Gemma 2 のパフォーマンスが 2 倍ですが、Llama 3 を同じレベルでプレイするにはどうすればよいですか?
AI トラックでは、テクノロジー大手が熾烈な競争を行っています。 GPT-4oが前足で登場し、Claude 3.5 Sonnetが後足で登場しました。このような熾烈な戦いの中で、グーグルは取り組みを開始したのが遅かったものの、短期間でフォローアップする大きな力を持っており、技術開発とイノベーションの可能性を示している。 Geminiモデルに加えて、軽量SOTAオープンモデルのGemmaシリーズが私たちに近いようです。これは、Gemini モデルと同じ研究とテクノロジーに基づいて構築されており、AI を構築するためのツールをすべての人に提供することを目的としています。 Google は引き続き Gemma ファミリーを拡大し、CodeGemma、RecurrentGemma、PaliGemma を含めます。各モデルはさまざまな AI タスクに独自の機能を提供し、Hugging Face、NVIDIA、Ollama などのパートナーを通じて簡単にアクセスできます。 
今、Gemma ファミリーは新しいメンバー、Gemma 2 を歓迎し、短く簡潔にするという伝統を続けています。今回Gemma 2で提供される90億個(9B)と270億個(27B)のパラメータの2つのバージョンは、第1世代よりも推論性能と効率が向上し、セキュリティも大幅に向上している。実際、270 億パラメータのバージョンは、2 倍以上のサイズのモデルと同じレベルで競合することができ、以前は独自のモデルによってのみ達成されていたパフォーマンスを提供できるようになり、現在は単一の NVIDIA H100 Tensor コア GPU または TPU で実装されています。これにより、展開コストが大幅に削減されます。
Google チームは、再設計されたアーキテクチャに基づいて Gemma 2 を構築し、Gemma ファミリーのこの新しいメンバーが優れたパフォーマンスと効率的な推論機能の両方を提供できるようにしました。簡単に要約すると、パフォーマンス、コスト、推論がその優れた機能です。
- 優れたパフォーマンス: Gemma 2 27B モデルは、そのボリューム カテゴリで最高のパフォーマンスを提供し、そのサイズの 2 倍を超えるモデル競合モデルとさえ競合します。 9B Gemma 2 モデルもそのサイズ カテゴリで優れたパフォーマンスを示し、Llama 3 8B や他の同等のオープン モデルを上回りました。
- 高効率、低コスト: 27B Gemma 2 モデルは、高いパフォーマンスを維持しながら、単一の Google Cloud TPU ホスト、NVIDIA A100 80GB Tensor コア GPU、または NVIDIA H100 Tensor コア GPU 上でフル精度で効率的に推論を実行するように設計されています。コストを大幅に削減します。これにより、AI の導入がより便利になり、手頃な価格になります。
