Meta は、プログラマーがより効率的にコードを作成できるようにする素晴らしい LLM コンパイラーを開発しました。
昨日、3大AI大手OpenAI、Google、Metaが提携し、自社の大規模モデルの最新の研究結果を発表しました - OpenAIはGPT-4に基づく新しいモデルCriticGPTを発表しましたバグ発見に特化したトレーニング、Google オープンソースの Gemma2 9B および 27B バージョン、そして Meta は最新の人工知能の画期的な LLM コンパイラーを考案しました。 これは、コードを最適化し、コンパイラー設計に革命を起こすように設計されたオープンソース モデルの強力なセットです。このイノベーションは、開発者がコードの最適化に取り組む方法を変え、コードの最適化をより高速に、効率的に、そしてコスト効率よく行う可能性があります。 LLM コンパイラーの最適化の可能性は、自動チューニング検索の 77% に達すると報告されており、この結果により、コンパイル時間が大幅に短縮され、さまざまなアプリケーションのコード効率が向上し、逆アセンブリに関してはその効果が向上します。トリップ 分解成功率は45%。 一部のネチズンは、これはコードの最適化と逆アセンブリのゲームチェンジャーのようなものだと言いました。 大規模な言語モデルは、多くのソフトウェア エンジニアリングやプログラミング タスクで優れた機能を示していますが、コードの最適化やコンパイラーの分野でのアプリケーションは十分に活用されていません。これらの LLM のトレーニングには、高価な GPU 時間や大規模なデータセットを含む広範なコンピューティング リソースが必要であり、多くの研究やプロジェクトが持続不可能になることがよくあります。 このギャップを埋めるために、メタ研究チームは、特にコードを最適化し、コンパイラー設計に革命を起こす LLM コンパイラーを導入しました。 LLVM-IR およびアセンブリ コードの 5,460 億トークンの膨大なコーパスでモデルをトレーニングすることにより、モデルがコンパイラの中間表現、アセンブリ言語、および最適化手法を理解できるようになりました。 論文リンク: https://ai.meta.com/research/publications/meta-large- language-model-compiler-foundation-models-of-compiler-optimization/「」の研究者LLM コンパイラーは、コンパイラーの中間表現 (IR)、アセンブリ言語、および最適化手法についての理解を強化します」と論文では説明しています。 LLM Compilerのトレーニングプロセスを図1に示します。 LLM コンパイラーは、コードサイズの最適化において重要な結果を達成します。テストでは、モデルの最適化可能性は自動チューニング検索の 77% に達し、その結果、コンパイル時間を大幅に短縮し、さまざまなアプリケーションのコード効率を向上させることができました。 このモデルは分解が得意です。 LLM コンパイラは、x86_64 および ARM アセンブリ コードを LLVM-IR に変換する際に、45% の往復逆アセンブリ成功率 (うち 14% は完全一致) を達成します。この機能は、リバース エンジニアリング タスクやレガシー コードのメンテナンスに非常に役立ちます。 このプロジェクトの中心的な貢献者の 1 人、Chris Cummins は、このテクノロジーの潜在的な影響を次のように強調しました。 「LLM コンパイラーは、コードとコンパイラーの最適化の分野で LLM の未開発の可能性を探求する道を開きます」と彼は述べました。通常、LLM は主に Python などの高レベルのソース言語で構成され、これらのデータ セットではアセンブリ コードが占める割合はごくわずかで、コンパイラ IR が占める割合はさらに小さくなります。これらの言語をよく理解して LLM を構築するために、研究チームは、Code Llama の重みを使用して LLM コンパイラー モデルを初期化し、主にコンパイラー中心のデータセットで 4,010 億個のトークンをトレーニングしました。表 1 に示すように、アセンブリ コードとコンパイラ IR で構成されます。 データセット LLM コンパイラーは主に、LLVM (バージョン 17.0.6) によって生成されたコンパイラーの中間表現とアセンブリ コードでトレーニングされます。これらのデータは、表 2 で報告されているコード Llama のトレーニングに使用されたのと同じデータセットから派生します。データセットの概要を に示します。 Code Llama と同様に、自然言語データセットから小さなトレーニング バッチも取得します。  