
 テクノロジー周辺機器
AI
Google チームは、高効率でラベルを必要とせず、AI を使用して臨床データをマイニングし、遺伝子発見と疾患予測を改善し、その成果が Nature サブジャーナルに掲載されました。
テクノロジー周辺機器
AI
Google チームは、高効率でラベルを必要とせず、AI を使用して臨床データをマイニングし、遺伝子発見と疾患予測を改善し、その成果が Nature サブジャーナルに掲載されました。
Google チームは、高効率でラベルを必要とせず、AI を使用して臨床データをマイニングし、遺伝子発見と疾患予測を改善し、その成果が Nature サブジャーナルに掲載されました。


編集者 | ScienceAI
現代の医療システムは、肺機能マップ、光電脈波計 (PPG)、心電図 (ECG) 記録、CT スキャン、MRI 画像などの大量の高次元臨床データ (HDCD) を生成します。データを単一の 2 進数または連続数値で要約することはできません。
私たちのゲノムと HDCD の関係を理解することは、この病気に対する理解が深まるだけでなく、この病気の治療法の開発にも重要です。
最近、Google Research のゲノミクス チームは、HDCD を使用して病気や生物学的特徴を特徴付けることで進歩を遂げました。
研究チームは、遺伝的変異とHDCDの間の関連性を発見するために、教師なし深層学習モデル、低次元埋め込み遺伝子発見のための表現学習(REGLE)を提案しました。
REGLE は、新しい遺伝子発見手法として、高次元の臨床データに隠された情報を活用でき、計算効率が高く、疾患ラベルを必要とせず、専門家が定義した知識からの情報を統合できます。
全体として、REGLE には既存の専門家が定義したシグネチャで捕捉される情報を超える臨床関連情報が含まれており、遺伝子発見と疾患予測の向上が可能になります。
関連研究は「高次元臨床データ上の教師なし表現学習によりゲノム発見と予測が向上」と題され、7月8日付けの「Nature Genetics」に掲載されました。

論文リンク: https://www.nature.com/articles/s41588-024-01831-6
HDCDの隠された情報を明らかにする
遺伝子とHDCD Aの関係に関する研究簡単なアプローチは、各データ座標に対して GWAS を実行することです。たとえば、医療画像の各ピクセルの値の変化を調べることができます。このアプローチは計算コストが高く、隣接する座標間の相関性が高く、複数のテスト負荷が大きいため、重要な関連性を検出する能力が低くなります。
より一般的なアプローチは、GWAS のターゲット特徴または表現型として HDCD から抽出された少数の専門家定義特徴 (EDF) に焦点を当てることです。 EDF には、肺活量測定による努力肺活量 (FVC) や 1 秒努力呼気量 (FEV1) などの臨床的に知られている機能を含めることができます。
これらの EDF は専門家によって発見された重要な機能ですが、HDCD でエンコードされた信号を完全にはキャプチャできない可能性があると想定されているため、これらの信号に対して GWAS を実行しても HDCD の可能性を最大限に活用できない可能性があります。
REGLE は、変分オートエンコーダー (VAE) モデルを使用してこれらの制限を克服することを目的としています。この方法は 3 つの主要なステップで構成されます:
(1) VAE を通じて HDCD の非線形、低次元、もつれの解いた表現 (つまり、エンコードまたは埋め込み) を学習します。
(2) エンコードされた座標ごとに個別に GWAS を実行します。
(3) コード座標からの多遺伝子リスク スコア (PRS) を一般的な生物学的機能の遺伝スコアとして使用し、これらのスコアを組み合わせて特定の疾患または形質 (少数の疾患ラベルが与えられた場合) の PRS を作成する可能性があります。 注目すべきことに、REGLE では、修正された VAE アーキテクチャのデコーダの入力に関連する EDF を選択的に含めることもできるため、エンコーダは EDF によって表されていない残留信号のみを学習することができます。
