

産業ナレッジグラフの高度な実践

1. 背景の紹介
まず、Yunwen Technologyの開発の歴史をご紹介します。

Yunwen Technology Company...
2023 年は、大規模モデルが普及した後、情報システムが研究される前にグラフの重要性が大幅に低下したと考えられています。もう重要ではありません。しかし、RAG の推進とデータ ガバナンスの普及により、より効率的なデータ ガバナンスと高品質のデータが民営化された大規模モデルの有効性を向上させるための重要な前提条件であることがわかり、ますます多くの企業が注目し始めています。知識構築関連コンテンツへ。これにより、知識の構築と処理がより高いレベルに促進され、探索できる技術や方法が数多く存在します。新しいテクノロジーの出現がすべての古いテクノロジーを打ち破るわけではないことがわかります。また、新しいテクノロジーと古いテクノロジーを相互に統合することで、より良い結果が達成される可能性もあります。私たちは巨人の肩の上に立ち、拡大し続けなければなりません。
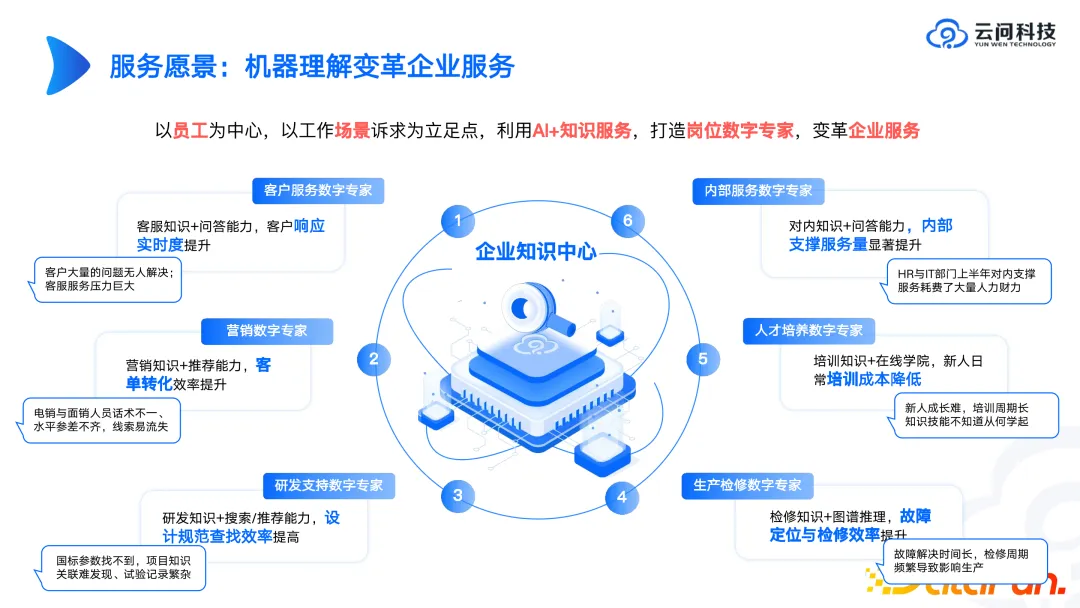
Yunwen Technology がエンタープライズ ナレッジ センターに焦点を当てているのはなぜですか?過去の事例で、リスク管理や薬物検査などの多くの複雑なシナリオに直面した場合、短期間で理想的な結果を達成し、標準化された製品を提供することは困難であることが判明したためです。エンタープライズナレッジマネジメントやオフィス関連のビジネス管理シナリオでは、比較的迅速に試行を開始でき、理想的な結果が得られる場合があります。したがって、今年、企業と協力して大規模な民営化モデルを構築する際には、企業知識管理に基づく質疑応答や検索などの企業知識管理を主要テーマに含める予定です。企業にとって、独自の民営化された知識とナレッジセンターの構築は非常に重要です。
これらの理由に基づいて、知識グラフの方向性を研究したい友人がいる場合、私たちの提案は、知識のライフサイクル全体を考慮し、解決すべき問題と具体的な着地点を考えることです。たとえば、一部の企業では、既存のドキュメントを使用して試験、トレーニング、面接に関連するコンテンツを生成していますが、このような技術的なホットワードは非常に注目されていますが、このようなシナリオでは GPT3.5 や GPT4 よりも効果的です。プリプロダクションが完了しました。したがって、今後の開発では、より専門的で洗練されたモデルが大きなトレンドになると考えています。
2. 地図プロダクトフォーム
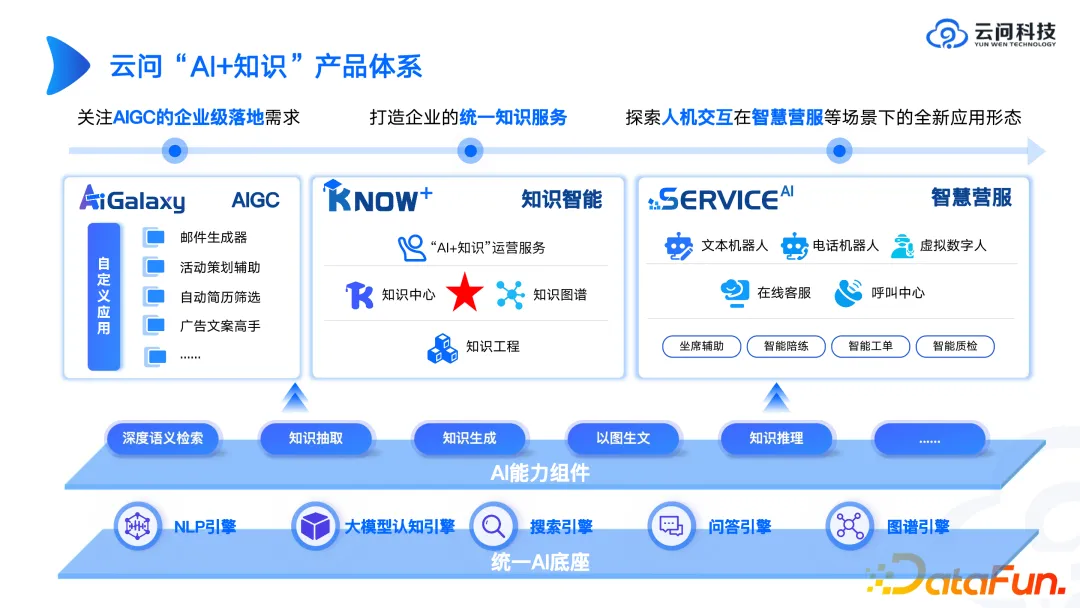
上記の背景では、地図プロダクトフォームはどのようになりますか?次に、Yunwen Technologyの「AI + 知識」製品システムを例として紹介します。
まず第一に、統合された AI ベースが必要です。これは 1 つのチームや 1 つの企業で行うことはできません。多くの場合、大規模なモデル エンジンのサードパーティ API または SDK を使用できます。構築に数か月かかったホイールはオープン エンジンほど効果的ではない可能性があるため、ホイールを最初から構築する必要はありません。発売されたばかりのソースモデル。したがって、AI ベースの部分については、サードパーティのテクノロジーをどのように組み合わせるかをより検討することをお勧めします。もちろん、それを最大限に活用するのが最善です。プラットフォームの価値を考慮し、両方を考慮してください。