コード最適化のメカニズムを理解するために、研究チームは、図 2 に示すように、LLM コンパイラ モデルで命令の微調整を実行し、コンパイラの最適化をシミュレートしました。 そのアイデアは、ランダムに生成されたコンパイラ最適化シーケンスをこれらのプログラムに適用することにより、最適化されていないシード プログラムの限られたコレクションから多数の例を生成することです。次に、最適化によって生成されるコードを予測するようにモデルをトレーニングし、最適化を適用した後のコード サイズを予測するようにモデルをトレーニングしました。 タスクの仕様。 最適化されていない LLVM-IR (clang フロントエンドによる出力)、最適化パスのリスト、および開始コード サイズを指定して、これらの最適化を適用した後の結果のコードとコード サイズを生成します。 このタスクには 2 つのタイプがあります。1 つ目では、モデルはコンパイラ IR を出力することを期待し、2 つ目では、モデルはアセンブリ コードを出力することを期待します。入力 IR、最適化プロセス、コード サイズはどちらのタイプでも同じで、ヒントによって必要な出力形式が決まります。 コードサイズ。 コード サイズを測定するために、IR 命令の数とバイナリ サイズという 2 つの指標が使用されます。バイナリ サイズは、IR またはアセンブリをオブジェクト ファイルにダウングレードした後、.TEXT セグメント サイズと .DATA セグメント サイズの合計として計算されます。 .BSS セグメントはディスク上のサイズに影響を与えないため、除外します。 パスを最適化します。 この作業では、研究チームは LLVM 17.0.6 をターゲットにしており、パスをモジュール、関数、ループなどのさまざまなレベルに分類し、パスの変換と分析を行う新しいプロセス マネージャー (PM、2021) を使用しています。 。変換パスは特定の入力 IR を変更しますが、分析パスは後続の変換に影響を与える情報を生成します。 opt に使用できる 346 個のパス パラメーターのうち、使用する 167 個を選択しました。これには、すべてのデフォルトの最適化パイプライン (例: module (default))、個々の最適化変換パス (例: module (constmerge)) が含まれますが、非最適化ユーティリティ パス (例: module (dot-callgraph)) は除外され、セマンティクス変換パスは保持されません。 (モジュール(内部化)など)。 分析パスには副作用がなく、必要に応じて依存する分析パスを挿入するためにパスマネージャーに依存しているため、分析パスは除外されます。パラメーターを受け入れるパスの場合は、デフォルト値を使用します (例: module (licm))。表 9 には、使用されたすべてのパスのリストが含まれています。 LLVM の opt ツールを使用してパス リストを適用し、clang を使用して結果の IR をオブジェクト ファイルにダウングレードします。リスト 1 に、使用されるコマンドを示します。 データセット。研究チームは、表 2 にまとめた最適化されていないプログラムに 1 ~ 50 のランダムな最適化パスのリストを適用することで、コンパイラー シミュレーション データセットを生成しました。各パス リストの長さは均一かつランダムに選択されます。パス リストは、上記の 167 パス セットから均一にサンプリングして生成されます。コンパイラーのクラッシュまたは 120 秒後のタイムアウトの原因となるパス リストは除外されます。 llmコンパイラFTD:ダウンストリームコンパイルタスクを拡張するintruction最適化フラグのためのインストラクション微調整
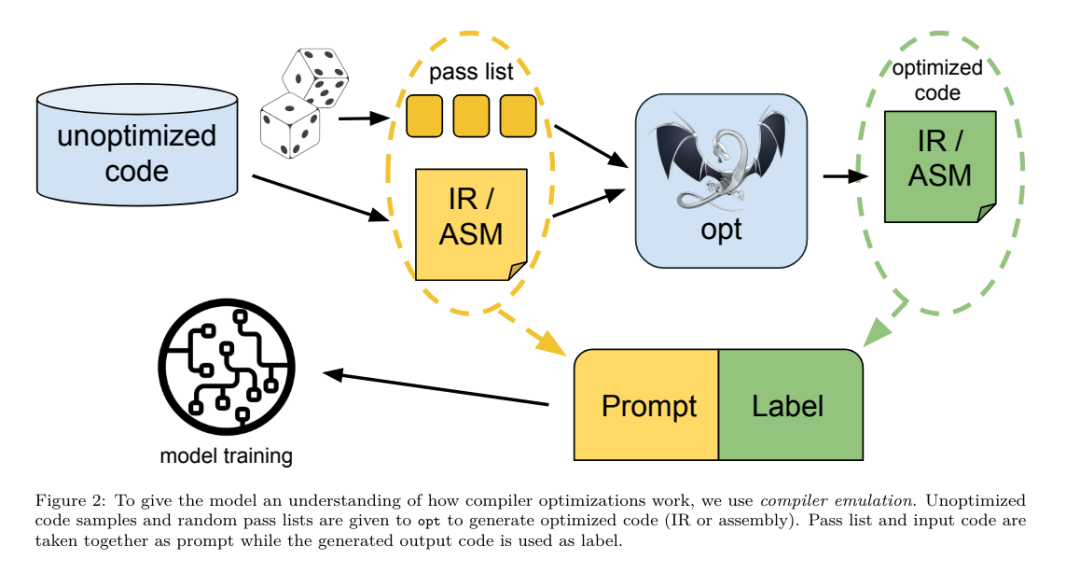
コード最適化のメカニズムを理解するために、研究チームは、図 2 に示すように、LLM コンパイラ モデルで命令の微調整を実行し、コンパイラの最適化をシミュレートしました。 そのアイデアは、ランダムに生成されたコンパイラ最適化シーケンスをこれらのプログラムに適用することにより、最適化されていないシード プログラムの限られたコレクションから多数の例を生成することです。次に、最適化によって生成されるコードを予測するようにモデルをトレーニングし、最適化を適用した後のコード サイズを予測するようにモデルをトレーニングしました。 タスクの仕様。 最適化されていない LLVM-IR (clang フロントエンドによる出力)、最適化パスのリスト、および開始コード サイズを指定して、これらの最適化を適用した後の結果のコードとコード サイズを生成します。 このタスクには 2 つのタイプがあります。1 つ目では、モデルはコンパイラ IR を出力することを期待し、2 つ目では、モデルはアセンブリ コードを出力することを期待します。