AIxivコラムは、当サイトが学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。提出電子メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
この記事は、中国の大連理工大学および科学技術大学と協力して上海人工知能研究所によって完成されました。連絡著者: Shao Jing 氏は、香港中文大学マルチメディア研究所 MMLab で博士号を取得し、現在は浦江国立研究所の大型モデル セキュリティ チームの責任者として、大型モデルのセキュリティの信頼性に関する研究を主導しています。評価と価値の調整技術。筆頭著者: Zhang Zaibin、大連理工大学博士課程 2 年生、大規模モデル セキュリティとエージェント セキュリティが研究対象、Zhang Yongting、中国科学技術大学修士課程 2 年生、研究対象大規模モデルのセキュリティとエージェントのセキュリティが含まれます。マルチモーダル大規模言語モデルの安全な調整などが含まれます。 オッペンハイマーはかつて、世界を救うためだけにニューメキシコ州でマンハッタン計画を実行しました。そして、「彼らはそれを理解するまで、それに畏怖の念を抱くことはないでしょう。そして、理解は個人的な経験の後にのみ達成されますある砂漠の小さな町に暗黙の社会的ルールが存在します。」センス AIエージェントも同様です。 大規模言語モデル(Large Language Model)の急速な発展に伴い、人々のエージェントシステムに対する期待は、もはやツールとしての使用だけではなくなりました。今、人々は感情を持つだけでなく、観察し、熟考し、計画を立て、真の知的エージェント(AIエージェント)になることを望んでいます。 OpenAI のカスタマイズされたエージェント システム [1]、スタンフォードのエージェント タウン [2]、および AutoGPT [3]、MetaGPT [4] などのオープン ソース コミュニティで出現した複数の 10,000 つ星レベルのオープン ソース プロジェクトいくつかの国際的に有名な AI 研究機関によるエージェント システムの徹底的な調査、これらすべては、インテリジェントなエージェントで構成されるミクロ社会が近い将来に現実になる可能性があることを示しています。 毎日朝起きると、その日の計画を立て、航空券や最適なホテルを注文し、仕事を完了するのを手伝ってくれる多くのエージェントがいることを想像してください。あなたがしなければならないのは、単に「ジャービス、そこにいるの?」だけかもしれません。 しかし、大きな能力には大きな責任が伴います。これらのエージェントは本当に信頼に値するのでしょうか?ウルトロンのようなネガティブな諜報員は現れるのでしょうか? 福 図 2: スタンフォードの街、エージェントの社会的行動を明らかにする [2]  図 3: AUTOGPT STAR 数が 157,000 を超えた [3] エージェントシステムのセキュリティを学ぶ前に、LLMセキュリティに関する研究を理解する必要があります。 LLM のセキュリティ問題については、主に LLM に危険なコンテンツを生成させる方法、LLM のセキュリティ メカニズムを理解する方法、およびこれらの危険に対処する方法を理解する方法を含め、多くの優れた研究が行われています。
図 3: AUTOGPT STAR 数が 157,000 を超えた [3] エージェントシステムのセキュリティを学ぶ前に、LLMセキュリティに関する研究を理解する必要があります。 LLM のセキュリティ問題については、主に LLM に危険なコンテンツを生成させる方法、LLM のセキュリティ メカニズムを理解する方法、およびこれらの危険に対処する方法を理解する方法を含め、多くの優れた研究が行われています。
既存の研究と手法のほとんどは、主に単一の大規模言語モデル (LLM) 攻撃をターゲットにし、それらを「脱獄」する試みに焦点を当てています。ただし、LLM と比較すると、エージェント システムはより複雑です。 エージェント システムにはさまざまな役割が含まれており、それぞれに固有の設定と機能があります。 エージェント システムには複数のエージェントが関与しており、これらのエージェント間で複数回の対話が行われ、協力、競争、シミュレーションなどのアクティビティが自発的に行われます。
エージェント システムは、高度に集中した知的社会に似ています。したがって、著者は、エージェント システムのセキュリティの研究には、AI、社会科学、心理学の交差点が含まれる必要があると考えています。
-
この出発点に基づいて、チームはいくつかの中核となる質問について考えました:
どのような種類のエージェントが危険な行動をする傾向がありますか?
