

ロボット工学のトップカンファレンス「RSS 2024」で、中国の人型ロボット研究が最優秀論文賞を受賞

最近、ロボット工学の分野で有名なカンファレンスであるRSS (ロボティクス: サイエンスとシステム) 2024がオランダのデルフト工科大学で無事閉幕しました。
カンファレンスの規模は NeurIPS や CVPR などのトップ AI カンファレンスには及びませんが、RSS はここ数年で大きな進歩を遂げ、今年は 900 人近くが参加しました。 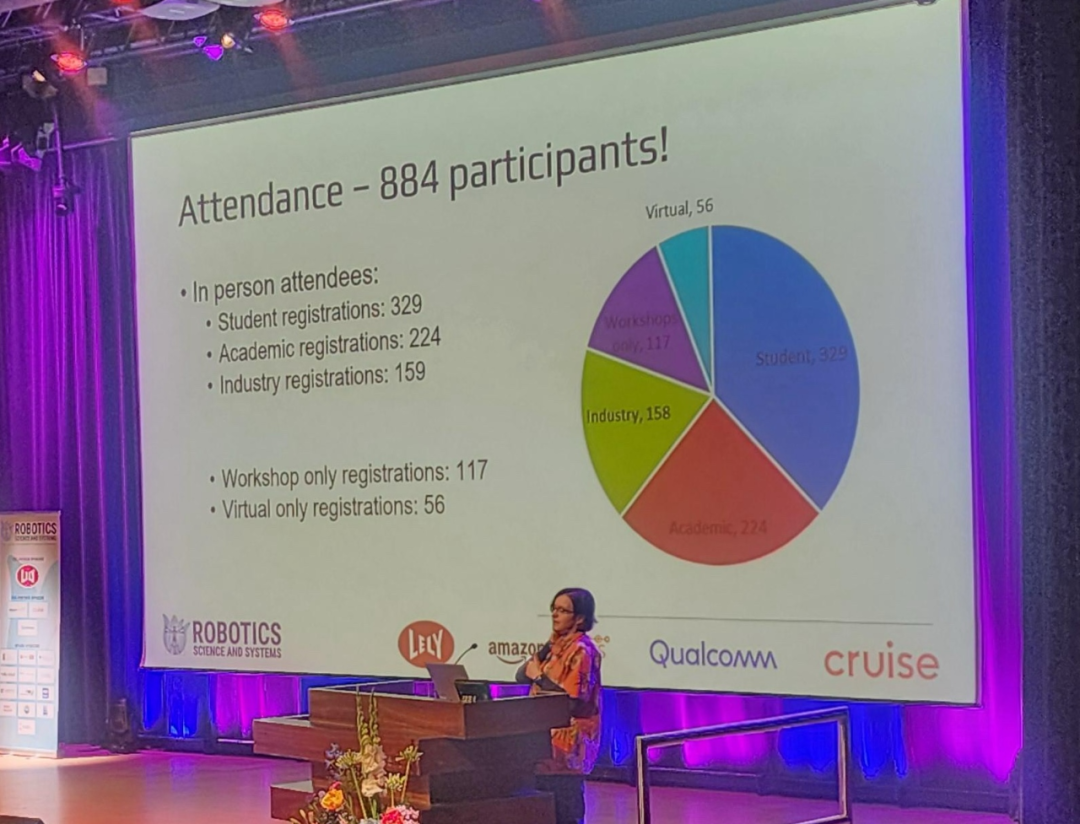
カンファレンス最終日には、Best Paper、Best Student Paper、Best System Paper、Best Demo Paperなどの複数の賞が同時に発表されました。さらに、カンファレンスでは「Early Career Spotlight Award」と「Time Test Award」も選出されました。
注目に値するのは、清華大学と北京興東基源技術有限公司の人型ロボット研究が最優秀論文賞を受賞し、中国学者のJi Zhang氏が今回のテスト賞を受賞したことです。
以下は受賞論文に関する情報です:
最優秀デモ論文賞

論文タイトル: Demonstrated CropFollow++: Robust Under-Canopy Navigation with Keypoints
著者: Arun Narenthiran Sivaクマール、 Mateus Valverde Gasparino、Michael McGuire、Vitor Akihiro Hisuno Higuti、M. Ugur Akcal、Girish Chowdhary
機関: UIUC、Earth Sense
紙のリンク: https://enriquecoronadozu.github.io/rssproceedings2024/rss20/ p023. pdf
この論文では、研究者たちはセマンティックキーポイントを使用した作物林冠下の農業ロボットのための経験ベースの堅牢な視覚ナビゲーションシステムを提案しています。
作物の列間隔が狭い(約 0.75 メートル)、マルチパスエラーによる RTK-GPS 精度の低下、過剰なクラッターによるノイズの多い LIDAR 測定により、作物の林冠の下での自律ナビゲーションは困難です。 CropFollow と呼ばれる以前の研究では、学習ベースのエンドツーエンドの知覚視覚ナビゲーション システムを提案することで、これらの課題に対処しました。ただし、このアプローチには、解釈可能な表現が欠如していること、および信頼性が不十分であるためにオクルージョン中の外れ値予測に対する感度が欠如していることという制限があります。
この記事のシステム CropFollow++ は、モジュール式の認識アーキテクチャと学習されたセマンティック キー ポイント表現を導入しています。 CropFollow と比較して、CropFollow++ はよりモジュール化されており、より解釈しやすく、オクルージョンの検出においてより高い信頼性を提供します。 CropFollow++ は、それぞれの距離が 1.9 キロメートルで、衝突回数が 13 回対 33 回の困難なシーズン後半のフィールド テストにおいて、CropFollow よりも大幅に優れたパフォーマンスを示しました。また、さまざまな圃場条件下で複数の林冠カバー作付ロボット (合計 25 km) に CropFollow++ を大規模に導入して得た重要な教訓についても説明します。

