ling」がテスト用に公開されています。120 秒以上のビデオを生成し、物理学をより深く理解し、複雑な動きを正確にモデル化できます。
 アメリカ空軍が初のAI戦闘機を公開し注目を集める!大臣はプロセス全体を通じて干渉することなく個人的にテストを実施し、10万行のコードが21回にわたってテストされました。
May 07, 2024 pm 05:00 PM
アメリカ空軍が初のAI戦闘機を公開し注目を集める!大臣はプロセス全体を通じて干渉することなく個人的にテストを実施し、10万行のコードが21回にわたってテストされました。
May 07, 2024 pm 05:00 PM
アメリカ空軍が初のAI戦闘機を公開し注目を集める!大臣はプロセス全体を通じて干渉することなく個人的にテストを実施し、10万行のコードが21回にわたってテストされました。
