

不管你來自哪個城市,相信在你的記憶中,都有自己的「家鄉話」:吳語柔軟細膩、關中方言質樸厚重、四川方言幽默詼諧、粵語古雅瀟灑……
某種意義上說,方言不只是一種語言習慣,也是一種情感連結、一種文化認同。我們「上網衝浪」遇到的新鮮詞彙中,有不少就是來自各地方言。
當然,有些時候,方言也是一種溝通「壁壘」。
在現實生活中,我們經常會看到方言導致的“雞同鴨講”,比如這個: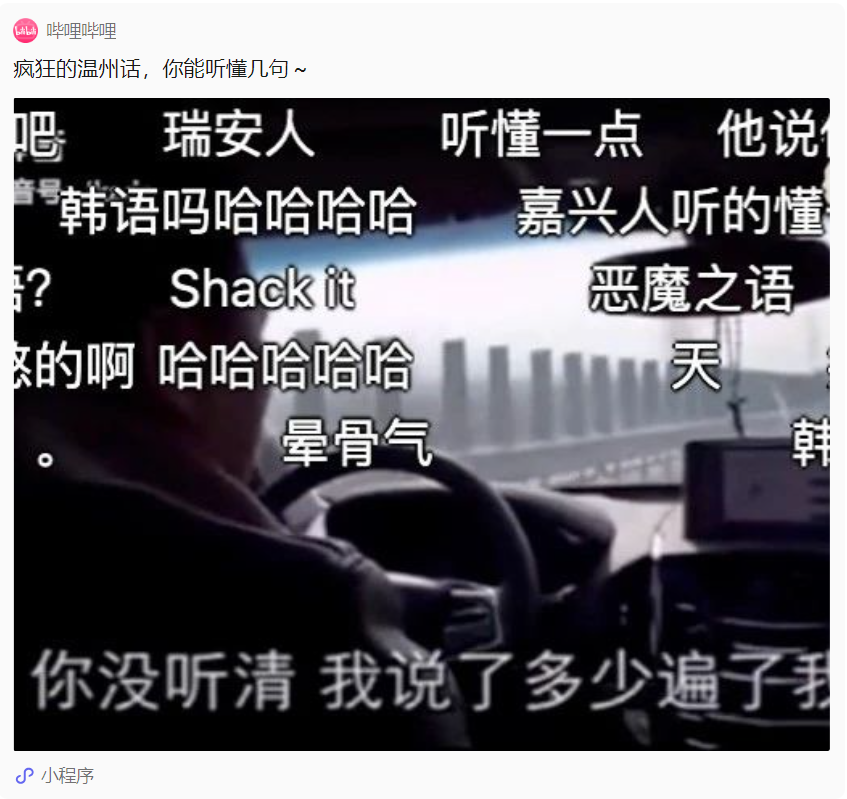
如果你關注最近科技圈的動態就會知道,當前的AI 語音助手已經能達到「即時回覆」的水準,甚至比人類反應還快。而且,AI 已經能夠充分理解人類的情感,自己也能表現出各種感情。
在這樣的基礎上,如果語音助理能夠辨識並理解每一種方言,就能徹底擊破溝通壁壘,與任何群體無障礙進行語言溝通。
實際上,這件事已經有人做了:近日,中國電信人工智慧研究院(TeleAI)發布了業內首個支援30 種方言自由混說的「星辰超多方言語音識別大模型」,可同時辨識理解粵語、上海話、四川話、溫州話等各地方言,是國內支持最多方言的語音辨識大模型。
例如在以下這個會議場景中,面對多種方言的輸入,星辰超多方言語音辨識大模型的辨識準確率達到業界領先。
首先是來自廣東公司的代表,使用了粵語發言: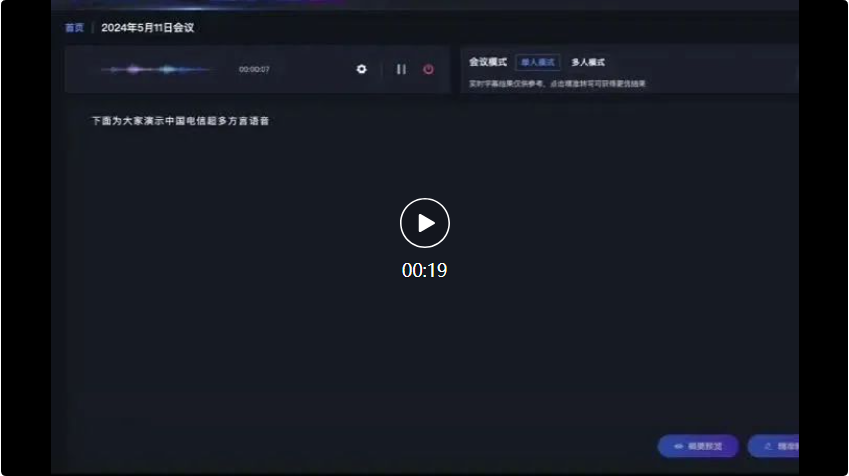
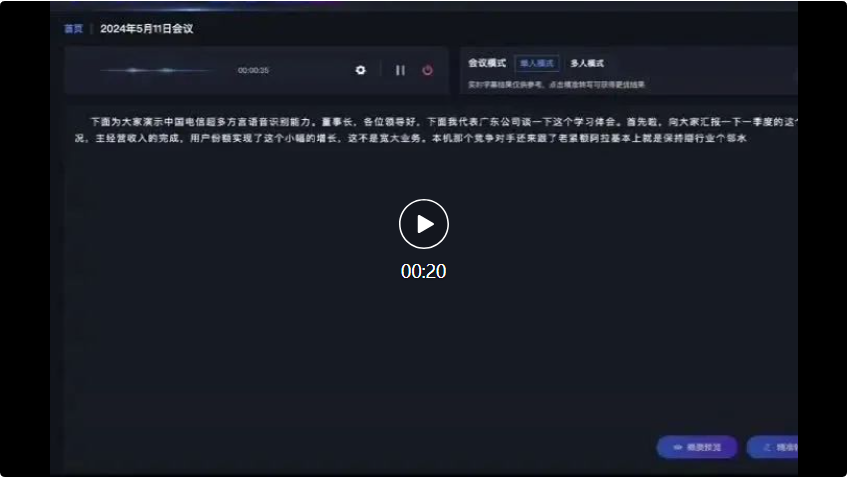 而在接下來的四川方言和山西方言的對話中,星辰超多方言語音辨識大模型也能準確辨識並轉換為文字記錄:
而在接下來的四川方言和山西方言的對話中,星辰超多方言語音辨識大模型也能準確辨識並轉換為文字記錄: 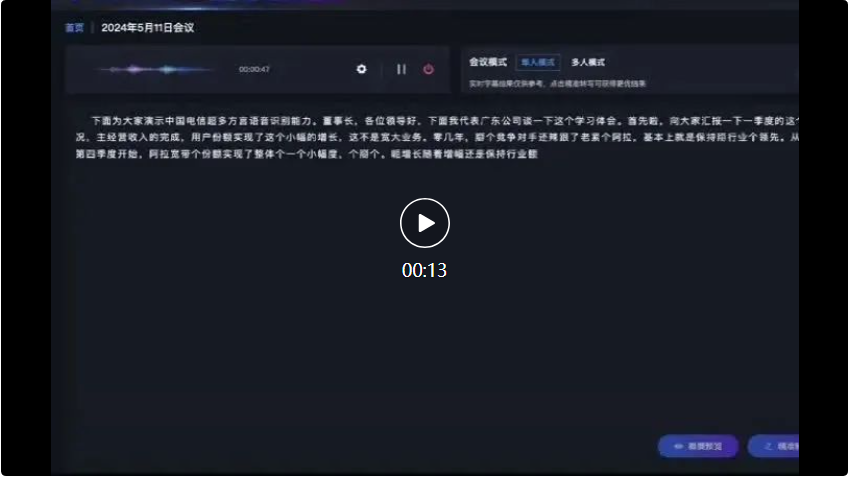
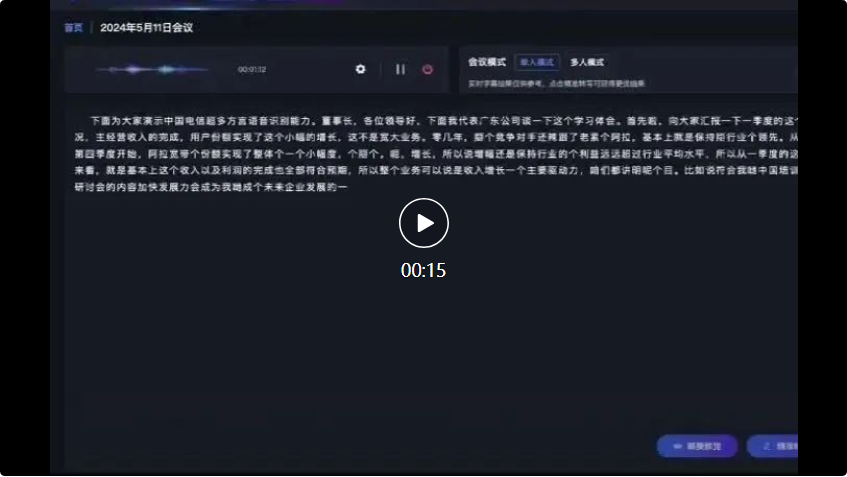
與語音助理對話過的人都知道,針對普通話的語音辨識準確率是相當不錯的,但當面對重口音或方言的時候,辨識準確度會大幅下降,甚至「張冠李戴」。