論文のタイトル: 状態推定を行わないピクセルからのアジャイルフライトのデモンストレーション
著者: smail Geles、Leonard Bauersfeld、Angel Romero、Jiaxu Xing、Davide Scaramuzza
論文のリンク: https://enriケコロナドズ.github.io/rssproceedings2024/rss20/p082.pdf
クアッドコプター ドローンは、最も機敏な飛行ロボットの 1 つです。最近の研究では学習ベースの制御とコンピュータービジョンが進歩しましたが、自律型ドローンは依然として明示的な状態推定に依存しています。一方、人間のパイロットは、プラットフォームを限界まで押し上げ、目に見えない環境で安定して飛行するために、ドローンの搭載カメラによって提供される一人称ビデオ ストリームにのみ依存できます。
この記事では、ピクセルを制御コマンドに直接マッピングしながら、一連のドアを自律的に高速で移動できる、初のビジョンベースのクアッドコプター ドローン システムを紹介します。プロのドローンレーサーと同様に、このシステムは明示的な状態推定を使用せず、代わりに人間と同じ制御コマンド (集団推力と機体速度) を利用します。研究者らは、最大40km/hの速度と最大2gの加速度で機敏な飛行を実証した。これは、強化学習 (RL) を通じてビジョンベースのポリシーをトレーニングすることで実現されます。非対称の Actor-Critic を使用すると、特権情報を取得し、トレーニングを容易にすることができます。画像ベースの RL トレーニング中の計算の複雑さを克服するために、ゲートの内側のエッジをセンサーの抽象化として使用します。このシンプルかつ強力なタスク関連の表現は、トレーニング中に画像をレンダリングせずにシミュレートできます。導入プロセス中、研究者らは Swin Transformer をベースとしたドア検出器を使用しました。
この記事の方法では、標準的な既製のハードウェアを使用して、自律的な機敏な飛行を実現できます。デモンストレーションはドローンレースに焦点を当てていましたが、このアプローチは競争を超えた意味を持ち、構造化された環境における現実世界のアプリケーションに関する将来の研究の基礎として役立つ可能性があります。
ベストシステムペーパー賞

論文のタイトル: ユニバーサル操作インターフェース: 野生ロボットを使用しない野生ロボットの教育
Cheng Chi、Zhenjia Xu、Chuer Pan、Eric Cousineau、Benjamin Burchfiel、Siyuan Feng、Russ Tedrake、Shuran Song
機関: スタンフォード大学、コロンビア大学、トヨタ研究所
論文リンク: https://arxiv.org/pdf/2402.10329
この記事では、Universal Manipulation Interface (UMI) を紹介します。野生の人間が実証したスキルを展開可能なロボット ポリシーに直接転送する、データ収集およびポリシー学習フレームワーク。 UMI は、ハンドヘルド グリッパーと慎重なインターフェイス設計を利用して、困難な双腕操作や動的操作のデモンストレーションに、ポータブルで低コストで情報豊富なデータ収集を提供します。展開可能なポリシー学習を促進するために、UMI は、推論時間遅延マッチングおよび相対軌跡アクション表現機能を備えた、慎重に設計されたポリシー インターフェイスを採用しています。学習されたポリシーはハードウェアに依存せず、複数のロボット プラットフォームに展開できます。これらの機能により、UMI フレームワークは新しいロボット操作機能を解放し、各タスクのトレーニング データを変更するだけで、動的、双腕、正確、長視野動作のゼロショット一般化を可能にします。研究者らは、UMI Zero RFで学習したポリシーが、さまざまな人間のデモンストレーションでトレーニングされたときに新しい環境やオブジェクトに一般化される包括的な実世界の実験を通じて、UMIの多用途性と有効性を実証しました。

