
 テクノロジー周辺機器
AI
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
テクノロジー周辺機器
AI
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。


Editor | ScienceAI
質問と回答 (QA) データセットは、自然言語処理 (NLP) 研究を促進する上で重要な役割を果たします。高品質の QA データ セットは、モデルの微調整に使用できるだけでなく、大規模言語モデル (LLM) の機能、特に科学的知識を理解し推論する能力を効果的に評価することもできます。
現在、医学、化学、生物学、その他の分野をカバーする多くの科学 QA データ セットがありますが、これらのデータ セットにはまだいくつかの欠点があります。
まず、データ形式は比較的単純で、そのほとんどが多肢選択式の質問であり、評価は簡単ですが、モデルの回答の選択範囲が制限され、科学的な質問に回答するモデルの能力を完全にテストすることはできません。対照的に、公開質問応答 (openQA) では、モデルの機能をより包括的に評価できますが、適切な評価指標がありません。
第二に、既存のデータセットの内容の多くは大学レベル以下の教科書からのものであり、実際の学術研究や生産環境でLLMの高度な知識保持能力を評価することが困難です。
第三に、これらのベンチマーク データセットの作成は人間の専門家のアノテーションに依存しています。
これらの課題に対処することは、より包括的な QA データセットを構築するために重要であり、科学的 LLM のより正確な評価にも役立ちます。
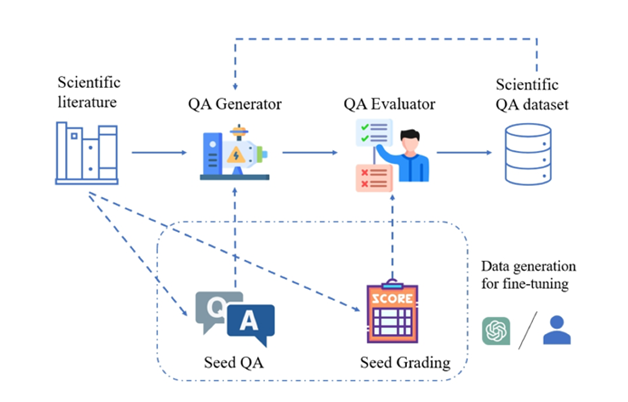
イラスト: 科学文献から高品質の科学的な質問と回答のペアを生成するための SciQAG フレームワーク。
この目的のために、米国のアルゴンヌ国立研究所、シカゴ大学のイアン・フォスター教授のチーム(2002年ゴードン・ベル賞受賞者)、ニューサウスウェールズ大学のブラム・ホークス教授のUNSW AI4Scienceチーム、オーストラリア、AI4Science 企業 GreenDynamics、および香港城市大学の Jie Chunyu 教授のチームは共同で、大規模な言語モデルに基づいて大規模な科学文献コーパスから高品質の科学的公開質問と回答のペアを自動的に生成する初の新しいフレームワークである SciQAG を提案しました。 (LLM)。

論文リンク:https://arxiv.org/abs/2405.09939
githubリンク:https://github.com/MasterAI-EAM/SciQAG
研究者らはSciQAGに基づいて構築したSciQAG-24D は、大規模で高品質のオープンな科学 QA データセットで、24 の科学分野の 22,743 の科学論文から抽出された 188,042 の QA ペアが含まれており、LLM の微調整と科学的問題の評価に役立つように設計されています。解決能力。
実験では、SciQAG-24D データセットで LLM を微調整すると、自由回答形式の質問応答や科学的タスクのパフォーマンスが大幅に向上することが実証されました。
AI for Science コミュニティによるオープンな科学 Q&A の共同開発を促進するために、データセット、モデル、評価コードがオープンソース化されました (https://github.com/MasterAI-EAM/SciQAG)。
