

4大VLMは皆、やみくもに象に触れようとしているのでしょうか?
最も人気のある SOTA モデル (GPT-4o、Gemini-1.5、Sonnet-3、Sonnet-3.5) に 2 つの線の間にある交差点の数を数えさせてください。それらは人間よりも優れたパフォーマンスを発揮しますか?
答えはおそらくノーです。
GPT-4V の発表以来、ビジュアル言語モデル (VLM) は、大規模モデルの知能を私たちが想像する人工知能のレベルに向けて大きく前進させてきました。
VLM は、画像を理解し、見たものを説明するために言語を使用することができ、これらの理解に基づいて複雑なタスクを実行できます。たとえば、VLM モデルに食卓の写真とメニューの写真を送信すると、2 つの写真からビール瓶の本数とメニューの単価を抽出し、ビールの値段がいくらになるかを計算できます。食事。
VLM は非常に急速に進歩しているため、この写真に不合理な「抽象的な要素」があるかどうかを確認することがモデルの課題になっています。たとえば、アイロンをかけている人がいるかどうかをモデルに確認する必要があります。スピード違反のタクシーの中での服装。

ただし、現在のベンチマーク テスト セットでは、VLM のビジュアル機能が十分に評価されていません。 MMMU を例にとると、問題の 42.9% は絵を見ずに解くことができます。これは、多くの答えがテキストの質問と選択肢だけから推測できることを意味します。第 2 に、VLM が現在実証している機能の大部分は、大規模なインターネット データを「記憶」した結果です。この結果、VLM はテスト セットで非常に高いスコアを獲得しましたが、これはその判断が正しいことを意味するわけではありません。つまり、VLM は人間と同じように画像を認識できるかということです。
この質問に対する答えを得るために、オーバーン大学とアルバータ大学の研究者は、VLM の「視覚テスト」を行うことにしました。検眼医の「視力検査」にヒントを得て、彼らは GPT-4o、Gemini-1.5 Pro、Claude-3 Sonnet、Claude-3.5 Sonnet の 4 つのトップ VLM に一連の「視力検査の質問」を作成するよう依頼しました。

論文タイトル: 視覚言語モデルは盲目である
論文リンク: https://arxiv.org/pdf/2407.06581
プロジェクトリンク: https://vlmsareblind.github.io/
この一連の質問は、たとえば、2 つの線の交点の数を数えたり、どの文字が赤い丸でマークされているかを特定したりするのに、世界に関する知識はほとんど必要ありません。テスト結果は衝撃的で、実際には VLM は「近視」であり、画像の細部が実際にぼやけて見えます。
VLM 盲目ですか? 7 つの主要なタスクは、たった 1 回のテストでわかります
VLM がインターネット データセットから直接「答えをコピー」するのを防ぐために、論文の著者は新しい一連の「視覚テスト」を設計しました。この論文の著者らは、2 つの図形が交差するかどうかなど、空間内の幾何学的図形間の関係を VLM に判断させることを選択しました。なぜなら、白いキャンバス上のこれらのパターンの空間情報は、通常、自然言語では説明できないからです。
人間がこの情報を処理するとき、彼らは「視覚脳」を通じてそれを認識します。しかし、VLM の場合、モデルの初期段階で画像の特徴とテキストの特徴を組み合わせる、つまり、ビジュアル エンコーダーを大規模な言語モデルに統合することに依存します。これは本質的には目のない知識脳です。
予備実験では、私たち一人ひとりがテストした逆さまの「E」視力表など、人間の視力テストに直面したときに、VLM が驚くほど優れたパフォーマンスを発揮することが示されています。
テストと結果
レベル 1: 線の間に交差点が何個あるか数えますか?
論文の著者は、白い背景に 2 つの線分を含む 150 枚の画像を作成しました。これらの線分の x 座標は固定されており、等間隔に配置されていますが、y 座標はランダムに生成されます。 2 つの線分間の交点は 0、1、2 の 3 つだけです。

図 5 に示すように、プロンプト ワードの 2 つのバージョンと線分の太さの 3 つのバージョンのテストでは、すべての VLM がこの単純なタスクで低いパフォーマンスを示しました。最高の精度を持つ

Sonnet-3.5 は 77.33% にすぎません (表 1 を参照)。

より具体的には、2 つのライン間の距離が縮まると、VLM のパフォーマンスが低下する傾向があります (以下の図 6 を参照)。各折れ線グラフは 3 つのキー点で構成されているため、2 つの線の間の距離は、3 つの対応する点のペアの平均距離として計算されます。