AI 機能コンポーネントに関しては、いくつかの納品経験から、これらの AI 機能コンポーネントは製品よりもよく売れる傾向があることがわかりました。なぜなら、多くの企業は、専門のテクノロジー企業が構築したコンポーネントを使用して、独自の上位層アプリケーションを構築したいと考えているからです。ビッグモデルの時代において、AI 機能コンポーネントを販売することはシャベルを販売するようなものであり、金鉱山は依然として大企業自身によって採掘されています。
上位層アプリケーションに関しては、AIGC独自のアプリケーション、ナレッジインテリジェンス、インテリジェントビジネスサービスの3つの方向から実装していきます。どの方向に価値が高まるかを検討します。ナレッジ グラフは、ナレッジ インテリジェンス全体のコア リンクとして分類されます。ナレッジ グラフは中核ですが、唯一のものではないことに注意してください。私たちはこれまでに多くのシナリオに遭遇しました。顧客は多数のリレーショナル データベースと多数の非構造化ドキュメントを所有しており、これらすべての知識システムと知識資産をナレッジ グラフに組み込むことができるようにしたいと考えています。私たちは、将来の知識アーキテクチャは異種混合であるべきだと考えています。一部の知識はドキュメント内にあり、一部の知識はグラフ ネットワークから得られる可能性があります。最終的に、大規模なモデルが行う必要があるのは、複数の知識に基づくことです。ソースヘテロジニアス 構造データの包括的な分析。たとえば、インテリジェンスは、リレーショナル データベースから数値指標を抽出し、文書内で提案を見つけ、作業指示書から履歴情報を検索し、すべての内容を分析のためにまとめます。これが、大規模なモデルとナレッジ グラフの組み合わせをどのように考えるかです。アーキテクチャ全体では、大規模なモデルが最終分析を行い、ナレッジ グラフは、大規模なモデルが知識表現システムを通じてその背後に隠された知識をより迅速かつ正確に見つけるのに役立ちます。
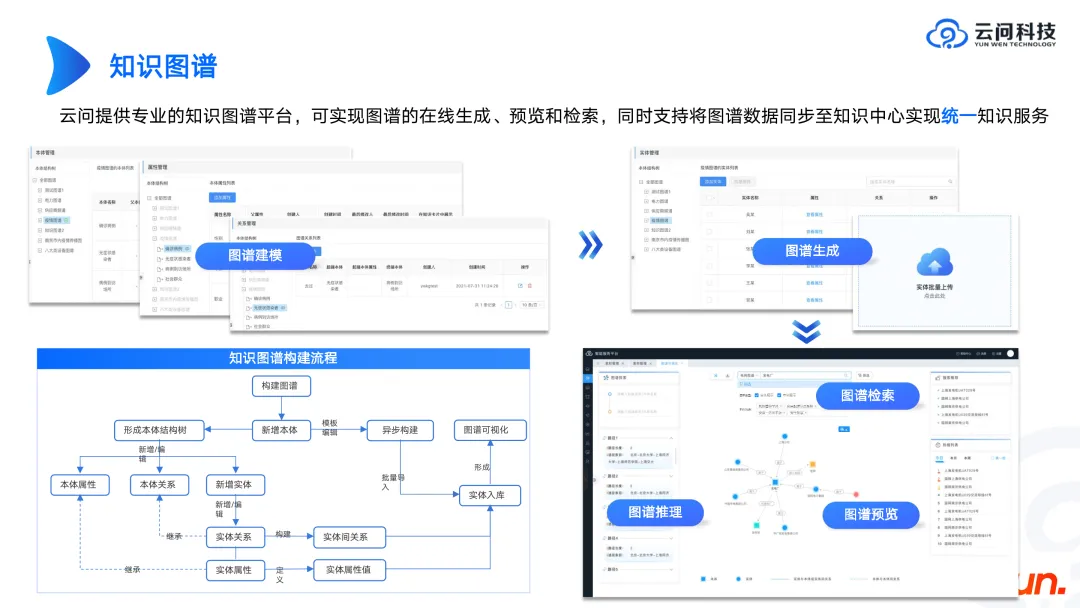
大きなモデルとマップの関係については以前に説明しました。次に、マップ自体に必要なものを確認しましょう。
まず、グラフの背後にあるのは、オープンソースの Neo4j、Genius Graph、およびいくつかの国内データベース ブランドなどのグラフ データベースです。ナレッジ グラフとグラフ データベースは 2 つの異なる概念です。ナレッジ グラフ製品の作成は、グラフ データベースの上位層をカプセル化して、迅速なグラフ モデリングと視覚化を実現することと同じです。
ナレッジグラフ製品を作成したい場合、まずNeo4jの製品形態や国内大手メーカーのナレッジグラフ製品を参照すると、ナレッジグラフ製品にどのような機能や連携が必要なのかを大まかに理解することができます。実装する。さらに重要なのは、ナレッジ グラフを構築する方法を知ることです。企業やシナリオが異なればグラフも異なるため、これはビジネス上の問題であると考えられます。技術者として、電気、設備、産業などを理解していなければ、ビジネスが満足するマップを構築することはできません。最終的に結果を得るには、ビジネスとの継続的なコミュニケーションと継続的な反復が必要です。議論のプロセスは実際にスキーマの本質に立ち返り、一連の存在論理論とスキーマの論理概念を提示することができます。これらの内容は非常に重要です。スキーマが完成したら、より多くの関係者を関与させてコンテンツを充実させ、製品をさらに改善することができます。これまでの経験をいくつかご紹介します。