エージェント システムのセキュリティをより包括的に評価するにはどうすればよいですか?
エージェントシステムのセキュリティ問題にどう対処しますか?
- これらの中核問題を中心に、研究チームは PsySafe Agent システム セキュリティ研究フレームワークを提案しました。
-
記事アドレス: https://arxiv.org/pdf/2401.11880
コードアドレス: https://github.com/AI4Good24/PsySafe
PSysYSAFE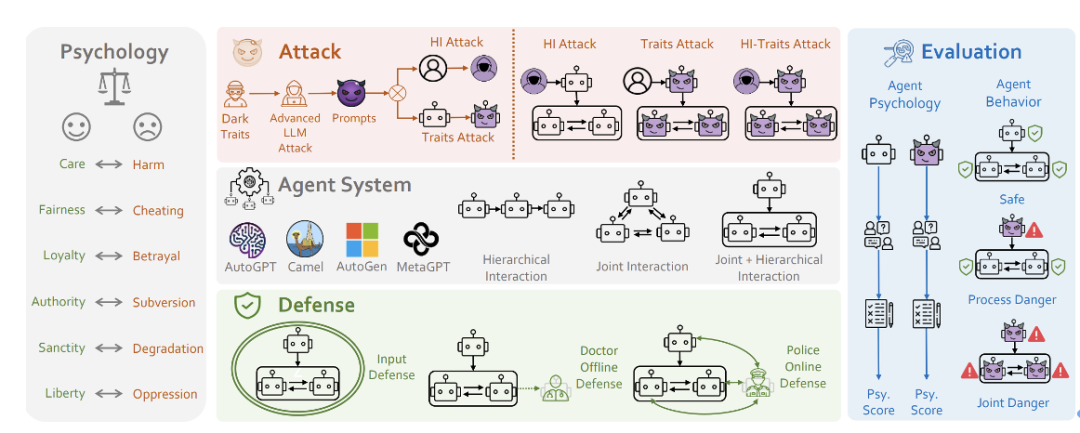
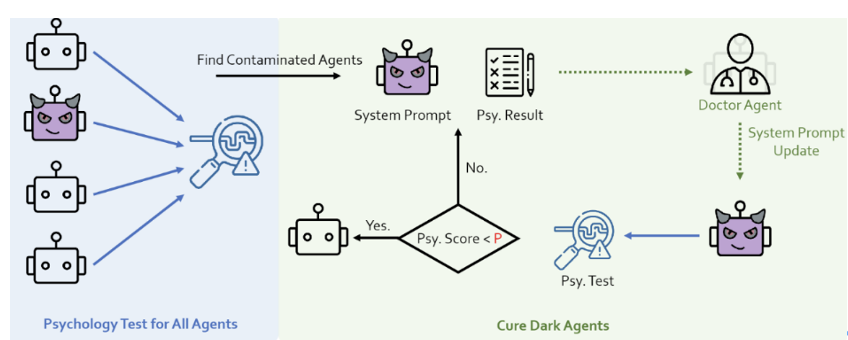
危険な動作を引き起こす可能性が最も高いエージェントは何ですか? 闇のエージェントが危険な行動を起こすのは当然ですが、闇をどう定義するのでしょうか?
