

Huawei GTS LocMoE+: 高いスケーラビリティとアフィニティ MoE アーキテクチャ、アクティブ ルーティングを実現する低オーバーヘッド


AIxivコラムは、当サイトが学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。提出電子メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
この論文の共著者は、GTS AI Computing Lab の Li Jing 博士、Sun Zhijie 博士、Lin Dachao 博士です。主な研究および実装分野には、LLM トレーニングと促進、AI トレーニング保証、グラフ コンピューティングが含まれます。

論文リンク: https://arxiv.org/pdf/2406.00023



この理論も非常に直感的です。ルーターにディスパッチ能力がない場合、つまり、エキスパートがディスパッチ能力を持っている場合には、トークンにランダムにエキスパートを選択させる方がよいでしょう。適切なトークンの場合は、 ECR を使用する方が適切です。したがって、著者は TCR から ECR への移行を推奨し、同時に、エキスパート キャパシティの需要推定に基づいて、トレーニングの後期段階ではより小さなエキスパート キャパシティを使用するグローバル レベルの適応型ルーティング スイッチング戦略を提案します。



以上がHuawei GTS LocMoE+: 高いスケーラビリティとアフィニティ MoE アーキテクチャ、アクティブ ルーティングを実現する低オーバーヘッドの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1667
1667
 14
1426
52
1328
25
1273
29
1255
24
14
1426
52
1328
25
1273
29
1255
24