為了解決這個問題,傳統語音辨識模型的處理方式是針對每種方言單獨訓練一個方言模型,這導致了同一個應用背後需要維護多個方言模型,且無法透過一個模型識別多種方言。然而後者恰恰是現實落地場景中最需要的。
一直以來深耕語音賽道的中國電信,決定挑戰這個命題:打造一個更「通用」的語音辨識大模型。
30 多種方言,大模型如何拿下?
讓大模型一口氣學會 30 幾種方言,並沒有想像中的簡單 —— 挑戰同樣存在於數據、演算法、算力方面。
一方面,因為方言資料量的稀疏,不利用其他方言資料中的共有資訊而單獨訓練某個方言模型,效果往往不盡人意。
經過在語音領域多年的積累,TeleAI 已經構建了超 30 種、超 30 萬小時的高質量方言數據庫,方言數據庫在豐富性和高質量等層面均居於業內前列。高品質語音資料對研究者而言是一大利好,能夠讓模型更有效率、有系統地對方言進行整理歸納。更長遠地看,建構高品質方言資料庫,也是方言保護和研究的基礎。
另一方面的挑戰來自於語音辨識技術。如何讓使用者與大模型對話就像和家人講話一樣自然,無需刻意切換普通話,無需提高音量、放慢語速,是工業界當前追求的新目標。
チャイナテレコムの最高技術責任者(CTO)で人工知能研究所所長の李雪龍氏が主導し、TeleAIは大規模なXingchen音声認識モデルを独自に開発した。チームは、「蒸留 + 拡張」共同トレーニング アルゴリズムを開拓しました。これにより、超大規模マルチシナリオ データセットと大規模パラメータ条件下での事前トレーニング崩壊の問題を解決し、80 層モデルの安定したトレーニングを実現しました。 。同時に、超大規模音声事前トレーニングと複数方言共同モデリングを通じて、単一モデルで 30 の方言の自由な混合音声認識をサポートします。

Xingchen 音声認識大規模モデルは、離散音声表現に基づく業界初のオープンソース大規模音声認識モデルでもあり、「音声からトークン、そしてテキストへ」という新しいモデリング パラダイムを通じて、音声伝送中のビット レートを実現します。推論が数十倍削減されます。
Xingchen 音声認識モデルは、その絶対的に優れたパフォーマンスにより、これまでに多くの国際的な権威ある競技大会で国際的に優勝しています。