以下は、マップの全体的な特徴の紹介です。現在、ナレッジ グラフは依然として主にトリプルに基づいており、これに基づいて、エンティティ、属性、関係などの複数の粒度および複数レベルの意味関係が構築されます。産業界では、セットされたエンティティ属性値を使用して実際の物理世界を記述すると、多くの問題が発生します。このとき、CVTという形で制約条件を実装します。したがって、ナレッジ グラフを構築するときは、全員がまずトリプルで現在の問題を解決できることを実証する必要があります。
一つ注意しなければならないのは、世界は無限であり、そこに含まれる知識の内容も無限であるため、地図を構築する際には必要に応じて構築する必要があるということです。最初は、物理世界に存在するすべてのエンティティをコンピューターの世界に描写するというビジョンを抱くことがよくあります。これの問題は、最終的に構築されるスキーマ全体が複雑すぎて、実際のビジネスには役に立たないことです。たとえば、地球が太陽の周りを回っているという事実を、三重に構成することができます。ただし、このトリプレットでは現在直面している実際の問題を解決できないため、必要に応じてトリプレットを構築する必要があります。
それでは、常識的な質問にどう対処すればよいのでしょうか?多くの質問には常識のトリプルが必要です。これは大手モデルに任せてもいいと思います。また、ナレッジ グラフによってプロフェッショナリズムを探求し、真に関連性のある知識をグラフに構築できることを期待しています。次に、大規模なモデルを常識に基づいて、オープンフィールドでは取得できないナレッジ グラフによって提供される事前知識と組み合わせることで、より良い結果を達成できます。

ナレッジグラフの構築には、オントロジー、関係性、属性とエンティティの定義、およびそれを視覚化する方法を含む、ビジネス担当者と運用担当者が共同で設計する必要があります。最終的には、プロダクトの形でユーザーにどのようなコンテンツを提示するかという問題に関わってきます。ユーザーが最終消費者の場合、表示する必要があるのは視覚的な検索と Q&A のみです。このタイプの顧客は、地図が自動化されているか手動で構築されているかを気にしないからです。
ここにはもう 1 つの非常に重要な問題が関係しています。つまり、大規模なモデル シナリオであっても、すべてのマップを自動的に構築できるわけではありません。グラフの構築コストは非常に高くなります。グラフ モデリングに多くのエネルギーを費やすのではなく、消費にエネルギーを費やす必要があります。ビジネスで受け入れられるようにしたい場合は、手動による構築に頼らなければならない場合があります。たとえば、特定の形式のテーブルが複数のテーブルにわたって複雑である場合、大規模なモデルを使用してベースラインを見つけることができます。これにより、エネルギーは建設から消費へと移行します。たとえば、プロジェクト サイクルが 100 日続く場合、マップの構築に 70 日を費やし、最後の 30 日はこのマップの適用シナリオを考えるのに費やします。または、初期の構築時間が延長されるため、価値ある消費シナリオを考えてみましょう。大きな疑問が生まれます。私たちの経験では、構築に少しの時間を費やすか、デフォルトで手動構築を行うべきです。次に、構築されたマップの価値を最大化する方法を考えるのに多くの時間を費やします。