 余成東氏はファーウェイの三つ折り画面携帯電話が9月に発表されることを明らかに:価格は安くないと予想
Aug 20, 2024 am 06:36 AM
余成東氏はファーウェイの三つ折り画面携帯電話が9月に発表されることを明らかに:価格は安くないと予想
Aug 20, 2024 am 06:36 AM
8月19日、Hongmengは上海でXiangjie S9オーナーの第1期納車式を開催し、ファーウェイ幹部のYu Chengdong氏が自ら出席し、車両をオーナーに引き渡した。現場では、すでにWenjie M5、M7、M9を所有している自動車所有者がYu Chengdong氏にファーウェイの3つ折り画面携帯電話をいつ買えるのか尋ねると、来月発売されると答えた。フェニフェニエ 以前、ファーウェイの三つ折りスクリーン携帯電話と思われる実物の写真がインターネット上に流出し、広く懸念を引き起こした。写真では、Yu Chengdong氏が手にした新しい携帯電話は、画面サイズが従来の折りたたみ式携帯電話よりもはるかに大きく、タブレットではありませんが、タブレットよりも優れています。左側上部には中央に穴あきカメラがはめ込まれており、携帯電話の側面にはスタイラスが装備されていると思われる二重のデザインがぼんやりと見えます。これらの手がかりはすべてこれを示しています
 Huawei Mate 60シリーズ、新しいAI排除+イメージアップグレード、秋のプロモーションを楽しむのに最適な時期
Aug 29, 2024 pm 03:33 PM
Huawei Mate 60シリーズ、新しいAI排除+イメージアップグレード、秋のプロモーションを楽しむのに最適な時期
Aug 29, 2024 pm 03:33 PM
昨年Huawei Mate60シリーズが発売されて以来、個人的にはMate60Proをメインで使っています。ほぼ1年の間に、Huawei Mate60Proは複数のOTAアップグレードを受け、全体的なエクスペリエンスが大幅に向上し、人々に常に新しい感覚を与えました。たとえば、最近、Huawei Mate60 シリーズは再びイメージング機能の大幅なアップグレードを受けました。 1 つ目は、新しい AI 除去機能で、通行人やゴミをインテリジェントに除去し、空白領域を自動的に埋めることができます。2 つ目は、メインカメラの色の精度と望遠の鮮明さが大幅に向上しました。新学期シーズンであることを考慮して、Huawei Mate60シリーズは秋のプロモーションも開始しました。携帯電話の購入時に最大800元の割引が受けられ、開始価格は4,999元という低価格です。よく使われる、価値の高い新製品が多い
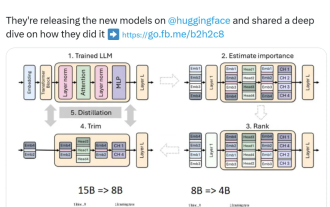 Nvidia はプルーニングと蒸留を試しています。Llama 3.1 8B のパラメータを半分にして、同じサイズでより良いパフォーマンスを実現しています。
Aug 16, 2024 pm 04:42 PM
Nvidia はプルーニングと蒸留を試しています。Llama 3.1 8B のパラメータを半分にして、同じサイズでより良いパフォーマンスを実現しています。
Aug 16, 2024 pm 04:42 PM
小型モデルの台頭。先月、Meta は Llama3.1 シリーズのモデルをリリースしました。これには、Meta のこれまでで最大のモデルである 405B モデルと、それぞれ 700 億と 80 億のパラメータを持つ 2 つの小型モデルが含まれています。 Llama3.1 は、オープンソースの新時代の到来を告げるものと考えられています。ただし、新世代モデルはパフォーマンスが強力ですが、導入時には依然として大量のコンピューティング リソースが必要です。したがって、多くの言語タスクで十分なパフォーマンスを発揮し、導入コストも非常に安価な小規模言語モデル (SLM) を開発するという別の傾向が業界に現れています。最近、NVIDIA の研究では、構造化された重み枝刈りと知識の蒸留を組み合わせることで、最初は大きなモデルから徐々に小さな言語モデルを取得できることが示されました。チューリング賞受賞、メタチーフA
 ファーウェイは、心拍数に基づいてユーザーの感情状態を評価できるスマートウェアラブル分野でXuanjiセンシングシステムを発売する
Aug 29, 2024 pm 03:30 PM
ファーウェイは、心拍数に基づいてユーザーの感情状態を評価できるスマートウェアラブル分野でXuanjiセンシングシステムを発売する
Aug 29, 2024 pm 03:30 PM
最近、ファーウェイは、Xuanjiセンシングシステムを搭載した新しいスマートウェアラブル製品を9月に発売すると発表しました。これはファーウェイの最新スマートウォッチとなる予定です。この新製品は、高度な感情的健康モニタリング機能を統合し、正確性、包括性、スピード、柔軟性、オープン性、拡張性という 6 つの特徴を備えた包括的な健康評価をユーザーに提供します。このシステムはスーパーセンシングモジュールを使用し、マルチチャンネル光路アーキテクチャ技術を最適化することで、心拍数、血中酸素、呼吸数などの基本的な指標の監視精度を大幅に向上させます。さらに、Xuanji センシング システムは、心拍数データに基づく感情状態の研究も拡張しており、生理学的指標に限定されず、ユーザーの感情状態やストレス レベルを評価することもでき、60 以上のスポーツのモニタリングをサポートしています。健康指標、心臓血管、呼吸器、神経、内分泌、
 Apple と Huawei は両方ともボタンのない携帯電話を作りたがっていましたが、Xiaomi が最初にそれを作りましたか?
Aug 29, 2024 pm 03:33 PM
Apple と Huawei は両方ともボタンのない携帯電話を作りたがっていましたが、Xiaomi が最初にそれを作りましたか?
Aug 29, 2024 pm 03:33 PM
Smartprix の報道によると、Xiaomi はコードネーム「Suzaku」というボタンのない携帯電話を開発中です。このニュースによると、コードネームZhuqueというこの携帯電話は、統合コンセプトで設計され、画面下カメラを使用し、Qualcomm Snapdragon 8gen4プロセッサを搭載する予定で、計画が変更されなければ、2025年に登場する可能性が高いとのことです。 。このニュースを見たとき、2019 年に戻ったような気がしました。当時、Xiaomi は Mi MIX Alpha コンセプトフォンをリリースしました。サラウンドスクリーンのボタンのないデザインは非常に素晴らしかったです。ボタンのない携帯電話の魅力を初めて知りました。 「魔法のガラス」が欲しいなら、まずボタンを殺さなければならない、ジョブズはかつて「スティーブ・ジョブズの伝記」の中で、携帯電話が「魔法のガラス」のようなものになりたいと述べた。
 数十年ぶりに進歩が見られ、見習いのタオ・ゼシュアンさんとチャオ・ユーフェイさんが組み合わせ数学の問題を突破した
Aug 15, 2024 pm 05:04 PM
数十年ぶりに進歩が見られ、見習いのタオ・ゼシュアンさんとチャオ・ユーフェイさんが組み合わせ数学の問題を突破した
Aug 15, 2024 pm 05:04 PM
最近、何十年も解決されなかった数学的パズルに初めて進歩が見られました。この進歩を推進しているのは、UCLA の大学院生である James Leng、MIT の数学の大学院生である Ashwin Sah、およびコロンビア大学の助教授である Mehtaab Sawhney です。その中で、ジェームズ・レンは有名な数学者のテレンス・タオに師事し、アシュウィン・サーは離散数学の達人である趙玉飛に師事しました。論文アドレス: https://arxiv.org/pdf/2402.17995 この研究で達成された画期的な成果を理解するには、等差数列から始める必要があります。等差数列の最初の n 項の合計は等差数列と呼ばれ、等差級数とも呼ばれます。 1936年、数学者パウル・エルデ
 Mamba の作者による新作: Llama3 をハイブリッド線形 RNN に蒸留する
Sep 02, 2024 pm 01:41 PM
Mamba の作者による新作: Llama3 をハイブリッド線形 RNN に蒸留する
Sep 02, 2024 pm 01:41 PM
深層学習の分野における Transformer の大成功の鍵は、アテンション メカニズムです。アテンション メカニズムにより、Transformer ベースのモデルは入力シーケンスに関連する部分に焦点を当てることができ、コンテキストの理解が向上します。ただし、アテンション メカニズムの欠点は、計算オーバーヘッドが高く、入力サイズに応じて二次関数的に増加するため、Transformer が非常に長いテキストを処理することが困難になることです。少し前に、Mamba の登場によりこの状況は打破され、コンテキストの長さが増加するにつれて線形拡張を実現できるようになりました。 Mamba のリリースにより、これらの状態空間モデル (SSM) は、秩序を維持しながら中小規模のスケールで Transformer に匹敵するか、さらにはそれを超えることができます。
 Mate 60の価格は800元値下げされ、Pura 70の価格は1,000元値下げされます。HuaweiがMate 70をリリースするまで待ってください!
Aug 16, 2024 pm 03:45 PM
Mate 60の価格は800元値下げされ、Pura 70の価格は1,000元値下げされます。HuaweiがMate 70をリリースするまで待ってください!
Aug 16, 2024 pm 03:45 PM
8月16日のニュースによると、現行のファーウェイ製携帯電話はすでに新モデルの投入に向けて懸命に取り組んでおり、Mate60シリーズやPura70シリーズが次々と値下げされていくのは誰もが見たことがあるだろう。ファーウェイが8月15日にMate60シリーズの値下げを正式に発表したことにより、ファーウェイの主力2シリーズの最新モデルの価格調整が完了した。今年7月、ファーウェイはファーウェイPura70シリーズを最大1,000元値下げして販売すると正式に発表した。その中で、Huawei Pura70は直接割引で、開始価格は4999元です。Huawei Pura70 Beidou Satellite News Editionは直接割引で、開始価格は5099元です。 800元、開始価格は5699元。
