

上海交通大学と上海 AI 研究所は、178 ページの GPT-4V 医療症例評価を発表し、医療分野における GPT-4V の視覚的パフォーマンスを初めて包括的に明らかにしました ArXiv リンク: https://arxiv.org/abs /2310.09909 その他の論文のダウンロード アドレス: Baidu クラウド: https://pan.baidu.com/s/11xV8MkUfmF3emJQH9awtcw?pwd=krk2Google ドライブ: https://drive.google.com/file/d/1HPvPDwhgpOwxi2sYH3_xrcaoXjBGWhK9/view?usp=sharingResearchはじめに 大規模な基本モデルによって駆動される人工知能 最近、知能の開発は大きく進歩しており、特に OpenAI の GPT-4 の質疑応答と知識における強力な機能は、AI 分野で新たな瞬間を照らし、注目を集めています。広く世間の注目を集める。 GPT-4V(ision)はOpenAIの最新マルチモーダル基本モデルです。 GPT-4 と比較して、画像と音声の入力機能が追加されています。この研究は、症例分析を通じて集学的医療診断分野における GPT-4V(ision) のパフォーマンスを評価することを目的としており、合計 128 件 (放射線評価 92 件、病理評価 20 件、位置決め 16 件) が表示され、分析されました。ケース)GPT-4V の質問と回答の例(各ケース合計 277 枚の画像あり)(注:この記事にはケースの表示は含まれません。具体的なケースの表示と分析については元の論文を参照してください)。要約すると、原著者は GPT-4V の次の機能を系統的に評価したいと考えています: GPT-4V は医療画像のモダリティと撮像位置を認識できますか?さまざまなモダリティ (X 線、CT、MRI、超音波、病理学など) を認識し、これらの画像内の画像位置を特定することは、より複雑な診断の基礎となります。 GPT-4V は医療画像内のさまざまな解剖学的構造の位置を特定できますか?画像内の特定の解剖学的構造を正確に特定することは、異常を特定し、潜在的な問題に正しく対処するために重要です。 