


AIxivコラムは、本サイト上で学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。提出メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
この論文の著者は全員、イリノイ大学アーバナ・シャンペーン校 (UIUC) の Zhang Lingming 教師のチームのメンバーです: Steven Xia博士課程 4 年生、研究の方向性は AI ラージ モデルに基づく自動コード修復です。博士課程 4 年生、研究の方向性は AI ラージ モデルに基づくコード生成です。Soren Dunn、科学研究インターンです。 , 現在、UIUCの3年生です。 Zhang Lingming 先生は現在、UIUC のコンピューター サイエンス学部の准教授で、主にソフトウェア エンジニアリング、機械学習、大規模コード モデルに関連する研究に従事しています。
さらに詳しい情報については、Zhang 先生の個人ホームページをご覧ください: https://lingming.cs.illinois.edu/
Devin (最初の全自動 AI ソフトウェア エンジニア) が提案して以来、ソフトウェア エンジニアリングのための AIエージェントの設計が研究の焦点となっており、エージェント ベースの AI 自動ソフトウェア エンジニアがますます提案されており、SWE ベンチ データ セットで良好なパフォーマンスを達成し、実際の GitHub の問題の多くを自動的に修復しています。
しかし、複雑なエージェント システムは追加のオーバーヘッドと不確実性をもたらします。GitHub の問題を解決するために本当にそのような複雑なエージェントを使用する必要がありますか?エージェント不要のソリューションで彼らのパフォーマンスに近づくことができるでしょうか?
これら 2 つの問題から出発して、イリノイ大学アーバナ シャンペーン校 (UIUC) の Zhang Lingming 教師のチームは、実際の GitHub の問題を解決できる、シンプルで効率的で完全にオープンソースのエージェントレス ソリューションである OpenAutoCoder-Agentless を提案しました。たったの0.34ドルで。 Agentless は、わずか数日で 300 名を超える GitHub スターを GitHub に集め、DAIR.AI の最もホットな ML 論文の週間リストのトップ 3 にランクインしました。

論文: AGENTLESS: Demystifying LLM-based Software Engineering Agents
論文のアドレス: https://huggingface.co/papers/2407.01489
オープンソースコード: https://github. com /OpenAutoCoder/Agentless
AWS の研究科学者、Leo Boytsov 氏は次のように述べています。「Agentless フレームワークは、すべてのオープンソース Agent ソリューションを上回り、SWE Bench Lite のトップレベル (27%) にほぼ達しました。さらに、大幅に低い水準でそれを破りました」すべてのオープン ソース ソリューション。このフレームワークは、パッチの場所を決定するために (LLM にファイル、クラス、関数などの検索を依頼することによって) 階層的なクエリ アプローチを使用しますが、LLM が計画の決定を自動化することはできません。シンプルな 2 段階のアプローチを使用して、コード ベース内のバグを特定して修正するソフトウェア開発の問題。検出フェーズでは、エージェントレスは階層的アプローチを使用して、疑わしいファイル、クラス/関数、および特定の編集場所に徐々に絞り込みます。修正の場合、単純な diff 形式 (オープン ソース ツール Aider から参照) を使用して複数のパッチ候補を生成し、それらをフィルタリングして並べ替えます。

研究者らは、エージェントレスを、最先端のオープンソースおよび商用/クローズドソースプロジェクトを含む既存の AI ソフトウェアエージェントと比較しました。驚くべきことに、エージェントレスは、既存のすべてのオープンソース ソフトウェア エージェントよりも低コストで優れたパフォーマンスを発揮します。エージェントレスは問題の 27.33% を解決しましたが、これはオープンソース ソリューションの中で最も高く、問題ごとに平均 0.29 ドル、すべての問題 (解決可能および未解決の両方) 全体で平均約 0.34 ドルで解決しました。