- 超高速推論: Gemma 2 は、強力なゲーミング ラップトップ、ハイエンド デスクトップ、クラウドベースのセットアップなど、さまざまなハードウェア上で超高速で実行できるように最適化されています。ユーザーは、Google AI Studio で Gemma 2 をフル精度で実行してみたり、CPU 上で量子化バージョンの Gemma.cpp を使用してローカル パフォーマンスを解放したり、Hugging Face Transformers を介して NVIDIA RTX または GeForce RTX を使用して自宅のコンピューターで試したりすることができます。
上記はGemma2、Llama3、Grok-1のスコアデータ比較です。
実際、さまざまなスコアデータから判断すると、オープンソースの 9B 大型モデルの利点は特に明らかではありません。約 1 か月前に Zhipu AI によってオープンソース化された大型の国内モデル GLM-4-9B には、さらに多くの利点があります。
さらに、Gemma 2 はより強力になっているだけでなく、ワークフローに簡単に統合できるように設計されています。 Google は、開発者に AI ソリューションをより簡単に構築および展開できる、より多くの可能性を提供します。
- オープンでアクセス可能: オリジナルの Gemma モデルと同様に、Gemma 2 では開発者や研究者がイノベーションを共有し、商品化することができます。
- 幅広いフレームワーク互換性: Gemma 2 は、Hugging Face Transformers などの主要な AI フレームワークに加え、Keras 3.0、vLLM、Gemma.cpp、Llama.cpp、Ollama を通じてネイティブにサポートされている JAX、PyTorch、TensorFlow と互換性があります。ユーザー好みのツールやワークフローと簡単に統合できます。さらに、Gemma は NVIDIA TensorRT-LLM で最適化されており、NVIDIA アクセラレーション インフラストラクチャ上で、または NVIDIA NIM 推論マイクロサービスとして実行できます。将来的には NVIDIA の NeMo にも最適化され、Keras と Hugging Face を使用して微調整することができます。さらに、Google は微調整機能を積極的にアップグレードしています。
- 簡単なデプロイ: 来月から、Google Cloud のお客様は Vertex AI に Gemma 2 を簡単にデプロイして管理できるようになります。
