

ソフトウェア テクノロジの最前線で、UIUC Zhang Lingming のグループは、BigCode 組織の研究者とともに、最近 StarCoder2-15B-Instruct 大規模コード モデルを発表しました。
この革新的な成果により、コード生成タスクに大きな進歩がもたらされ、CodeLlama-70B-Instruct を上回り、コード生成パフォーマンス リストのトップに到達しました。

StarCoder2-15B-Instruct の独自性は、その純粋な自己調整戦略です。トレーニング プロセス全体がオープンで透明で、完全に自律的で制御可能です。
このモデルは StarCoder2-15B を通じて何千もの命令を生成し、それに応じて StarCoder-15B ベース モデルを微調整します。高価なデータの手動アノテーションに依存する必要も、商用の大規模なデータからデータを取得する必要もありません。 GPT4 などのモデルを使用して、潜在的な著作権の問題を回避します。
HumanEval テストでは、StarCoder2-15B-Instruct が Pass@1 スコア 72.6% で際立っており、CodeLlama-70B-Instruct の 72.0% から改善されました。
LiveCodeBench データセットでの評価では、この自己調整モデルは、GPT-4 で生成されたデータでトレーニングされた同様のモデルをも上回りました。この結果は、外部教師からの大規模モデルの偏った分布に依存することなく、大規模モデルが独自の分布内のデータを使用して人間と同様に位置合わせする方法を効果的に学習できることを示しています。
このプロジェクトの実施の成功には、ノースイースタン大学、カリフォルニア大学バークレー校、ServiceNow、Hugging Face およびその他の機関の Arjun Guha 氏の研究グループからの強力な支援を受けました。
テクノロジーの公開StarCoder2-Instruct のデータ生成プロセスには、主に 3 つのコア ステップが含まれています:
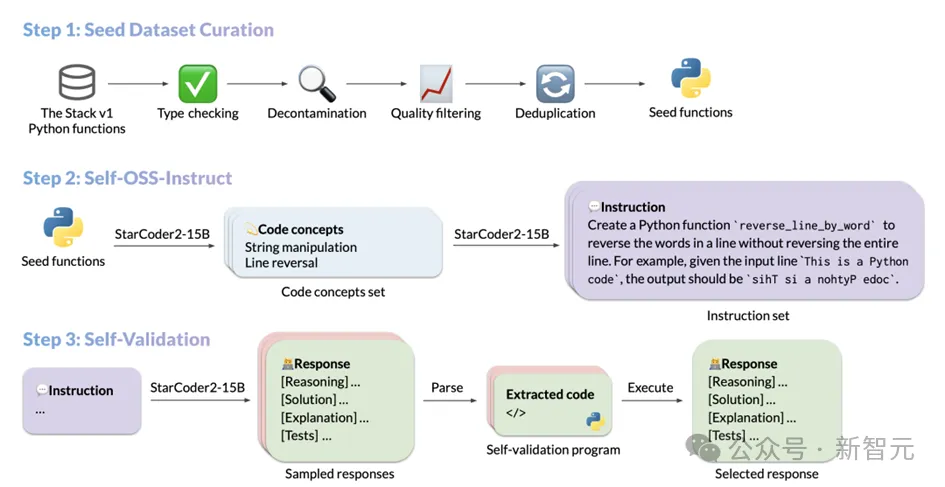
1. シード コード スニペットのコレクション: The Stack のチームv1ライセンスされたソース コードの膨大なコーパスから高品質で多様なシード関数をフィルタリングします。厳密なフィルタリングとスクリーニングを通じて、シード コードの品質と多様性が保証されます。現実的なコードの指示。これらの命令は、データの逆シリアル化からリストの連結、再帰などの幅広いプログラミング シナリオをカバーします。ガイド付き自己検証方法。生成された応答が正確で高品質であることを保証します。
各ステップの具体的な操作は次のとおりです: シードコードスニペットを選択するプロセス
コードモデルの指示に従う能力を向上させるために、モデルは広範囲に公開される必要がありますさまざまなプログラミング原理を実際の操作とともに学びます。 StarCoder2-15B-Instruct は OSS-Instruct からインスピレーションを受けており、オープン ソース コード スニペット、特に The Stack V1 の適切にフォーマットされ明確に構造化された Python シード関数からインスピレーションを得ています。 StarCoder2-15B-Instruct は、基本データ セットを構築する際に、The Stack V1 の詳細な調査を実施し、文書化された手順に従ってすべての Python 関数を選択し、これらの関数に必要な関数を自動的に分析および推論しました。自動インポート関数の依存関係。