それだけでなく、エージェントレスには改善の可能性があります。生成されたすべてのパッチを考慮すると、エージェントレスは問題の 41% を解決できます。この上限は、パッチの分類と選択の段階で改善の余地が大きいことを示しています。さらに、エージェントレスは、最良の商用ツール (Alibaba Lingma Agent) でさえ解決できないいくつかの固有の問題を解決できるため、既存のツールを補完するものとして使用できることが示唆されています。
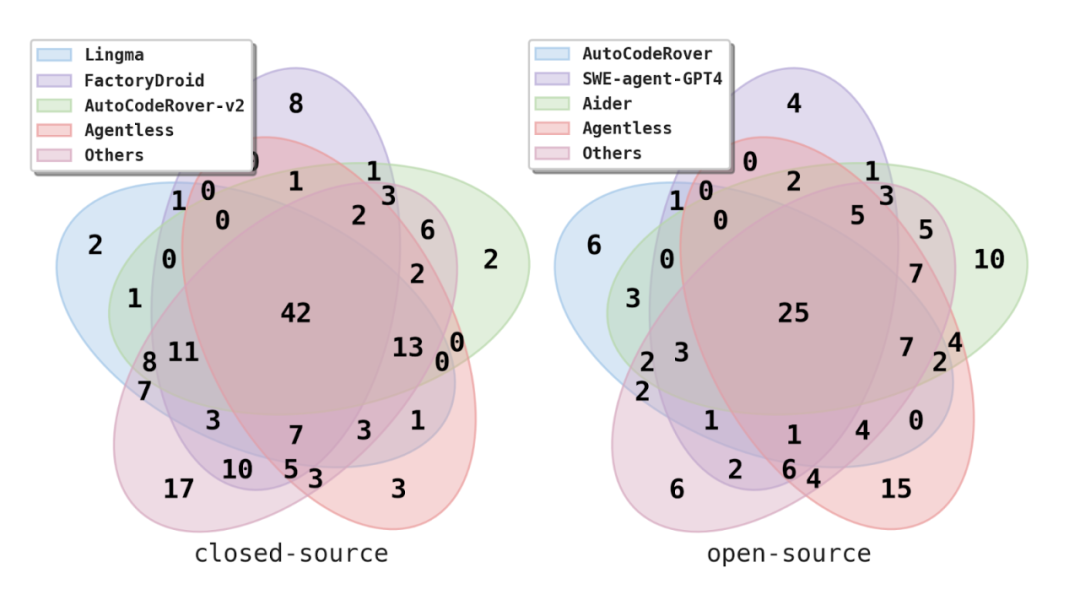
對 SWE-bench Lite 資料集的分析
研究者也對 SWE-bench Lite 資料集進行了人工檢查和詳細分析。
研究發現,SWE-bench Lite 資料集中,有 4.3% 的問題在問題描述中直接給出了完整的答案,也就是正確的修復補丁。而另外 10% 的問題則描述了正確解決方案的確切步驟。這表明,SWE-bench Lite 中的某些問題可能更容易解決。
此外,研究團隊觀察到有 4.3% 的問題在問題描述中包含了使用者提議的解決方案或步驟,但這些方案與開發人員的真實修補程式並不一致。這進一步揭示了該基準測試的潛在問題,因為這些誤導性解決方案可能導致 AI 工具僅透過遵循問題描述來產生不正確的解決方案。
在問題描述品質方面,研究者觀察到,雖然SWE-bench Lite 中大部分的任務都包含了足夠的信息,並且許多任務還提供了失敗示例來復現錯誤,但是仍有9.3% 的問題沒有包含足夠的資訊。例如需要實作一個新的函數或新增一個錯誤訊息,但是特定的函數名稱或特定的錯誤訊息字串並沒有在問題描述中給出。這意味著即使正確實現了底層功能,如果函數名稱或錯誤訊息字串不完全匹配,測試也會失敗。

普林斯頓大學的研究人員,同時也是SWE-Bench 的作者之一,Ofir Press 確認了他們的發現:「Agentless 對SWE-bench Lite 進行了不錯的手動分析。他們認為Lite 上的理論最高得分可能是90.7%。過濾的嚴格問題子集
 針對這些問題,研究者提出了一個嚴格的問題子集SWE-bench Lite-S(包含252 個問題)。具體來說,從 SWE-bench Lite(包含 300 個問題)中排除了那些在問題描述中包含確切補丁、誤導性解決方案或未提供足夠資訊的問題。這樣可以去除不合理的問題,並使基準測試的難度等級標準化。與原始的 SWE-bench Lite 相比,過濾後的基準測試更準確地反映了自動軟體開發工具的真實能力。
針對這些問題,研究者提出了一個嚴格的問題子集SWE-bench Lite-S(包含252 個問題)。具體來說,從 SWE-bench Lite(包含 300 個問題)中排除了那些在問題描述中包含確切補丁、誤導性解決方案或未提供足夠資訊的問題。這樣可以去除不合理的問題,並使基準測試的難度等級標準化。與原始的 SWE-bench Lite 相比,過濾後的基準測試更準確地反映了自動軟體開發工具的真實能力。
結語
儘管基於 Agent 的軟體開發非常有前景,作者們認為技術和研究社群是時候停下來思考其關鍵設計與評估方法,而不是急於發布更多的 Agent。研究者希望 Agentless 可以幫助重置未來軟體工程 Agent 的基線和方向。
以上がオープンソース AI ソフトウェア エンジニアのリストのトップに立つ UIUC のエージェントレス ソリューションは、SWE ベンチの実際のプログラミングの問題を簡単に解決しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