Google は、ユーザーが独自のアプリケーションを構築し、特定のタスクに合わせて Gemma 2 モデルを微調整するのに役立つように設計された一連の実用的な例とガイドである、新しい Gemma Cookbook も提供しています。 Gemma Cookbook リンク: https://github.com/google-gemini/gemma-cookbook同時に、Google は、I/O カンファレンスで発表された公式製品も開発者に提供しました。 Gemini 1.5 Pro の 200 万コンテキスト ウィンドウ アクセス、Gemini API のコード実行機能、および Google AI Studio への Gemma 2 の追加。
- Google は最新のブログで、Gemini 1.5 Pro の 200 万トークンのコンテキスト ウィンドウへのアクセスをすべての開発者に開放したと発表しました。ただし、コンテキスト ウィンドウが増加すると、入力コストも増加する可能性があります。開発者が同じトークンを使用する複数のプロンプト タスクのコストを削減できるようにするために、Google は思慮深く、Gemini 1.5 Pro および 1.5 Flash 用の Gemini API にコンテキスト キャッシュ機能を導入しました。
- 数学やデータ推論を処理する際に、大規模な言語モデルが精度を向上させるためにコードを生成して実行する必要があるという問題を解決するために、Google は Gemini 1.5 Pro および 1.5 Flash でのコード実行を有効にしました。オンにすると、モデルは Python コードを動的に生成して実行し、目的の最終出力が達成されるまで結果から繰り返し学習できます。実行サンドボックスはインターネットに接続せず、いくつかの数値ライブラリが標準で付属しており、開発者はモデルの出力トークンに基づいて請求するだけで済みます。 Google がモデル機能にコード実行ステップを導入したのはこれが初めてであり、現在、Gemini API と Google AI Studio の詳細設定を通じて利用可能です。
- Google は、API キーを介して Gemini モデルを統合するか、オープン モデルの Gemma 2 を使用するかにかかわらず、すべての開発者が AI にアクセスできるようにしたいと考えています。開発者が Gemma 2 モデルを入手できるように、Google チームは Google AI Studio で実験できるようにします。
以下はGemma2の技術実験レポートであり、技術的な詳細を多角的に分析することができます。
- 紙のアドレス: https://storage.googleapis.com/deepmind-media/gemma/gemma-2-report.pdf