たとえば、権威ある国際音声会議である Interspeech 2024 Discrete Speech Unit Modeling Challenge の ASR トラック (自動音声認識、自動音声認識) では、Xingchen 音声認識大規模モデル チームがジョンズ ホプキンス大学カード ウェルを上回っています。・メロン大学やNVIDIAなど国内外の著名な大学や企業がトラック選手権で一気に優勝した。
このコンペティションでチームが提案したシステムソリューションは非常に特徴的です。フロントエンドの事前トレーニングモデル表現調整戦略(フロントエンドモデル)、表現抽出および離散化プロセスを含む、トレーニング中に「3段階」の設計を採用しています。 (Dsicrete トークン プロセス) と多言語認識モデル トレーニング プロセス (離散 ASR モデル) があり、後者の 2 つのプロセスのみが推論段階で使用されます。
表現離散化手法により、モデルは音声推論伝送ビットレートの削減、メモリ使用量の削減、トレーニング効率の向上という目的を達成しながら、他の無関係な情報を削除しながら音声内のタスク関連情報を保持することができます。また、音声の可能なソリューションも提供します。統合モデル構築、マルチモーダル モデル モデリング、およびマルチタスク (ASR、TTS、話者認識など) のための話者のプライバシー保護の方向で提供されます。
業界でよく知られた複数方言音声認識データセットである KeSpeech タスクでは、Xingchen 音声認識大規模モデルが、これまでの最高結果を 20% 上回る記録を破り、単語精度 92.97% を達成しました。 NIST (国立標準技術研究所) が実施した低リソースの広東語電話 Babel 音声認識タスクでも、Xingchen 音声認識大型モデルは業界で最高の結果を達成しました。