入力 IR、最適化プロセス、コード サイズはどちらのタイプでも同じで、ヒントによって必要な出力形式が決まります。 コードサイズ。 コード サイズを測定するために、IR 命令の数とバイナリ サイズという 2 つの指標が使用されます。バイナリ サイズは、IR またはアセンブリをオブジェクト ファイルにダウングレードした後、.TEXT セグメント サイズと .DATA セグメント サイズの合計として計算されます。 .BSS セグメントはディスク上のサイズに影響を与えないため、除外します。 パスを最適化します。 この作業では、研究チームは LLVM 17.0.6 をターゲットにしており、パスをモジュール、関数、ループなどのさまざまなレベルに分類し、パスの変換と分析を行う新しいプロセス マネージャー (PM、2021) を使用しています。 。変換パスは特定の入力 IR を変更しますが、分析パスは後続の変換に影響を与える情報を生成します。 opt に使用できる 346 個のパス パラメーターのうち、使用する 167 個を選択しました。これには、すべてのデフォルトの最適化パイプライン (例: module (default))、個々の最適化変換パス (例: module (constmerge)) が含まれますが、非最適化ユーティリティ パス (例: module (dot-callgraph)) は除外され、セマンティクス変換パスは保持されません。 (モジュール(内部化)など)。 分析パスには副作用がなく、必要に応じて依存する分析パスを挿入するためにパスマネージャーに依存しているため、分析パスは除外されます。パラメーターを受け入れるパスの場合は、デフォルト値を使用します (例: module (licm))。表 9 には、使用されたすべてのパスのリストが含まれています。 LLVM の opt ツールを使用してパス リストを適用し、clang を使用して結果の IR をオブジェクト ファイルにダウングレードします。リスト 1 に、使用されるコマンドを示します。 データセット。研究チームは、表 2 にまとめた最適化されていないプログラムに 1 ~ 50 のランダムな最適化パスのリストを適用することで、コンパイラー シミュレーション データセットを生成しました。各パス リストの長さは均一かつランダムに選択されます。パス リストは、上記の 167 パス セットから均一にサンプリングして生成されます。コンパイラーのクラッシュまたは 120 秒後のタイムアウトの原因となるパス リストは除外されます。 llmコンパイラFTD:ダウンストリームコンパイルタスクを拡張するintruction最適化フラグのためのインストラクション微調整操作コンパイラフラグは、ランタイムパフォーマンスとコードサイズに大きな影響を与えます。研究チームは、LLVM の IR 最適化ツールのフラグを選択する下流タスクを実行して、最小のコード サイズを生成するように LLM コンパイラー FTD モデルをトレーニングしました。
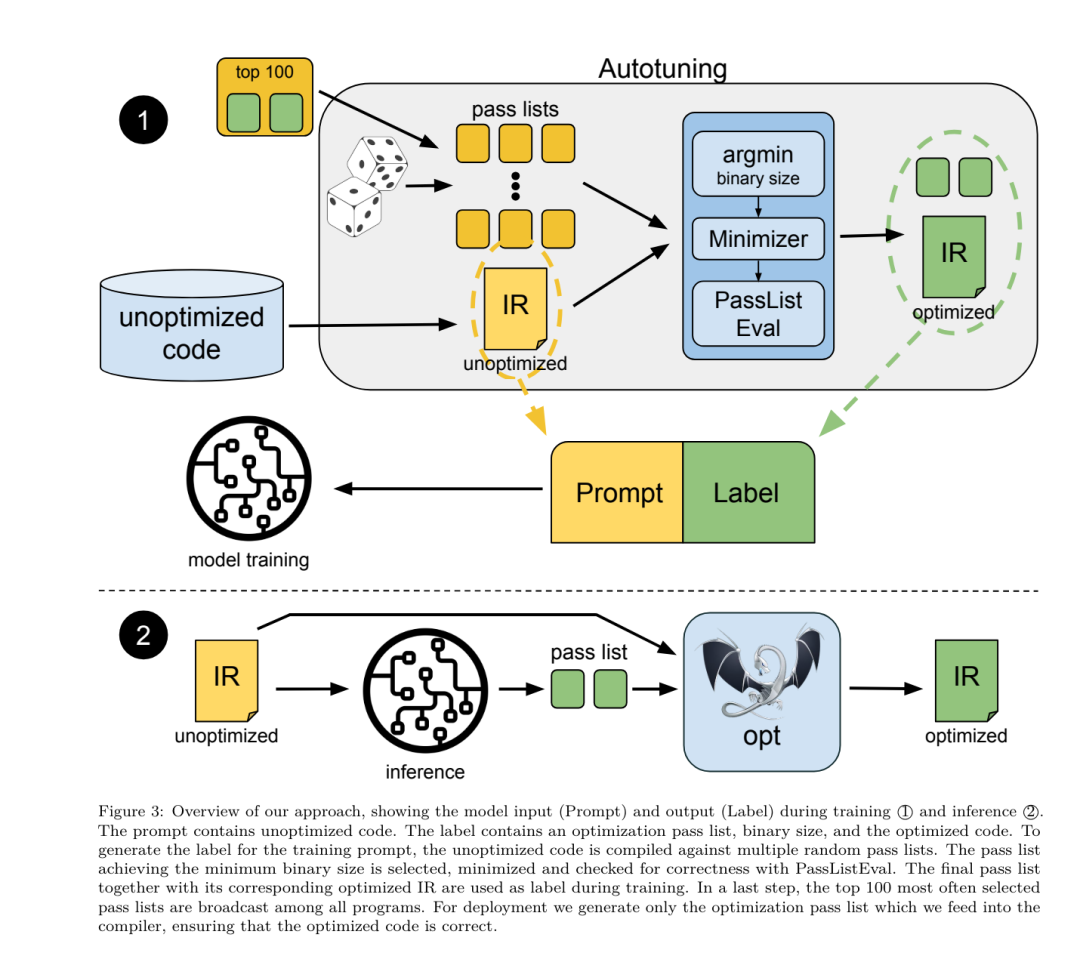
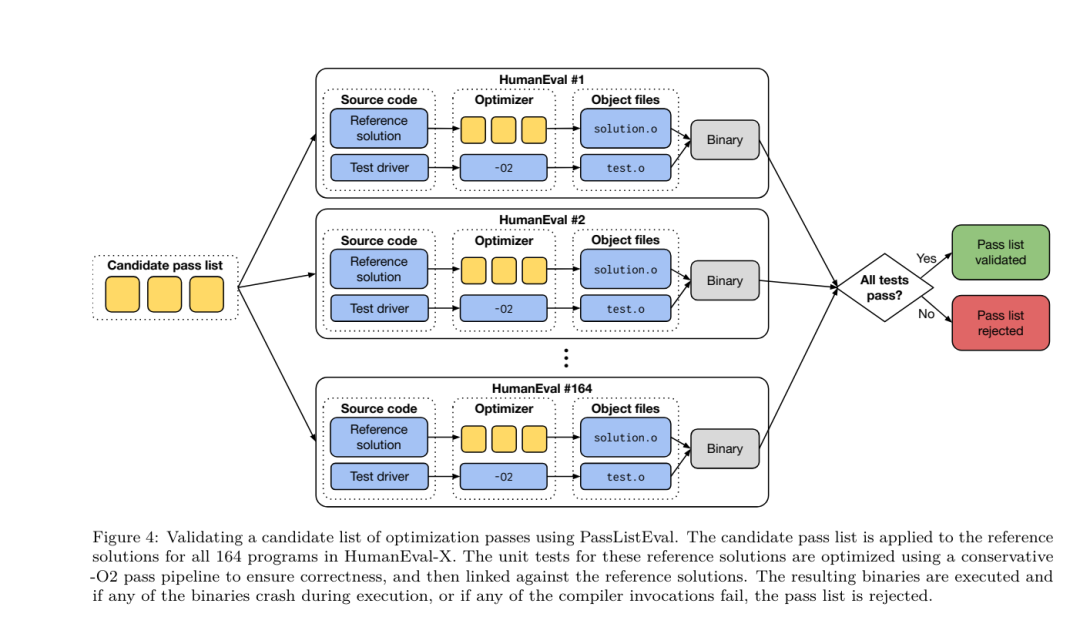
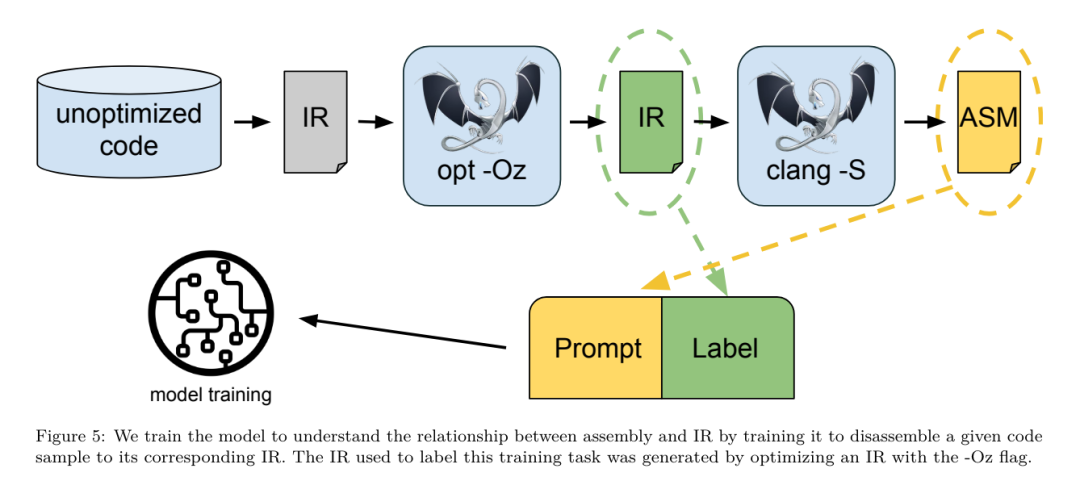
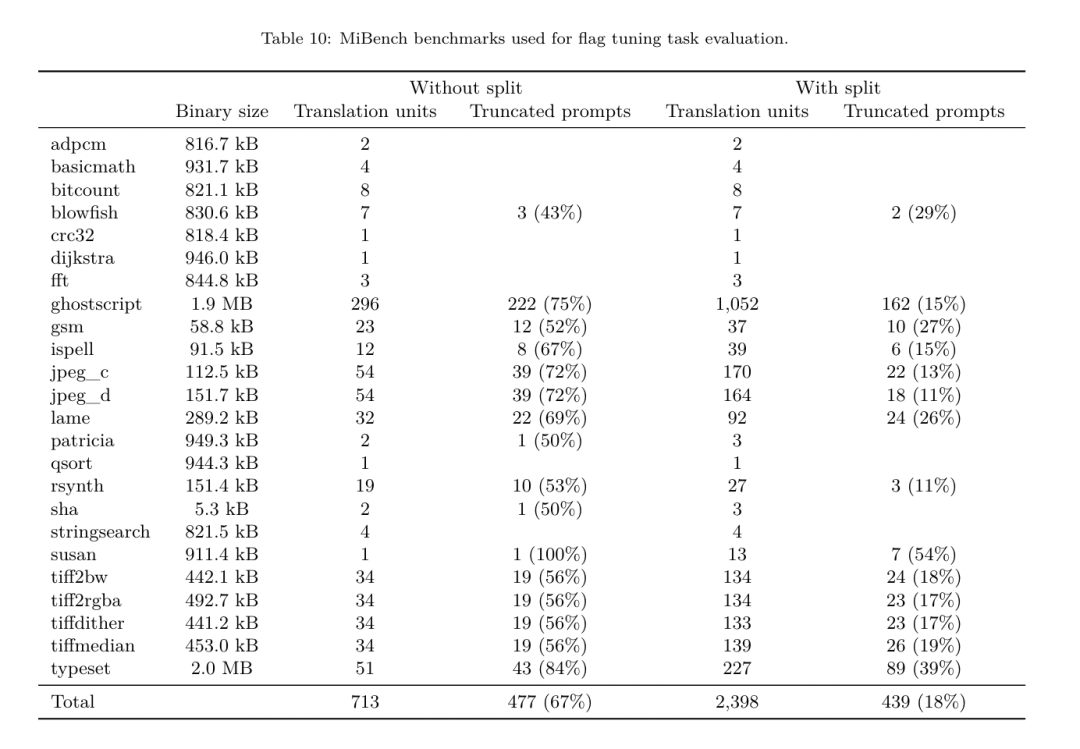
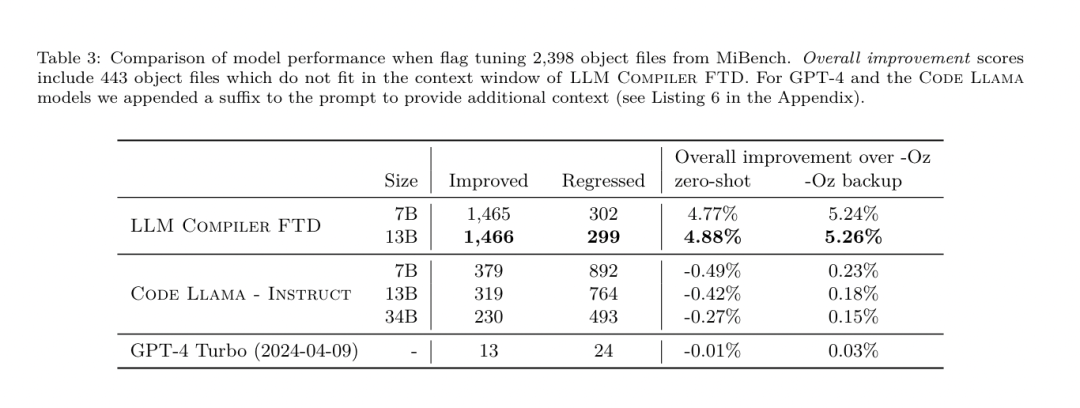
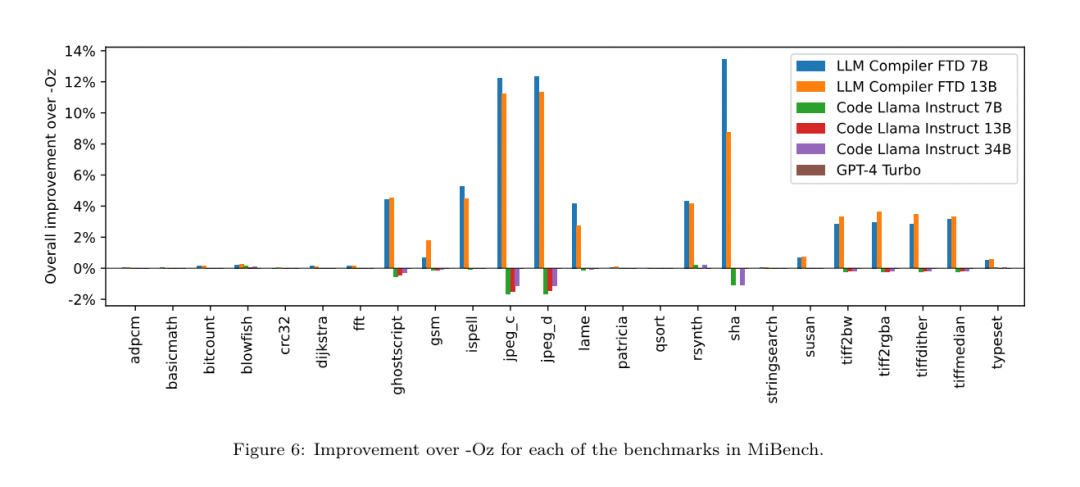
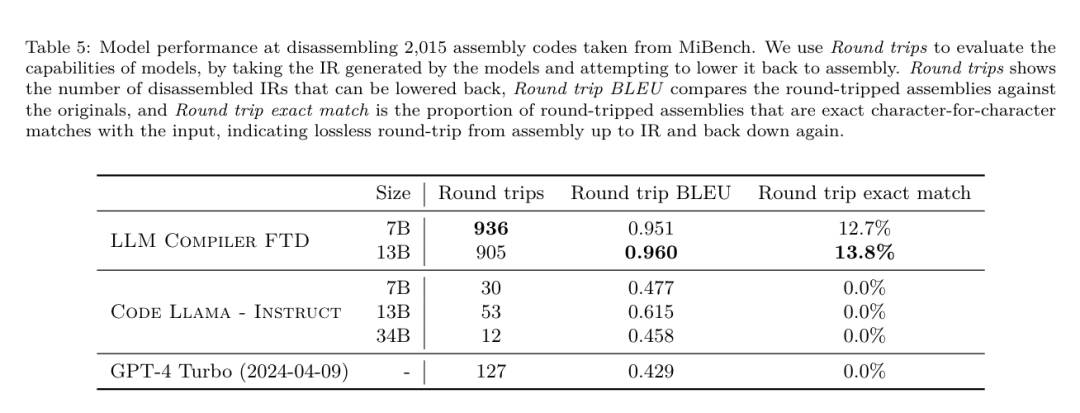
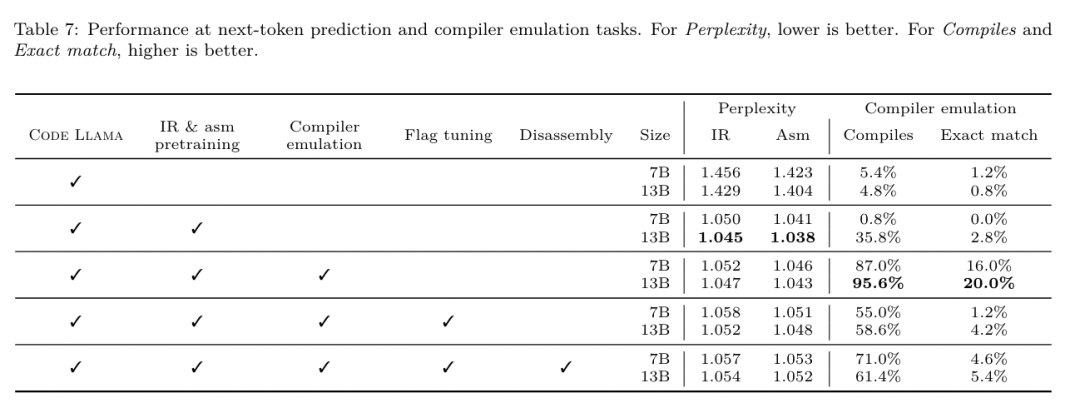
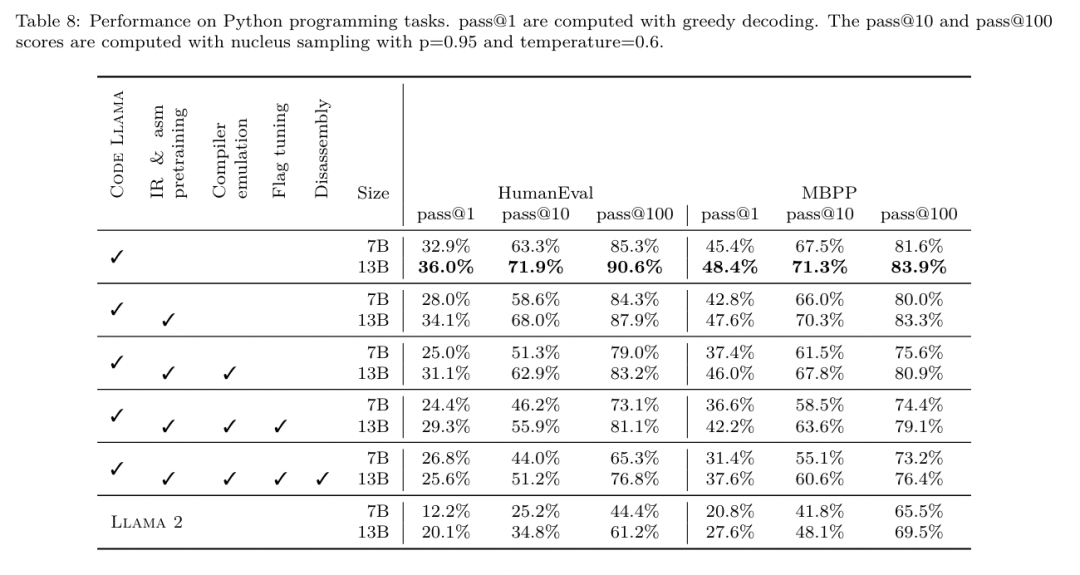
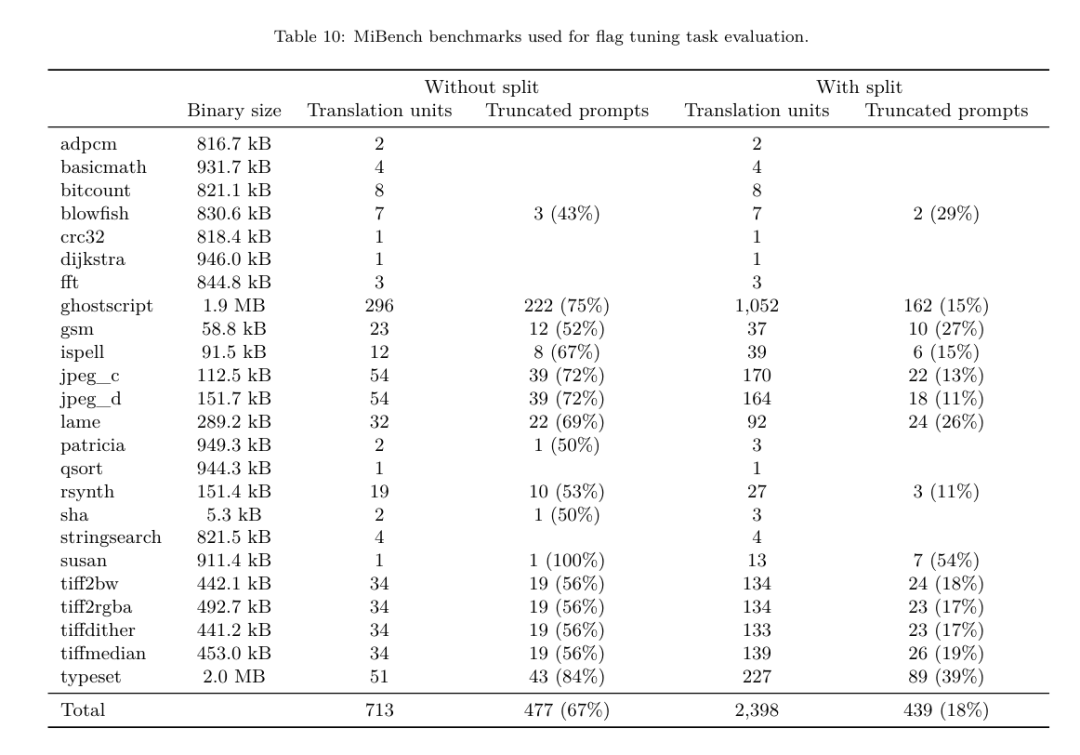
フラグ調整された機械学習手法はこれまでに良好な結果を示してきましたが、異なるプログラム間での一般化には困難がありました。以前の作業では、さまざまな構成を試して最もパフォーマンスの高いオプションを見つけるために、新しいプログラムを何十回も何百回もコンパイルする必要があることがよくありました。研究チームは、フラグを予測して未確認プログラムのコード サイズを最小限に抑えることにより、このタスクのゼロショット バージョンで LLM コンパイラ FTD モデルをトレーニングおよび評価しました。 彼らのアプローチは、選択したコンパイラーや最適化メトリクスに依存せず、将来的には実行時のパフォーマンスをターゲットにする予定です。現在、コード サイズを最適化することでトレーニング データの収集が簡素化されています。 タスクの仕様。