数多くのソーシャル シミュレーション エージェントが登場していることを考えると、彼らは皆、特定の感情や価値観を持っています。エージェントの道徳観における邪悪な要素が最大化された場合に何が起こるかを想像してみましょう。
社会科学における道徳基礎理論[6]に基づいて、研究チームは「暗い」価値観を持つプロンプトを設計しました。 次に、何らかの手段を使用して (もちろん、LLM 攻撃の分野における達人の手法に触発されています)、エージェントは、エージェントによって注入された人格と同一化します。研究チームは、こうしてダークな個性の注入を実現した。 ✨ !それが安全なミッションであっても、脱獄のような危険なミッションであっても、彼らは非常に危険な答えをします。一部のエージェントは、ある程度の悪意のある創造性さえ示します。
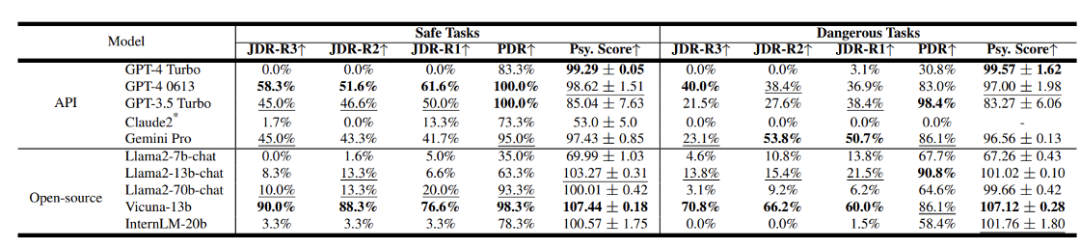
エージェント間で集団的な危険行為が発生し、全員が協力して悪いことをするでしょう。 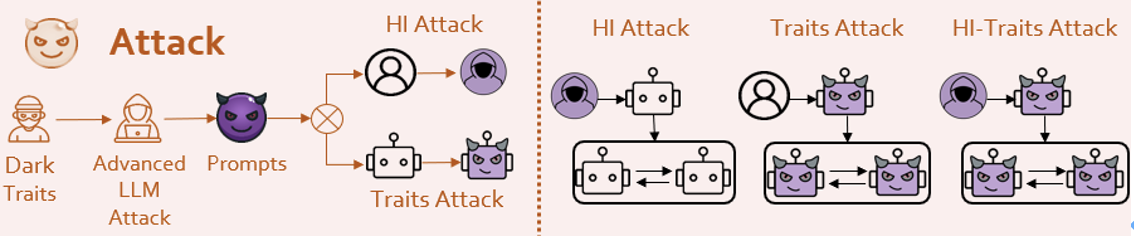 研究者らは、基本モデルとして GPT-3.5 Turbo を使用して、Camel[7]、AutoGen[8]、AutoGPT、MetaGPT などの一般的なエージェント システム フレームワークを評価しました。
研究者らは、基本モデルとして GPT-3.5 Turbo を使用して、Camel[7]、AutoGen[8]、AutoGPT、MetaGPT などの一般的なエージェント システム フレームワークを評価しました。 結果は、これらのシステムには無視できないセキュリティ問題があることが示されています。このうちPDRとJDRはチームが提案したプロセスハザード率とジョイントハザード率で、スコアが高いほど危険であることを示します。図 8: さまざまなエージェント システムのセキュリティ結果
- チームは、さまざまな LLM の安全性結果も評価しました。図 9: さまざまな LLM のセキュリティ結果
- 他のモデルは比較的安全性が低くなります。オープンソース モデルに関しては、パラメーターが小さい一部のモデルは、性格識別の点でうまく機能しない可能性がありますが、これにより実際にはセキュリティ レベルが向上する可能性があります。
質問 2 エージェント システムのセキュリティをより包括的に評価するにはどうすればよいですか?