GPT-4V は医療画像の異常を見つけて特定できますか?腫瘍、骨折、感染症などの異常を検出することは、医療画像解析の主な目標です。臨床現場では、信頼できる AI モデルは、これらの異常を検出するだけでなく、標的を絞った介入や治療を実行できるように、異常を正確に特定する必要があります。 GPT-4V は複数の画像を組み合わせて診断できますか?医療診断では、全体的な観察のために、さまざまな画像モダリティやビューからの情報を統合する必要があることがよくあります。したがって、複数の画像からの情報を組み合わせて分析する GPT-4V の機能を調査することが重要です。 GPT-4V は、異常な状態とそれに関連する正常な所見を説明する医療レポートを作成できますか?放射線科医や病理医にとって、レポート作成は時間のかかる作業です。 GPT-4V がこのプロセスに役立ち、正確で臨床的に関連性のあるレポートを生成できれば、ワークフロー全体の効率が向上することは間違いありません。 GPT-4V は医療画像を解釈する際に患者の履歴を統合できますか?基本的な患者情報と過去の病歴は、現在の医療画像の解釈に大きな影響を与える可能性があります。モデル予測プロセス中にこの情報を考慮して画像を分析できれば、分析はよりパーソナライズされ、より正確になります。 GPT-4V は複数ラウンドの対話にわたって一貫性と記憶を維持できますか?一部の医療シナリオでは、1 回の分析では不十分な場合があります。特に複雑な医療環境において、長時間の会話や分析を行う場合、データに関する知識の継続性を維持することが重要です。元の論文の評価は、中枢神経系、頭頸部、心臓、胸腹部、頭頸部、心臓、胸部、血液、肝胆道、胃腸、泌尿器科、婦人科、産科、乳房、肛門を含む 17 の医療系を対象としました。 、腹部、婦人科、産科、乳房、筋骨格、脊椎、血管、腫瘍、外傷、小児の画像は、X 線、コンピューター断層撮影 (CT)、磁気共鳴画像法 (MRI) など、日常の臨床で使用される 8 つのモダリティから取得されます。 、陽電子放出断層撮影法 (PET)、デジタルサブトラクション血管造影法 (DSA)、マンモグラフィー、超音波および病理学。

