

無制限のビデオ生成、計画と意思決定、次のトークン予測とフルシーケンス拡散の拡散強制統合

現在、次のトークン予測パラダイムを使用した自己回帰大規模言語モデルが世界中で普及しており、同時にインターネット上の多数の合成画像や動画がすでに拡散の力を示しています。モデル。
最近、MIT CSAIL の研究チーム (その 1 人は MIT の博士課程学生である Chen Boyuan です) は、全系列拡散モデルとネクスト トークン モデルの強力な機能を統合することに成功し、トレーニングとサンプリングを提案しました。パラダイム: 拡散強制(DF)。

論文のタイトル: Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion
論文のアドレス: https://arxiv.org/pdf/2407.01392
プロジェクトのウェブサイト: https:/ /arxiv.org/pdf/2407.01392 /boyuan.space/diffusion-forcing
コードアドレス: https://github.com/buoyancy99/diffusion-forcing
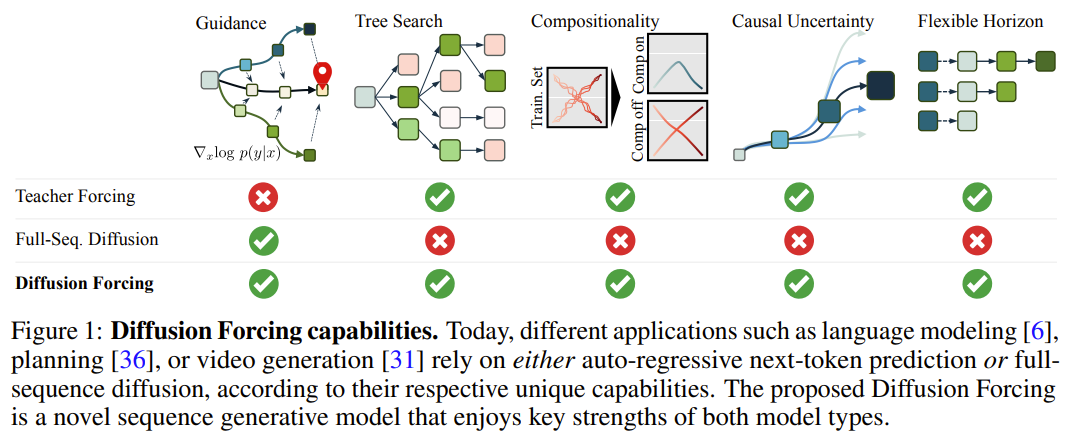
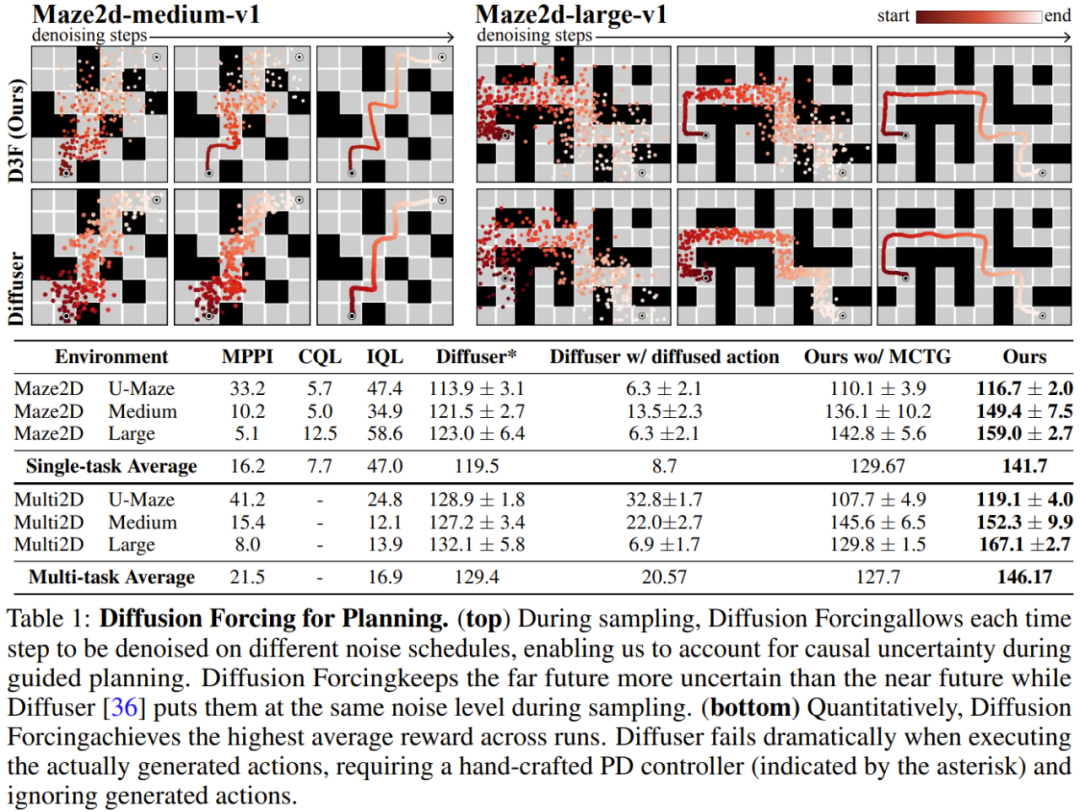
以下に示すように、拡散強制は明らかにすべての点で優れています。一貫性と安定性の観点 2 つの方法は、シーケンス拡散と教師強制です。