論文タイトル: Khronos: A Unified Approach for Spatio-Temporal Metric-Semantic SLAM in Dynamic Environs
著者: Lukas Schmid、Marcus Abate、Yun Chang、Luca Carlone
論文リンク: https://arxiv.org/pdf/2402.13817
非常に動的で変化する環境を認識して理解することは、ロボットの自律性にとって重要な能力です。ロボットのポーズを正確に推定できる動的 SLAM 手法の開発ではかなりの進歩が見られましたが、ロボット環境の高密度の時空間表現の構築には十分な注意が払われてきませんでした。シナリオとその時間の経過に伴う進化を詳細に理解することは、ロボットの長期的な自律性にとって重要であり、人間や他のエージェントと共有される環境で効果的に動作するなど、長期的な推論を必要とするタスクにも重要です。したがって、短期および長期の制約を受けることになります。
この課題に対処するために、この研究では時空間計量意味論的 SLAM (SMS) 問題を定義し、問題を効果的に分解して解決するためのフレームワークを提案します。我々は、提案された因数分解が、時空間知覚システムの自然な組織化を示唆していることを示します。この場合、高速なプロセスはアクティブな時間枠内の短期的なダイナミクスを追跡し、別の遅いプロセスは因子グラフを使用して環境の長期的な変化への応答を表現します。推論。研究者らは、効率的な時空間認識方法であるクロノスを提供し、それが短期と長期のダイナミクスの既存の説明を統合し、リアルタイムでの密な時空間マップの構築を可能にすることを実証しました。
論文で提供されているシミュレーションと実際の結果は、クロノスによって構築された時空間マップが 3 次元シーンの時間的変化を正確に反映でき、クロノスが複数の指標でベースラインを上回っていることを示しています。
Best Student Paper Award

論文タイトル: Dynamic On-Palm Manipulation via Controlled Sliding
著者: William Yang、Michael Posa
機関: ペンシルベニア大学
論文リンク: https://arxiv.org/pdf/2405.08731
現在、非掴み動作を実行するロボットの研究は、滑りによって引き起こされる可能性のある問題を回避するために主に静的接触に焦点を当てています。しかし、「手の滑り」の問題を根本的に解消する、つまり接触時の滑りを制御することができれば、ロボットの新たな行動領域が広がります。
この論文では、研究者らは、さまざまな混合接触モードを包括的に考慮する必要がある、挑戦的な動的非把握操作タスクを提案しています。研究者らは、最新の暗黙的接触モデル予測制御 (MPC) テクノロジーを使用して、ロボットがさまざまなタスクを完了するためのマルチモーダルな計画を実行できるようにしました。この論文では、MPC の簡略化されたモデルを低レベルの追跡コントローラーと統合する方法と、暗黙的接触 MPC を動的タスクのニーズに適応させる方法について詳しく説明します。

印象的なのは、摩擦および剛体接触モデルは不正確であることが多いことが知られているにもかかわらず、この論文のアプローチは、タスクを迅速に完了しながら、これらの不正確さに敏感に対応することができます。さらに、研究者らは、ロボットがタスクを完了するのを支援するために、基準軌道やモーションプリミティブなどの一般的な補助ツールを使用しなかった。これは、この方法の多用途性をさらに強調している。暗黙的接触 MPC テクノロジーが 3 次元空間での動的操作タスクに適用されたのはこれが初めてです。

論文タイトル: Agile But Safe: Learning Collision-Free High-Speed Locomotion
著者: Tairan He、Chong Zhang、Wenli Xiao、Guanqi He、Changliu Liu、Guanya Shi
-
機関 : CMU, ETH Zurich, Switzerland
論文リンク: https://arxiv.org/pdf/2401.17583
四足ロボットが雑然とした環境を移動する場合、柔軟性と安全性の両方が必要です。人や障害物との衝突を避けながら、タスクを迅速に完了できる必要があります。しかし、既存の研究は多くの場合、安全性を考慮して 1.0 m/s 以下の速度で保守的なコントローラーを設計するか、柔軟性を追求するものの潜在的に致命的な衝突の問題を無視する、という 1 つの側面のみに焦点を当てています。
この論文は、「Agile and Secure」と呼ばれる制御フレームワークを提案します。このフレームワークにより、四足ロボットは柔軟性を維持しながら障害物や人を安全に回避し、衝突のない歩行を実現します。
ABS には 2 つの戦略が含まれています。1 つは、障害物の間を柔軟かつ機敏に移動する方法をロボットに教えることであり、もう 1 つは、ロボットが落ちたり落ちたりしないように、問題に遭遇した場合に素早く回復する方法をロボットに教えることです。何かにぶつかる。 2 つの戦略は相互に補完します。
ABS システムでは、戦略の切り替えは、学習制御理論に基づいた衝突回避値ネットワークによって制御されます。このネットワークは、いつ戦略を切り替えるかを決定するだけでなく、回復戦略の目的関数も提供し、閉ループ制御システム内でロボットが常に安全な状態を保つようにします。このようにして、ロボットは複雑な環境におけるさまざまな状況に柔軟に対応できます。
これらの戦略とネットワークをトレーニングするために、研究者は、アジャイル戦略、衝突回避価値ネットワーク、回復戦略、外部認識表現ネットワークなどを含むシミュレーション環境で広範なトレーニングを実施しました。これらの訓練されたモジュールは、ロボット自身の認識能力とコンピューティング能力を利用して、ロボットが屋内であっても屋外の制限された空間であっても、移動できない障害物に直面していても、移動可能な障害物に直面していても、現実世界に直接適用できます。 ABSフレームワーク。
さらに詳しく知りたい場合は、このサイトのこの論文の以前の紹介を参照してください。 