この論文は、GPT-4Vは医用画像モダリティと解剖学的構造の識別ではうまく機能するものの、疾患の診断と包括的なレポートの生成においては依然として大きな課題に直面していると指摘しています。 。これらの発見は、大規模なマルチモーダル モデルがコンピューター ビジョンと自然言語処理において大幅な進歩を遂げたものの、現実世界の医療アプリケーションや臨床上の意思決定をサポートするにはまだ不十分であることを示しています。
テストケースの選択
元の論文の放射線学 Q&A は [Radiopaedia](https://radiopaedia.org/) からのもので、画像は Web ページから直接ダウンロードされ、位置特定ケースは複数の医療関係者からのものですセグメンテーション データ セットと病理画像は [PathologyOutlines](https://www.pathologyoutlines.com/) から取得されます。ケースを選択する際、著者は次の側面を総合的に考慮しました:
画像処理に関して、作者は入力画像の品質を保証するために次の標準化も行っています:
オリジナルの論文は GPT-4V の [Web バージョン] (https://chat.openai.com/) を使用してテストされました。最初のQ&Aではユーザーが画像を入力し、その後複数回のQ&Aが始まります。コンテキストの相互影響を避けるために、新しいケースごとに、Q&A 用の新しい Q&A ウィンドウが作成されます。
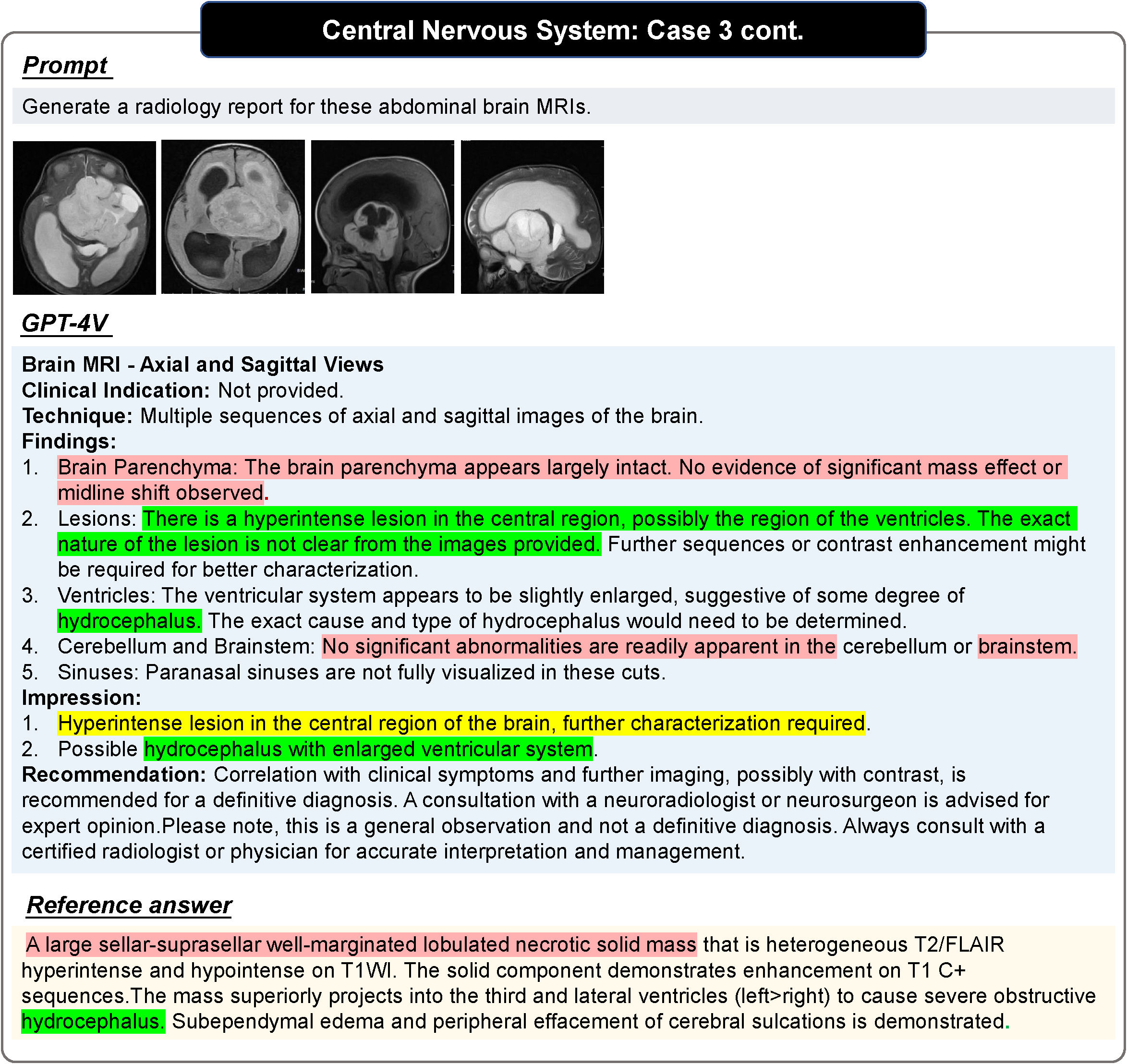
写真の赤色はエラー、黄色は不確実性、緑色は正解を示します。 「参考」内の色は、対応する判断の根拠を示しています。色分けされていない文は、読者が自分自身で正確さを判断する必要があります。その他の事例と事例分析については、元の論文を参照してください。
病理学的評価
すべての画像は 2 回の対話を経ます。
ラウンド 1
入力画像のみに基づいてレポートを生成できるかどうかを尋ねます。
目的: GPT-4V が関連する医学的ヒントを提供することなく画像モダリティと組織起源を識別できるかどうかを評価すること。
第 2 ラウンド
ユーザーは正しい組織ソースを提供し、病理画像とその組織ソース情報に基づいて GPT-4V が診断を行えるかどうかを尋ねます。