一般的なコンピューティング能力の課題に関しては、Xingchen 音声認識大型モデルの研究開発チームにも利点があります。 China Telecom はクラウド コンピューティングの分野に参入した最初の国内通信事業者であり、コンピューティング パワーの構築とコンピューティング パワーのスケジューリングに関する多数のコア テクノロジーを蓄積してきました。さらに、チャイナテレコムは、北京-天津-河北インテリジェント コンピューティング センターや中南インテリジェント コンピューティング センターなど、大規模モデルのトレーニングのニーズを満たすいくつかの公共インテリジェント コンピューティング センターを相次いで稼働させました。
これらの利点に基づいて、Xingchen の大規模な複数方言音声認識モデルが誕生し、単一のモデルは特定の単一の方言しか認識できないというジレンマを打破しました。複数のベンチマーク テストで、Xingchen 超多方言音声認識大型モデルは非常に優れた機能を示しました:
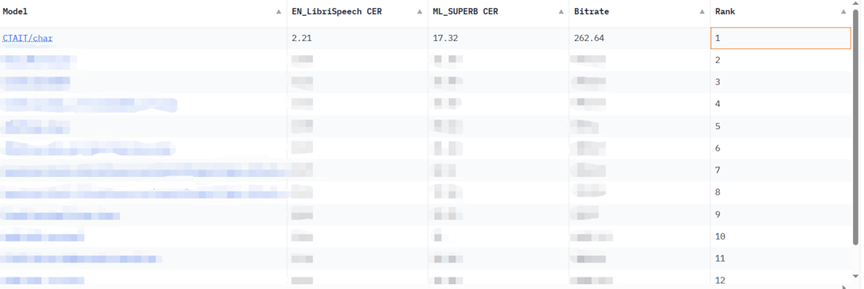
テクノロジーが普及する前に広く使用されていた音声アシスタント、スマート デバイス、カスタマー サービス システムのユーザー エクスペリエンスは、音声認識システムの精度に大きく依存しています。多くの国内外のメーカーがこの分野で熱心に取り組んでいますが、主流言語以外では、何億人ものユーザーがいる中国語の方言が正当な注目を集めておらず、そのシーンの価値が著しく過小評価されていることに誰もが気づくでしょう。
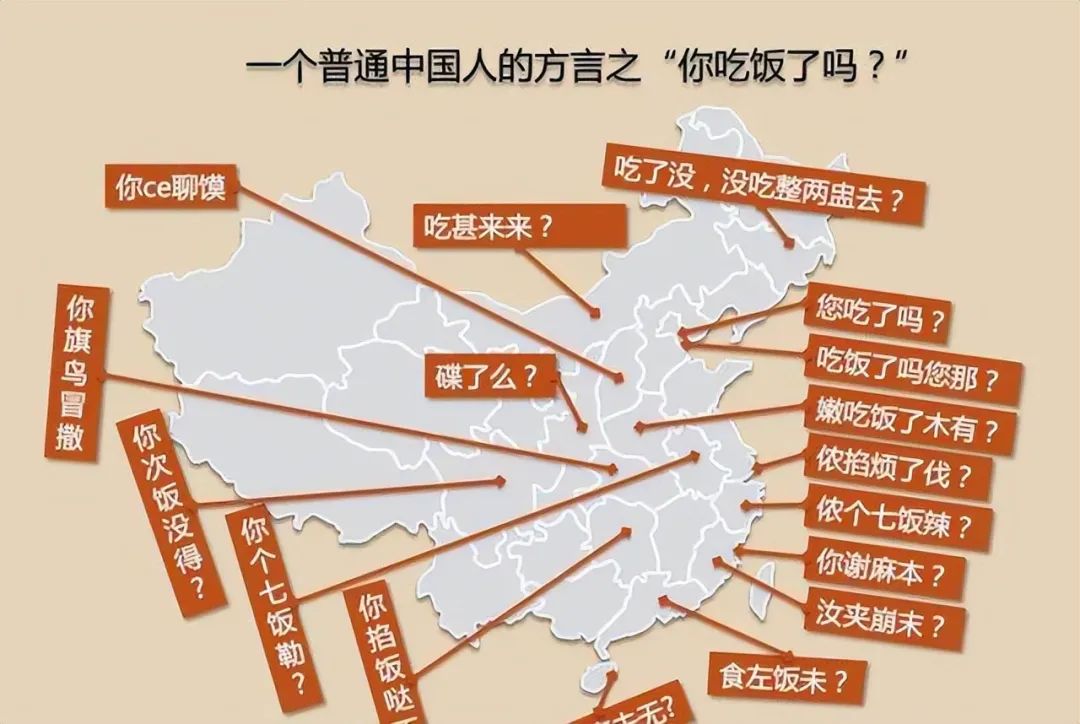
長期的には、Xingchen の大規模な複数方言音声認識モデルの複数方言機能は、非常に幅広い社会生活のシナリオで価値がある可能性があります。高頻度の音声対話を伴うスマートコックピットシナリオを例にとると、さまざまな方言に優れたXingchenの大規模な複数方言音声認識モデルにより、システムはさまざまな方言での音声入力をより正確に認識し、書き写すことができます。特に方言がよく使われる地域では、より自然でスムーズなインタラクティブな体験をもたらすことで、「ニワトリとアヒルの会話」によって引き起こされる誤解を減らすことができます。