SciQAG-24D ベンチマーク データセットを備えた SciQAG フレームワーク
SciQAG は、QA ジェネレーターと QA エバリュエーターで構成され、科学文献に基づいた多様な未解決の質問と回答のペアを大規模に迅速に生成することを目的としています。まず、ジェネレータが科学論文を質問と回答のペアに変換し、次に評価者が品質基準を満たさない質問と回答のペアをフィルタリングして、高品質の科学的質問と回答のデータセットを取得します。
QA ジェネレーター
研究者らは比較実験を通じて 2 段階のプロンプト (プロンプト) を設計し、LLM が最初にキーワードを抽出し、次にそのキーワードに基づいて質問と回答のペアを生成できるようにしました。
生成された質問と回答のデータセットは「クローズドブック」モードを採用しているため、つまり元の論文は提供されず、抽出された科学的知識自体にのみ焦点を当てています。プロンプトは、生成された質問と回答のペアが依存しないことを要求します。元の論文に含まれる固有の情報について言及したり、「この論文」、「この研究」などの現代的な命名法を使用したり、その表や写真について質問したりすることはできません。記事)。
パフォーマンスとコストのバランスを取るために、研究者らはオープンソース LLM をジェネレーターとして微調整することを選択しました。 SciQAG ユーザーは、微調整またはプロンプト ワード エンジニアリングを使用して、独自の状況に応じて、オープン ソースまたはクローズド ソースの LLM をジェネレーターとして選択できます。
QA エバリュエーター
エバリュエーターは、(1) 生成された質問と回答のペアの品質を評価する、(2) 設定された基準に基づいて低品質の質問と回答のペアを破棄する、という 2 つの目的を達成するために使用されます。
研究者らは、関連性、不可知論、完全性、正確性、合理性の 5 つの側面から構成される包括的な評価指標 RACAR を開発しました。
この研究では、研究者らは QA 評価ツールとして GPT-4 を直接使用し、生成された QA ペアを RACAR に従って 1 ~ 5 の評価レベルで評価しました (1 は許容できないことを意味し、5 は完全に許容できることを意味します)。
図に示すように、GPT-4 と手動評価の間の一貫性を測定するために、2 人のドメイン専門家が RACAR メトリクスを使用して 10 件の記事 (合計 100 の質問と回答のペア) に対して手動評価を実行しました。ユーザーは、ニーズに応じて、オープンソースまたはクローズドソースの LLM を評価者として選択できます。
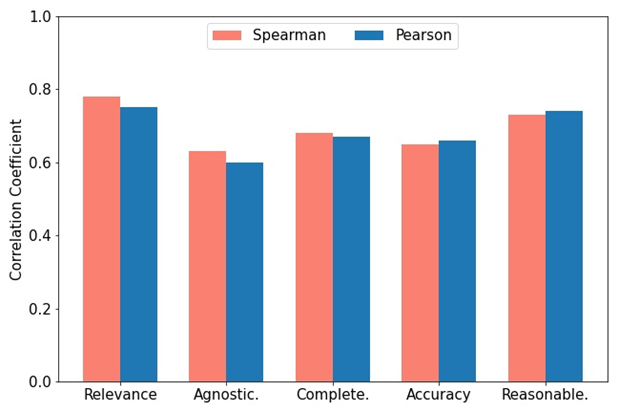
図: GPT-4 に割り当てられたスコアと専門家の注釈スコアの間のスピアマンとピアソンの相関関係。
SciQAG フレームワークの適用
この研究では、Web of Science (WoS) コア コレクション データベースから、材料科学、化学、物理学、エネルギーなどの分野から、24 のカテゴリーで合計 22,743 件の高被引用論文を取得しました。 、信頼性が高く、豊富でバランスの取れた代表的な科学知識の情報源を構築することを目指しています。
オープンソース LLM を微調整して QA ジェネレーターを形成するために、研究者らは論文コレクションから 426 の論文を入力としてランダムに選択し、GPT-4 をプロンプトすることで 4260 のシード QA ペアを生成しました。