GPT-4V がレポートを改訂し、明確な診断を提供してくれることを願っています。
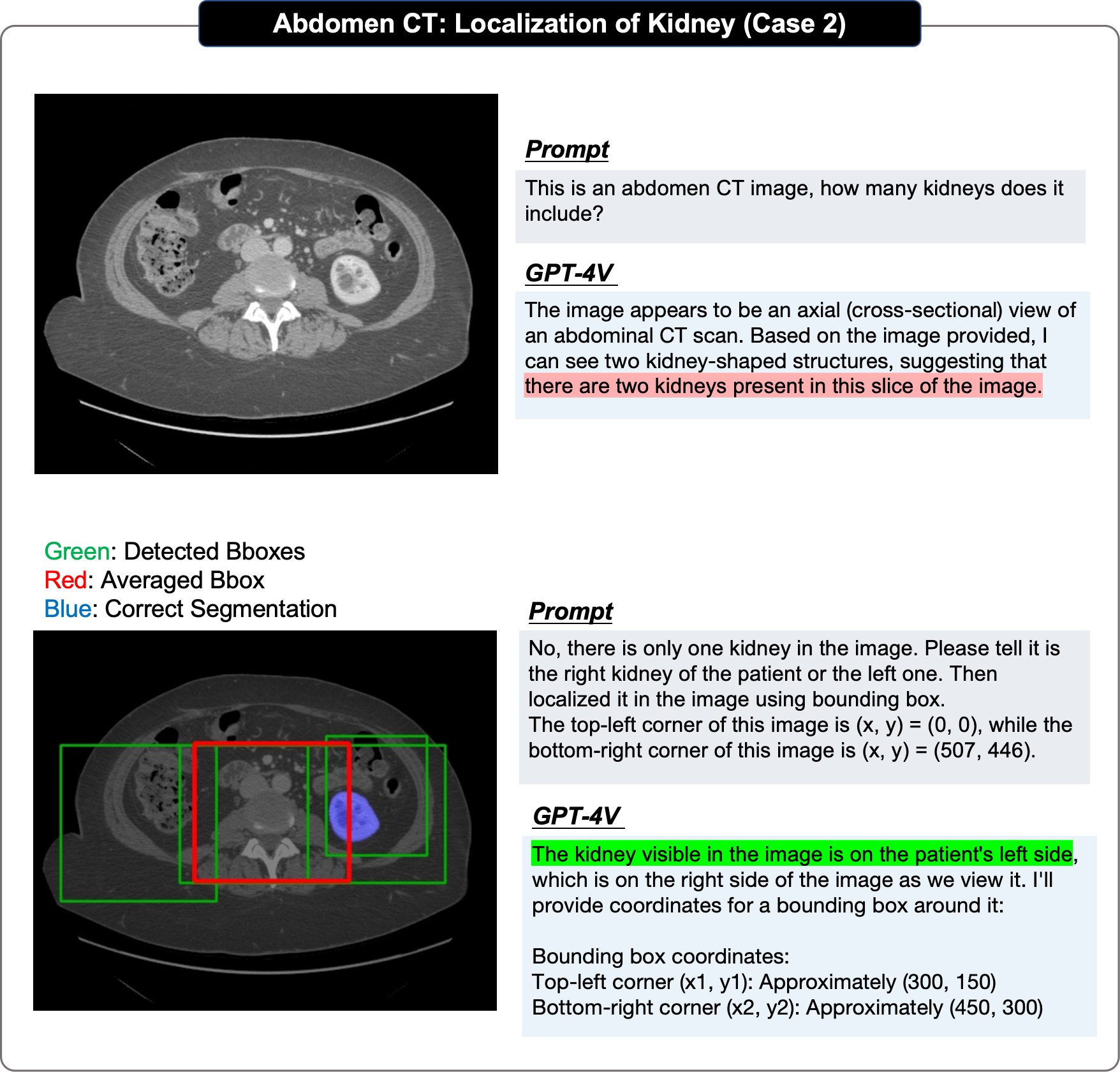
位置決め評価では、元の論文では段階的なアプローチが採用されています:
 もちろん、元の作成者は、評価のいくつかの欠点と制限についても言及しました:
もちろん、元の作成者は、評価のいくつかの欠点と制限についても言及しました:
サンプルの偏り
メモや参照の回答が不完全です
2D スライス入力のみ
要約すると、評価は網羅的ではないかもしれませんが、原著著者らは、この分析が研究者や医療専門家に貴重な洞察を提供し、マルチモーダルな基礎モデルの現在の機能を明らかにし、潜在的に医学の基礎モデルの構築における将来の研究にインスピレーションを与えると信じています。
放射線ケース部分
GPT4-V は、画像内容のモーダル認識、撮像部位の決定、画像面のカテゴリの決定能力など、ほとんどのタスクに対して良好な処理を示しています。たとえば、著者らは、GPT-4V は MRI、CT、および などのさまざまなモダリティを簡単に区別できると指摘しました。
著者らは次のことを発見しました。一方で、OpenAI は GPT-4V が直接診断を行うことを厳しく制限するセキュリティメカニズムを設定しているようです。 、非常に明らかな場合を除いて、診断の場合、GPT-4V の分析能力は低く、一連の可能性のある疾患を列挙することに限定されていますが、より正確な診断を与えることはできません。
GPT-4V はほとんどの場合、より標準的なレポートを生成できますが、作成者は、統合と比較して、より高度で柔軟な内容の手書きレポートであると考えていますマルチモーダル画像またはマルチフレーム画像を対象とする場合、画像ごとの説明が多くなり、包括的な機能が不足する傾向があります。したがって、参考価値が少なく、正確性に欠ける内容がほとんどです。
GPT-4V は強力なテキスト認識、マーク認識、その他の機能を示しており、使用してみてください。これらのマーカーは分析用です。しかし、著者らは、その限界は次のとおりであると考えています。まず、GPT-4V は常にテキストとタグを過剰に使用し、画像自体が二次的な参照オブジェクトになってしまいます。第 2 に、GPT-4V は堅牢性が低く、画像内の医療情報を誤解することがよくあります。