上の図は、ナレッジグラフを構築するプロセスを示しています。オントロジーを構築するときは、データベース自体のテーブル構造も更新される可能性があるのと同様に、オントロジーが変更されることを受け入れる必要があります。したがって、設計する際には、堅牢性と拡張性を必ず考慮してください。たとえば、ある種類の機器のマップを作成する場合、機器システム全体を考慮する必要があります。将来的には、このシステムを通じてデバイスを検索する必要が生じる可能性があります。また、このシステムの下にある他のデバイスはまだマップを構築しておらず、将来構築される可能性があることも理解する必要があります。大規模システム全体を通じて、ユーザーにさらなる価値をもたらします。
よくある質問は、FAQ や大きなモデルから答えを見つけることができるのに、なぜマップを使用する必要があるのですか?というものです。私たちの答えは、現在の知識を地図に関連付ければ、私たちが見ている世界はもはや一次元ではなく、ネットワーク化された世界になるということです。これは地図が消費者側で実現できる価値であり、達成するのは困難です。他のテクノロジーを使用して。現在、その大きさや使用されている高度なアルゴリズムに注目が集まりがちですが、実際には、消費と問題解決の観点からグラフの構築を考える必要があります。

大規模なモデルが普及している現在、大規模なモデルとグラフの組み合わせを考慮する必要があります。グラフは上位層のアプリケーションであり、大規模なモデルは基礎的な機能であると考えることができます。大規模なモデルがさまざまなシナリオからマップにどのような助けをもたらすかを理解できます。
グラフを構築する際、元の UIE、NER、およびその他の関連技術を置き換えるためのいくつかのドキュメントとプロンプトワードを通じて情報抽出を実行でき、それによって抽出能力がさらに向上します。また、ゼロショット、少数ショット、十分なデータ トレーニングの場合、大規模なモデルと小規模なモデルのどちらが優れているのかも考慮する必要があります。この種の質問に対する唯一の答えはなく、さまざまなシナリオやさまざまなデータセットに対してさまざまなソリューションがあります。これは知識構築の全く新しい道です。現時点では、ゼロショット シナリオでは、大規模なモデルの方が優れた抽出機能を備えています。ただし、サンプルサイズが大きくなると、コストパフォーマンスや推論速度の点で小型モデルの方が有利になります。
消費者側では、企業が特定のポリシーを満たすことができるかどうか、ポリシーに記載されている利点を享受できるかどうかなど、政策判断などの推論問題を解決するためにグラフが使用されます。従来は、グラフ、ルール、ステートメント式によって判断していました。現在のアプローチは Graph RAG に似ており、ユーザーの質問を使用して現在の企業に類似したトリプルまたはタプルを見つけ、大規模なモデルを使用して回答を得て結論を導き出します。したがって、多くのグラフ推論問題とグラフ構築問題は、大規模モデル技術によって解決できます。
グラフ ストレージの観点では、グラフ データベースのデータ構造とグラフ自体が非常に重要です。大規模なモデルは短期的には長いテキストやグラフ全体を処理できないため、グラフ ストレージは非常に重要な方向性です。ベクトル データベースと同様に、これは将来の大規模モデル エコシステムにおいて非常に重要なコンポーネントとなるでしょう。上位層のアプリケーションは、実際の問題を解決するためにこのコンポーネントを使用するかどうかを決定します。

グラフの視覚化はフロントエンドの問題であり、シナリオと解決すべき問題に従って設計する必要があります。また、このテクノロジーが、モバイル端末、PC、ハンドヘルドデバイスなど、将来のさまざまなインタラクション形式に対応する特定の機能を提供するためのミドルプラットフォームとして使用できることを期待しています。構造を提供するだけでよく、フロントエンドがどのようにレンダリングして表示するかは、実際のニーズに基づいて決定できます。大規模なモデルも、そのような構造を呼び出す方法になります。大規模なモデルまたはエージェントが要件に基づいてグラフを呼び出す方法を決定できる場合、閉ループを開くことができます。将来的には、さまざまなアプリケーションからの呼び出しに適応できるように、Graph はより優れた API をカプセル化できる必要があります。ミドルプラットフォームの概念は、独立した分離されたサービスをすべての関係者がより広く使用できるようになりつつあります。
たとえば、ドキュメント内のテーブルに残っている特定の値を検索する必要がある場合、コンテンツを表示するためにグラフの構造機能を使用する場合、その場所を見つけるのは困難です。 、アプリケーション システムのインターフェイスを呼び出すことでこのマップの値を取得し、それが配置されているドキュメント、または大規模なモデルの解析結果を表示できます。この視覚化方法は、ユーザーにとって最も効率的です。これは、現在一般的な Copilot 手法でもあり、マップ、検索、またはその他のアプリケーション機能を呼び出して共同で問題を解決し、最後に大規模なモデルを使用して「ラスト マイル」を生成して効率を向上させます。