この結果は、ChartQA の VLM の高精度とは対照的です。VLM は折れ線グラフの全体的な傾向を特定できるものの、「どの線が交差しているか」などの詳細を確認するために「ズームイン」することはできないことを示しています。 」。
第2レベル: 2つの円の位置関係を決定します
図に示すように、論文の著者は、与えられたサイズのキャンバス上に同じサイズの2つの円をランダムに生成しました。 2 つの円の位置関係には、交差、接、離間という 3 つの状況しかありません。 
驚くべきことに、人間が直感的に認識でき、一目で答えがわかるこのタスクでは、完璧に答えを与える VLM は存在しません (図 7 を参照)。

最高の精度 (92.78%) を持つモデルは Gemini-1.5 です (表 2 を参照)。

実験では、ある状況が頻繁に発生しました。2 つの円が非常に近い場合、VLM はパフォーマンスが低下する傾向がありますが、知識に基づいた推測を行います。以下の図に示すように、Sonnet-3.5 は通常、保守的に「いいえ」と答えます。

図8に示すように、2つの円間の距離が遠く、半径(d = 0.5)ほど広い場合でも、最も精度の悪いGPT-4oでは100%を達成することはできません。正確な。
とはいえ、VLM のビジョンは、2 つの円の間の小さなギャップや交差点を認識できるほど明確ではないようです。

レベル 3: 赤で囲まれた文字は何文字ありますか?
単語内の文字間の距離は非常に小さいため、論文の著者は、VLM が「近視」である場合、赤で囲まれた文字を認識できないだろうと仮説を立てました。
そこで、彼らは「Acknowledgement」、「Subdermatoglyphic」、「tHyUiKaRbNqWeOpXcZvM」などの文字列を選択しました。テストとして、文字列内の文字を丸で囲む赤い丸をランダムに生成します。

テスト結果は、テストされたモデルがこのレベルでは非常に悪いパフォーマンスを示していることを示しています (図 9 と表 3 を参照)。


たとえば、視覚言語モデルは、文字が赤い丸でわずかに隠れている場合に間違いを犯す傾向があります。赤丸の隣の文字を混同することがよくあります。たとえば、モデルは単語を正確に綴ることができますが、単語に文字化けした文字 (「9」、「n」、「©」など) を追加することがあります。

GPT-4o を除くすべてのモデルは、ランダムな文字列よりも単語に対してわずかに優れたパフォーマンスを示しました。これは、単語のスペルを知ることが視覚言語モデルの判断に役立ち、それによって精度がわずかに向上する可能性があることを示唆しています。
Gemini-1.5 と Sonnet-3.5 は、それぞれ 92.81% と 89.22% の精度率を持つ上位 2 つのモデルであり、GPT-4o と Sonnet-3 をほぼ 20% 上回っています。

レベル 4 とレベル 5: 重なっている図形はいくつありますか?正方形の「マトリョーシカ」は何個ありますか?
VLM が「近視」であると仮定すると、「オリンピックの輪」と同様のパターンで、2 つの円の交差部分を明確に見ることができない可能性があります。この目的を達成するために、論文の著者は「オリンピックの輪」に似たパターンの 60 グループをランダムに生成し、重複するパターンがいくつあるかを VLM に数えるよう依頼しました。彼らはまた、さらなるテストのために「オリンピックリング」の五角形バージョンも生成しました。

交差する円の数を数えるときの VLM のパフォーマンスが低いため、著者らはパターンのエッジが交差せず、各形状が別の形状内に完全にネストされている場合をさらにテストしました。彼らは 2 ~ 5 個の正方形からなる「マトリョーシカ」のようなパターンを生成し、VLM に画像内の正方形の総数を数えるように依頼しました。