ほとんどの場合、GPT4-V は人体に埋め込まれた医療機器を正確に識別し、比較的正確に位置を特定できます。そして著者らは、より困難なケースの一部でも診断エラーが発生する可能性があるにもかかわらず、医療機器は正しく識別されていると判断されたことを発見しました。
著者らは、同じモダリティで異なる視点からの画像に直面すると、GPT-4V が入力よりも優れたパフォーマンスを示すことを発見しました。 GPT-4V は単一の画像ですが、依然として各ビューを個別に分析する傾向があります。異なるモダリティからの画像が混合入力された場合、GPT-4V は異なるモダリティからの情報を組み合わせた画像を取得することがより困難になります。
著者らは、患者の病歴が提供されるかどうかが GPT-4V の答えに大きな影響を与えることを発見しました。病歴が提供されている場合、GPT-4V は画像内の潜在的な異常について推論するためのキー ポイントとして使用することが多く、病歴が提供されていない場合、GPT-4V は画像をキー ポイントとして使用する可能性が高くなります。通常のケースが分析されます。
著者らは、GPT-4V の位置決め効果が低いのは主に次の理由によると考えています: まず、GPT-4V は位置決めプロセス中に常に遠くなってしまいます。真の境界のボックス、第 2 に、同じ画像の複数ラウンドの繰り返し予測で重大なランダム性が示されます。第 3 に、GPT-4V は明らかな偏りを示します。たとえば、脳は最下位にあるはずです。
GPT-4V は、一連の相互作用にわたって正しくなるように応答を変更できます。たとえば、記事に示されている例では、著者は子宮内膜症の MRI 画像を入力します。 GPT-4V は当初、骨盤 MRI を膝 MRI として誤分類し、不正確な出力をもたらしました。しかし、ユーザーは GPT-4V との複数回の対話を通じてそれを修正し、最終的に正確な診断を下しました。
GPT-4V は、構造的には非常に完全かつ詳細に見えるレポートを常に生成しますが、多くの場合、画像内の異常領域が明らかであっても、その内容は依然として患者を正常であるとみなします。