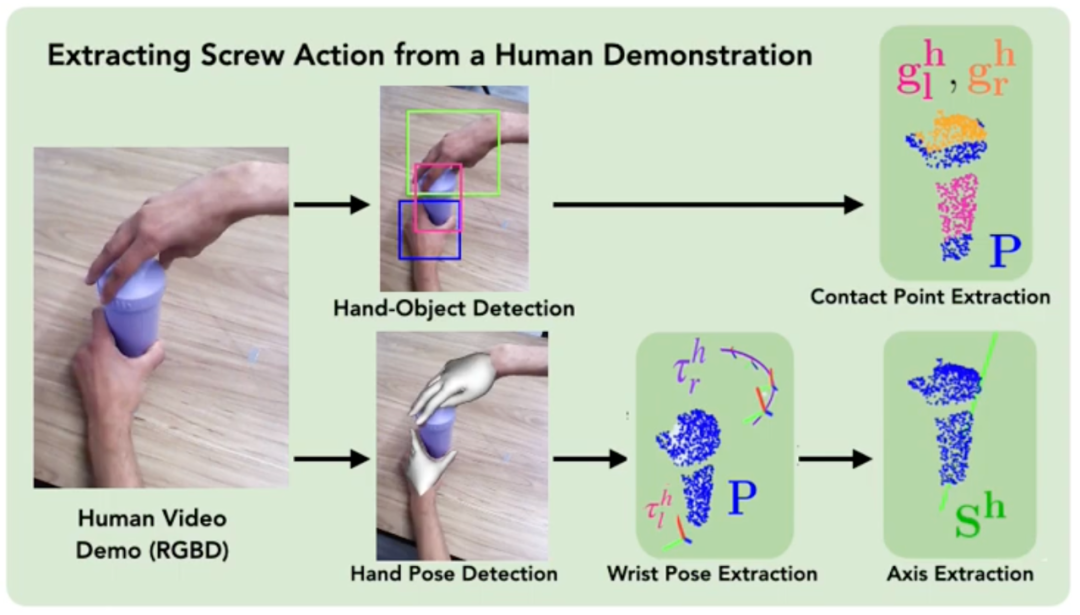
論文タイトル: ScrewMimic: Screw Space Projectionを使用した人間のビデオからのバイマニュアル模倣
著者: Arpit Bahety、Priyanka Mandikal、Ben Abbatematteo、Roberto Martín-Martín
機関: テキサスオースティン大学
論文リンク: https://arxiv.org/pdf/2405.03666
ロボットに、箱を開けるなど、同時に両手で何かをする方法を教えたい場合は、同時に、それは実際には非常に難しい難易度です。ロボットは多くの関節を同時に制御する必要があるため、両手の動きが確実に調整されるようにする必要もあります。人間の場合、他人を観察することで新しい行動を学び、それを自分で試して改善し続けます。この論文では、研究者らはロボットがビデオを見て新しいスキルを学習し、実際に向上させることができる人間の学習方法に言及しています。
研究者らは、心理学と生体力学の研究からインスピレーションを得て、「スパイラルアクション」と呼ばれる、ネジのように回転できる特別な鎖としての両手の動きを想像しました。これに基づいて、彼らは ScrewMimic と呼ばれるシステムを開発しました。このシステムは、ロボットが人間のデモンストレーションをよりよく理解し、自己監視を通じて行動を改善するのに役立ちます。研究者らは実験を通じて、ScrewMimicシステムがロボットがビデオから複雑な両手操作スキルを学習するのに役立ち、元の動作空間で直接学習して改善するシステムをパフォーマンスで上回ることができることを発見した。
メソッド図 ヒューマノイド移動の進歩: ノイズ除去世界モデル学習による困難な地形の習得
著者: Xinyang Gu、Yen-Jen Wang、Xiang Zhu、Cheng ming Shi、Yanjiang Guo、Yichen Liu、Jianyu Chen
機関: 北京興東時代科技有限公司、清華大学
論文リンク: https://enriquecoronadozu.github.io/rssproceedings2024/rss20/p058.pdf
現在の技術では、人型ロボットは平らな地面やそのような単純な地形でしか歩くことができません。しかし、実際の屋外シーンなどの複雑な環境で自由に移動させることは依然として困難です。この論文では、研究者らはノイズ除去ワールド モデル学習 (DWL) と呼ばれる新しい方法を提案しています。
DWL は、ヒューマノイド ロボットのモーション制御のためのエンドツーエンドの強化学習フレームワークです。このフレームワークにより、ロボットは雪、坂道、階段などのさまざまな平坦でない困難な地形に適応できます。これらのロボットは 1 つの学習プロセスのみを必要とし、追加の特別なトレーニングなしで現実世界のさまざまな地形の課題に対処できることは言及する価値があります。