- ブログのアドレス: https://blog.google/ technology/developers/google-gemma-2/
以前の Gemma モデルと同様に、Gemma 2 モデルもデコーダーのみのトランスフォーマー アーキテクチャに基づいています。表 1 は、モデルの主なパラメータとアーキテクチャ上の選択をまとめたものです。 一部の構造要素は、Gemma モデルの最初のバージョンと似ています。つまり、コンテキストの長さは 8192 トークン、回転位置埋め込み (RoPE) の使用、および近似 GeGLU 非線形性です。 Gemma 1 と Gemma 2 には、より深いネットワークの使用など、いくつかの違いがあります。主な違いは次のように要約されます:
- ローカルなスライディング ウィンドウとグローバルな注目。研究チームは、ローカルなスライディング ウィンドウの注目と、他のレイヤーごとのグローバルな注目を交互に切り替えました。ローカル アテンション レイヤーのスライディング ウィンドウ サイズは 4096 トークンに設定され、グローバル アテンション レイヤーのスパンは 8192 トークンに設定されます。
- ロジットのソフトキャップ。研究チームは、Gemini 1.5の手法に従い、logitの値が-soft_capと+soft_capの間に収まるように、各注目層と最終層でlogitを制限した。
- 9B モデルと 27B モデルの場合、研究チームは注目の対数上限を 50.0 に設定し、最終対数上限を 30.0 に設定しました。公開時点では、アテンション ロジット ソフト キャッピングは一般的な FlashAttend 実装と互換性がないため、FlashAttend を使用するライブラリからこの機能が削除されました。研究チームは、アテンション ロジット ソフト キャッピングを使用した場合と使用しない場合のモデル生成に関するアブレーション実験を実施し、生成の品質はほとんどの事前トレーニングと事後評価でほとんど影響を受けないことを発見しました。このペーパーのすべての評価では、アテンション ロジット ソフト キャッピングを含む完全なモデル アーキテクチャが使用されます。ただし、一部のダウンストリーム パフォーマンスは、この削除によって依然としてわずかに影響を受ける可能性があります。
- ポストノルムとプレノルムには RMSNorm を使用します。トレーニングを安定させるために、研究チームは RMSNorm を使用して、各変換サブレイヤー、アテンション レイヤー、フィードフォワード レイヤーの入出力を正規化しました。
- グループで注意を喚起します。 27B モデルと 9B モデルはどちらも GQA、num_groups = 2 を使用しており、アブレーションベースの実験では、ダウンストリームのパフォーマンスを維持しながら推論速度が向上していることが示されています。