肺と循環機能の新規遺伝子座の検出
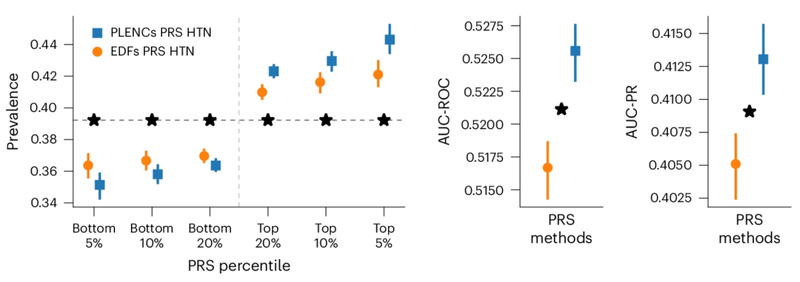
研究者らは、肺機能を測定するスパイロメトリーと心血管機能を測定するスパイロメトリーという 2 つの高次元臨床データモダリティを使用して、REGLE の能力を実証しました。 .PPG。どちらも診療所または消費者向けウェアラブル デバイスで非侵襲的かつ比較的安価に収集でき、両方のモダリティにはよく知られた特徴があります)。 同じ次元のスパイロメトリーとPPGシグネチャーを用いたゲノムワイド関連研究と比較して、REGLEの学習されたコーディングの研究は、肺と循環機能に関連する既知の遺伝子座(遺伝子座)の大部分を回復し、同時に他の部位(例えば、 、PPG の重要なサイトは 45% 増加しました)。これらの部位がさらなる分析やウェットラボ実験で検証されれば、新しい薬剤の標的となる可能性があります。 遺伝的リスクスコアの改善多遺伝子リスクスコア (PRS) は、特定の形質に対する多くの遺伝的変異の推定影響を単一の数値で表したものです。 REGLE 埋め込みに関するゲノムワイド関連研究によって作成された PRS は、少数の疾患シグネチャのみを使用して結合され、その特定の疾患の PRS を生成できます。研究者らは、スパイロメトリーのコーディングから作成された肺機能 PRS は、専門家が定義した特徴量、PCA、PRS などの既存の方法と比較して COPD と喘息の予測を改善し、リスク スペクトルの両端で特徴量 PRS を上回っていることを観察しました。以下に示すように、喘息および COPD に関する複数の独立したデータセット (COPDGene、eMERGE III、Indiana Biobank、EPIC-Norfolk) にわたる複数の指標 (AUC-ROC、AUC-PR、および Pearson 相関) における統計的に有意な改善が見られます。

同様に、PPG の REGLE 埋め込みから派生した PRS は、高血圧と収縮期血圧 (SBP) の予測を改善します。 PPG エンコードおよび PPG シグネチャによって生成された高血圧および SBP PRS は、3 つの独立したデータセット (COPDGene、eMERGE III、EPIC-Norfolk) および英国バイオバンクが保有するテスト セットで評価されました。
複数のデータセットにわたって、高血圧とSBPの両方について、専門家が定義した特徴からのPRSを使用するよりも、PPGコーディングからのPRSを使用する方が一貫した改善傾向があることが観察されました。

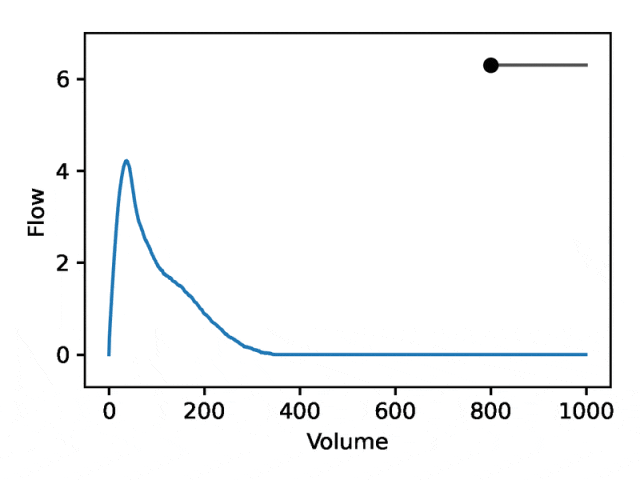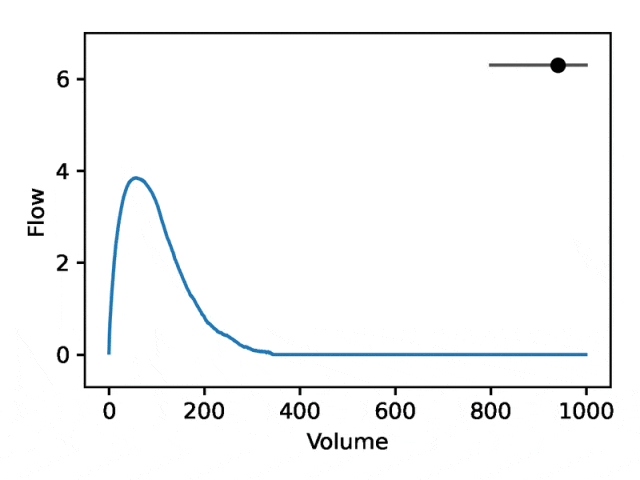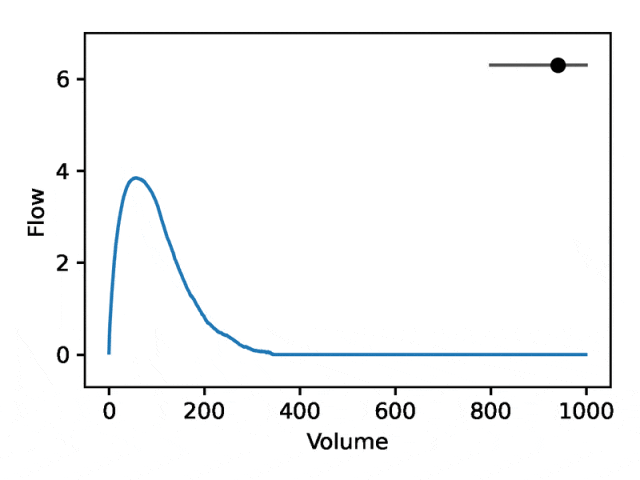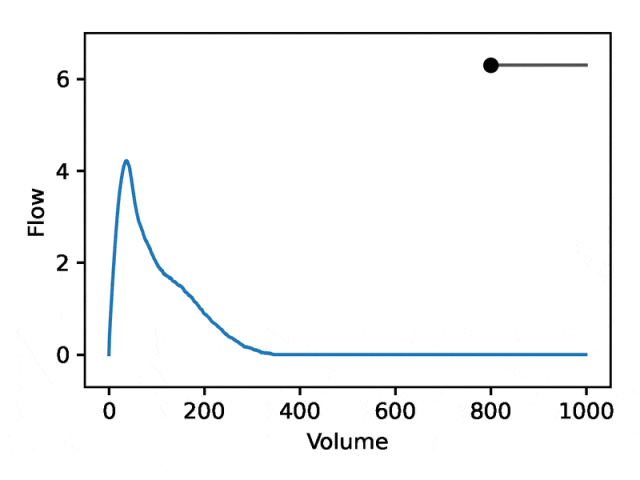
部分的に解釈可能な埋め込み
REGLE の生成特性を利用して、専門家が定義した特徴量の値を固定し、一方のエンコード座標を変更しながらもう一方のエンコード座標を変更することで、肺活量測定におけるエンコード座標の影響を研究します。エンコード座標はゼロです。次に、トレーニングされたモデルのデコーダー部分のみを使用して、対応する肺活量測定マップが生成されます。
典型的な流量肺活量測定は、次の 2 つの異なる部分で構成されます: (1) 流量が体積の増加とともに単調増加する、ピーク流量に達するまでの比較的短いセクション (2) 流量が減少する肺活量測定セクションの主要部分。単調に。