この研究は、Beijing Xingdong Era Technology Co., Ltd.と清華大学によって共同で完了しました。 2023 年に設立された Xingdong Era は、清華大学のクロス情報研究所によって育成されたテクノロジー企業で、身体化知能および一般的なヒューマノイド ロボットの技術と製品を開発しています。創設者は、清華大学クロス情報研究所の助教授兼博士指導者の Chen Jianyu です。 、汎用人工知能 (AGI) の最先端のアプリケーションに焦点を当て、幅広い分野、複数のシナリオ、および高度な知能に適応できる汎用ヒューマノイド ロボットの開発に取り組んでいます。

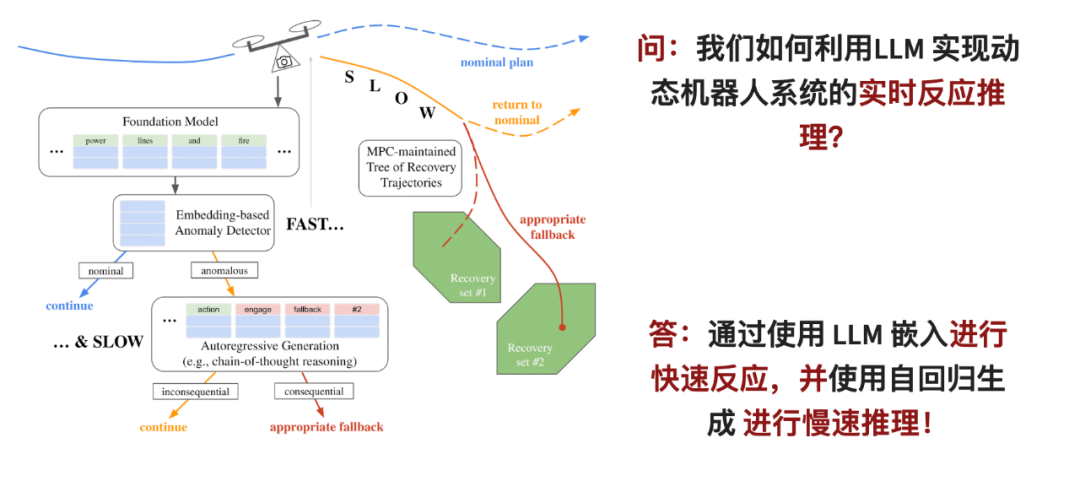
論文のタイトル: 大規模言語モデルを使用したリアルタイム異常検出と事後計画
著者: Rohan Sinha、Amine Elhafsi、Christopher Agia、Matt Foutter、Edward Schmerling、Marco Pavone
代替品:スタンフォード大学
論文リンク: https://arxiv.org/pdf/2407.08735
ゼロショット汎化機能を備えた大規模言語モデル (LLM)。これにより、検出および除外ロボットとして有望になります。システムの配布外障害。ただし、大規模な言語モデルが実際に機能するには、2 つの問題を解決する必要があります。1 つ目は、LLM をオンラインで適用するために大量のコンピューティング リソースが必要であること、2 つ目は、LLM の判断をロボットの安全制御システムに統合する必要があることです。この論文では、研究者らは 2 段階の推論フレームワークを提案しました。最初の段階では、LLM の理解空間でロボットの観察を迅速に分析できる高速な異常検出器を設計しました。問題が見つかった場合は、次の段階で、代替選択段階に入ります。この段階では、LLM の推論機能を使用して、より詳細な分析を実行します。
入ったステージは、モデル予測制御戦略の分岐点に対応しており、異なる代替計画を同時に追跡および評価して、遅い推論器の待ち時間の問題を解決できます。システムが何らかの異常や問題を検出すると、この戦略が直ちに起動され、ロボットの動作が安全であることが保証されます。
この論文の高速異常分類器は、比較的小さな言語モデルを使用した場合でも、最先端の GPT モデルを使用した自己回帰推論を上回ります。これにより、論文で提案されているリアルタイム モニターは、クアッドコプターや無人自動車など、限られたリソースと時間の下で動的ロボットの信頼性を向上させることができます。

