


編集者 | ScienceAI
Transformer などの高度なシーケンス モデルを使用することにより、シングルステップ逆合成予測問題は、生成物の SMILES 表現から反応物の SMILES 表現への変換タスクに変換され、広く使用され、顕著な結果をもたらす戦略となっています。
しかし、この方法では重要な点が無視されていることがよくあります。それは、反応物と生成物の間には、直接利用できる同一の部分構造が多数存在するということです。これらの下部構造の利用が不十分だと、モデル予測の効率と精度が制限されます。
2024年7月、上海交通大学人工知能研究所のJin Yaohui氏とXu Yanyan氏の研究チームは、論文「Ualign: 教師なしSMILESアライメントによるテンプレートフリー逆合成予測の限界を押し上げる」を、 「ケモインフォマティクスジャーナル」。
この研究において、著者は、化学反応予測の精度と効率を向上させることを目的として、教師なしSMILES配列アライメント技術を統合したシングルステップ逆合成予測プロセスを提案しました。実験結果は、逆合成経路の予測におけるこのモデルの有効性を実証し、このモデルが創薬の貴重なツールとなる可能性があることを示唆しています。
Graph to Sequenceのモデルアーキテクチャ
原子をノードとみなすと、化学結合をエッジとして扱うことで、分子構造を自然にグラフ構造に変換することができます。配列モデルと比較して、グラフ ニューラル ネットワークは分子内部のトポロジカル構造情報をより適切に捕捉できるため、より正確な分子の特性評価を実現できます。 さらに、他のグラフ構造と比較して、化学分子内の化学結合は豊富な化学特性情報を保持します。 これらの利点に基づいて、著者は、下流アプリケーションにより強力な分子表現機能を提供することを目的として、Transformer モデルのエンコーダー部分を置き換えるグラフ アテンション ネットワークに基づくバリアントを提案します。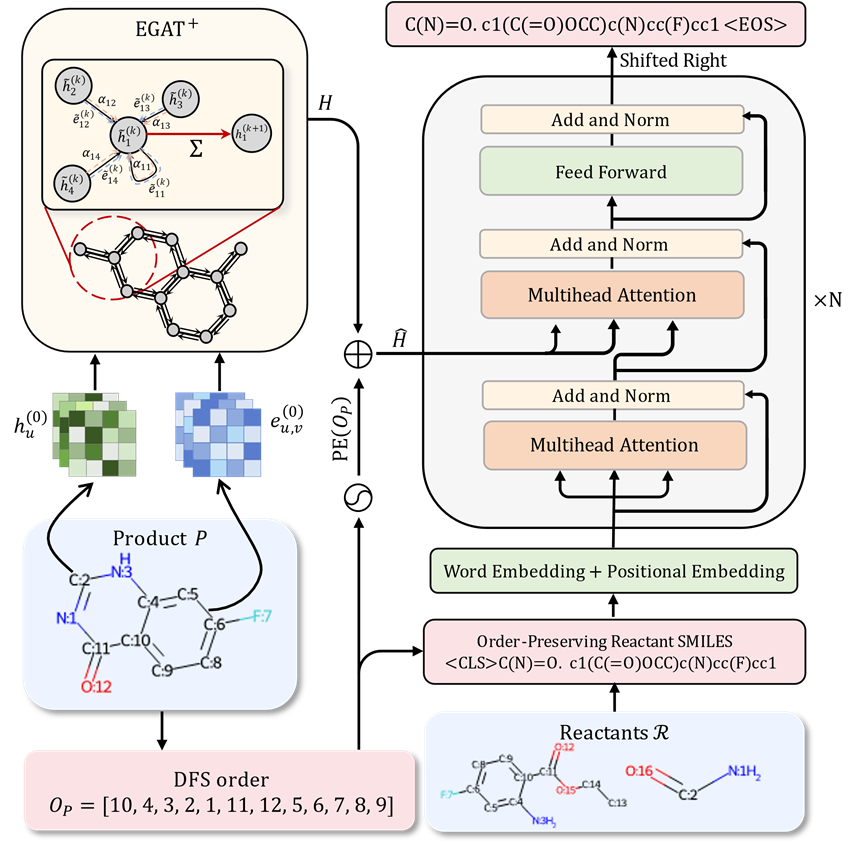
教師なしSMILESアライメントメカニズム