現在、私たちはナレッジベースとグラフのさまざまな統合を頻繁に行っています。今年は多くのナレッジプロジェクトが登場しています。以前は、知識は主に検索と消費のために利用できました。大規模モデルの出現により、知識を大規模モデルに提供して消費できることに誰もが気づきました。したがって、誰もが知識の貢献と構築により多くの注意を払っています。私たち自身も多くの知識を持っていますが、私たちの知識は構造化されていないため、サードパーティのナレッジ グラフ システムも必要です。また、作業指示や設備メンテナンスのケースなど、非常に重要な知識がたくさんあるため、この知識を構造化コンテンツに転送する必要があります。このコンテンツは以前は検索に使用されていましたが、大規模モデルの SFT に使用できるようになりました。
ナレッジベースとグラフは当然組み合わせ可能であり、組み合わせることで一連のナレッジサービス製品を外部に提供できます。このナレッジ サービス製品の生命力は非常に強く、OA、ERP、MIS、PRM システムのいずれにおいてもナレッジに対する需要が存在します。
統合する際には、知識とデータをどのように区別するかに細心の注意を払う必要があります。顧客は大量のデータを提供しますが、このデータは知識ではない可能性があります。需要側から知識を定義する必要があります。例えば、ある装置であれば、その装置が稼働しているときのデータの変動など、通常知りたいことはすべてデータであり、その装置の工場出荷時刻や最終メンテナンス時刻などは知識です。知識をどのように定義するかは非常に重要であり、企業の参加と指導を得て共同で構築する必要があります。
3. Industrial Graph Advanced

デジタル変革のプロセスでは、スケジュール、設備、マーケティング、分析などのシナリオで AI およびグラフ技術が使用されます。特に派遣シナリオにおいては、交通派遣であってもエネルギー派遣であっても人材派遣であっても、すべて業務配分の形で行われます。たとえば、火災が発生した場合、何人の人、車両などを派遣する必要がありますか? スケジュールを設定するときに、いくつかの関連データをクエリする必要があります。 現在の問題は、多くの場合、結果が見つからないことではなく、コンテンツが多すぎることです。が返されますが、本当に有用な解決策は提供されません。キーワード検索では知識の消費が残っているため、「fire」という単語を含むすべての文書が表示されます。より適切にプレゼンテーションするには、グラフを使用できます。たとえば、「火」のオントロジーを設計する場合、その上位のオントロジーは災害である「火」というエンティティに対して、その予防策、防御策、経験事例を設計できます。これらのコンテンツを通じて知識を分割します。このようにして、ユーザーが「fire」と入力すると、関連するマップのコンテキストと次に何をすべきかが表示されます。
関連のシナリオをスケジュールする際には、エージェントの指示に注意を払う必要があります。スケジューリング自体はマルチタスクのシナリオであるため、エージェントはスケジューリングにとって非常に重要です。マップによって返される結果は、より正確かつ豊富になります。
スマートデバイス向けのアプリケーションシナリオも多数あります。設備情報は、たとえば、工場情報は製品マニュアルに、メンテナンス情報は保守作業指示書に、稼働状況は設備管理システムに、検査状況は産業検査システムに保管されます。 。業界が直面している大きな問題は、システムが多すぎることです。デバイスの情報をクエリする場合は、複数のシステムからクエリを実行する必要がありますが、これらのシステム内のデータは相互に接続されていません。現時点では、接続を開いてすべてのコンテンツを関連付けてマッピングできるシステムが必要です。ナレッジグラフを核としたナレッジベースは、この問題を解決できます。
ナレッジグラフには、オントロジーを通じて関連する属性、フィールド、フィールドソースなどを含めることができ、さまざまなシステム間の直列および並列関係を下から記述して関連付けることができます。ただし、グラフを構築するときは、それに応じてグラフを設計および構築する必要があることに留意してください。多くの企業がマップを構築するとき、D2R テクノロジーを介してデータ センターからすべてのデータを転送します。このマップには実際には意味がありません。マップを構築するときは、動的マップと静的マップの関係を考慮する必要があります。
インテリジェント マーケティングとマルチシナリオ エネルギー AI の分野にも多くのアプリケーション シナリオと設計手法がありますが、ここでは説明せず、後で説明します。