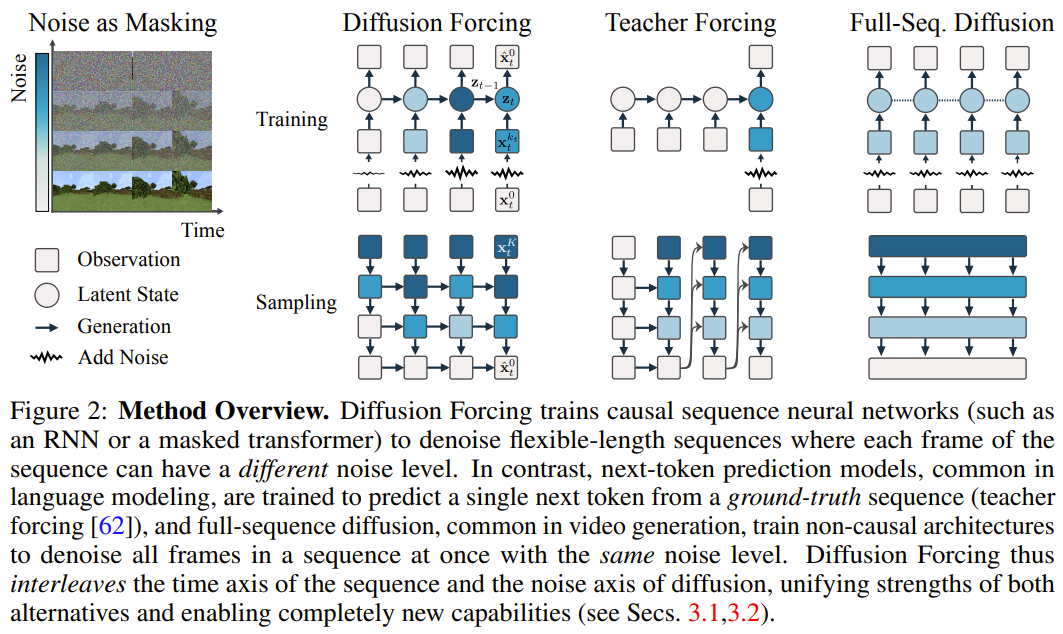
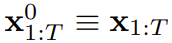 ) は、「ノイズ軸に沿ってマスキングを実行する」
) は、「ノイズ軸に沿ってマスキングを実行する」  は (おそらく) ホワイト ノイズとなり、元のデータに関する情報はなくなりました。図 2 に示すように、チームはこれら 2 つの軸のエッジ マスクを確認するための統一された視点を確立しました。
は (おそらく) ホワイト ノイズとなり、元のデータに関する情報はなくなりました。図 2 に示すように、チームはこれら 2 つの軸のエッジ マスクを確認するための統一された視点を確立しました。 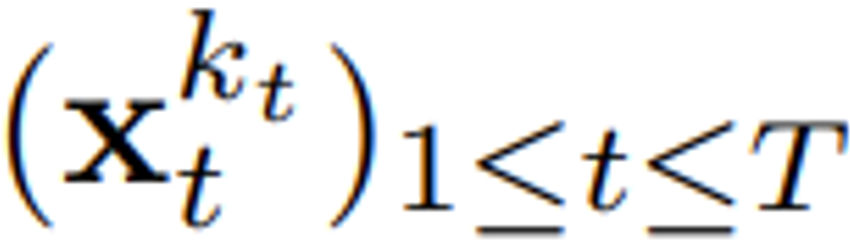 に従って進化します。入力ノイズ観測値
に従って進化します。入力ノイズ観測値 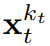 が取得されると、隠れ状態がマルコフ方式で更新されます。
が取得されると、隠れ状態がマルコフ方式で更新されます。 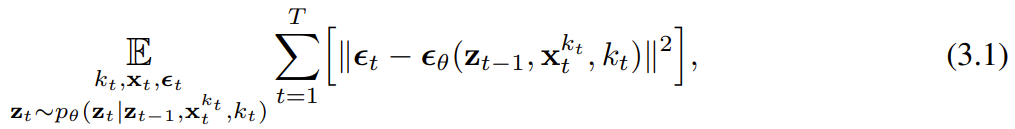