下の表の真っ赤な×印から、これら 2 つのレベルも VLM にとって乗り越えられない障害であることが簡単にわかります。

ネストされた正方形テストでは、各モデルの精度は大きく異なります。GPT-4o (精度 48.33%) と Sonnet-3 (精度 55.00%) は、少なくとも Gemini-1.5 (精度 80.00%) より優れています。 Sonnet-3.5 (精度 87.50%) 30 パーセントポイント低い。
モデルが重なり合う円や五角形をカウントする場合、この差はさらに大きくなりますが、Sonnet-3.5 は他のモデルよりも数倍優れたパフォーマンスを発揮します。以下の表に示すように、画像が五角形の場合、Sonnet-3.5 の精度 75.83% は Gemini-1.5 の 9.16% を大きく上回ります。
驚くべきことに、テストした 4 つのモデルはすべて、5 つのリングを数えるときに 100% の精度を達成しましたが、リングを 1 つ追加するだけで、精度が大幅にゼロ近くまで低下するのに十分でした。
ただし、五角形を計算する場合、すべての VLM (Sonnet-3.5 を除く) は、5 つの五角形を計算する場合でもパフォーマンスが低下します。 全体として、6 ~ 9 個の形状 (円と五角形を含む) を計算することは、すべてのモデルにとって困難です。

これは、VLM が偏っていて、結果として有名な「オリンピックの輪」を出力する傾向があることを示しています。たとえば、Gemini-1.5 は、実際の円の数に関係なく、試行の 98.95% で結果を「5」と予測します (表 5 を参照)。他のモデルでは、この予測エラーは五角形よりも環の方がはるかに頻繁に発生します。

数量に加えて、VLM には形状の色にもさまざまな「好み」があります。
GPT-4o は、純粋な黒色の形状よりも色付きの形状の方がパフォーマンスが優れていますが、Sonnet-3.5 は、画像サイズが大きくなるにつれて予測の精度が向上します。ただし、研究者が色と画像の解像度を変更しても、他のモデルの精度はわずかに変化するだけでした。
ネストされた正方形を計算するタスクでは、正方形の数がわずか 2 ~ 3 個であっても、GPT-4o と Sonnet-3 の計算は依然として難しいことに注意してください。正方形の数が 4 つ、5 つと増えると、すべてのモデルの精度が 100% に遠く及ばなくなります。これは、形状のエッジが交差していない場合でも、VLM がターゲット形状を正確に抽出することが難しいことを示しています。

レベル 6: テーブルに行が何行あるか数えますか?列は何本ありますか?
VLM はグラフィックのオーバーラップやネストに問題がありますが、タイル パターンとして何が認識されますか?基本的なテスト セット、特に多くの表形式のタスクが含まれる DocVQA では、テストされたモデルの精度は 90% 以上です。この論文の著者は、行数と列数が異なる 444 個のテーブルをランダムに生成し、VLM にテーブル内に何行あるかを数えるよう依頼しました。列は何本ありますか?
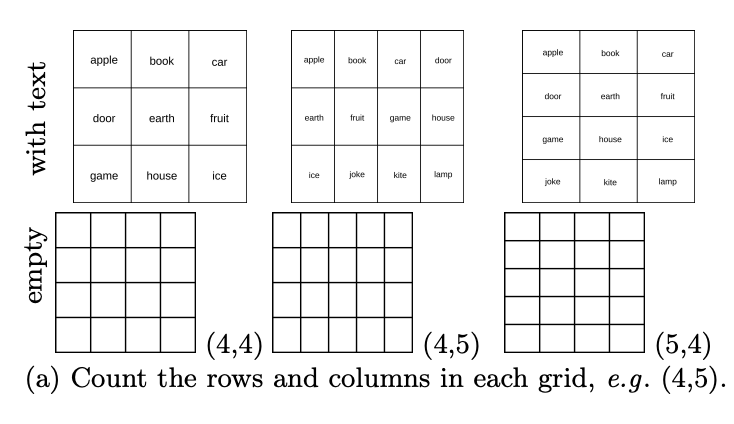
その結果、以下の図に示すように、VLM は基本データ セットで高いスコアを達成しましたが、空のテーブルの行と列をカウントするパフォーマンスも悪かったことがわかります。

具体的には、通常は1〜2小節ずれています。下図に示すように、GPT-4o は 4×5 グリッドを 4×4 として認識し、Gemini-1.5 は 5×5 として認識します。