グラフを構築するとき、アーキテクチャ設計は非常に重要です。基礎となるライブラリとプロセスをグラフの構築と利用と統合する方法。最終的にどのように提供するかについては、考慮すべき詳細がたくさんあります。設計と実践については、上の図にリストされているリンクを参照してください。
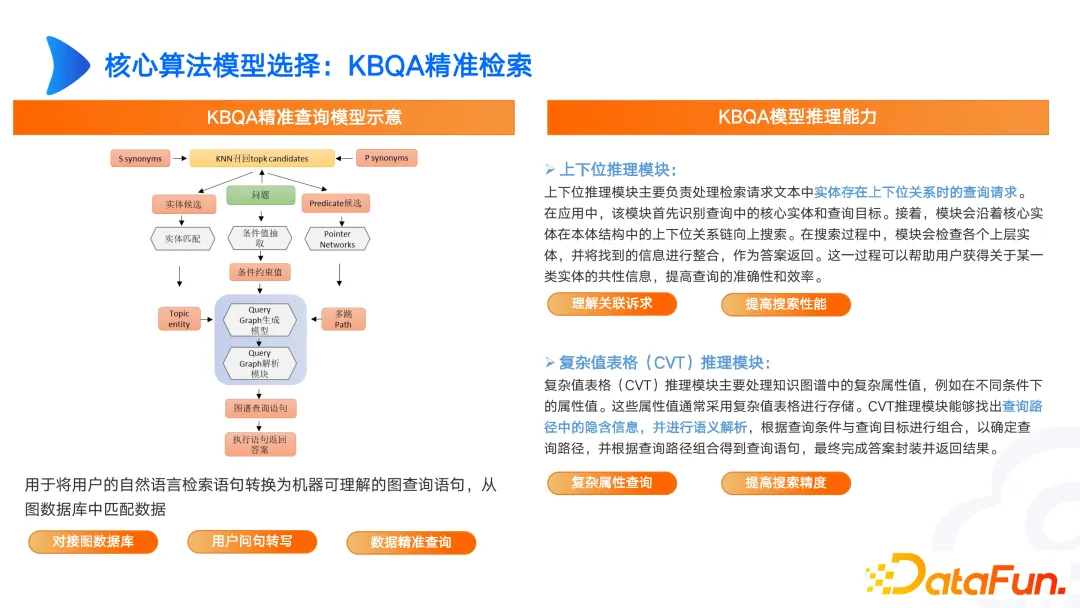
また、上位ビットと下位ビット、グラフCVTクエリなど、グラフKBQAでいくつかの研究を行いました。たとえば、医療シナリオでは、発熱と頭痛は身体の異常な表現に関連付けられますが、元のドキュメントでは、それらは軽微な身体的異常として格納されます。ユーザーの表現と専門的な表現の間に差異がある場合、優劣推論 CVT を通じてそれを解決できます。
現在構築されているグラフは、SPO、マルチホップ、TransE などのエンティティ アラインメントのみである可能性があります。ただし、実際の複雑なシナリオでは、CVT を上下のポジションと組み合わせて実装する必要があります。英語のデータセットでは非常に優れた結果を示している論文も数多くありますが、中国語のデータセットでは理想的な結果は得られません。したがって、私たちは独自のニーズに基づいて設計し、良い結果を達成するために継続的に反復する必要があります。
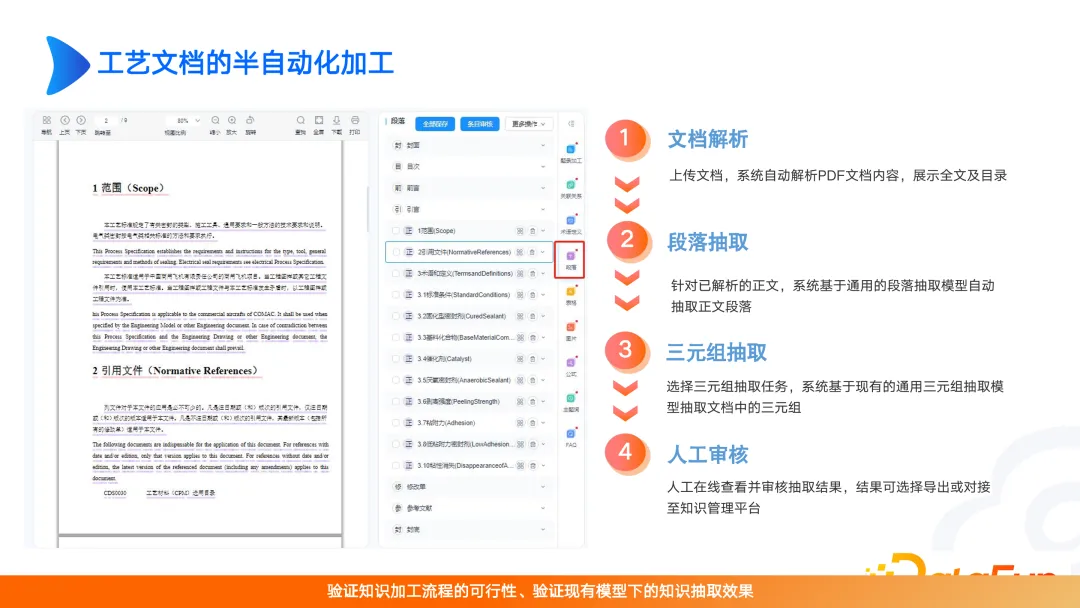
文書の解析、段落抽出、トリプル抽出、手動レビューなどの半自動文書処理。手動レビューのこのステップは無視されることが多く、特に大規模なモデルが登場した後は、手動レビューに注意が払われなくなります。実際、データ処理とデータガバナンスが行われると、モデル効果は大幅に向上します。したがって、最終的に解決したいシナリオは高い価値を持っている必要があることを考慮する必要があり、マップの構築や大規模モデルの最適化など、リソースがどこに投資されるかにも注意を払う必要があります。これらの考慮事項を考慮しないと、製品は簡単に交換されたり、問題が発生したりしてしまいます。

上の写真はYunwen Technologyのデバイスライフサイクル管理製品を示しています。このようなシナリオは、さまざまなシナリオでの軽量の中間モジュールと上位層のアプリケーション構築を通じて実現されます。これらのモジュールの活力は、ナレッジ グラフ システム自体の活力よりもはるかに活発です。スタンドアロンまたはミドルウェアのみを販売することは、グラフ分野、特に産業シナリオには適していません。多くの産業上の問題は、顧客の観点から見ると非常に複雑であり、図や大規模なモデルでは解決できません。私たちがやるべきことは、効果からお客様を納得していただくことです。