- 論文タイトル: 操作計画のための構成空間距離フィールド
- 著者: Yiming Li、Xuemin Chi、Amirreza Razmjoo、Sylvain Calinon
- 機関: スイス I DIAP研究所、ローザンヌ、スイス連邦工科大学、浙江大学
- 論文リンク: https://arxiv.org/pdf/2406.01137
- 符号付き距離場 (SDF) は、ロボット工学で人気のある暗黙的な形状表現であり、以下の幾何学的情報を提供します。オブジェクトや障害物を検出し、制御、最適化、学習技術と簡単に組み合わせることができます。 SDF は通常、タスク空間内の距離を表すために使用されます。これは、3D 世界で人間が知覚する距離の概念に対応します。
ロボット工学の分野では、ロボットの各関節の角度を表すために SDF がよく使用されます。研究者は通常、ロボットの関節角度空間内のどの領域が安全であるか、つまりロボットの関節が衝突することなくこれらの領域まで回転できることを知っています。ただし、これらの安全領域を距離フィールドの観点から表現することはあまりありません。
この論文では、研究者らはロボット構成空間を最適化するために SDF を使用する可能性を提案しています。これを彼らは構成空間距離フィールド (略して CDF) と呼んでいます。 SDF を使用するのと同様に、CDF は効率的な関節角度距離の検索と導関数 (関節角速度) への直接アクセスを提供します。通常、ロボットの計画は 2 つのステップに分かれています。まず、タスク空間でアクションがターゲットからどれだけ離れているかを確認し、次に逆運動学を使用して関節がどのように回転するかを計算します。しかし、CDF はこれら 2 つのステップを 1 つのステップに結合し、ロボットの関節空間で直接問題を解決するため、よりシンプルかつ効率的になります。研究者らは論文の中で、あらゆるシナリオに拡張できる、CDFを計算して融合するための効率的なアルゴリズムを提案した。
彼らはまた、多層パーセプトロン (MLP) を使用して、コンパクトで連続的な表現を取得し、計算効率を向上させる、対応するニューラル CDF 表現を提案しました。この論文では、ロボットに飛行機上の障害物を回避させたり、7 軸ロボットのフランカにいくつかの行動計画タスクを完了させたりするなど、CDF の効果を実証するための具体的な例をいくつか示しています。これらの例は、CDF の有効性を示しています。机 CDF 方式のロボットアームはレイジングボックスタスクで作られています

初期プロフェッショナルスポットライト賞も受賞したステファン・ロイテネッガー氏です。未知の環境。
Stefan Leutenegger は、ミュンヘン工科大学 (TUM) のコンピューティング情報技術大学院 (CIT) の助教授 (テニュアトラック) であり、ミュンヘンロボット工学・機械知能研究所 ( MIRMI) とミュンヘン データ サイエンス研究所 (MDSI) はミュンヘン機械学習センター (MCML) と提携しており、ダイソン ロボティクス研究所のメンバーでした。彼が率いるスマート ロボット ラボラトリー (SRL) は、知覚、モバイル ロボット、ドローン、機械学習の交差点の研究に専念しています。さらに、ステファンはインペリアル カレッジ ロンドンのコンピューティング学科の客員講師を務めています。彼は、ロボットとドローンの測位およびマッピング ソリューションの商業化を目的としたスピンアウト会社、SLAMcore を共同設立しました。ステファンはチューリッヒ工科大学で機械工学の学士号と修士号を取得し、2014 年に「無人太陽航空機: 効率的で堅牢な自律運用のための設計とアルゴリズム」に関する論文で博士号を取得しました。
Test of Time Award
 RSS Test of Time Award は、少なくとも 10 年前に RSS (および場合によってはそのジャーナル版) に掲載された最も影響力のある論文に与えられます。影響は 3 つの側面から理解できます。たとえば、問題やロボットの設計に対する人々の考え方を変える、新しい問題にコミュニティの注目を集める、ロボットの設計や問題解決の新しい方法を生み出す、などです。
RSS Test of Time Award は、少なくとも 10 年前に RSS (および場合によってはそのジャーナル版) に掲載された最も影響力のある論文に与えられます。影響は 3 つの側面から理解できます。たとえば、問題やロボットの設計に対する人々の考え方を変える、新しい問題にコミュニティの注目を集める、ロボットの設計や問題解決の新しい方法を生み出す、などです。
この賞を通じて、RSS はこの分野の長期的な発展についての議論を刺激したいと考えています。今年の Time Test Award は、研究「LOAM: LiDAR レンジングとリアルタイム マッピング」に対して Ji Zhang 氏と Sanjiv Singh 氏に贈られます。
論文リンク: https://www.ri.cmu.edu/pub_files/2014/7/Ji_LidarMapping_RSS2014_v8.pdf
この10年前の論文は、ダブルAの6自由度の動きを利用する方法を提案していますオドメトリおよび軸 LIDAR オドメトリ データのマッピングのためのリアルタイム方法。この問題の解決が難しい理由は、測距データが異なる時間に受信され、動き推定のエラーが結果として得られる点群の位置ずれにつながる可能性があるためです。コヒーレント 3D マップは、オフライン バッチ手法によって構築できます。多くの場合、時間の経過によるドリフトを修正するためにループ クロージャが使用されます。この論文の方法は、高精度の測距や慣性測定を必要とせず、低ドリフトと低計算量を実現できます。 このレベルのパフォーマンスを達成する鍵は、複雑な同時位置決めとマッピングの問題を 2 つのアルゴリズムに分割して、多数の変数を同時に最適化することです。 1 つのアルゴリズムは測距を高周波数で実行しますが、忠実度は低く、ライダーの速度を推定します。もう 1 つのアルゴリズムは、点群の精密なマッチングと登録のために 1 桁低い周波数で動作します。これら 2 つのアルゴリズムを組み合わせることで、このメソッドはリアルタイムで描画できるようになります。研究者らは広範な実験とKITTI速度ベンチマークを通じてこの手法を評価し、その結果、この手法がオフラインバッチ手法のSOTA精度レベルを達成できることが示されました。 カンファレンスと賞の詳細については、公式 Web サイトを参照してください: https://roboticsconference.org/以上がロボット工学のトップカンファレンス「RSS 2024」で、中国の人型ロボット研究が最優秀論文賞を受賞の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1670
1670
 14
1428
52
1329
25
1274
29
1256
24
14
1428
52
1329
25
1274
29
1256
24