研究チームは、最適化されていない LLVM-IR (clang フロントエンドによって生成された) を LLM コンパイラー FTD モデルに提示し、適用する必要がある opt フラグのリスト、これらの最適化が適用される前後のバイナリ サイズ、および入力コードで使用できない場合の出力コード 最適化されていないバイナリ サイズのみを含む短い出力メッセージを生成するように改良が加えられました。 彼らは、コンパイラ シミュレーション タスクと同じ制限付き最適化パスのセットを使用し、同じ方法でバイナリ サイズを計算しました。 図 3 は、トレーニング データの生成に使用されるプロセスと、推論時にモデルがどのように使用されるかを示しています。 評価中に必要なのは、生成されたパスリストのみです。モデル出力からパス リストを抽出し、指定されたパラメーターを使用して opt を実行します。その後、研究者はモデルの予測バイナリ サイズの精度を評価し、出力コードを最適化できますが、これらは補助的な学習タスクであり、使用には必須ではありません。 正しさ。 LLVM オプティマイザーは確実ではなく、最適化パスを予期しない順序またはテストされていない順序で実行すると、モデルの有用性を低下させる微妙な正確性エラーが露呈する可能性があります。このリスクを軽減するために、研究チームは PassListEval を開発しました。これは、プログラムのセマンティクスを壊す、またはコンパイラのクラッシュを引き起こすパス リストを自動的に特定するのに役立つツールです。図 4 にツールの概要を示します。 PassListEval は、候補パスのリストを入力として受け取り、HumanEval-X から取得した 164 個の自己テスト C++ プログラムのスイートでそれを評価します。各プログラムには、「指定された数値ベクトル内の 2 つの数値間の距離が指定されたしきい値より小さいかどうかを確認する」などのプログラミングの課題に対する参照ソリューションと、正確さを検証するための一連の単体テストが含まれています。候補パスのリストを参照ソリューションに適用し、それらをテスト スイートにリンクしてバイナリを生成します。実行時にテストが失敗すると、バイナリはクラッシュします。バイナリがクラッシュするか、コンパイラ呼び出しが失敗した場合、合格候補リストは拒否されます。 データセット。チームは、事前トレーニングに使用された 450 万の最適化されていない IR から派生したフラグ調整されたサンプル データセットで LLM コンパイラー FTD モデルをトレーニングしました。各プログラムのベスト パス リストの例を生成するために、図 3 に示すように、広範な反復コンパイル プロセスが実行されました。 1. 研究チームは大規模なランダム検索を使用して、プログラムの最初の候補ベストパスリストを生成します。各プログラムについて、前述の 167 個の検索可能なパスのセットから均一にサンプリングされた、最大 50 個のパスのランダム リストを独自に生成しました。プログラムのパス リストを評価するたびに、結果のバイナリ サイズを記録し、最小のバイナリ サイズを生成する各プログラムのパス リストを選択しました。彼らは 220 億の独立したコンピレーションを実行し、プログラムごとに平均 4,877 を実行しました。 2. ランダム検索によって生成されたパス リストには冗長なパスが含まれる場合がありますが、最終結果には影響しません。さらに、一部のパス順序は交換可能であり、順序を変更しても最終結果には影響しません。これらはトレーニング データにノイズを導入するため、最小化プロセスを開発し、それを各パス リストに適用しました。 最小化には、冗長パスの削除、バブルソート、挿入検索の 3 つのステップが含まれます。冗長パスの削除では、個々のパスを繰り返し削除してバイナリ サイズに影響を与えているかどうかを確認し、そうでない場合は破棄することで、最適なパス リストを最小化します。パスがドロップされなくなるまで、このプロセスを繰り返します。次に、バブル ソートは、キーワードに基づいてパスを並べ替え、パスのサブシーケンスに統一された順序付けを提供しようとします。最後に、挿入ソートは、パス リスト内の各パスをループし、その前に 167 個の検索パスのそれぞれを挿入しようとすることにより、ローカル検索を実行します。そうすることでバイナリ サイズが改善される場合は、この新しいパス リストを保持してください。最小化パイプライン全体は、固定点に到達するまでループされます。最小化されたパス リストの長さの分布を図 9 に示します。パス リストの平均長は 3.84 です。3. 前述の PassListEval を最適パス候補のリストに適用します。このようにして、彼らは、コンパイル時エラーまたは実行時エラーを引き起こす可能性のある 1,704,443 個の一意のパス リストのうち 167,971 個 (9.85%) を特定しました4。