トレーニング済み QA ジェネレーターを使用して残りの論文に対して推論を実行し、合計 227,430 の QA ペア (シード QA ペアを含む) が生成されました。各カテゴリから 50 件の論文 (合計 1,200 件の論文) が抽出され、GPT-4 を使用して生成された各 QA ペアの RACAR スコアが計算され、いずれかのディメンション スコアが 3 未満の QA ペアがテスト セットとして除外されました。
残りの QA ペアについては、ルールベースの方法を使用して、論文の一意の情報を含むすべての質問と回答のペアをフィルタリングして除外し、トレーニング セットを形成します。
SciQAG-24D ベンチマーク データ セット
上記に基づいて、研究者はオープン科学 QA ベンチマーク データ セット SciQAG-24D を確立しました。フィルターされたトレーニング セットには 21,529 の論文と 179,511 の QA ペアが含まれ、フィルターされたテスト セットには次のものが含まれます。 1,199 件の論文と 8,531 件の QA ペア。
統計によると、回答内のデータの 99.15% は元の論文からのものであり、質問の 87.29% の類似性は 0.3 未満であり、回答は元のコンテンツの 78.26% をカバーしています。
このデータセットは広く使用されています。トレーニングセットはLLMを微調整し、科学的知識を注入するために使用できます。テストセットは、特定または全体的な科学分野におけるオープンQAタスクにおけるLLMのパフォーマンスを評価するために使用できます。 。テスト セットが大きいため、微調整用の高品質データとしても使用できます。
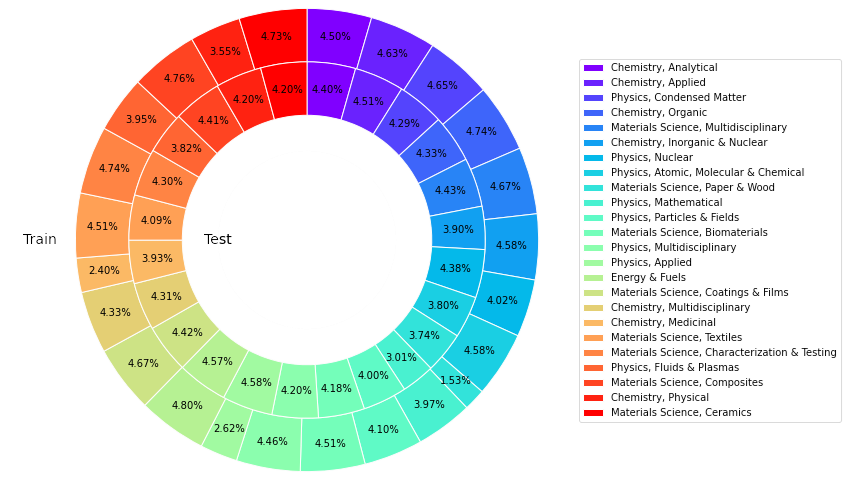
図: SciQAG-24D データセットのトレーニングとテストにおけるさまざまなカテゴリの記事の割合。
実験結果
研究者らは、異なる言語モデル間の科学的質問応答のパフォーマンスの違いを比較し、微調整の影響を調査するために包括的な実験を実施しました。
ゼロショット設定
研究者らは、SciQAG-24D のテストセットの一部を使用して、5 つのモデルのゼロショット性能を比較しました。そのうちの 2 つはオープンソース LLM、LLaMA1 (7B) と LLaMA2-chat (7B) で、残りはクローズドソース LLM です。
API 経由で呼び出します: GPT3.5 (gpt-3.5-turbo)、GPT-4 (gpt-4-1106-preview)、および Claude 3 (claude-3-opus-20240229)。テストでは各モデルに 1,000 の質問が表示され、その出力は CAR メトリクス (応答評価のみに焦点を当て、RACAR メトリクスから適応) によって評価され、科学研究の質問に答えるゼロショット能力が測定されました。
図に示すように、すべてのモデルの中で、GPT-4 は完全性 (4.90) と妥当性 (4.99) のスコアが最も高く、Claude 3 は精度スコア (4.95) が最も高くなります。 GPT-3.5 も非常に優れたパフォーマンスを示し、すべての指標で GPT-4 および Claude 3 に僅差のスコアを付けています。
特に、LLaMA1 は 3 つの次元すべてで最も低いスコアを持っています。対照的に、LLaMA2 チャット モデルは GPT モデルほどスコアは高くありませんが、すべての指標において元の LLaMA1 よりも大幅に向上しています。この結果は、科学的な質問に答える上で商用 LLM の優れたパフォーマンスが実証されている一方、オープンソース モデル (LLaMA2 チャットなど) もこの点で大きな進歩を遂げています。