産業のインテリジェント変革の過程では、研究開発と設計、生産管理、供給管理、販売前マーケティング、総合サービスにおいて多くの応用ポイントがあります。

上の写真は、欠陥のある機器マップの適用シナリオの例です。このシナリオでは、機器の稼働状況やリレーショナル データベースの単純なデータなど、すべてのグラフ要素が含まれているわけではありません。設備のメンテナンスでは、主に 3 種類のデータが重要であると考えています。1 つ目は、工場からの出荷時期、製造元、稼働期間などの設備の基本情報です。タイプは、障害の名前、上司と部下、そのような障害、どのような障害が発生するか、どのようなタイプの障害がどのような種類の障害を引き起こすかなどの障害です。 3 番目のカテゴリは、どのような障害が発生したかを説明する作業指示です。どのような設備。これら 3 種類のデータを接続すると、小さな閉ループ グラフを構築できます。将来的には、動的データに基づいて拡張することもできます。したがって、グラフを作成するときは、閉ループ シーンを含む小さくて美しいグラフを作成することを好みます。やみくもに高いレベルを追求しても消費者のニーズに応えられない地図ではありません。
したがって、産業ナレッジグラフを構築するときは、より良い実装と応用を達成するために、特定のシナリオから始めて、シナリオの要件を分析してグラフを構築する必要があります。
以上が産業ナレッジグラフの高度な実践の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1667
1667
 14
1426
52
1328
25
1273
29
1255
24
14
1426
52
1328
25
1273
29
1255
24