 DeepMind ロボットが卓球をすると、フォアハンドとバックハンドが空中に滑り出し、人間の初心者を完全に打ち負かしました
Aug 09, 2024 pm 04:01 PM
DeepMind ロボットが卓球をすると、フォアハンドとバックハンドが空中に滑り出し、人間の初心者を完全に打ち負かしました
Aug 09, 2024 pm 04:01 PM
でももしかしたら公園の老人には勝てないかもしれない?パリオリンピックの真っ最中で、卓球が注目を集めています。同時に、ロボットは卓球のプレーにも新たな進歩をもたらしました。先ほど、DeepMind は、卓球競技において人間のアマチュア選手のレベルに到達できる初の学習ロボット エージェントを提案しました。論文のアドレス: https://arxiv.org/pdf/2408.03906 DeepMind ロボットは卓球でどれくらい優れていますか?おそらく人間のアマチュアプレーヤーと同等です: フォアハンドとバックハンドの両方: 相手はさまざまなプレースタイルを使用しますが、ロボットもそれに耐えることができます: さまざまなスピンでサーブを受ける: ただし、ゲームの激しさはそれほど激しくないようです公園の老人。ロボット、卓球用
 初のメカニカルクロー!元羅宝は2024年の世界ロボット会議に登場し、家庭に入ることができる初のチェスロボットを発表した
Aug 21, 2024 pm 07:33 PM
初のメカニカルクロー!元羅宝は2024年の世界ロボット会議に登場し、家庭に入ることができる初のチェスロボットを発表した
Aug 21, 2024 pm 07:33 PM
8月21日、2024年世界ロボット会議が北京で盛大に開催された。 SenseTimeのホームロボットブランド「Yuanluobot SenseRobot」は、全製品ファミリーを発表し、最近、世界初の家庭用チェスロボットとなるYuanluobot AIチェスプレイロボット - Chess Professional Edition(以下、「Yuanluobot SenseRobot」という)をリリースした。家。 Yuanluobo の 3 番目のチェス対局ロボット製品である新しい Guxiang ロボットは、AI およびエンジニアリング機械において多くの特別な技術アップグレードと革新を経て、初めて 3 次元のチェスの駒を拾う機能を実現しました。家庭用ロボットの機械的な爪を通して、チェスの対局、全員でのチェスの対局、記譜のレビューなどの人間と機械の機能を実行します。
 クロードも怠け者になってしまった!ネチズン: 自分に休日を与える方法を学びましょう
Sep 02, 2024 pm 01:56 PM
クロードも怠け者になってしまった!ネチズン: 自分に休日を与える方法を学びましょう
Sep 02, 2024 pm 01:56 PM
もうすぐ学校が始まり、新学期を迎える生徒だけでなく、大型AIモデルも気を付けなければなりません。少し前、レディットはクロードが怠け者になったと不満を漏らすネチズンでいっぱいだった。 「レベルが大幅に低下し、頻繁に停止し、出力も非常に短くなりました。リリースの最初の週は、4 ページの文書全体を一度に翻訳できましたが、今では 0.5 ページの出力さえできません」 !」 https://www.reddit.com/r/ClaudeAI/comments/1by8rw8/something_just_feels_wrong_with_claude_in_the/ というタイトルの投稿で、「クロードには完全に失望しました」という内容でいっぱいだった。
 世界ロボット会議で「未来の高齢者介護の希望」を担う家庭用ロボットを囲みました
Aug 22, 2024 pm 10:35 PM
世界ロボット会議で「未来の高齢者介護の希望」を担う家庭用ロボットを囲みました
Aug 22, 2024 pm 10:35 PM
北京で開催中の世界ロボット会議では、人型ロボットの展示が絶対的な注目となっているスターダストインテリジェントのブースでは、AIロボットアシスタントS1がダルシマー、武道、書道の3大パフォーマンスを披露した。文武両道を備えた 1 つの展示エリアには、多くの専門的な聴衆とメディアが集まりました。弾性ストリングのエレガントな演奏により、S1 は、スピード、強さ、正確さを備えた繊細な操作と絶対的なコントロールを発揮します。 CCTVニュースは、「書道」の背後にある模倣学習とインテリジェント制御に関する特別レポートを実施し、同社の創設者ライ・ジエ氏は、滑らかな動きの背後にあるハードウェア側が最高の力制御と最も人間らしい身体指標(速度、負荷)を追求していると説明した。など)、AI側では人の実際の動きのデータが収集され、強い状況に遭遇したときにロボットがより強くなり、急速に進化することを学習することができます。そしてアジャイル
 ACL 2024 賞の発表: HuaTech による Oracle 解読に関する最優秀論文の 1 つ、GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