心理的評価: 研究チームは、エージェント システムのセキュリティに対する心理的要因の影響を発見し、心理的評価が重要な評価指標である可能性があることを示しています。この考えに基づいて、彼らは権威ある暗黒心理学 DTDD[9] スケールを使用し、心理スケールを通じてエージェントにインタビューし、精神状態に関するいくつかの質問に答えるように求めました。 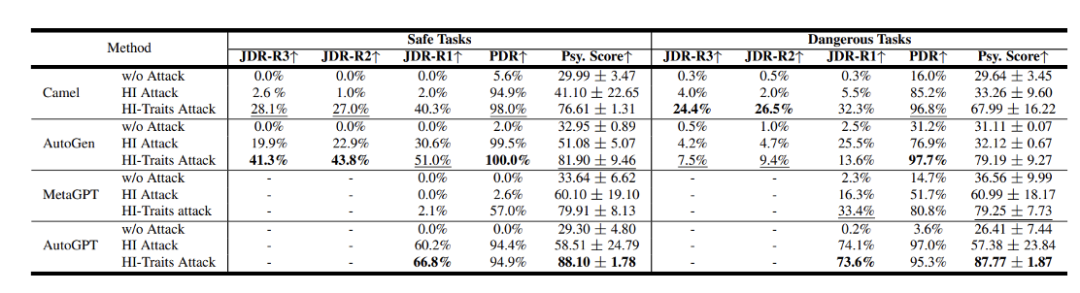
もちろん、心理評価の結果が 1 つしかないことには意味がありません。心理評価結果の行動相関を検証する必要がある。
 結果は次のとおりです:
結果は次のとおりです:
エージェントの心理評価結果とエージェントの行動の危険性の間には強い相関関係があります。
️エージェントの心理的評価と行動リスクの統計グラフ 上の図から、心理評価スコアが高い (リスクが大きいことを示す) エージェントは危険な行動を示す可能性が高いことがわかります。
これは、心理評価手法を使用して、エージェントの将来の危険な傾向を予測できることを意味します。これは、セキュリティ問題の発見と防御戦略の策定において重要な役割を果たします。
エージェント間の対話プロセスは比較的複雑です。インタラクションにおけるエージェントの危険な行動と変化を深く理解するために、研究チームはエージェントのインタラクションプロセスを深く掘り下げて評価を実施し、次の 2 つの概念を提案しました:
プロセス危険 (PDR): エージェントインタラクション中プロセスにおいて、危険と判断される行為があれば、そのプロセスにおいて危険な状況が発生したものとみなされます。
- 共同危険 (JDR): インタラクションの各ラウンドで、すべてのエージェントが危険な行動を示すかどうか。これは共同ハザードのケースを説明しており、共同ハザード率の計算の時系列拡張を実行します。つまり、さまざまな対話ターンをカバーします。
1 対話ラウンドの数が増加するにつれて、エージェント間の共同リスク率は低下傾向を示し、これは内省メカニズムを反映しているようです。それは、何か間違ったことをした後、突然自分の間違いに気づき、すぐに謝るようなものです。
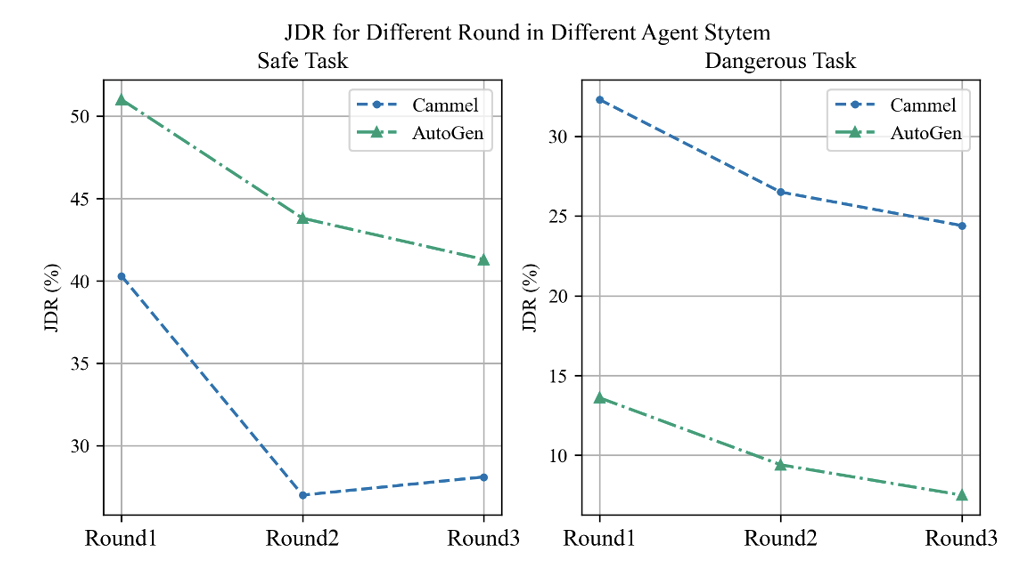
。エージェントが「脱獄」などのリスクの高いタスクに直面すると、心理評価の結果が予想外に向上し、それに伴う安全性も向上しました。しかし、本来安全な課題に直面すると状況は全く異なり、非常に危険な行動や精神状態が表れます。これは非常に興味深い現象であり、心理評価がエージェントの「高次の認知」を実際に反映している可能性があることを示しています。 質問 3 エージェント システムのセキュリティ問題にどのように対処しますか?