Google は、Gemma 1 とは異なる事前トレーニング部分の簡単な概要を提供します。 彼らは、主に英語のデータである 13 兆のトークンで Gemma 2 27B をトレーニングし、8 兆のトークンで 9B モデルをトレーニングし、2 兆のトークン トレインで 2.6B モデルをトレーニングしました。これらのトークンは、Web ドキュメント、コード、科学論文などのさまざまなデータ ソースから取得されます。このモデルはマルチモーダルではなく、最先端の多言語機能向けに特別にトレーニングされたものでもありません。最終的なデータミックスは、Gemini 1.0 と同様のアブレーション研究を通じて決定されます。 研究チームはモデルのトレーニングに TPUv4、TPUv5e、および TPUv5p を使用しています。詳細は以下の表 3 に示されています。 ポストトレーニングでは、Google は事前トレーニングされたモデルを命令調整されたモデルに微調整します。
- まず、プレーンテキスト、純粋な英語合成、および人工的に生成されたプロンプト応答ペアの混合物に教師あり微調整 (SFT) を適用します。
- その後、報酬モデル (RLHF) に基づく強化学習がこれらのモデルに適用されます。報酬モデルはトークンベースの純粋な英語の嗜好データでトレーニングされ、戦略は SFT ステージと同じプロンプトを使用します。
- 最後に、各段階で得られたモデルを平均化することで全体のパフォーマンスを向上させます。最終的なデータ混合およびトレーニング後の方法 (調整されたハイパーパラメーターを含む) は、モデルの有用性を高めながら、安全性と幻覚に関連するモデルの危険性を最小限に抑えることに基づいて選択されます。
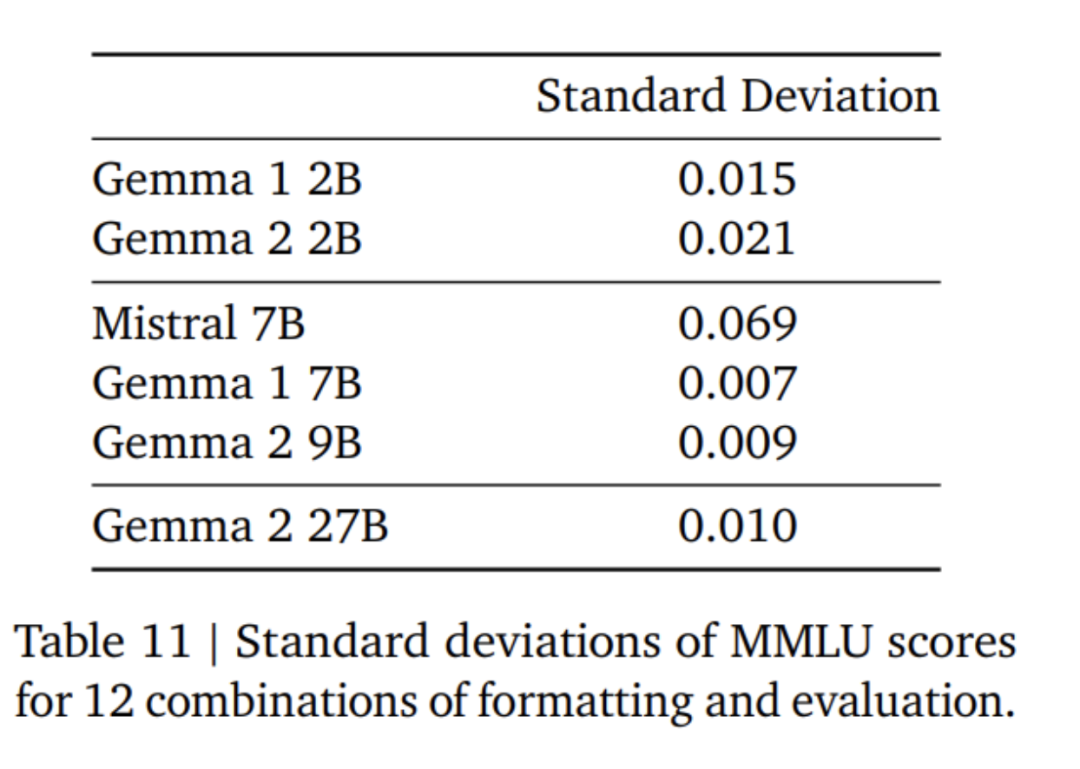
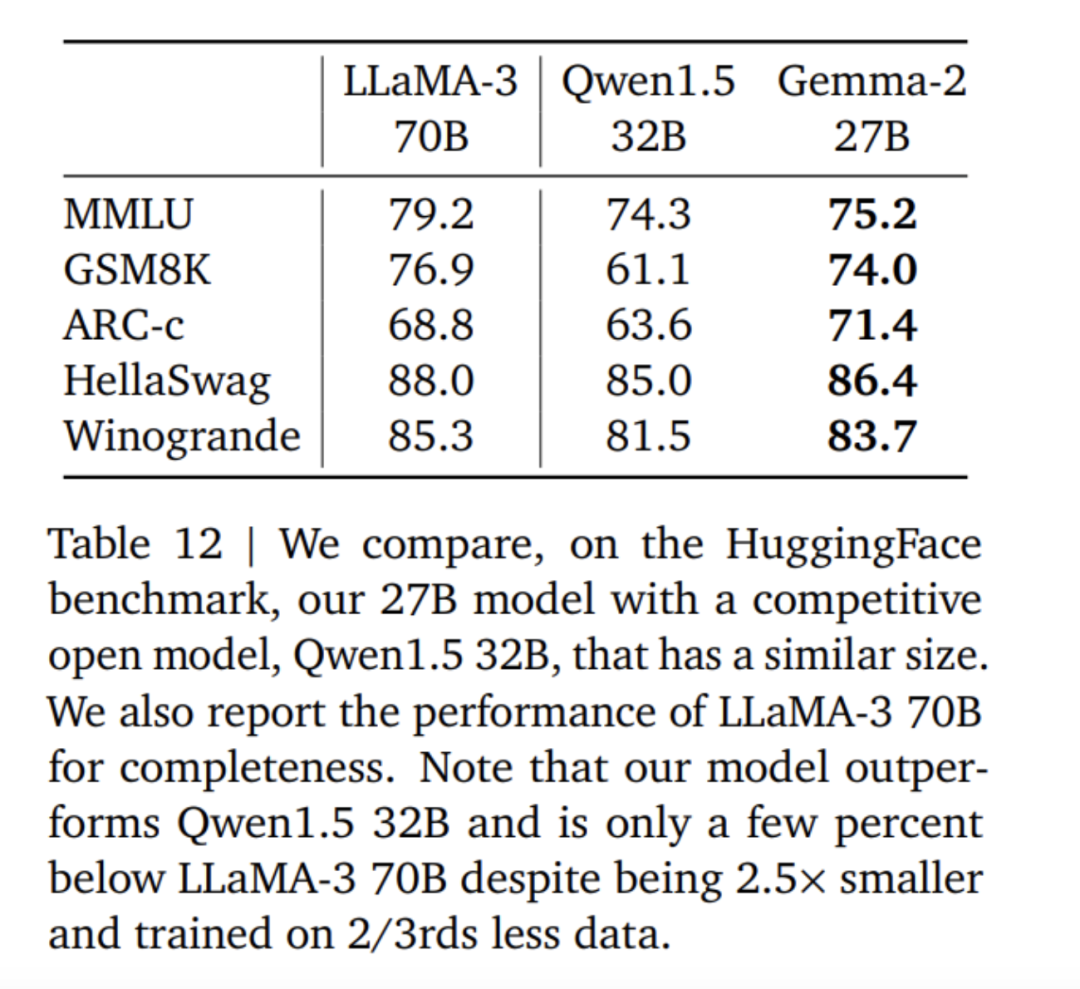
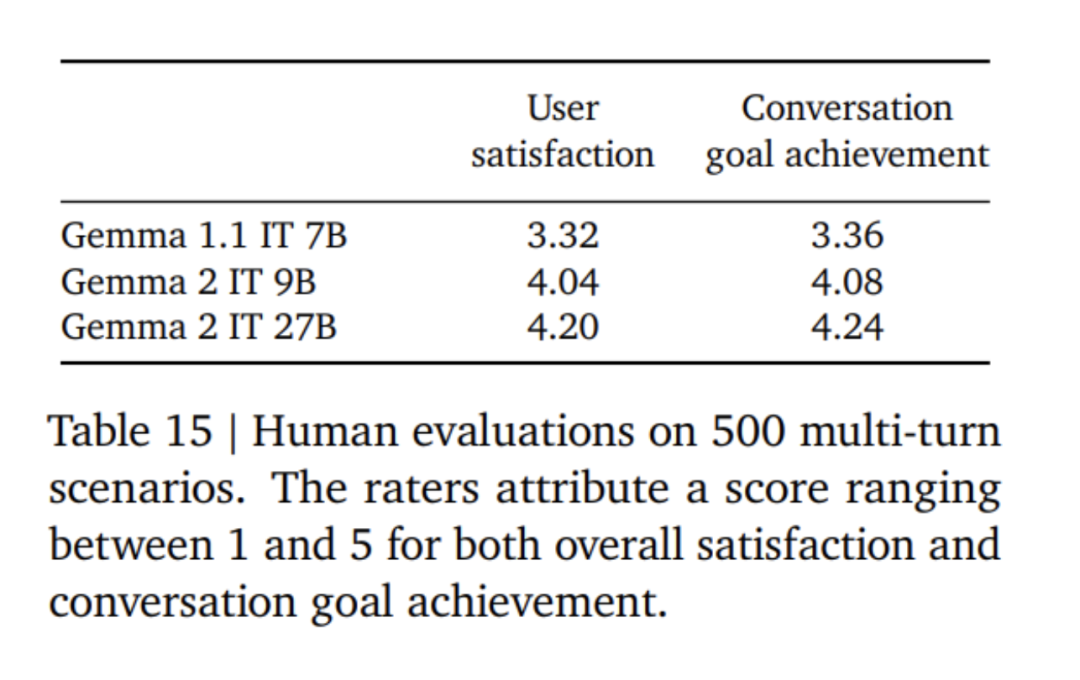
Gemma 2 モデルの微調整では、Gemma 1 モデルとは異なるフォーマット モードが使用されます。 Google は、表 4 で説明したものと同じコントロール トークンを使用しており、会話の例を表 5 に示します。表 6 では、より大きなモデルからの結果を調整すると、最初からトレーニングする場合と比較してパフォーマンスが向上することがわかります。 500B トークンは、2.6B モデルの最適な計算トークン数の 10 倍であることに注意してください。研究チームは、27B モデルから 9B モデルへの蒸留と同様の比率を維持するために、7B モデルからの蒸留を実行しました。 