最も一般的な 100 個の最適なパス リストをすべてのプログラムにブロードキャストし、更新します。改善が見つかった場合は、各プログラムのベストパスリスト。その後、単一ベスト パス リストの総数は 1,536,472 から 581,076 に減少しました。 上記の自動チューニング パイプラインにより、-Oz と比較して幾何平均 7.1% のバイナリ サイズの削減が行われました。図 10 は、シングルパスの周波数を示しています。彼らにとって、この自動チューニングはあらゆるプログラム最適化のゴールドスタンダードとして機能します。バイナリ サイズの削減は大幅ですが、これには 21,000 CPU 日を超える計算コストで 280 億の追加コンパイルが必要でした。フラグ チューニング タスクを実行するための LLM コンパイラ FTD の命令微調整の目標は、コンパイラを何千回も実行することなく、自動チューナーのパフォーマンスの一部を達成することです。 コードをアセンブリ言語から、アプリケーション コードに直接統合されたライブラリ コードや、レガシー コードを新しいアーキテクチャ。逆コンパイルの分野では、バイナリ実行可能ファイルから可読で正確なコードを生成する機械学習技術の適用が進歩しました。この研究で研究チームは、LLM コンパイラー FTD が微調整を通じてどのように逆アセンブリを実行できるかを示し、アセンブリ コードとコンパイラー IR の関係を学習します。課題は、図 5 に示すように、clang -xir - -o - -S の逆変換を学習することです。 往復テスト。逆アセンブリに LLM を使用すると、正確性の問題が発生する可能性があります。ブーストされたコードは等価性チェッカーを使用して検証する必要がありますが、常に可能であるとは限らず、手動による正確性の検証または信頼性を得るために十分なテスト ケースが必要です。ただし、正確さの下限はラウンドトリップ テストを通じて見つけることができます。つまり、リフトされた IR をアセンブリ コードに再コンパイルすることにより、アセンブリ コードが同じであれば、IR は正しいことになります。これは、LLM の結果を使用するための簡単なパスを提供し、逆アセンブルされたモデルの有用性を測定する簡単な方法です。 タスクの仕様。研究チームはモデルのアセンブリ コードを入力し、対応する逆アセンブリ IR を出力するようにトレーニングしました。このタスクのコンテキスト長は、入力アセンブリ コードの場合は 8k トークン、出力 IR の場合は 8k トークンに設定されました。 データセット。彼らは、前のタスクで使用されたデータセットからアセンブリ コードと IR のペアを導き出しました。彼らの微調整データセットには 470 万のサンプルが含まれており、入力 IR は x86 アセンブリに削減される前に -Oz を使用して最適化されています。 データは、Code Llama、Llama、および Llama 2 と同じトークナイザーを使用して、バイト ペア エンコードによってトークン化されます。 4 つのトレーニング フェーズすべてに同じトレーニング パラメーターを使用します。彼らは、Code Llama ベース モデルと同じトレーニング パラメーターのほとんどを使用し、β1 と β2 の値が 0.9 と 0.95 の AdamW オプティマイザーを使用しました。彼らは、1000 ステップのウォームアップ ステップでコサイン スケジューリングを使用し、最終学習率をピーク学習率の 1/30 に設定しました。 Code Llama 基本モデルと比較して、チームは単一シーケンスのコンテキスト長を 4096 から 16384 に増加しましたが、バッチ サイズは 400 万トークンで一定に保ちました。より長いコンテキストに対応するために、学習率を 2e-5 に設定し、RoPE 位置埋め込みのパラメーターを変更し、周波数を基本値 θ=10^6 にリセットしました。これらの設定は、Code Llama 基本モデルの長いコンテキスト トレーニングと一致しています。 研究チームは、フラグの調整と逆アセンブリのタスク、コンパイラーのシミュレーション、次のトークンの予測、およびソフトウェア エンジニアリングのタスクに関する LLM コンパイラー モデルのパフォーマンスを評価します。 メソッド。彼らは、目に見えないプログラムの最適化フラグを調整するタスクにおける LLM Compiler FTD のパフォーマンスを評価し、それを GPT-4 Turbo および Code Llama - Instruct と比較します。各モデルで推論を実行し、モデル出力から最適化パスのリストを抽出します。次に、このパス リストを使用して特定のプログラムを最適化し、バイナリ サイズを記録します。ベースラインは、-Oz で最適化されたときのプログラムのバイナリ サイズです。 