下の画像は、最初の座標を変更すると、最初の部分を相対的に固定したまま 2 番目の部分を拡大または縮小 (負の傾き) することと同等であることを示しています。実際、呼吸器科医がディップと呼ぶ曲線の 2 番目の部分の凹みは、標準の EDF では十分に表現されていない気道閉塞の指標です。
ヒトの形質と病気の遺伝的基盤を解明する
REGLE は、遺伝子解析、改善された新規遺伝子座の発見、およびリスク予測を実行する教師なし学習手法です。 EDF を手動で大規模に発見するのは難しいため、HDCD 表現の教師なし学習はゲノム発見にとって魅力的です。
REGLE フレームワークは、従来の VAE アーキテクチャを変更することで、モデリングにおけるこれらの機能の原則的な使用もサポートしています。 REGLE は 2 つの臨床データ モダリティ (肺活量測定と PPG) で実証されており、臨床現場で日常的に測定することも、スマートフォンやウェアラブル デバイスを介して受動的かつ非侵襲的に測定することもできます。
REGLE は、ラベル付きデータなしで臓器機能に対する遺伝的影響を特定するメカニズムを提供し、専門家の特徴をモデルに組み込むことができます。また、少数のラベルを使用して疾患および形質に固有の PRS を作成する方法も提供します。将来的には、人間の形質や病気の遺伝的基盤をさらに解明するために、このようなアプローチがますます利用されることになるでしょう。
参考コンテンツ:https://research.google/blog/harnessing-hidden-genetic-information-in-clinical-data-with-regle/
以上がGoogle チームは、高効率でラベルを必要とせず、AI を使用して臨床データをマイニングし、遺伝子発見と疾患予測を改善し、その成果が Nature サブジャーナルに掲載されました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1667
1667
 14
1426
52
1328
25
1273
29
1255
24
14
1426
52
1328
25
1273
29
1255
24

 「Defect Spectrum」は、従来の欠陥検出の限界を打ち破り、超高精度かつ豊富なセマンティックな産業用欠陥検出を初めて実現します。
Jul 26, 2024 pm 05:38 PM
「Defect Spectrum」は、従来の欠陥検出の限界を打ち破り、超高精度かつ豊富なセマンティックな産業用欠陥検出を初めて実現します。
Jul 26, 2024 pm 05:38 PM
現代の製造において、正確な欠陥検出は製品の品質を確保するための鍵であるだけでなく、生産効率を向上させるための核心でもあります。ただし、既存の欠陥検出データセットには、実際のアプリケーションに必要な精度や意味論的な豊富さが欠けていることが多く、その結果、モデルが特定の欠陥カテゴリや位置を識別できなくなります。この問題を解決するために、広州香港科技大学と Simou Technology で構成されるトップの研究チームは、産業欠陥に関する詳細かつ意味的に豊富な大規模なアノテーションを提供する「DefectSpectrum」データセットを革新的に開発しました。表 1 に示すように、他の産業データ セットと比較して、「DefectSpectrum」データ セットは最も多くの欠陥注釈 (5438 個の欠陥サンプル) と最も詳細な欠陥分類 (125 個の欠陥カテゴリ) を提供します。
 ORB-SLAM3を超えて! SL-SLAM: 低照度、重度のジッター、弱いテクスチャのシーンはすべて処理されます。
May 30, 2024 am 09:35 AM
ORB-SLAM3を超えて! SL-SLAM: 低照度、重度のジッター、弱いテクスチャのシーンはすべて処理されます。
May 30, 2024 am 09:35 AM