感情的な仲間関係の観点から、方言での大型モデルの理解と習熟は、会話型ロボット製品の仲間関係の質を大幅に向上させ、中国語に堪能ではない高齢者やその他のグループの問題を効果的に解決できます。情報サービスにアクセスします。 SF映画『Her』のプロットのように、AIは現実世界での人間関係を超えた質の高いケアを人間に提供できる。 
現在、Xingchen の大規模な複数方言音声認識モデルはさまざまな業界に統合され始めており、新たなアプリケーション シナリオを積極的に模索しています。たとえば、興チェンの大規模な複数方言音声認識モデルは、興チェンの大規模な複数方言にアクセスした後、福建省、江西省、広西チワン族自治区、北京、内モンゴルなどのチャイナテレコムの万豪インテリジェント顧客サービスシステムで試験運用されています。音声認識モデル、Wanhao インテリジェント カスタマー サービスは 30 の方言を数秒で理解し、1 日あたり平均約 200 万件の通話を処理します; インテリジェント カスタマー サービス Yisheng プラットフォームは、Xingchen の超多方言音声の音声理解および分析機能に接続されています。認識モデルにより、31 州を完全にカバーし、毎日 125 万件のカスタマー サービス コールに対応できます。
チャイナテレコムにとって、もう一つの非常に重要な出発点があります。それは、2023 年以前には、人々が大型モデルのテクノロジーについて語るとき、公共の福祉の価値について言及されることはほとんどなくなるということです。しかし 2024 年には、この価値がますます「認識」されるようになります。
大型モデル技術の応用は、方言文化の保護を大きく促進します。我が国の 130 以上の言語のうち、話者が 10,000 人未満の言語が 68 言語、話者が 5,000 人未満の言語が 48 言語、話者が 1,000 人未満の言語が 25 言語あり、話者が十数人または数人しかいない言語もあります。話せる。大規模な音声モデルの参加は、絶滅の危機に瀕している方言を記録して保護し、方言の継承と学習を促進するのに役立ちます。大量の方言コンテンツを含む歴史文書やアーカイブの場合、方言大規模モデルは、文化遺産の損失を防ぐためのデジタル化と整理作業にも役立ちます。