GPT-4 Turbo および Code Llama - Instruct の場合、ヒントの後にサフィックスを追加して、問題と予想される出力形式を詳しく説明するための追加のコンテキストを提供します。モデルによって生成されたすべてのパス リストは PassListEval を使用して検証され、検証が失敗した場合は代替として -Oz が使用されます。モデルによって生成されたパス リストの正確性をさらに検証するために、最終的なプログラム バイナリをリンクし、保守的な -O2 最適化パイプラインを使用して最適化されたベンチマーク出力に対してその出力を差分テストしました。 データセット。研究チームは、MiBench ベンチマーク スイートから抽出した 2,398 個のテスト キューを使用して評価を実施しました。これらのヒントを生成するために、24 の MiBench ベンチマークを構成する 713 個の翻訳ユニットをすべて取得し、各ユニットから最適化されていない IR を生成し、それらをヒントにフォーマットします。生成されたヒントが 15,000 トークンを超える場合、llvm-extract を使用して、その翻訳単位を表す LLVM モジュールを関数ごとに 1 つずつ小さなモジュールに分割します。その結果、1,985 個のヒントが 15,000 トークンのコンテキスト ウィンドウに収まり、443 個の翻訳単位が残ります。 不適切。パフォーマンス スコアを計算する際、除外された 443 個の翻訳単位に -Oz を使用しました。表 10 はベンチマークをまとめたものです。 結果。表 3 は、フラグ調整タスクにおけるすべてのモデルのゼロショット パフォーマンスを示しています。 LLM コンパイラ FTD モデルのみが -Oz よりも改善されており、13B パラメータ モデルはより小さいモデルよりわずかに優れており、61% の確率で -Oz よりも小さなオブジェクト ファイルを生成します。 場合によっては、モデルによって生成されたパス リストにより、ターゲット ファイル サイズが -Oz よりも大きくなることがありました。たとえば、LLM Compiler FTD 13B では 12% のケースで機能低下が発生します。これらの機能低下は、プログラムを 2 回コンパイルするだけで回避できます。1 回目はモデルによって生成されたパス リストを使用し、もう 1 回目は -Oz を使用して、最良の結果が得られるパス リストを選択します。 -Oz と比較した低下を排除することで、これらの -Oz バックアップ スコアは、-Oz と比較した LLM Compiler FTD 13B の全体的な改善を 5.26% に増加させ、Code Llama - Instruct および GPT-4 Turbo が -Oz と比較してわずかな改善を達成できるようにします。図 6 は、さまざまなベンチマークにおける各モデルのパフォーマンスの内訳を示しています。 バイナリサイズの精度。モデルによって生成されたバイナリ サイズの予測は実際のコンパイルには影響しませんが、研究チームは最適化の前後でバイナリ サイズを予測するモデルのパフォーマンスを評価し、各モデルが最適化をどの程度理解しているかを理解できます。図 7 に結果を示します。 LLM Compiler FTD のバイナリ サイズ予測は実際の状況とよく相関しており、7B パラメータ モデルは、最適化されていないバイナリ サイズと最適化されたバイナリ サイズに対してそれぞれ 0.083 と 0.225 の MAPE 値を達成しています。 13B パラメータ モデルの MAPE 値は同様で、それぞれ 0.082 と 0.225 でした。 Code Llama - Instruct および GPT-4 Turbo のバイナリ サイズ予測は現実とほとんど相関がありません。研究者らは、LLM コンパイラ FTD では、最適化されたコードの方が、最適化されていないコードよりもエラーがわずかに高いことに気づきました。特に、LLM コンパイラ FTD は、最適化の有効性を過大評価する傾向があり、その結果、バイナリ サイズが実際よりも小さくなることが予測されます。 アブレーションの研究。表 4 は、トレーニング データと同じ分布からの 500 キューの小さなホールドアウト検証セット (ただしトレーニングには使用されません) でのモデルのパフォーマンスのアブレーション スタディを示しています。彼らは、図 1 に示すトレーニング パイプラインの各段階でフラグ調整トレーニングを実行し、パフォーマンスを比較しました。示されているように、分解トレーニングでは、パフォーマンスが平均 5.15% から 5.12% にわずかに低下しました (-Oz よりも改善)。また、セクション 2 で説明したトレーニング データの生成に使用されるオートチューナーのパフォーマンスも示します。 