以前に書きましたが、今日は、深層学習テクノロジーが複雑な環境におけるビジョンベースの SLAM (同時ローカリゼーションとマッピング) のパフォーマンスをどのように向上させることができるかについて説明します。ここでは、深部特徴抽出と深度マッチング手法を組み合わせることで、低照度条件、動的照明、テクスチャの弱い領域、激しいセックスなどの困難なシナリオでの適応を改善するように設計された多用途のハイブリッド ビジュアル SLAM システムを紹介します。当社のシステムは、拡張単眼、ステレオ、単眼慣性、ステレオ慣性構成を含む複数のモードをサポートしています。さらに、他の研究にインスピレーションを与えるために、ビジュアル SLAM と深層学習手法を組み合わせる方法も分析します。公開データセットと自己サンプリングデータに関する広範な実験を通じて、測位精度と追跡堅牢性の点で SL-SLAM の優位性を実証しました。
 結晶相問題を解決するための数百万の結晶データを使用したトレーニング、深層学習手法 PhAI が Science 誌に掲載
Aug 08, 2024 pm 09:22 PM
結晶相問題を解決するための数百万の結晶データを使用したトレーニング、深層学習手法 PhAI が Science 誌に掲載
Aug 08, 2024 pm 09:22 PM
編集者 |KX 今日に至るまで、単純な金属から大きな膜タンパク質に至るまで、結晶学によって決定される構造の詳細と精度は、他のどの方法にも匹敵しません。しかし、最大の課題、いわゆる位相問題は、実験的に決定された振幅から位相情報を取得することのままです。デンマークのコペンハーゲン大学の研究者らは、結晶相の問題を解決するための PhAI と呼ばれる深層学習手法を開発しました。数百万の人工結晶構造とそれに対応する合成回折データを使用して訓練された深層学習ニューラル ネットワークは、正確な電子密度マップを生成できます。この研究では、この深層学習ベースの非経験的構造解法は、従来の非経験的計算法とは異なり、わずか 2 オングストロームの解像度で位相問題を解決できることが示されています。これは、原子解像度で利用可能なデータのわずか 10% ~ 20% に相当します。
 NVIDIA 対話モデル ChatQA はバージョン 2.0 に進化し、コンテキストの長さは 128K と記載されています
Jul 26, 2024 am 08:40 AM
NVIDIA 対話モデル ChatQA はバージョン 2.0 に進化し、コンテキストの長さは 128K と記載されています
Jul 26, 2024 am 08:40 AM
オープンな LLM コミュニティは百花繚乱の時代です Llama-3-70B-Instruct、QWen2-72B-Instruct、Nemotron-4-340B-Instruct、Mixtral-8x22BInstruct-v0.1 などがご覧いただけます。優秀なパフォーマーモデル。しかし、GPT-4-Turboに代表される独自の大型モデルと比較すると、オープンモデルには依然として多くの分野で大きなギャップがあります。一般的なモデルに加えて、プログラミングと数学用の DeepSeek-Coder-V2 や視覚言語タスク用の InternVL など、主要な領域に特化したいくつかのオープン モデルが開発されています。
 Google AI が IMO 数学オリンピック銀メダルを獲得、数理推論モデル AlphaProof が発売、強化学習が復活
Jul 26, 2024 pm 02:40 PM
Google AI が IMO 数学オリンピック銀メダルを獲得、数理推論モデル AlphaProof が発売、強化学習が復活
Jul 26, 2024 pm 02:40 PM