 ビッグモデルアプリ Tencent Yuanbao がオンラインになりました! Hunyuan がアップグレードされ、どこにでも持ち運べるオールラウンドな AI アシスタントが作成されました
Jun 09, 2024 pm 10:38 PM
ビッグモデルアプリ Tencent Yuanbao がオンラインになりました! Hunyuan がアップグレードされ、どこにでも持ち運べるオールラウンドな AI アシスタントが作成されました
Jun 09, 2024 pm 10:38 PM
5月30日、TencentはHunyuanモデルの包括的なアップグレードを発表し、Hunyuanモデルに基づくアプリ「Tencent Yuanbao」が正式にリリースされ、AppleおよびAndroidアプリストアからダウンロードできるようになりました。前のテスト段階のフンユアン アプレット バージョンと比較して、Tencent Yuanbao は、日常生活シナリオ向けの AI 検索、AI サマリー、AI ライティングなどのコア機能を提供し、Yuanbao のゲームプレイもより豊富で、複数の機能を提供します。 、パーソナルエージェントの作成などの新しいゲームプレイ方法が追加されます。 Tencent Cloud 副社長で Tencent Hunyuan 大型モデルの責任者である Liu Yuhong 氏は、「テンセントは、最初に大型モデルを開発しようとはしません。」と述べました。 Tencent Hunyuan の大型モデルは、ビジネス シナリオにおける豊富で大規模なポーランド テクノロジーを活用しながら、ユーザーの真のニーズを洞察します。
 Bytedance Beanbao 大型モデルがリリース、Volcano Engine フルスタック AI サービスが企業のインテリジェントな変革を支援
Jun 05, 2024 pm 07:59 PM
Bytedance Beanbao 大型モデルがリリース、Volcano Engine フルスタック AI サービスが企業のインテリジェントな変革を支援
Jun 05, 2024 pm 07:59 PM
Volcano Engine の社長である Tan Dai 氏は、大規模モデルを実装したい企業は、モデルの有効性、推論コスト、実装の難易度という 3 つの重要な課題に直面していると述べました。複雑な問題を解決するためのサポートとして、適切な基本的な大規模モデルが必要です。また、サービスは低コストの推論を備えているため、大規模なモデルを広く使用できるようになり、企業がシナリオを実装できるようにするためには、より多くのツール、プラットフォーム、アプリケーションが必要になります。 ——Huoshan Engine 01 社長、Tan Dai 氏。大きなビーンバッグ モデルがデビューし、頻繁に使用されています。モデル効果を磨き上げることは、AI の実装における最も重要な課題です。 Tan Dai 氏は、良いモデルは大量に使用することでのみ磨かれると指摘しました。現在、Doubao モデルは毎日 1,200 億トークンのテキストを処理し、3,000 万枚の画像を生成しています。企業による大規模モデルシナリオの実装を支援するために、バイトダンスが独自に開発した豆包大規模モデルが火山を通じて打ち上げられます。
 NVIDIA の大規模モデル推論フレームワークを明らかにする: TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
NVIDIA の大規模モデル推論フレームワークを明らかにする: TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
1. TensorRT-LLM の製品位置付け TensorRT-LLM は、NVIDIA が開発した大規模言語モデル (LLM) 向けのスケーラブルな推論ソリューションです。 TensorRT 深層学習コンパイル フレームワークに基づいて計算グラフを構築、コンパイル、実行し、FastTransformer の効率的なカーネル実装を利用します。さらに、デバイス間の通信には NCCL を利用します。開発者は、カットラスに基づいてカスタマイズされた GEMM を開発するなど、技術開発や需要の違いに基づいて特定のニーズを満たすためにオペレーターをカスタマイズできます。 TensorRT-LLM は、NVIDIA の公式推論ソリューションであり、高いパフォーマンスを提供し、実用性を継続的に向上させることに尽力しています。 TensorRT-LL
 産業ナレッジグラフの高度な実践
Jun 13, 2024 am 11:59 AM
産業ナレッジグラフの高度な実践
Jun 13, 2024 am 11:59 AM
1. 背景の紹介 まず、Yunwen Technology の開発の歴史を紹介します。 Yunwen Technology Company ...2023 年は大規模モデルが普及する時期であり、多くの企業は大規模モデルの後、グラフの重要性が大幅に低下し、以前に検討されたプリセット情報システムはもはや重要ではないと考えています。しかし、RAG の推進とデータ ガバナンスの普及により、より効率的なデータ ガバナンスと高品質のデータが民営化された大規模モデルの有効性を向上させるための重要な前提条件であることがわかり、ますます多くの企業が注目し始めています。知識構築関連コンテンツへ。これにより、知識の構築と処理がより高いレベルに促進され、探索できる技術や方法が数多く存在します。新しいテクノロジーの出現によってすべての古いテクノロジーが打ち破られるわけではなく、新旧のテクノロジーが統合される可能性があることがわかります。
 GPT-4をベンチマーク!中国移動の九天大型モデルが二重登録を通過
Apr 04, 2024 am 09:31 AM
GPT-4をベンチマーク!中国移動の九天大型モデルが二重登録を通過
Apr 04, 2024 am 09:31 AM
4月4日のニュースによると、中国サイバースペース局は最近、登録された大型モデルのリストを発表し、その中にチャイナモバイルの「九天自然言語インタラクション大型モデル」が含まれており、チャイナモバイルの九天AI大型モデルが生成人工言語を正式に提供できることを示した。外部世界への諜報機関。チャイナモバイルは、これは中央企業が開発した初めての大規模モデルであり、国家の「生成人工知能サービス登録」と「国内深層合成サービスアルゴリズム登録」の二重登録を通過したと述べた。報告によると、Juiutian の自然言語インタラクション大規模モデルは、強化された業界能力、セキュリティ、信頼性の特徴を持ち、フルスタック ローカリゼーションをサポートしており、90 億、139 億、570 億、1000 億などのさまざまなパラメータ バージョンを形成しており、クラウド、エッジ、エンドでは状況が異なりますが、柔軟に導入できます。
 GPT ストアはオープンすることさえできません。なぜこの国内プラットフォームがこのような道を歩むのでしょうか? ?
Apr 19, 2024 pm 09:30 PM
GPT ストアはオープンすることさえできません。なぜこの国内プラットフォームがこのような道を歩むのでしょうか? ?
Apr 19, 2024 pm 09:30 PM
この男性は 1,000 を超える大型モデルを接続し、シームレスに接続して切り替えることができることに注目してください。最近、ビジュアル AI ワークフローが開始されました。直感的なドラッグ アンド ドロップ インターフェイスを提供し、ドラッグ、プル、ドラッグして、無限のキャンバス上に独自のワークフローを配置できます。ことわざにあるように、戦争にはスピードがかかります。Qubit は、この AIWorkflow がオンラインになってから 48 時間以内に、ユーザーがすでに 100 ノードを超える個人ワークフローを構成したと聞きました。早速ですが、今日私が話したいのは、LLMOps 企業である Dify とその CEO の Zhang Luyu についてです。 Zhang Luyu は Dify の創設者でもあります。ビジネスに入社する前は、インターネット業界で 11 年の経験がありました。私は製品設計に携わっており、プロジェクト管理を理解しており、SaaS について独自の洞察を持っています。その後彼は
 新しいテストベンチマークがリリース、最も強力なオープンソースのLlama 3が困惑
Apr 23, 2024 pm 12:13 PM
新しいテストベンチマークがリリース、最も強力なオープンソースのLlama 3が困惑
Apr 23, 2024 pm 12:13 PM
テストの問題が簡単すぎると、上位の生徒も下位の生徒も 90 点を獲得でき、その差は広がりません。Claude3、Llama3、さらには GPT-5 などのより強力なモデルが後にリリースされるため、業界はより困難で差別化されたモデルのベンチマークが緊急に必要です。大型モデルアリーナの背後にある組織 LMSYS は、次世代ベンチマーク Arena-Hard を発表し、広く注目を集めました。 Llama3 命令の 2 つの微調整されたバージョンの強度に関する最新のリファレンスもあります。全員が同様のスコアを持っていた以前の MTBench と比較すると、アリーナとハードの識別は 22.6% から 87.4% に増加し、一目で強くも弱くもなりました。 Arena-Hard は、アリーナからのリアルタイムの人間データを使用して構築されており、人間の好みとの一致率は 89.1% です。
 Shengteng AI テクノロジーを使用した秦嶺・秦川交通モデルは、西安のスマート交通イノベーション センターの構築を支援します
Oct 15, 2023 am 08:17 AM
Shengteng AI テクノロジーを使用した秦嶺・秦川交通モデルは、西安のスマート交通イノベーション センターの構築を支援します
Oct 15, 2023 am 08:17 AM
「高度な複雑性、高度な断片化、およびクロスドメイン」は、輸送業界のデジタル化およびインテリジェントなアップグレードに向かう上で常に主要な問題点でした。最近、チャイナビジョン、西安雁塔区政府、西安未来人工知能コンピューティングセンターが共同で構築したパラメータースケール1000億の「秦嶺・秦川交通モデル」は、スマート交通・交通分野を指向している。西安とその周辺地域にサービスを提供しており、この地域はスマート交通イノベーションの拠点となるでしょう。 「秦嶺・秦川交通モデル」は、オープンシナリオにおける西安の膨大な地元交通生態データ、中国科学ビジョンが自社開発したオリジナルの高度なアルゴリズム、そして西安未来人工知能コンピューティングセンターのShengteng AIの強力なコンピューティング能力を組み合わせたものです。道路網の監視を提供するため、緊急指令、メンテナンス管理、公共交通機関などのスマートな交通シナリオは、デジタルでインテリジェントな変化をもたらします。交通管理には都市ごとに異なる特徴があり、道路の交通状況も異なります。