LLM コンパイラ FTD は、オートチューナーのパフォーマンスの 77% を達成します。 メソッド。研究チームは、アセンブリ コードを LLVM-IR に逆アセンブルする際に、LLM で生成されたコードの機能の正確さを評価します。彼らは LLM Compiler FTD を評価し、Code Llama - Instruct および GPT-4 Turbo と比較し、これらのモデルから最高のパフォーマンスを引き出すには追加のヒント サフィックスが必要であることを発見しました。 サフィックスは、タスクに関する追加のコンテキストと予想される出力形式を提供します。モデルのパフォーマンスを評価するために、モデルによって生成された逆アセンブリ IR をアセンブリに戻すラウンドトリップ ダウングレードを行いました。これにより、元のアセンブリの BLEU スコアとラウンドトリップ結果を比較することで、逆アセンブリの精度を評価できます。アセンブリから IR までのロスのない完全な逆アセンブリでは、往復の BLEU スコアは 1.0 (完全一致) になります。 データセット。彼らは、MiBench ベンチマーク スイートから抽出された 2,015 のテスト ヒントを使用して評価し、上記のフラグ調整評価に使用された 2,398 の翻訳単位を取得して、逆アセンブリ ヒントを生成しました。次に、最大 8,000 トークンの長さに基づいてチップをフィルタリングし、モデル出力に 8,000 トークンを許可し、2,015 個が残りました。表 11 にベンチマークをまとめます。 結果。表 5 は、分解タスクにおけるモデルのパフォーマンスを示しています。 LLM Compiler FTD 7B は、LLM Compiler FTD 13B よりもラウンドトリップの成功率がわずかに高くなりますが、LLM Compiler FTD 13B のラウンドトリップ アセンブリ精度 (ラウンドトリップ BLEU) が最も高く、最も頻繁に完全な逆アセンブリが生成されます (往復完全一致)。 Code Llama - Instruct および GPT-4 Turbo では、構文的に正しい LLVM-IR を生成することが困難です。図 8 は、すべてのモデルの往復 BLEU スコア分布を示しています。 アブレーションの研究。表 6 は、以前に使用した MiBench データセットから取得した、500 個のキューからなる小規模なホールドアウト検証セットでのモデルのパフォーマンスのアブレーション スタディを示しています。 彼らは、図 1 に示すトレーニング パイプラインの各段階で逆アセンブリ トレーニングを実行し、パフォーマンスを比較しました。ラウンドトリップ レートは、トレーニング データ スタック全体を通過するときに最も高く、トレーニング ステージごとに減少し続けますが、ラウンドトリップ BLEU は各ステージでほとんど変化しません。 メソッド。研究チームは、次のトークン予測とコンパイラ シミュレーションという 2 つの基本的なモデル タスクについて、LLM コンパイラ モデルのアブレーション研究を実施しました。彼らはトレーニング パイプラインの各段階でこの評価を実行し、連続する各タスクのトレーニングがパフォーマンスにどのような影響を与えるかを理解します。次のトークンを予測するために、LLVM-IR の小さなサンプルとアセンブリ コードのパープレキシティをすべての最適化レベルで計算します。彼らは、生成された IR またはアセンブリ コードがコンパイルされるかどうか、および生成された IR またはアセンブリ コードがコンパイラが生成するものと正確に一致するかどうかという 2 つの指標を使用してコンパイラ シミュレーションを評価します。 データセット。次のトークンの予測には、トレーニング データと同じ分布からの小さなホールドアウト検証データセットが使用されますが、トレーニングには使用されません。これらは、最適化されていないコード、-Oz で最適化されたコード、ランダムに生成されたパス リストなど、最適化レベルを組み合わせて使用します。コンパイラ シミュレーションの場合、セクション 2.2 で説明した方法でランダムに生成されたパス リストを使用して MiBench から生成された 500 個のヒントを使用して評価されました。 結果。表 7 は、すべてのトレーニング ステージにわたる 2 つの基本モデル トレーニング タスク (次のトークン予測とコンパイラ シミュレーション) における LLM コンパイラ FTD のパフォーマンスを示しています。次のトークンの予測パフォーマンスは、IR とアセンブリがほとんど見られない Code Llama の後で急激に上昇し、その後の微調整段階ごとにわずかに低下します。 コンパイラ シミュレーションの場合、Code Llama ベース モデルと事前トレーニングされたモデルは、このタスクでトレーニングされていないため、パフォーマンスが良くありません。