データセットの純度と高品質を保証するために、StarCoder2-15B-Instruct は、選択されたすべての関数を慎重にフィルタリングし、スクリーニングしました。
その後、正確な文字列マッチング技術を通じて、評価データセットに関連する可能性のあるコードとヒントが特定され、削除されてデータ汚染が回避されます。ドキュメントの品質に関して、StarCoder2-15B-Instruct は独自のスクリーニング メカニズムを採用しています。
独自の評価機能を使用して 7 つのサンプル プロンプトをモデルに表示し、モデルが各関数のドキュメント品質が基準を満たしているかどうかを判断し、それによってそれを最終データ セットに含めるかどうかを決定します。
モデルの自己判断に基づくこの方法は、データスクリーニングの効率と精度を向上させるだけでなく、データセットの高品質と一貫性も保証します。
最後に、データの冗長性と重複を避けるために、StarCoder2-15B-Instruct は MinHash と局所性を考慮したハッシュ アルゴリズムを使用して、データ セット内の関数の重複を排除します。 Jaccard の類似性しきい値を 0.5 に設定すると、類似性の高い重複関数が効果的に削除され、データ セットの一意性と多様性が確保されます。
この一連の細かいスクリーニングとフィルタリングの後、StarCoder2-15B-Instruct は最終的に、ドキュメントをシード データ セットとして、500 万の Python 関数から 250,000 の高品質関数を選択しました。このアプローチは、MultiPL-T データ収集プロセスから大きく影響を受けています。
StarCoder2-15B-Instruct がシード関数の収集を完了すると、Self-OSS-Instruct テクノロジーを使用して多様なプログラミング命令を作成しました。このテクノロジーの核心は、StarCoder2-15B 基本モデルが、コンテキスト学習を通じて、特定のシード コード フラグメントに対応する命令を自律的に生成できるようにすることです。
この目標を達成するために、StarCoder2-15B-Instruct は 16 個の例を慎重に設計しました。各例は (コード スニペット、概念、命令) の構造に従います。命令生成プロセスは 2 つの段階に細分されます:
コード概念の特定: この段階では、StarCoder2-15B は各シード関数の詳細な分析を実行し、関数内の主要なコード概念を含むリストを生成します。これらの概念は、パターン マッチング、データ型変換など、プログラミング分野の基本原則とテクニックを幅広くカバーしており、開発者にとって非常に実用的価値があります。
命令の作成: 認識されたコード概念に基づいて、StarCoder2-15B はさらに、対応するコーディング タスク命令を生成します。このプロセスは、生成された命令がコード フラグメントのコア機能と要件を正確に反映するように設計されています。
上記のプロセスを通じて、StarCoder2-15B-Instruct は最終的に最大 238k の命令の生成に成功し、トレーニング データ セットを大幅に強化し、プログラミング タスクのパフォーマンスを強力にサポートしました。
Self-OSS-Instructによって生成された命令を取得した後、StarCoder2-15B-Instructの主要なタスクは、各命令の高品質な応答を照合することです。 。