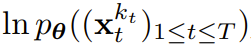 の証拠下限 (ELBO) を最適化する再重み付けです。ここで、期待値はノイズ レベル全体にわたって平均され、
の証拠下限 (ELBO) を最適化する再重み付けです。ここで、期待値はノイズ レベル全体にわたって平均され、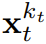 は順方向プロセスに従ってノイズが多くなります。さらに、適切な条件下では、(3.1) を最適化すると、すべてのノイズ レベル シーケンスの下限を同時に最大化することもできます。
は順方向プロセスに従ってノイズが多くなります。さらに、適切な条件下では、(3.1) を最適化すると、すべてのノイズ レベル シーケンスの下限を同時に最大化することもできます。 
安定した自己回帰生成 将来を不確実にしておく 長期的なガイダンス機能
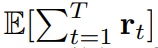 の期待累積報酬を最大化するようにポリシー π(a_t|o_{1:t}) をトレーニングすることです。ここではトークン x_t = [a_t, r_t, o_{t+1}] が割り当てられます。軌跡はシーケンス x_{1:T} であり、その長さは可変であり、トレーニング方法はアルゴリズム 1 に示すとおりです。
の期待累積報酬を最大化するようにポリシー π(a_t|o_{1:t}) をトレーニングすることです。ここではトークン x_t = [a_t, r_t, o_{t+1}] が割り当てられます。軌跡はシーケンス x_{1:T} であり、その長さは可変であり、トレーニング方法はアルゴリズム 1 に示すとおりです。 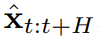 がサンプリングされます。ここで
がサンプリングされます。ここで 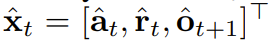 には、予測されたアクション、報酬、および観察が含まれます。 H は前方観測ウィンドウであり、モデル予測制御における将来予測に似ています。計画されたアクションを実行した後、環境は報酬と次の観察、つまり次のトークンを受け取ります。隠れ状態は事後 p_θ(z_t|z_{t−1}, x_t, 0) に従って更新できます。
には、予測されたアクション、報酬、および観察が含まれます。 H は前方観測ウィンドウであり、モデル予測制御における将来予測に似ています。計画されたアクションを実行した後、環境は報酬と次の観察、つまり次のトークンを受け取ります。隠れ状態は事後 p_θ(z_t|z_{t−1}, x_t, 0) に従って更新できます。 柔軟な計画期間を持つ 柔軟な報酬ガイダンスを可能にする を達成できる将来の不確実性を達成するためのカルロ ツリー ガイダンス (MCTG)




以上が無制限のビデオ生成、計画と意思決定、次のトークン予測とフルシーケンス拡散の拡散強制統合の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7315
7315
 9
1625
14
1348
46
1260
25
1207
29
9
1625
14
1348
46
1260
25
1207
29