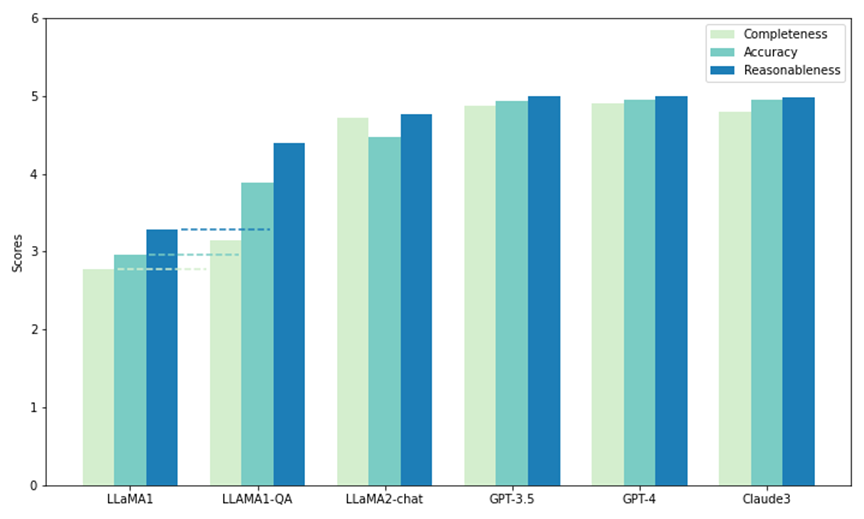
図: SciQAG-24D でのゼロサンプルテストと微調整テスト (LLAMA1-QA)
微調整設定 (微調整設定)
研究者は、最悪のゼロを持つ LLaMA1 を選択しました。サンプルパフォーマンス SciQAG-24D のトレーニングセットに対して微調整を実行し、LLaMA1-QA を取得します。 3 つの実験を通じて、研究者らは、SciQAG-24D が下流の科学タスクのパフォーマンスを向上させるための効果的な微調整データとして使用できることを実証しました:
(a) 目に見えない SciQAG-24D テスト セットでの LLaMA-QA と元の LLaMA1 のパフォーマンス比較。
上の図に示すように、LLaMA1-QA のパフォーマンスは、元の LLaMA1 と比較して大幅に向上しました (完全性は 13% 向上、精度と妥当性は 30% 以上向上)。これは、LLaMA1 が SciQAG-24D の訓練データから科学的質問に答えるロジックを学習し、科学的知識を内面化していることを示しています。
(b) 科学的な MCQ ベンチマークである SciQ での微調整パフォーマンスの比較。
以下の表の最初の行は、LLaMA1-QA が LLaMA1 よりわずかに優れている (+1%) ことを示しています。観察によると、微調整によりモデルの命令追従能力も向上しました。解析できない出力の確率は、LLaMA1 の 4.1% から LLaMA1-QA の 1.7% に低下しました。
(c) さまざまな科学的タスクにおける微調整パフォーマンスの比較。
評価指標としては、分類タスクにはF1スコア、回帰タスクにはMAE、変換タスクにはKLダイバージェンスが使用されます。以下の表に示すように、LLaMA1-QA は、科学的タスクにおいて LLaMA1 モデルと比較して大幅な改善が見られます。
最も明らかな改善は回帰タスクに反映されており、MAE が 463.96 から 185.32 に低下しました。これらの発見は、トレーニング中に QA ペアを組み込むことで、科学的知識を学習して適用するモデルの能力が向上し、それによって下流の予測タスクのパフォーマンスが向上する可能性があることを示唆しています。
驚くべきことに、LLM は、機能を備えた特別に設計された機械学習モデルと比較して、一部のタスクでは同等またはそれを上回る結果を達成できます。たとえば、バンド ギャップ タスクでは、LLaMA1-QA は MODNet (0.3327) などのモデルほどのパフォーマンスはありませんが、AMMExpress v2020 (0.4161) を上回っています。
多様性タスクでは、LLaMA1-QA が深層学習ベースライン (0.3198) を上回りました。これらの発見は、LLM が特定の科学的タスクにおいて大きな可能性を秘めていることを示しています。
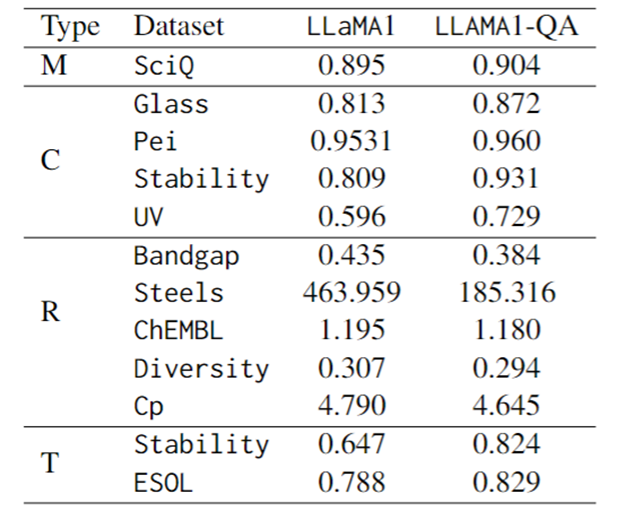
図: SciQ および科学的タスクにおける LLaMA1 および LLaMA1-QA のパフォーマンスの微調整 (M は多肢選択を表し、C は分類を表し、R は回帰を表し、T は変換を表します)
概要と展望