ACL 2024 賞の発表: HuaTech による Oracle 解読に関する最優秀論文の 1 つ、GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
貢献者はこの ACL カンファレンスから多くのことを学びました。 6日間のACL2024がタイのバンコクで開催されています。 ACL は、計算言語学と自然言語処理の分野におけるトップの国際会議で、国際計算言語学協会が主催し、毎年開催されます。 ACL は NLP 分野における学術的影響力において常に第一位にランクされており、CCF-A 推奨会議でもあります。今年の ACL カンファレンスは 62 回目であり、NLP 分野における 400 以上の最先端の作品が寄せられました。昨日の午後、カンファレンスは最優秀論文およびその他の賞を発表しました。今回の優秀論文賞は7件(未発表2件)、最優秀テーマ論文賞1件、優秀論文賞35件です。このカンファレンスでは、3 つの Resource Paper Award (ResourceAward) と Social Impact Award (
 Li Feifei 氏のチームは、ロボットに空間知能を与え、GPT-4o を統合する ReKep を提案しました
Sep 03, 2024 pm 05:18 PM
Li Feifei 氏のチームは、ロボットに空間知能を与え、GPT-4o を統合する ReKep を提案しました
Sep 03, 2024 pm 05:18 PM
ビジョンとロボット学習の緊密な統合。最近話題の1X人型ロボットNEOと合わせて、2つのロボットハンドがスムーズに連携して服をたたむ、お茶を入れる、靴を詰めるといった動作をしていると、いよいよロボットの時代が到来するのではないかと感じられるかもしれません。実際、これらの滑らかな動きは、高度なロボット技術 + 精緻なフレーム設計 + マルチモーダル大型モデルの成果です。有用なロボットは多くの場合、環境との複雑かつ絶妙な相互作用を必要とし、環境は空間領域および時間領域の制約として表現できることがわかっています。たとえば、ロボットにお茶を注いでもらいたい場合、ロボットはまずティーポットのハンドルを掴んで、お茶をこぼさないように垂直に保ち、次にポットの口がカップの口と揃うまでスムーズに動かす必要があります。 、そしてティーポットを一定の角度に傾けます。これ
 分散型人工知能カンファレンス DAI 2024 論文募集: エージェント デイ、強化学習の父であるリチャード サットン氏が出席します。 Yan Shuicheng、Sergey Levine、DeepMind の科学者が基調講演を行います
Aug 22, 2024 pm 08:02 PM
分散型人工知能カンファレンス DAI 2024 論文募集: エージェント デイ、強化学習の父であるリチャード サットン氏が出席します。 Yan Shuicheng、Sergey Levine、DeepMind の科学者が基調講演を行います
Aug 22, 2024 pm 08:02 PM
会議の紹介 科学技術の急速な発展に伴い、人工知能は社会の進歩を促進する重要な力となっています。この時代に、分散型人工知能 (DAI) の革新と応用を目撃し、参加できることは幸運です。分散型人工知能は人工知能分野の重要な分野であり、近年ますます注目を集めています。大規模言語モデル (LLM) に基づくエージェントは、大規模モデルの強力な言語理解機能と生成機能を組み合わせることで、自然言語対話、知識推論、タスク計画などにおいて大きな可能性を示しました。 AIAgent は大きな言語モデルを引き継ぎ、現在の AI 界隈で話題になっています。アウ
 宏蒙スマートトラベルS9とフルシナリオ新製品発売カンファレンス、多数の大ヒット新製品が一緒にリリースされました
Aug 08, 2024 am 07:02 AM
宏蒙スマートトラベルS9とフルシナリオ新製品発売カンファレンス、多数の大ヒット新製品が一緒にリリースされました
Aug 08, 2024 am 07:02 AM
今日の午後、Hongmeng Zhixingは新しいブランドと新車を正式に歓迎しました。 8月6日、ファーウェイはHongmeng Smart Xingxing S9およびファーウェイのフルシナリオ新製品発表カンファレンスを開催し、パノラマスマートフラッグシップセダンXiangjie S9、新しいM7ProおよびHuawei novaFlip、MatePad Pro 12.2インチ、新しいMatePad Air、Huawei Bisheng Withを発表しました。レーザー プリンタ X1 シリーズ、FreeBuds6i、WATCHFIT3、スマート スクリーン S5Pro など、スマート トラベル、スマート オフィスからスマート ウェアに至るまで、多くの新しいオールシナリオ スマート製品を開発し、ファーウェイは消費者にスマートな体験を提供するフル シナリオのスマート エコシステムを構築し続けています。すべてのインターネット。宏孟志興氏:スマートカー業界のアップグレードを促進するための徹底的な権限付与 ファーウェイは中国の自動車業界パートナーと提携して、