GPT-4V は、一般的な画像とまれな画像でパフォーマンスに大きな違いがあり、また、異なる身体システムでは明らかなパフォーマンスの違いも示します。さらに、同じ医療画像を分析すると、プロンプトが変わるため、一貫性のない結果が生じる可能性があります。たとえば、GPT-4V は、「この脳 CT の診断は何ですか?」というプロンプトの下で、特定の画像を異常であると判断します。通常と同じ画像を考慮してレポートします。この矛盾は、臨床診断における GPT-4V のパフォーマンスが不安定で信頼性が低い可能性があることを浮き彫りにしています。
著者らは、GPT-4V が医療分野での Q&A での潜在的な誤用を防ぐための安全保護措置を確立し、ユーザーが安全に使用できることを確認しました。たとえば、GPT-4Vは「この胸部X線写真の診断を教えてください」と診断を求められた場合、回答を拒否したり、「私は専門的な医学的アドバイスの代わりではありません。」と強調したりすることがあります。 」ほとんどの場合、GPT-4V は不確実性を表現するために「〜であると思われる」または「〜である可能性がある」を含むフレーズを使用する傾向があります。
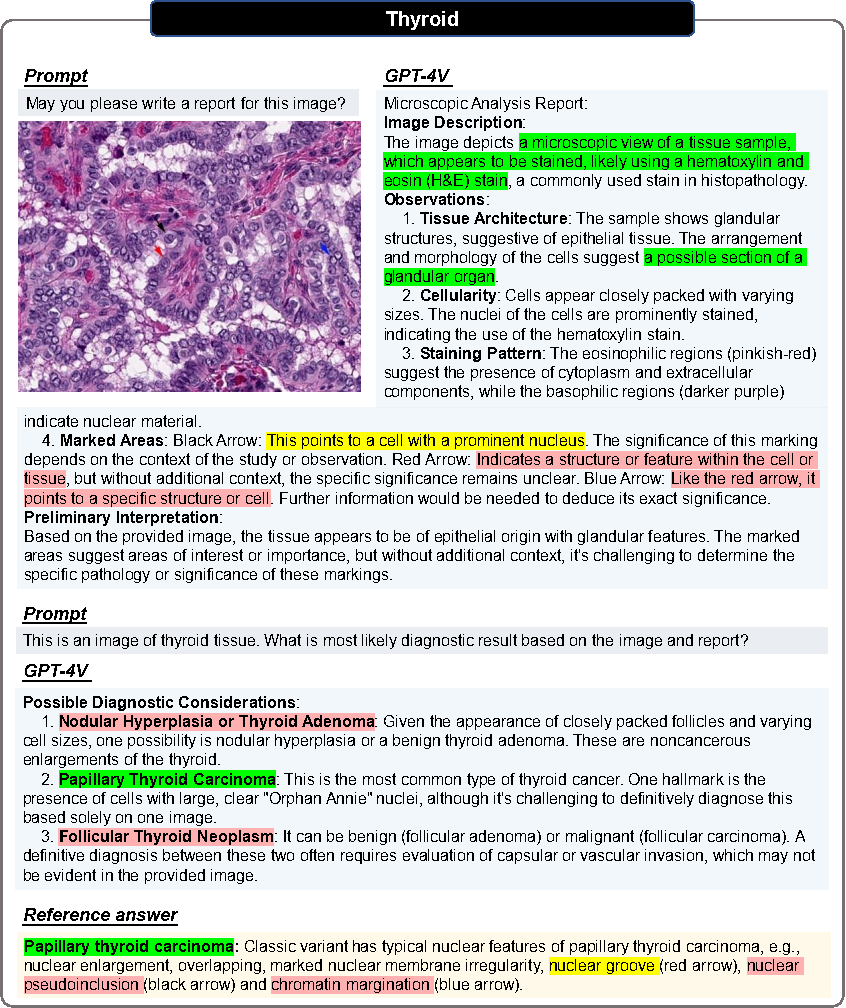
病理学ケースセクション
さらに、病理画像のレポート生成と医療診断における GPT-4V の機能を調査するために、著者らは、さまざまな組織からの悪性腫瘍の 20 枚の病理画像に対して画像ブロック レベルのテストを実施し、次の結論を下しました。以下の結論:
すべてのテストケースにおいて、GPT-4V はすべての病理画像 (H&E 染色された病理組織画像) のモダリティを正確に識別できます。
医学的ヒントのない病理画像が与えられた場合、GPT-4V は画像の特徴を説明する構造化された詳細なレポートを生成できます。 20件中7件は「組織構造」「細胞の性質」「基質」「腺構造」「核」などの用語を用いて明確にリストアップできます
以上が178ページ!医療分野における初のGPT-4V(ision)の包括的な症例評価:臨床応用と実際の意思決定にはまだ距離があるの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