( 1) SciQAG は、科学文献から QA ペアを生成するためのフレームワークであり、QA ペアを評価およびスクリーニングするための RACAR メトリクスと組み合わせることで、リソースが乏しい科学分野向けに大量の知識ベースの QA データを効率的に生成できます。
(2) チームは、SciQAG-24D と呼ばれる、188,042 の QA ペアを含む包括的なオープンソースの科学 QA データセットを生成しました。トレーニング セットは LLM を微調整するために使用され、テスト セットはオープンエンドのクローズドブック科学 QA タスクにおける LLM のパフォーマンスを評価します。
SciQAG-24D テスト セット上のいくつかの LLM のゼロサンプル パフォーマンスが比較され、LLaMA1-QA を取得するために SciQAG-24D トレーニング セット上で LLaMA1 が微調整されました。この微調整により、複数の科学的タスクにおけるパフォーマンスが大幅に向上します。
(3) 研究によると、LLM には科学的タスクにおける可能性があり、LLaMA1-QA の結果は機械学習のベースラインを超えるレベルに達する可能性があります。これは、SciQAG-24D の多面的な有用性を示しており、科学的な QA データをトレーニング プロセスに組み込むことで、科学的知識を学習して適用する LLM の能力を強化できることを示しています。
以上が新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1672
1672
 14
1428
52
1332
25
1276
29
1256
24
14
1428
52
1332
25
1276
29
1256
24

 「Defect Spectrum」は、従来の欠陥検出の限界を打ち破り、超高精度かつ豊富なセマンティックな産業用欠陥検出を初めて実現します。
Jul 26, 2024 pm 05:38 PM
「Defect Spectrum」は、従来の欠陥検出の限界を打ち破り、超高精度かつ豊富なセマンティックな産業用欠陥検出を初めて実現します。
Jul 26, 2024 pm 05:38 PM
現代の製造において、正確な欠陥検出は製品の品質を確保するための鍵であるだけでなく、生産効率を向上させるための核心でもあります。ただし、既存の欠陥検出データセットには、実際のアプリケーションに必要な精度や意味論的な豊富さが欠けていることが多く、その結果、モデルが特定の欠陥カテゴリや位置を識別できなくなります。この問題を解決するために、広州香港科技大学と Simou Technology で構成されるトップの研究チームは、産業欠陥に関する詳細かつ意味的に豊富な大規模なアノテーションを提供する「DefectSpectrum」データセットを革新的に開発しました。表 1 に示すように、他の産業データ セットと比較して、「DefectSpectrum」データ セットは最も多くの欠陥注釈 (5438 個の欠陥サンプル) と最も詳細な欠陥分類 (125 個の欠陥カテゴリ) を提供します。
 NVIDIA 対話モデル ChatQA はバージョン 2.0 に進化し、コンテキストの長さは 128K と記載されています
Jul 26, 2024 am 08:40 AM
NVIDIA 対話モデル ChatQA はバージョン 2.0 に進化し、コンテキストの長さは 128K と記載されています
Jul 26, 2024 am 08:40 AM