シングルステップ逆合成予測では、シーケンスモデリング手法を使用することは、通常、反応物の構造を最初から構築する必要があることを意味します。反応物と生成物の間で同一の部分構造を効率的に利用するために、既存の生成物に基づいて直接変更を加えることができません。このアプローチでは、生成される結果の精度がある程度制限されます。 シーケンスモデリングで一般的に使用される分子の SMILES 表現が実際に分子内の原子と化学結合を深さ優先探索の順序で並べていることを考慮すると、反応物 SMILES 表現に現れる各生成物原子の位置情報をモデルが反応中に変化しなかった部分構造を特定して再利用するのに役立ちます。これにより、モデルが反応物を予測する難しさが大幅に軽減され、予測の精度が向上します。 配列モデリングの観点から見ると、一般的に使用される分子 SMILES 特性評価では、基本的に深さ優先検索 (DFS) の順序に従って分子内の原子と化学結合が配置されます。反応物の SMILES 表現における生成物内の各原子の位置情報をモデルに提供できれば、モデルによる変更されていない部分構造の特定と再利用が大幅に容易になり、それによって反応物の予測の困難さが大幅に軽減され、予測精度が向上します。 。 ただし、この対応情報を直接提供すると、モデルのトレーニング中に情報漏洩のリスクが生じる可能性があります。この問題を回避するために、研究者らは、ラベル情報を漏らすことなく、反応物の分子構造を理解して予測するモデルの能力を最適化する革新的な戦略を提案しました。 SMILES 配列の特徴付けが分子グラフの深さ優先検索から得られ、反応物と生成物の間のほとんどの部分構造が高度に一致していることを考慮すると、どの生成物の特定の DFS 配列についても、対応するものが存在する必要があります。反応物の図では、反応物と生成物の対応する原子がほぼ同じ順序で表示されます。 この戦略に基づいて、研究者らは生成物の分子構造をモデル入力に組み込んだだけでなく、反応物分子の DFS 次数も入力の一部として導入しました。 さらに、上記の戦略に従って、研究者らは、特定の反応物の DFS シーケンスと高度に一致する生成物分子の DFS シーケンスを生成し、このシーケンスを使用して、モデルトレーニングのターゲットとして反応物の SMILES 表現を生成しました。 