

分子記述子の応用と課題
分子記述子は分子モデリングで広く使用されています。しかし、AI 支援による分子発見の分野では、自然に適用可能で完全かつオリジナルの分子表現が不足しており、モデルのパフォーマンスと解釈可能性に影響を与えています。
t-SMILESフレームワークの提案
フラグメントベースのマルチスケール分子特性評価フレームワークt-SMILESは、分子特性評価の問題を解決します。このフレームワークは SMILES タイプの文字列を使用して分子を記述し、生成モデルとして配列モデルをサポートします。
t-SMILESのコードアルゴリズム
t-SMILESには、TSSA、TSDY、TSIDの3つのコードアルゴリズムがあります。
実験結果
実験の結果、t-SMILESモデルによって生成された分子は100%の理論的妥当性と高い新規性を有し、SOTA SMILESに基づくモデルよりも優れていることが示されました。
さらに、t-SMILES モデルは過剰適合を回避し、ラベル付きの低リソース データセットでの類似性を維持しながら、より高い新規性を実現します。
出版情報
この研究は、「t-SMILES: a Fragment-based Moelepresentation Framework for de novo ligand design」と題され、6月11日付けの「Nature Communications」に掲載されました。

SMILESに基づく分子表現法の研究
分子の効果的な特性評価は、人工分子の性能に影響を与える重要な要素ですインテリジェンスモデル。
グラフ ニューラル ネットワーク (GNN) は、100% 効率的な分子を生成する機能で人気がありますが、その表現能力には限界があります。
簡易分子線形入力仕様 (SMILES) は、線形表現として、化学的に無効な文字列を生成する傾向があります。 DeepSMILES と SELFIES は代替手段としての改善ですが、まだ問題があります。
さらに、研究では、言語モデル (LM) が、大きくて複雑な分子の学習においてほとんどの GNN よりも優れている可能性があることが示されています。最近、トランスフォーマーに基づいた LM は、人間の筆記に非常に似たテキストを生成する能力を実証しました。
これらのアイデアに触発され、研究者らはフラグメント記述の開始選択肢として SMILES を選択し、高度な自然言語処理テクノロジーと組み合わせてフラグメントベースの分子モデリングタスクを処理しました。これにより、グラフモデルを融合して分子トポロジーと分子トポロジーにさらに注意を払うことができます。 LM 高い学習能力の利点。
SOTA よりも優れた 100% 効果的な新しい分子を生成
そこで、湖南大学のチームは、断片化された分子に基づく新しい分子記述フレームワークである t-SMILES (tree-based SMILES) を提案しました。このフレームワークには、TSSA (共有アトムを使用する t-SMILES)、TSDY (仮想アトムを使用するが ID を使用しない t-SMILES)、および TSID (ID と仮想アトムを使用する t-SMILES) の 3 つの t-SMILES エンコード アルゴリズムが含まれています。

