AIxivコラムは、当サイトが学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。送信メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
この記事の著者は、浙江大学、上海人工知能研究所、香港中文大学、シドニー大学、オックスフォード大学の出身です。著者リスト: Wu Yixuan、Wang Yizhou、Tang Shixiang、Wu Wenhao、He Tong、Wanli Ouyang、Philip Torr、Jian Wu。その中で、共同筆頭著者のウー・イーシュアン氏は浙江大学の博士課程の学生であり、ワン・イージョウ氏は上海人工知能研究所の科学研究助手である。責任著者の Tang Shixiang は、香港中文大学の博士研究員です。
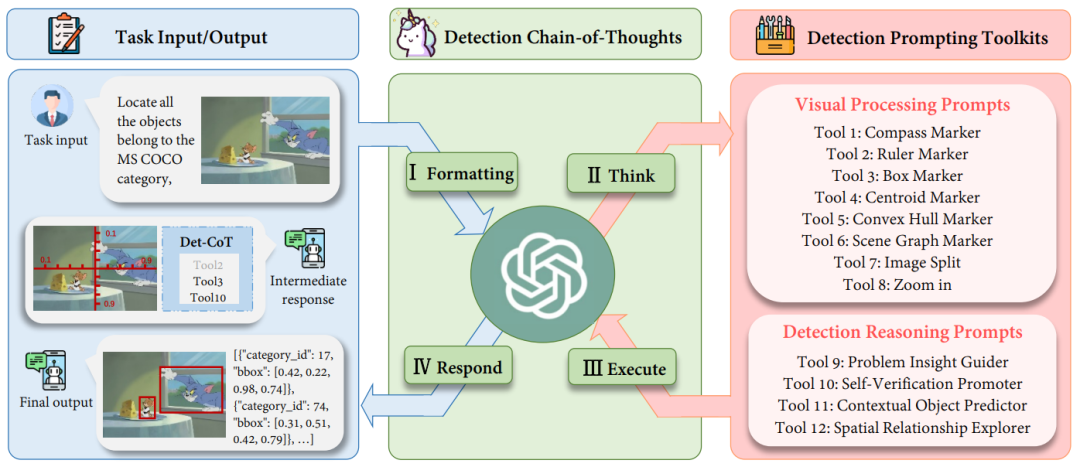
マルチモーダル大規模言語モデル (MLLM) はさまざまなタスクで優れた機能を示していますが、それにもかかわらず、検出タスクにおけるこれらのモデルの可能性は依然として過小評価されています。複雑な物体検出タスクで正確な座標が必要な場合、MLLM の幻覚により、ターゲット オブジェクトを見逃したり、不正確な境界ボックスを与えたりすることがよくあります。 MLLM の検出を可能にするために、既存の作業では、大量の高品質の命令データ セットを収集するだけでなく、オープンソース モデルを微調整する必要があります。時間と手間がかかりますが、クローズドソース モデルのより強力な視覚的理解機能を活用することもできません。この目的を達成するために、浙江大学は上海人工知能研究所およびオックスフォード大学と協力して、マルチモーダル大規模言語モデルの検出機能を解放する新しいプロンプトパラダイムであるDetToolChainを提案しました。大規模なマルチモーダル モデルは、トレーニングなしで正確に検出する方法を学習できます。関連する研究は ECCV 2024 に含まれています。 検出タスクにおける MLLM の問題を解決するために、DetToolChain は 3 つのポイントから開始します: (1) 検出のための視覚的なプロンプトを設計します。これは、従来のテキスト プロンプトよりも MLLM にとってより直接的かつ効果的です。 2) 詳細な検出タスクを小さくて単純なタスクに分割します。(3) 思考の連鎖を使用して検出結果を徐々に最適化し、大規模なマルチモーダル モデルの錯覚を可能な限り回避します。 上記の洞察に対応して、DetToolChain には 2 つの重要な設計が含まれています: (1) 包括的な視覚処理プロンプトのセット (視覚処理プロンプト)。これらは画像内に直接描画され、視覚情報と視覚情報の間のギャップを大幅に狭めることができます。テキスト情報の違い。 (2) 包括的な一連の検出推論により、検出ターゲットの空間的理解を強化し、サンプル適応型検出ツールチェーンを通じて最終的な正確なターゲット位置を徐々に決定します。 GPT-4VやGeminiなどのMLLMとDetToolChainを組み合わせることで、オープンボキャブラリーの検出、記述対象の検出、指示表現の理解、指向性の対象の検出など、さまざまな検出タスクを命令チューニングなしでサポートできます。 