オープンな LLM コミュニティは百花繚乱の時代です Llama-3-70B-Instruct、QWen2-72B-Instruct、Nemotron-4-340B-Instruct、Mixtral-8x22BInstruct-v0.1 などがご覧いただけます。優秀なパフォーマーモデル。しかし、GPT-4-Turboに代表される独自の大型モデルと比較すると、オープンモデルには依然として多くの分野で大きなギャップがあります。一般的なモデルに加えて、プログラミングと数学用の DeepSeek-Coder-V2 や視覚言語タスク用の InternVL など、主要な領域に特化したいくつかのオープン モデルが開発されています。
 結晶相問題を解決するための数百万の結晶データを使用したトレーニング、深層学習手法 PhAI が Science 誌に掲載
Aug 08, 2024 pm 09:22 PM
結晶相問題を解決するための数百万の結晶データを使用したトレーニング、深層学習手法 PhAI が Science 誌に掲載
Aug 08, 2024 pm 09:22 PM
編集者 |KX 今日に至るまで、単純な金属から大きな膜タンパク質に至るまで、結晶学によって決定される構造の詳細と精度は、他のどの方法にも匹敵しません。しかし、最大の課題、いわゆる位相問題は、実験的に決定された振幅から位相情報を取得することのままです。デンマークのコペンハーゲン大学の研究者らは、結晶相の問題を解決するための PhAI と呼ばれる深層学習手法を開発しました。数百万の人工結晶構造とそれに対応する合成回折データを使用して訓練された深層学習ニューラル ネットワークは、正確な電子密度マップを生成できます。この研究では、この深層学習ベースの非経験的構造解法は、従来の非経験的計算法とは異なり、わずか 2 オングストロームの解像度で位相問題を解決できることが示されています。これは、原子解像度で利用可能なデータのわずか 10% ~ 20% に相当します。
 Google AI が IMO 数学オリンピック銀メダルを獲得、数理推論モデル AlphaProof が発売、強化学習が復活
Jul 26, 2024 pm 02:40 PM
Google AI が IMO 数学オリンピック銀メダルを獲得、数理推論モデル AlphaProof が発売、強化学習が復活
Jul 26, 2024 pm 02:40 PM
AI にとって、数学オリンピックはもはや問題ではありません。木曜日、Google DeepMind の人工知能は、AI を使用して今年の国際数学オリンピック IMO の本当の問題を解決するという偉業を達成し、金メダル獲得まであと一歩のところまで迫りました。先週終了したばかりの IMO コンテストでは、代数、組合せ論、幾何学、数論を含む 6 つの問題が出題されました。 Googleが提案したハイブリッドAIシステムは4問正解で28点を獲得し、銀メダルレベルに達した。今月初め、UCLA 終身教授のテレンス・タオ氏が、100 万ドルの賞金をかけて AI 数学オリンピック (AIMO Progress Award) を宣伝したばかりだったが、予想外なことに、AI の問題解決のレベルは 7 月以前にこのレベルまで向上していた。 IMO に関する質問を同時に行うのが最も難しいのは、最も歴史が長く、規模が最も大きく、最も否定的な IMO です。
 PRO | なぜ MoE に基づく大規模モデルがより注目に値するのでしょうか?
Aug 07, 2024 pm 07:08 PM
PRO | なぜ MoE に基づく大規模モデルがより注目に値するのでしょうか?