。 この設計により、反応物と生成物間の同様の部分構造をモデルの入力と出力でほぼ同じ順序で配置できるため、モデルが反応物と生成物間の同じ構造的対応を学習するプロセスが簡素化され、グループの識別に役立ちます反応中に変化するもの。反応物の構造を最初から構築する場合でも、この方法では生成物の構造情報を効果的に再利用でき、予測の精度が大幅に向上します。
特に重要なのは、生成物の DFS 順序はその分子構造情報のみに基づいており、アノテーションとしての反応物に関する情報には依存しないため、この方法はモデルのトレーニング プロセス中のラベルの漏れの問題を効果的に回避できることです。
同時に、この教師なしSMILESアライメント方法は、トレーニングプロセス中に追加の監視信号を導入する必要がないため、マルチタスク学習における複雑なデータアノテーションと最適化の問題を回避し、分子分野に新しい方法を提供します。逆合成予測と効率的な研究方法。
実験結果の表示
この研究では、著者は、広く使用されている USPTO-50K データセットと、より大量の USPTO-50K データセットをカバーする複数の分子逆合成予測データセットの体系的な評価を実施しました。 MIT と USPTO-FULL のデータ。
モデルのパフォーマンスを評価する場合、top-k の精度が主な評価指標として使用されます。 USPTO-50K データセットに関して、著者はモデルによって生成された SMILES シーケンスの合法性を検査しただけでなく、大規模な事前トレーニングを通じてモデルによって出力された合成スキームの実際的な実現可能性のループバック検証も実施しました。順反応予測モデル。
表 1: USPTO-50K 逆合成予測の上位 k 精度
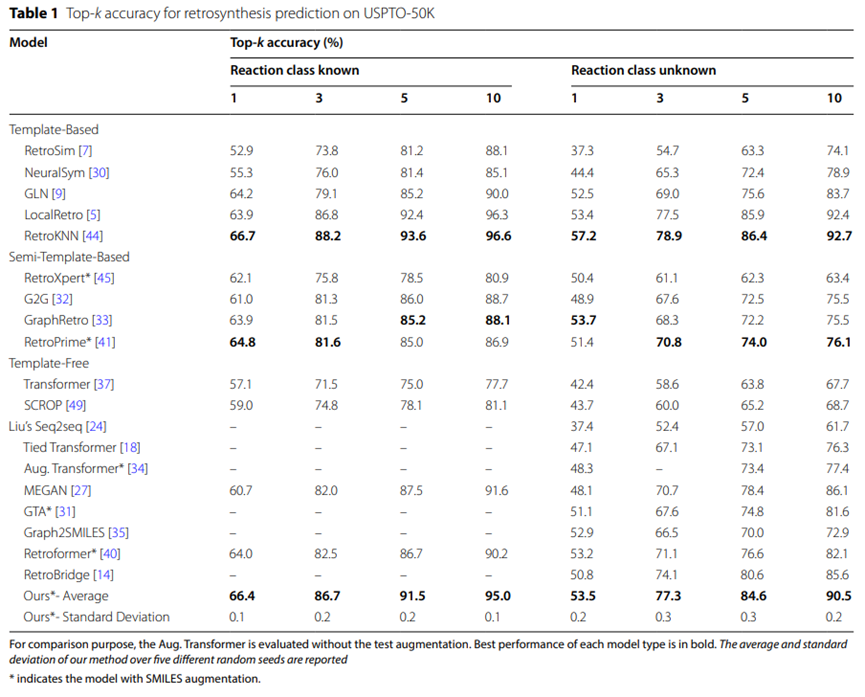
USPTO-50K データセットの実験結果を表 1 にまとめます。これは、特定の反応タイプの場合に USPTO で UAlign モデルのパフォーマンスが向上することを示しています。 -50K データセットのトップ 5 の精度は 84.6% と高く、他のテンプレートなしのベースライン モデルよりも大幅に優れています。