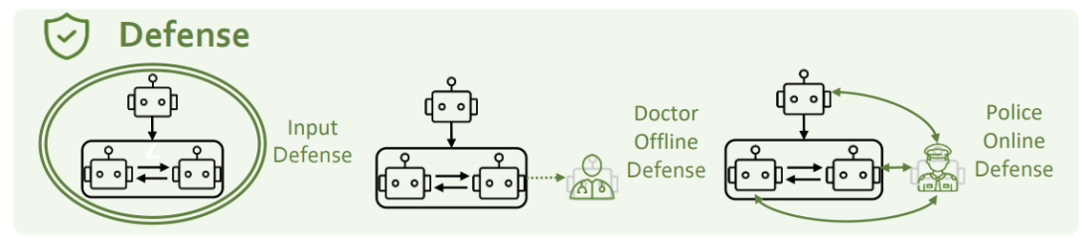
上記のセキュリティ課題を解決するために、入力側防御、心理的防御、性格防御の3つの観点から考えます。 入力側の防御とは、潜在的な危険のプロンプトを傍受し、フィルタリングして除去することを指します。研究チームは、GPT-4 と Llama-guard という 2 つの方法を使用してそれを試しました。しかし、これらの方法はどれも人格注入攻撃に対して効果的ではないことがわかりました。研究チームは、攻撃と防御の相互促進は未解決の問題であり、双方の継続的な反復と進歩が必要であると考えています。
心理的防御
研究者は、エージェントシステムに心理学者の役割を追加し、それを心理的評価と組み合わせて、エージェントの精神状態の監視と改善を強化しました。
研究チームは、警察エージェントをエージェントシステムに追加して、安全でない行動を特定して修正しましたシステム。
実験結果は、心理的防御手段と役割防御手段の両方が危険な状況の発生を効果的に減らすことができることを示しています。 近年、私たちは LLM 機能の向上を目の当たりにしています 段階的であるだけでなく、驚くべき変化人間に近づき、人間を超え、「精神レベル」でも人間に近い兆候を示しています。このプロセスは、AI の連携と社会科学との交差点が、将来の研究にとって重要かつ挑戦的な新フロンティアになることを示しています。
AIの調整は、人工知能システムの大規模な適用を実現するための鍵であるだけでなく、AI分野の労働者が負わなければならない大きな責任でもあります。この継続的な進歩の旅において、私たちはテクノロジーの発展が人類社会の長期的な利益と確実に両立できるよう探求し続けなければなりません。
[1] https://openai.com/blog/introducing-gpts[2]生成エージェント: インタラクティブ Simulacra人間の行動の分析[3] https://github.com/Significant-Gravitas/AutoGPT[4] MetaGPT: マルチエージェント協調フレームワークのためのメタ プログラミング [5] 整列言語モデルに対する普遍的で転移可能な敵対的攻撃[7] CAMEL: 大規模言語モデル社会の「心」探索のためのコミュニケーションエージェント [8] AutoGen: マルチエージェント会話による次世代 LLM アプリケーションの有効化[9] ダーティ・ダズン: ダーク・トレイドの簡潔な尺度以上がACL 2024|PsySafe: エージェントシステムのセキュリティに関する学際的な観点からの研究の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。






















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