「音声アシスタント」が全開
チャイナテレコムは大型モデル導入の戦いをどうリードできるのか?
大規模モデルを巡る戦いは 1 年半にわたって続いています。現在、業界ではコンセンサスが得られています。大規模モデルの推論のコストが大幅に低下するため、大規模モデルのアプリケーションはパンク期を迎えるでしょう。
国内外の多くの大型モデルプレーヤーの中で、チャイナテレコムは非常に特別な企業です。この新たな段階では、私たちがよく知っているテクノロジー企業と比較して、チャイナテレコムのような通信事業者はリソースとビジネスの面でより多くの利点を持っています。
一方で、オペレーターは豊富なネットワークとコンピューティングリソースを持っているため、トレーニングと推論のコストが比較的低くなります。特に大規模なモデルの構築では、スケールを活用しやすくなります。一方、チャイナテレコムは大規模な顧客ベースと豊富な2C、2H、2B情報サービス事業を有しており、さまざまな分野で大規模な人工知能モデルの実装を迅速に推進し、新たな経済成長ポイントを形成することができます。これらの利点は、通信事業者に人工知能分野への投資を増やし、技術の進歩を促進するインセンティブを与えます。
国内通信事業者の中で、チャイナテレコムはAI分野に初めて導入し、技術革新とコア機能の独立した研究開発の開発路線を堅持しています。昨年以来、Xingchen セマンティック大型モデルから Xingchen マルチモーダル大型モデル、Xingchen 音声認識大型モデルに至るまで、チャイナ テレコムの大規模モデルは常に迅速な反復を維持し、セマンティクス、音声、ビジョン、マルチモダリティの完全なモデルを完成させてきました。ダイナミックな大型モデルのレイアウト。

 このような多用途な中国語音声アシスタントを楽しみにしていますか?
このような多用途な中国語音声アシスタントを楽しみにしていますか?
以上が30 以上の方言に変更した後、中国電信の大規模音声モデルのテストに合格できませんでしたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