- 論文のタイトル: DetToolChain: MLLM の検出能力を解き放つ新しいプロンプトパラダイム
- 論文のリンク: https://arxiv.org/abs/2403.12488
I. フォーマット: タスクの元の入力フォーマットを MLLM への入力として適切な命令テンプレートに変換します。 II. 特定の複雑な検出を分解します。タスクをより単純なサブタスクに分割し、検出ヒント ツールキット (プロンプト) から効果的なヒントを選択します。 III. 実行: 特定のプロンプト (プロンプト) を繰り返し実行します。
IV. MLLM 独自の推論機能を使用して、検出プロセス全体を監視します。そして最終応答(最終回答)を返します。
検出プロンプトツールキット: 視覚処理プロンプト
그림 2: 시각적 처리 프롬프트의 도식적 다이어그램. 우리는 다양한 관점에서 MLLM의 감지 기능을 향상시키기 위해 (1) 지역 증폭기, (2) 공간 측정 표준, (3) 장면 이미지 파서를 설계했습니다. 그림 2에 표시된 것처럼 (1) 지역 증폭기는 원본 이미지를 다른 하위 지역으로 자르고 하위 지역에 초점을 맞추는 것을 포함하여 관심 지역(ROI)에 대한 MLLM의 가시성을 향상시키는 것을 목표로 합니다. 또한, 줌 기능을 사용하면 이미지의 특정 하위 영역을 세밀하게 관찰할 수 있습니다. (2) 공간 측정 표준은 그림 2(2)와 같이 원본 이미지에 선형 눈금으로 눈금자와 나침반을 겹쳐서 대상 탐지를 위한 보다 명확한 기준을 제공합니다. 보조 눈금자와 나침반을 사용하면 MLLM이 이미지에 겹쳐진 변환 및 회전 참조를 사용하여 정확한 좌표와 각도를 출력할 수 있습니다. 기본적으로 이 보조선은 감지 작업을 단순화하여 MLLM이 물체를 직접 예측하는 대신 물체의 좌표를 읽을 수 있도록 합니다. (3) 장면 이미지 파서는 예측된 개체 위치 또는 관계를 표시하고 공간 및 상황 정보를 사용하여 이미지의 공간 관계 이해를 달성합니다. 장면 이미지 파서는 두 가지 범주로 나눌 수 있습니다. 첫 번째, 단일 대상 개체의 경우 예측 개체에 중심, 볼록 껍질 및 레이블 이름과 상자 인덱스가 있는 경계 상자 레이블을 지정합니다. 이러한 마커는 다양한 형식으로 개체 위치 정보를 나타내므로 MLLM은 다양한 모양과 배경의 다양한 개체, 특히 모양이 불규칙하거나 폐색이 심한 개체를 감지할 수 있습니다. 예를 들어, 볼록 껍질 마커는 물체의 경계점을 표시하고 이를 볼록 껍질로 연결하여 모양이 매우 불규칙한 물체의 감지 성능을 향상시킵니다. 두 번째로, 다중 목표를 위해 장면 그래프 마커를 통해 다양한 개체의 중심을 연결하여 이미지 속 개체 간의 관계를 강조합니다. MLLM은 장면 그래프를 기반으로 상황별 추론 기능을 활용하여 예측 경계 상자를 최적화하고 환각을 피할 수 있습니다. 예를 들어, 그림 2(3)에 표시된 것처럼 Jerry는 치즈를 먹고 싶어하므로 경계 상자가 매우 가까워야 합니다. 탐지 추론 프롬프트 툴킷: 감지 추론 프롬프트