これは、VLM がテーブルから重要なコンテンツを抽出して DocVQA のテーブル関連の質問に答えることはできるものの、テーブルをセルごとに明確に識別できないことを示しています。
これは、ドキュメント内のテーブルがほとんど空ではなく、VLM が空のテーブルに慣れていないことが原因である可能性があります。興味深いことに、研究者らが各セルに単語を追加してタスクを簡素化した後、すべての VLM で精度の大幅な向上が観察されました。たとえば、GPT-4o は 26.13% から 53.03% に向上しました (表 6 を参照)。ただし、この場合、テスト対象モデルのパフォーマンスはまだ完全ではありません。図 15a および b に示すように、最もパフォーマンスの高いモデル (Sonnet-3.5) は、テキストを含むグリッドで 88.68%、空のグリッドで 59.84% のパフォーマンスを示しました。
そして、ほとんどのモデル (Gemini-1.5、Sonnet-3、および Sonnet-3.5) は、行のカウントよりも列のカウントの方が一貫して優れたパフォーマンスを示します (図 15c および d を参照)。

レベル 7: 出発地から目的地まで直通する地下鉄の路線は何本ありますか?
このテストは、VLM がパスをたどる能力をテストします。これは、モデルが地図やチャートを解釈し、ユーザーが入力画像に追加した矢印などの注釈を理解するために重要です。この目的を達成するために、論文の著者は、それぞれに 4 つの固定駅が含まれる 180 の地下鉄路線図をランダムに生成しました。彼らは VLM に対し、2 つのサイト間に単色パスが何本あるかを数えるように依頼しました。

テスト結果は衝撃的です。たとえ 2 つのサイト間のパスが 1 つに単純化されたとしても、すべてのモデルが 100% の精度を達成することはできません。表 7 に示すように、最もパフォーマンスの高いモデルは精度 95% の Sonnet-3.5 であり、最も悪いモデルは精度 23.75% の Sonnet-3 です。

下の図から、VLM の予測には通常 1 ~ 3 パスの偏差があることがわかります。マップの複雑さが 1 パスから 3 パスに増加するにつれて、ほとんどの VLM のパフォーマンスが低下します。

今日の主流のVLMの画像認識性能が極めて低いという「残酷な事実」に直面して、多くのネチズンはまず「AI弁護人」としての立場を脇に置き、多くの悲観的なコメントを残しました。
あるネチズンは次のように述べています。「SOTA モデル (GPT-4o、Gemini-1.5 Pro、Sonnet-3、Sonnet-3.5) のパフォーマンスが非常に悪いのに、これらのモデルがプロモーションで実際に次のように主張しているのは恥ずかしいことです。たとえば、目の見えない人を助けたり、子供たちに幾何学を教えるために使用することもできます。


悲観的な意見の反対側では、あるネチズンは、これらの悪い結果はトレーニングと微調整で簡単に解決できると信じています。約 100,000 の例と実際のデータでトレーニングすると、問題は解決されます

しかし、「AI 擁護者」も「AI 悲観論者」も、VLM が画像テストで依然として良好なパフォーマンスを示しているという事実を黙認しています。調整することが非常に困難な欠陥。
この論文の著者は、このテストが科学的かどうかについてさらに多くの質問を受けました。

一部のネチズンは、この論文のテストはVLMが「近視」であることを証明していないと信じています。まず、近視の人は細部がぼやけて見えません。これは遠視の症状です。第二に、詳細を見ることができないことは、交差点の数を数えることができないことと同じではありません。空白のグリッドの行と列の数をカウントする精度は、解像度を上げても向上しません。また、画像の解像度を上げても、このタスクを理解するのには役立ちません。さらに、画像の解像度を上げても、このタスクでの重なり合う線や交差点の理解には大きな影響を与えません。
実際、このようなタスクを処理する際にこれらの視覚言語モデル (VLM) が直面する課題は、単なる視覚的な解像度の問題ではなく、VLM の推論能力と画像コンテンツの解釈方法に関係している可能性があります。言い換えれば、たとえ画像の細部がすべてはっきりと見えていたとしても、モデルに正しい推論ロジックや視覚情報の深い理解が欠けている場合、モデルは依然としてこれらのタスクを正確に完了できない可能性があります。したがって、この研究では、単なる画像処理機能ではなく、視覚的な理解と推論における VLM の機能をさらに深く掘り下げる必要があるかもしれません。
一部のネチズンは、人間の視覚が畳み込みによって処理される場合、人間自身も線の交点を判断するテストで困難に遭遇すると信じています。
詳細については、元の論文を参照してください。
参考リンク:
https://arxiv.org/pdf/2407.06581
https://news.ycombinator.com/item?id=40926734
https://vlmsareblind.github.io/
以上がこれらの VLM はすべて盲目なのでしょうか? GPT-4oとSonnet-3.5は「視覚」テストに連続して不合格となったの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