新しく提案された t-SMILES フレームワーク
SMILESと比較すると
t-SMILESは、マルチスケールおよび階層的な分子トポロジーをエンコードするために2つの新しい記号「&」と「^」を導入するだけです。
t-SMILES アルゴリズム
は、理論的には幅広い下部構造スキームをサポートできる、スケーラブルで適応性のあるフレームワークを提供します。
t-SMILESベースのモデル
は、詳細な部分構造情報を処理しながら、高レベルの位相構造情報を学習することができます。
マルチコードシステム
t-SMILESアルゴリズムは、分子記述用のマルチコードシステムを構築できます。
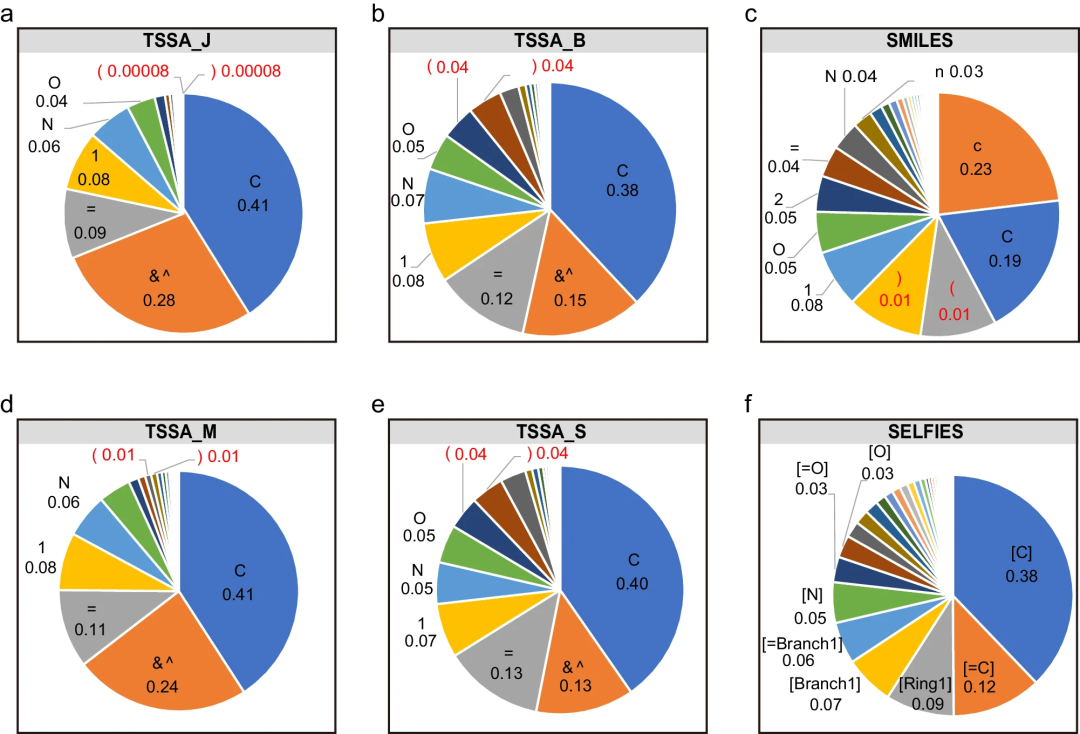
まず、研究者らはt-SMILESのユニークな特徴を掘り下げて体系的に評価しました。続いて、2 つのラベル付き低リソース データセット、JNK332 と AID170633 に対して TSSA と TSDY を使用して実験が行われました。
この研究は、t-SMILES とその代替手段の制限に焦点を当てており、標準のデータ拡張と事前トレーニングされた微調整モデルを活用することで達成されます。 ChEMBL 上の 20 の目標指向タスクは、TSDY、TSSA、TSID を使用して並行して評価されました。同様のセットアップを使用して、t-SMILES とその代替品を比較するために、ChEMBL、Zinc、および QM9 についても徹底的な実験が実行されました。さらに、さまざまなフラグメントベースのベースライン モデルと SOTA GNN モデルが比較されます。
最後に、再構成を伴う SMILES に基づく生成モデルの有効性を確認するためにアブレーション研究が実行されます。 t-SMILES アルゴリズムの適応性と柔軟性を評価するために、JTVAE、BRICS、MMPA、Scaffold など、以前に公開された 4 つの断片化アルゴリズムを使用して分子を分解しました。異なる実験では、分散学習ベンチマーク、目標指向ベンチマーク、および物理化学的特性の Wasserstein 距離メトリクスの 3 つのメトリクスが使用されました。
詳細な比較実験により、t-SMILES モデルによって生成された新しい分子は理論的に 100% 有効であり、SOTA SMILES に基づくモデルよりも優れていることが示されています。 SMILES、DSMILES、SELFIES と比較して、t-SMILES の全体的なソリューションは、データ拡張を使用する場合でも、事前にトレーニングされてから微調整されたモデルを使用する場合でも、過剰適合の問題を回避し、低リソースのデータセットでバランスの取れたパフォーマンスを大幅に向上させることができます。
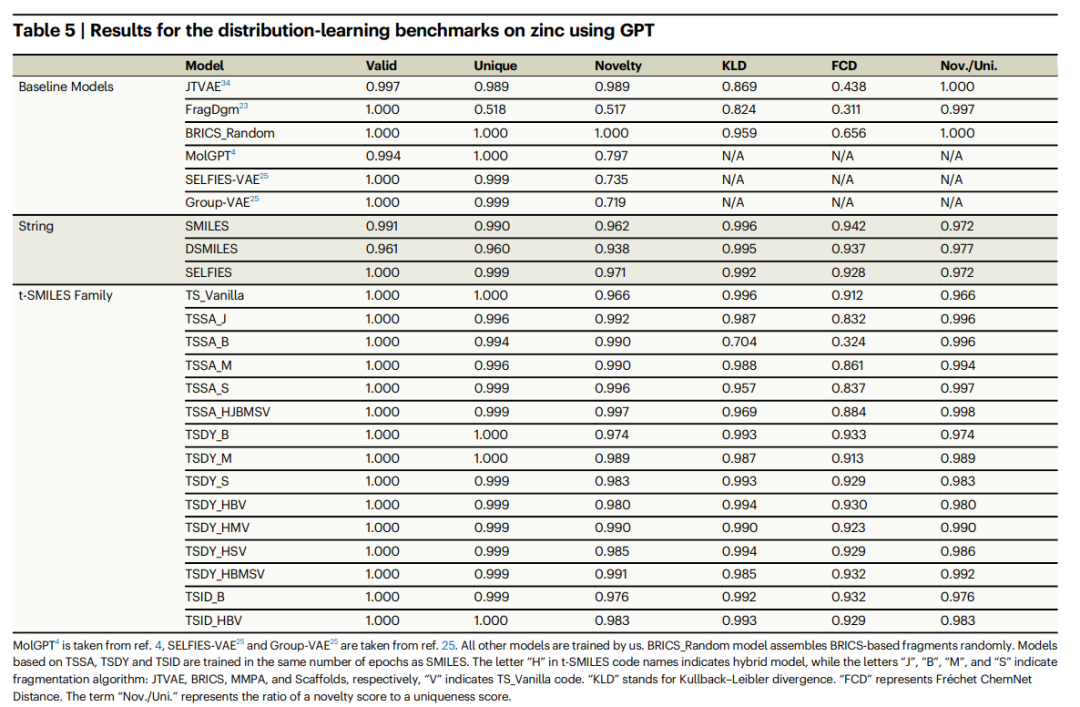
さらに、t-SMILES モデルは分子の物理化学的特性を巧みに捉えることができ、生成された分子がトレーニング分子分布との類似性を確実に維持します。これにより、既存のフラグメントベースおよびグラフベースのベースライン モデルと比較してパフォーマンスが大幅に向上します。特に、目標指向の再構成アルゴリズムを備えた t-SMILES モデルは、目標指向のタスクにおいて SMILES、DSMILES、SELFIES、SOTA CReM よりも明らかな利点を示しています。
制限と改善の余地
注: 表紙はインターネットから取得したものです
以上が分子は 100% 有効であり、リガンドはゼロから設計され、湖南大学はフラグメントベースの分子特性評価フレームワークを提案していますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