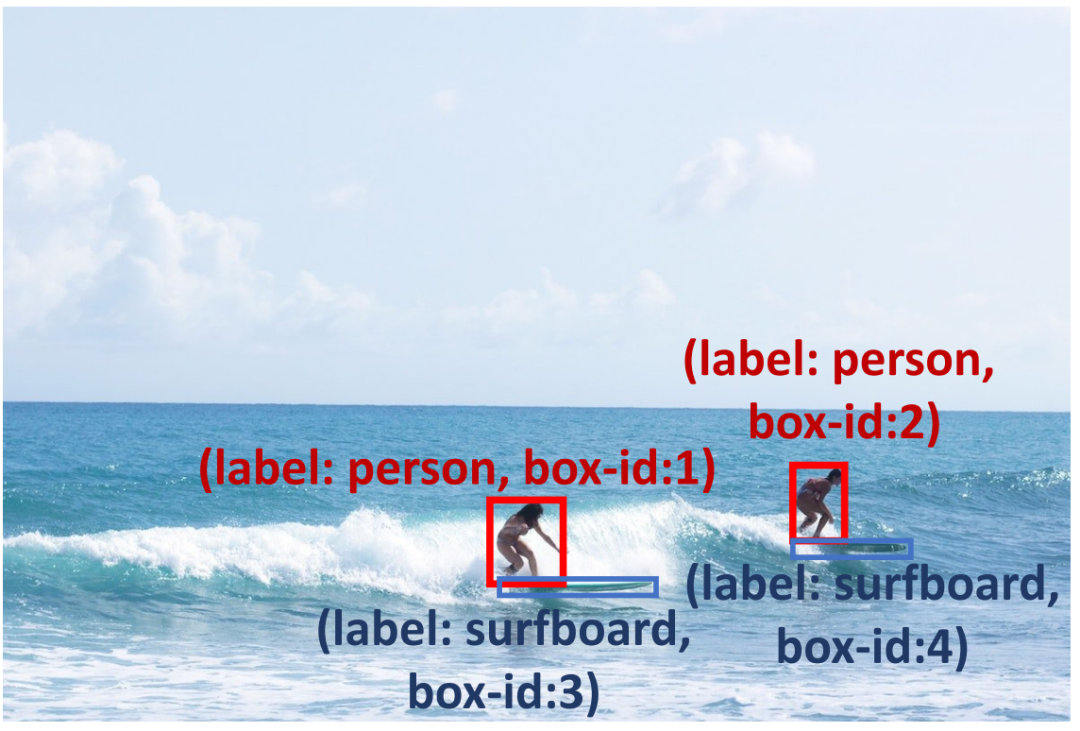
예측 상자의 신뢰성을 높이기 위해 감지 추론 프롬프트(표 1 참조)를 수행하여 예측 결과를 확인하고 잠재적인 문제를 진단했습니다. . 먼저, 어려운 문제를 강조하고 쿼리 이미지에 대한 효과적인 탐지 제안 및 유사한 예를 제공하는 Problem Insight Guider를 제안합니다. 예를 들어 그림 3의 경우 Problem Insight Guider는 쿼리를 작은 물체 감지 문제로 정의하고 서핑보드 영역을 확대하여 해결하도록 제안합니다. 둘째, MLLM의 고유한 공간 및 상황별 기능을 활용하기 위해 공간 관계 탐색기 및 상황별 개체 예측기를 설계하여 탐지 결과가 상식과 일치하도록 합니다. 그림 3에서 볼 수 있듯이 서핑보드는 바다와 함께 발생할 수 있으며(맥락적 지식), 서핑하는 사람의 발 근처에 서핑보드가 있어야 합니다(공간적 지식). 또한, 자체 검증 프로모터(Self-Verification Promoter)를 적용하여 여러 라운드에 걸쳐 응답의 일관성을 향상합니다. MLLM의 추론 능력을 더욱 향상시키기 위해 토론 및 자체 디버깅과 같이 널리 사용되는 프롬프트 방법을 채택합니다. 자세한 설명은 원문을 참조하시기 바랍니다. ㅋㅋㅋ 감지 추론 힌트는 MLLM이 작은 물체 감지 문제를 해결하는 데 도움이 될 수 있습니다. 예를 들어 상식을 사용하여 사람의 발 아래에서 서핑 보드를 찾고 모델이 바다에서 서핑 보드를 감지하도록 장려합니다.
Experiment : 2에 표시된 것처럼 테이블에 표시된 것처럼 훈련없이 미세 조정 방법을 능가 할 수 있습니다. OVD (Open Vocabulary Detection)에 대한 방법을 평가했습니다. , 17개의 새로운 클래스, 48개의 기본 클래스 및 COCO OVD 벤치마크의 모든 클래스에 대한 AP50 결과를 테스트했습니다. 결과는 DetToolChain을 사용하여 GPT-4V와 Gemini의 성능이 크게 향상되었음을 보여줍니다.
为了展示我们的方法在指称表达理解上的有效性,我们将我们的方法与其他零样本方法在 RefCOCO、RefCOCO + 和 RefCOCOg 数据集上进行了比较(表 5)。在 RefCOCO 上,DetToolChain 使得 GPT-4V 基线在 val、test-A 和 test-B 上的性能分别提升了 44.53%、46.11% 和 24.85%,展示了 DetToolChain 在 zero-shot 条件下优越的指称表达理解和定位性能。以上がECCV 2024 | GPT-4V および Gemini 検出タスクのパフォーマンスを向上するには、このプロンプト パラダイムが必要ですの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。






















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