従来、人々はこれらの応答を取得するために GPT-4 などのより強力な教師モデルに依存する傾向がありましたが、このアプローチは著作権ライセンスの問題に直面する可能性があるだけでなく、外部モデルが常に手の届くところにあるか、正確であるとは限りません。さらに重要なのは、外部モデルに依存すると、教師と生徒の間で分布に違いが生じ、最終結果の精度に影響を与える可能性があります。
これらの課題を克服するために、StarCoder2-15B-Instruct は自己検証メカニズムを導入しています。このメカニズムの中心となるアイデアは、自然言語応答を生成した後、StarCoder2-15B モデルに対応するテスト ケースを独自に作成させることです。このプロセスは、開発者がコードを作成した後に行う自己テスト プロセスに似ています。
具体的には、StarCoder2-15B は命令ごとに、自然言語応答と対応するテスト ケースを含む 10 個のサンプルを生成します。次に、StarCoder2-15B-Instruct は、サンドボックス環境でこれらのテスト ケースを実行し、応答の有効性を検証します。テストの実行に失敗したサンプルは除外されます。
この厳密なスクリーニングプロセスの後、StarCoder2-15B-Instruct は各命令のテストされた応答から 1 つをランダムに選択し、それを最終的な SFT データセットに追加します。プロセス全体を通じて、StarCoder2-15B-Instruct は 238k 命令に対して合計 240 万個の応答サンプル (命令ごとに 10 サンプル) を生成しました。 0.7 のサンプリング戦略を採用した後、500,000 個のサンプルが実行テストに合格しました。
データセットの多様性と品質を確保するために、StarCoder2-15B-Instruct は重複排除処理も実行します。最終的には 50,000 のコマンドが残り、それぞれにランダムに選択され、テストされ、検証された高品質の応答が含まれていました。これらの応答は StarCoder2-15B-Instruct の最終 SFT データ セットを構成し、その後のモデルのトレーニングと適用のための強固な基盤を提供します。
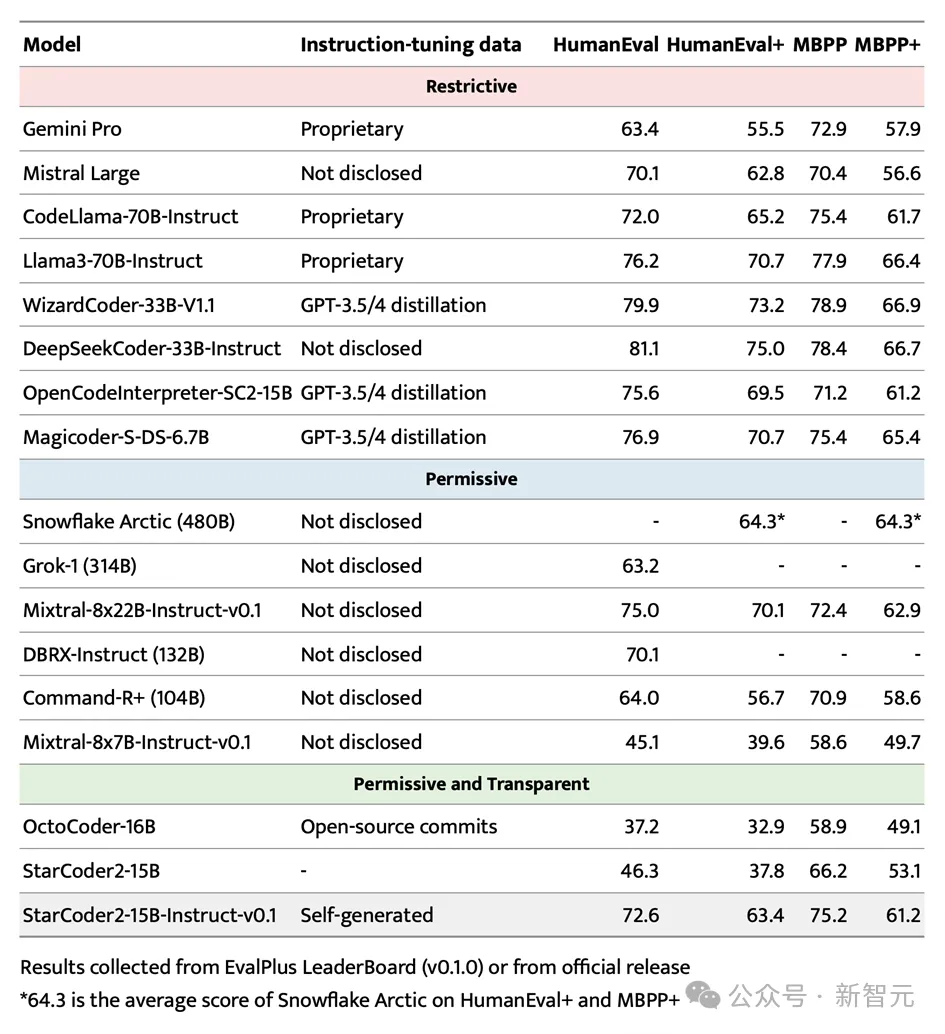
注目を集める EvalPlus ベンチマーク テストにおいて、StarCoder2-15B-Instruct はその規模の利点により傑出し、最高のパフォーマンスを誇る自律システムとなりました。制御可能な大型モデル。
より大型の Grok-1 Command-R+ や DBRX を上回るだけでなく、Snowflake Arctic 480B や Mixtral-8x22B-Instruct などの業界リーダーにも匹敵します。
StarCoder2-15B-Instruct は、HumanEval ベンチマークで 70 以上のスコアを達成した最初の大規模な独立したコード モデルであることは言及する価値があります。そのトレーニング プロセスは完全に透過的であり、データとメソッドの使用は法律と規制に準拠しています。 。
独立制御可能なコード大規模モデルの分野では、StarCoder2-15B-Instruct が以前のリーダーである OctoCoder を大幅に上回り、この分野での主導的地位を証明しました。