 RLHF から DPO、TDPO に至るまで、大規模なモデル アライメント アルゴリズムはすでに「トークンレベル」になっています
Jun 24, 2024 pm 03:04 PM
RLHF から DPO、TDPO に至るまで、大規模なモデル アライメント アルゴリズムはすでに「トークンレベル」になっています
Jun 24, 2024 pm 03:04 PM
RLHF から DPO、TDPO に至るまで、大規模なモデル アライメント アルゴリズムはすでに「トークンレベル」になっています
 OpenAI Super Alignment チームの遺作: 2 つの大きなモデルがゲームをプレイし、出力がより理解しやすくなる
Jul 19, 2024 am 01:29 AM
OpenAI Super Alignment チームの遺作: 2 つの大きなモデルがゲームをプレイし、出力がより理解しやすくなる
Jul 19, 2024 am 01:29 AM
OpenAI Super Alignment チームの遺作: 2 つの大きなモデルがゲームをプレイし、出力がより理解しやすくなる
 オープンソース AI ソフトウェア エンジニアのリストのトップに立つ UIUC のエージェントレス ソリューションは、SWE ベンチの実際のプログラミングの問題を簡単に解決します
Jul 17, 2024 pm 10:02 PM
オープンソース AI ソフトウェア エンジニアのリストのトップに立つ UIUC のエージェントレス ソリューションは、SWE ベンチの実際のプログラミングの問題を簡単に解決します
Jul 17, 2024 pm 10:02 PM
オープンソース AI ソフトウェア エンジニアのリストのトップに立つ UIUC のエージェントレス ソリューションは、SWE ベンチの実際のプログラミングの問題を簡単に解決します
 ControlNet の作者がまたヒット作を出しました!写真から絵画を生成し、2 日間で 1.4,000 個のスターを獲得する全プロセス
Jul 17, 2024 am 01:56 AM
ControlNet の作者がまたヒット作を出しました!写真から絵画を生成し、2 日間で 1.4,000 個のスターを獲得する全プロセス
Jul 17, 2024 am 01:56 AM
ControlNet の作者がまたヒット作を出しました!写真から絵画を生成し、2 日間で 1.4,000 個のスターを獲得する全プロセス
 arXiv 論文は「弾幕」として投稿可能、スタンフォード alphaXiv ディスカッション プラットフォームはオンライン、LeCun は気に入っています
Aug 01, 2024 pm 05:18 PM
arXiv 論文は「弾幕」として投稿可能、スタンフォード alphaXiv ディスカッション プラットフォームはオンライン、LeCun は気に入っています
Aug 01, 2024 pm 05:18 PM
arXiv 論文は「弾幕」として投稿可能、スタンフォード alphaXiv ディスカッション プラットフォームはオンライン、LeCun は気に入っています
 無制限のビデオ生成、計画と意思決定、次のトークン予測とフルシーケンス拡散の拡散強制統合
Jul 23, 2024 pm 02:05 PM
無制限のビデオ生成、計画と意思決定、次のトークン予測とフルシーケンス拡散の拡散強制統合
Jul 23, 2024 pm 02:05 PM
無制限のビデオ生成、計画と意思決定、次のトークン予測とフルシーケンス拡散の拡散強制統合
 リーマン予想の大きな進歩!陶哲軒氏はMITとオックスフォードの新しい論文を強く推薦し、37歳のフィールズ賞受賞者も参加した
Aug 05, 2024 pm 03:32 PM
リーマン予想の大きな進歩!陶哲軒氏はMITとオックスフォードの新しい論文を強く推薦し、37歳のフィールズ賞受賞者も参加した
Aug 05, 2024 pm 03:32 PM
リーマン予想の大きな進歩!陶哲軒氏はMITとオックスフォードの新しい論文を強く推薦し、37歳のフィールズ賞受賞者も参加した
 公理的トレーニングにより、LLM は因果推論を学習できます。6,700 万個のパラメータ モデルは、1 兆個のパラメータ レベル GPT-4 に匹敵します。
Jul 17, 2024 am 10:14 AM
公理的トレーニングにより、LLM は因果推論を学習できます。6,700 万個のパラメータ モデルは、1 兆個のパラメータ レベル GPT-4 に匹敵します。
Jul 17, 2024 am 10:14 AM
公理的トレーニングにより、LLM は因果推論を学習できます。6,700 万個のパラメータ モデルは、1 兆個のパラメータ レベル GPT-4 に匹敵します。