表 7 では、Google チームがモデル サイズの増加に伴う蒸留の影響を測定しています。モデル サイズが増加しても、このゲインが持続することがわかります。このアブレーション実験では、研究チームは教師モデルのサイズを 7B に保ち、より小さいモデルをトレーニングして、最終的な教師モデルと生徒モデルのサイズ間のギャップをシミュレートしました。 さらに、Google は、表 11 に示すように、プロンプト/評価形式の変更の影響を考慮し、MMLU でのパフォーマンスの差異を測定しました。 Gemma 2B モデルは、フォーマットの堅牢性の点で、より大きなモデルよりもわずかに劣ります。 Mistral 7B は堅牢性の点で Gemma シリーズ モデルよりも大幅に低いことに注意してください。 研究チームはまた、13兆個のトークンでトレーニングされた27Bモデル(蒸留されていない)のパフォーマンスを評価し、同様のサイズのQwen1.5 34Bモデルおよび2.5倍大きいLLaMA-3 70Bと比較しました。 HuggingFace 評価スイートのモデルの比較を行い、評価結果を表 12 に示します。モデルは、HuggingFace リーダーボードのランキングに基づいて選択されました。全体として、Gemma-2 27B モデルはそのサイズ カテゴリで最高のパフォーマンスを発揮し、トレーニングに時間がかかるより大きなモデルと競合することもできます。 Gemma-2 27B および 9B 命令微調整モデルは、チャットボット アリーナで人間の評価者によって他の SOTA モデルに対して盲目的に評価されました。研究チームは図 1 に ELO スコアを報告しています。 さらに、研究チームは、人間の評価者にモデルと対話させ、指定されたテストシナリオに従うことによって、Gemma 1.1 7B、Gemma 2 9B、および 27B モデルのマルチターン対話機能を評価しました。 Google は 500 のシナリオからなる多様な保持セットを使用しており、各シナリオにはブレインストーミング、計画の作成、新しいことの学習など、モデルに対する一連のリクエストが記述されています。ユーザー インタラクションの平均数は 8.4 です。最後に、Gemma 1.1 と比較して、ユーザーは Gemma 2 モデルの対話満足度および対話目標達成率が大幅に高いと評価していることがわかりました (表 15 を参照)。さらに、Gemma 2 モデルは、会話の開始からその後のラウンドまで、Gemma 1.1 7B モデルよりも高品質な応答を維持できます。 以上がGoogle の「誠実な仕事」、Gemma2 のオープンソース 9B および 27B バージョン、効率性と経済性に重点を置いています。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