AI にとって、数学オリンピックはもはや問題ではありません。木曜日、Google DeepMind の人工知能は、AI を使用して今年の国際数学オリンピック IMO の本当の問題を解決するという偉業を達成し、金メダル獲得まであと一歩のところまで迫りました。先週終了したばかりの IMO コンテストでは、代数、組合せ論、幾何学、数論を含む 6 つの問題が出題されました。 Googleが提案したハイブリッドAIシステムは4問正解で28点を獲得し、銀メダルレベルに達した。今月初め、UCLA 終身教授のテレンス・タオ氏が、100 万ドルの賞金をかけて AI 数学オリンピック (AIMO Progress Award) を宣伝したばかりだったが、予想外なことに、AI の問題解決のレベルは 7 月以前にこのレベルまで向上していた。 IMO に関する質問を同時に行うのが最も難しいのは、最も歴史が長く、規模が最も大きく、最も否定的な IMO です。
 PRO | なぜ MoE に基づく大規模モデルがより注目に値するのでしょうか?
Aug 07, 2024 pm 07:08 PM
PRO | なぜ MoE に基づく大規模モデルがより注目に値するのでしょうか?
Aug 07, 2024 pm 07:08 PM
2023 年には、AI のほぼすべての分野が前例のない速度で進化しています。同時に、AI は身体化されたインテリジェンスや自動運転などの主要な分野の技術的限界を押し広げています。マルチモーダルの流れのもと、AI大型モデルの主流アーキテクチャとしてのTransformerの状況は揺るがされるだろうか? MoE (専門家混合) アーキテクチャに基づく大規模モデルの検討が業界の新しいトレンドになっているのはなぜですか?ラージ ビジョン モデル (LVM) は、一般的な視覚における新たなブレークスルーとなる可能性がありますか? ...過去 6 か月間にリリースされたこのサイトの 2023 PRO メンバー ニュースレターから、上記の分野の技術トレンドと業界の変化を詳細に分析し、新しい分野での目標を達成するのに役立つ 10 の特別な解釈を選択しました。準備してください。この解釈は 2023 年の Week50 からのものです
 AlphaFold 3 が発売され、タンパク質とすべての生体分子の相互作用と構造をこれまでよりもはるかに高い精度で包括的に予測します。
Jul 16, 2024 am 12:08 AM
AlphaFold 3 が発売され、タンパク質とすべての生体分子の相互作用と構造をこれまでよりもはるかに高い精度で包括的に予測します。
Jul 16, 2024 am 12:08 AM
エディター | Radish Skin 2021 年の強力な AlphaFold2 のリリース以来、科学者はタンパク質構造予測モデルを使用して、細胞内のさまざまなタンパク質構造をマッピングし、薬剤を発見し、既知のあらゆるタンパク質相互作用の「宇宙地図」を描いてきました。ちょうど今、Google DeepMind が AlphaFold3 モデルをリリースしました。このモデルは、タンパク質、核酸、小分子、イオン、修飾残基を含む複合体の結合構造予測を実行できます。 AlphaFold3 の精度は、これまでの多くの専用ツール (タンパク質-リガンド相互作用、タンパク質-核酸相互作用、抗体-抗原予測) と比較して大幅に向上しました。これは、単一の統合された深層学習フレームワーク内で、次のことを達成できることを示しています。
 新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
編集者 |ScienceAI 質問応答 (QA) データセットは、自然言語処理 (NLP) 研究を促進する上で重要な役割を果たします。高品質の QA データ セットは、モデルの微調整に使用できるだけでなく、大規模言語モデル (LLM) の機能、特に科学的知識を理解し推論する能力を効果的に評価することもできます。現在、医学、化学、生物学、その他の分野をカバーする多くの科学 QA データ セットがありますが、これらのデータ セットにはまだいくつかの欠点があります。まず、データ形式は比較的単純で、そのほとんどが多肢選択式の質問であり、評価は簡単ですが、モデルの回答選択範囲が制限され、科学的な質問に回答するモデルの能力を完全にテストすることはできません。対照的に、自由回答型の Q&A