コンパイラ シミュレーション トレーニングの直後に最大のパフォーマンスが達成され、LLM コンパイラ FTD 13B によって生成された IR とアセンブリの 95.6% がコンパイルされ、20% がコンパイラと正確に一致します。フラグチューニングと逆アセンブリの微調整を行った後、パフォーマンスが低下しました。 メソッド。 LLM コンパイラ FTD の目的はコード最適化のための基本モデルを提供することですが、ソフトウェア エンジニアリング タスク用にトレーニングされた基本コード Llama モデルに基づいて構築されています。 LLM コンパイラ FTD の追加トレーニングがコード生成のパフォーマンスにどのような影響を与えるかを評価するために、Code Llama と同じベンチマーク スイートを使用して、自然言語プロンプトから Python コードを生成する LLM の機能を評価しました。指定された Python コード セットのペアによって形成される最長のチェーン。 Code Llama と同じ、HumanEval および MBPP ベンチマークを使用します。 結果。表 8 は、Code Llama ベース モデルから始まるすべてのモデル トレーニング ステージとモデル サイズに対する貪欲なデコード パフォーマンス (pass@1) を示しています。また、p=0.95 および温度=0.6 で生成された pass@10 および pass@100 でのモデルのスコアも表示されます。コンパイラ中心の各トレーニング フェーズでは、Python プログラミング能力がわずかに低下します。 HumanEval と MBPP では、追加のフラグ調整と逆アセンブリ微調整の後、LLM コンパイラーの pass@1 パフォーマンスが最大 18% と 5% 低下し、LLM コンパイラー FTD は最大 29% と 22% 低下しました。すべてのモデルは、両方のタスクにおいて依然として Llama 2 を上回っています。 メタ研究チームは、LLM Compilerがコンパイラ最適化タスクで良好に実行し、以前の研究と比較してコンパイラ表現とアセンブリコードの理解を向上させることを実証しました。しかし、まだいくつかの制限があります。主な制限は、入力 (コンテキスト ウィンドウ) のシーケンス長が制限されていることです。 LLM コンパイラーは 16,000 トークンのコンテキスト ウィンドウをサポートしますが、プログラム コードはこれよりもはるかに長くなる可能性があります。たとえば、表 10 に示すように、フラグ チューニング ヒントとしてフォーマットされた場合、MiBench 翻訳単位の 67% がこのコンテキスト ウィンドウを超えました。 この問題を軽減するために、より大きな翻訳単位を個別の関数に分割しますが、これにより実行できる最適化の範囲が制限されますが、それでも分割された翻訳単位の 18% はモデルが大きすぎるため大きすぎます。入力として受け入れられます。研究者は増え続けるコンテキスト ウィンドウを採用していますが、限られたコンテキスト ウィンドウが LLM の一般的な問題として残っています。 2 番目の制限は、すべての LLM に共通する問題であり、モデル出力の精度です。 LLM コンパイラのユーザーは、コンパイラ固有の評価ベンチマークを使用してモデルを評価することをお勧めします。コンパイラにバグがないわけではないため、提案されたコンパイラの最適化は厳密にテストする必要があります。モデルをアセンブリ コードに逆コンパイルするときは、ラウンドトリップ、手動検査、または単体テストを通じてその精度を確認する必要があります。一部のアプリケーションでは、LLM の生成を正規表現に制限したり、正確性を確保するために自動検証と組み合わせたりすることができます。 https://x.com/AIatMeta/status/1806361623831171318
https://ai.meta.com/研究/出版物/メタ-large- language-model-compiler-foundation-models-of-compiler-optimization/?utm_source=twitter&utm_medium=organic_social&utm_content=link&utm_campaign=fair以上が開発者は大喜びです! Meta の LLM コンパイラの最新リリースは 77% の自動チューニング効率を達成の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。






























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