Gemini Pro や Mistral Large など、ライセンスが制限されている大規模で強力なモデルと比較しても、StarCoder2-15B-Instruct は依然として優れたパフォーマンスを示し、CodeLlama-70B-Instruct と同等です。さらに注目すべき点は、StarCoder2-15B-Instruct がトレーニング用に自己生成データに完全に依存しており、そのパフォーマンスが GPT-3.5/4 データ微調整に基づく OpenCodeInterpreter-SC2-15B に匹敵することです。
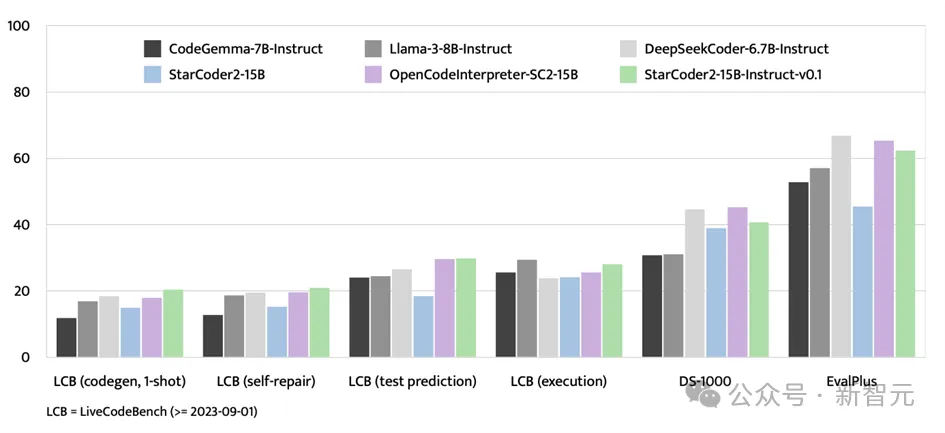
EvalPlus ベンチマーク テストに加えて、StarCoder2-15B-Instruct は、LiveCodeBench や DS-1000 などの評価プラットフォームでも強い強みを示しました。
LiveCodeBench は、2023 年 9 月 1 日以降に出現するコーディングの課題の評価に重点を置いており、StarCoder2-15B-Instruct はこのベンチマークで最高の結果を達成し、GPT-4 データ -SC2-15B を使用して微調整された OpenCodeInterpreter よりも常に優れています。
DS-1000 はデータ サイエンス タスクに重点を置いていますが、StarCoder2-15B-Instruct は依然としてこのベンチマークで優れたパフォーマンスを示し、トレーニング データにおけるデータ サイエンスの問題が比較的少ないことがわかります。
StarCoder2-15B-Instruct-v0.1 の核心は、コード学習の分野での自己調整戦略の適切な適用にあります。この戦略はモデルのパフォーマンスを向上させるだけでなく、さらに重要なことに、モデルの透明性と解釈可能性を高めます。これは、Snowflake-Arctic、Grok-1、Mixtral-8x22B、DBRX、CommandR+ などの他の大規模モデルとはまったく対照的です。これらのモデルは強力ではありますが、透明性の欠如により、適用範囲や信頼性が制限されることがよくあります。
さらに嬉しいのは、StarCoder2-15B-Instruct-v0.1 がそのデータセットとトレーニング プロセス全体 (データ収集とトレーニング プロセスを含む) を完全にオープンソースにしたことです。この動きは研究者のオープンな精神を示すだけでなく、この分野における将来の研究開発のための強固な基盤を築くことにもなります。
StarCoder2-15B-Instruct-v0.1 の実践が成功したことで、より多くの研究者がコード モデルのセルフチューニングの分野の研究に投資するようになり、この分野の技術進歩とアプリケーションの拡張が促進されると信じる理由があります。分野。同時に、私たちはこの分野でさらに革新的な成果が生まれ続け、人類社会の知的発展に新たな推進力をもたらすことも期待しています。
最近、チームは多数の革新的な大規模コード モデルとテスト ベンチマーク データ セットをリリースし、一連の大規模モデルベースのソフトウェア テストおよび修復テクノロジの提案を主導してきました。同時に、複数の実際のソフトウェア システムで何千もの新しい欠陥や抜け穴が発見され、ソフトウェアの品質向上に大きく貢献しました。
以上がOpenAI データは必要ありません。大規模なコード モデルのリストに加わりましょう。 UIUC が StarCoder-15B-Instruct をリリースの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