Aug 07, 2024 pm 07:08 PM
2023 年には、AI のほぼすべての分野が前例のない速度で進化しています。同時に、AI は身体化されたインテリジェンスや自動運転などの主要な分野の技術的限界を押し広げています。マルチモーダルの流れのもと、AI大型モデルの主流アーキテクチャとしてのTransformerの状況は揺るがされるだろうか? MoE (専門家混合) アーキテクチャに基づく大規模モデルの検討が業界の新しいトレンドになっているのはなぜですか?ラージ ビジョン モデル (LVM) は、一般的な視覚における新たなブレークスルーとなる可能性がありますか? ...過去 6 か月間にリリースされたこのサイトの 2023 PRO メンバー ニュースレターから、上記の分野の技術トレンドと業界の変化を詳細に分析し、新しい分野での目標を達成するのに役立つ 10 の特別な解釈を選択しました。準備してください。この解釈は 2023 年の Week50 からのものです
 新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
編集者 |ScienceAI 質問応答 (QA) データセットは、自然言語処理 (NLP) 研究を促進する上で重要な役割を果たします。高品質の QA データ セットは、モデルの微調整に使用できるだけでなく、大規模言語モデル (LLM) の機能、特に科学的知識を理解し推論する能力を効果的に評価することもできます。現在、医学、化学、生物学、その他の分野をカバーする多くの科学 QA データ セットがありますが、これらのデータ セットにはまだいくつかの欠点があります。まず、データ形式は比較的単純で、そのほとんどが多肢選択式の質問であり、評価は簡単ですが、モデルの回答選択範囲が制限され、科学的な質問に回答するモデルの能力を完全にテストすることはできません。対照的に、自由回答型の Q&A
 Transformer に基づく浙江大学の化学逆合成予測モデルは、Nature サブジャーナルで 60.8% に達しました。
Aug 06, 2024 pm 07:34 PM
Transformer に基づく浙江大学の化学逆合成予測モデルは、Nature サブジャーナルで 60.8% に達しました。
Aug 06, 2024 pm 07:34 PM
編集者 | KX 逆合成は創薬や有機合成において重要なタスクであり、そのプロセスを高速化するために AI の使用が増えています。既存の AI 手法はパフォーマンスが不十分で、多様性が限られています。実際には、化学反応は多くの場合、反応物と生成物の間にかなりの重複を伴う局所的な分子変化を引き起こします。これに触発されて、浙江大学のHou Tingjun氏のチームは、単一ステップの逆合成予測を分子列編集タスクとして再定義し、標的分子列を反復的に改良して前駆体化合物を生成することを提案した。そして、高品質かつ多様な予測を実現できる編集ベースの逆合成モデルEditRetroを提案する。広範な実験により、このモデルが標準ベンチマーク データ セット USPTO-50 K で優れたパフォーマンスを達成し、トップ 1 の精度が 60.8% であることが示されました。
 AIハードウェアがまたメンバー追加!携帯電話を置き換えるのではなく、NotePinは長生きできるでしょうか?
Sep 02, 2024 pm 01:40 PM
AIハードウェアがまたメンバー追加!携帯電話を置き換えるのではなく、NotePinは長生きできるでしょうか?
Sep 02, 2024 pm 01:40 PM
これまでのところ、AI ウェアラブル デバイス分野で特に優れた結果を達成した製品はありません。今年初めのMWC24で発表されたAIPinは、評価プロトタイプが出荷されると、発表当時に喧伝された「AI神話」が崩れ始め、わずか1年で大規模なリターンを獲得した。数か月; RabbitR1 も当初は比較的よく売れましたが、大量に出荷されたときは「Android ケース」と同様に否定的な評価を受けました。さて、別の企業がAIウェアラブルデバイス分野に参入しました。テクノロジーメディアのTheVergeは昨日、AIスタートアップのPlaudがNotePinという製品を発売したとのブログ投稿を公開した。まだ「絵を描いている」段階にあるAIFriendとは異なり、NotePinはすでに開始されています