表 2: USPTO-MIT 逆合成予測の Top-k 精度
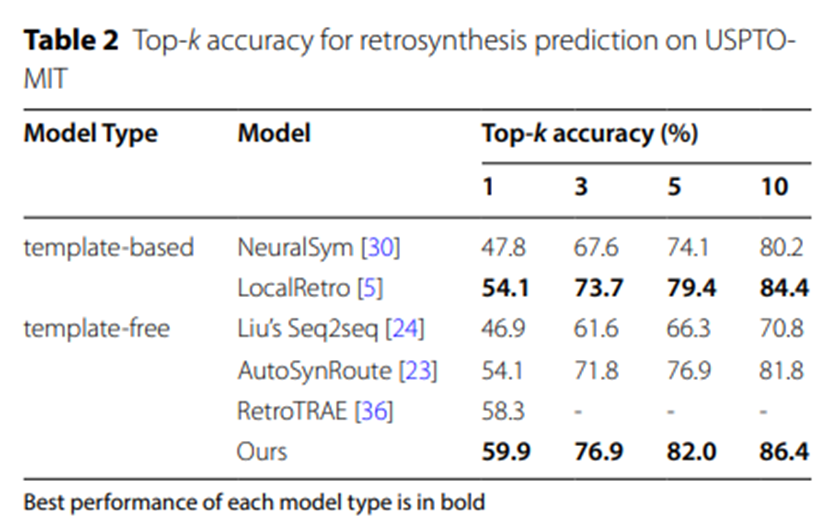
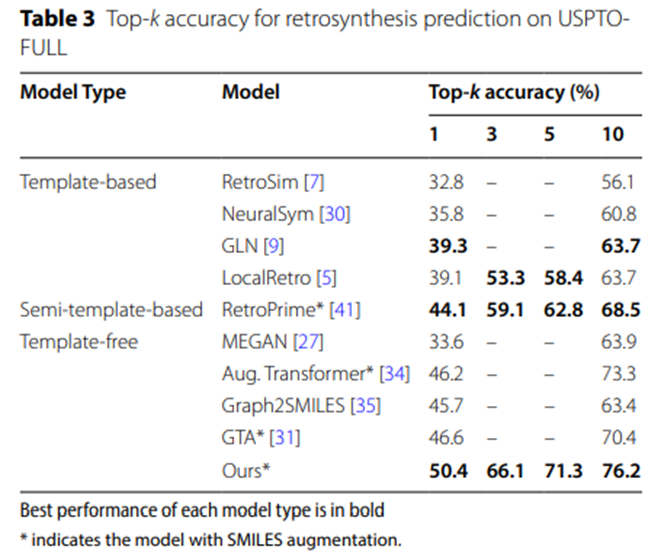
表 2 と表 3 の実験データは、より大規模なデータセット USPTO-MIT および USPTO-FULL、UAlign モデルでの結果をさらに裏付けています。他のさまざまなベースラインモデルを大幅に上回る利点があります。
表 3: USPTO-FULL での逆合成予測の Top-k 精度
さらに、表 4 の実験結果は、他の SMILES ベースの逆合成予測モデルと比較して、UAlign モデルによって生成された反応物質がSMILESシーケンスの方が正当性が高い。
表 4: USPTO-50K での未知の反応クラスの逆合成予測に対する Top-k SMILES の有効性
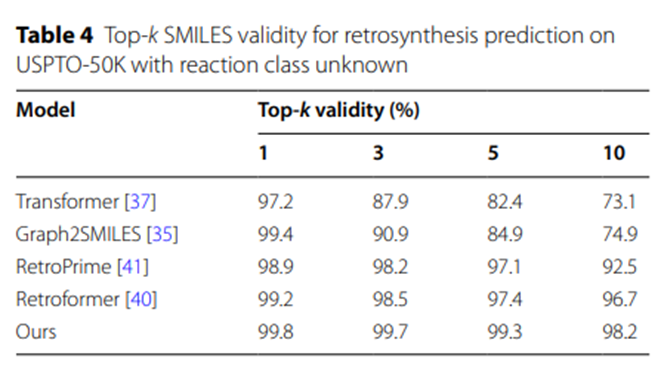
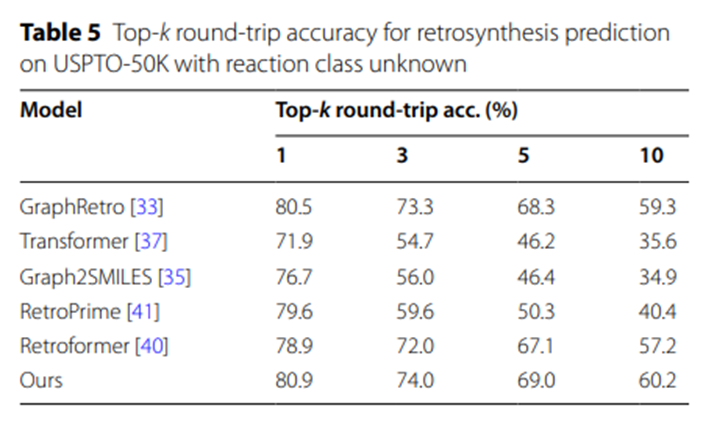
表 5 の実験データは、合理的で実現可能な合成ソリューションを生成する UAlign モデルの能力をさらに強調しています。その理由は、UAlign によって提案された合成スキームの比較的高い割合が正反応予測モデルの検証に合格できるためです。つまり、これらのスキームは、対応する化学反応後に所定の目的生成物に効率的に変換できるためです。
表 5: USPTO-50K における未知の反応カテゴリーでの逆合成予測のトップ k ラウンドトリップ精度
これらの実験結果は、分子逆合成予測タスクにおける UAlign モデルの効率と精度を検証するだけでなく、また、大規模なデータセットを処理する際の優れたパフォーマンスと、高品質の合成ソリューションを生成する際の大きな利点も強調されています。
実際の生産における UAlign モデルの応用可能性を検証するために、著者は、モデルの複数回の反復を通じて、過去 2 年間に米国食品医薬品局 (FDA) によって承認された新薬を合成ターゲットとして選択しました。合成ルートが無事に得られました。これら 2 つの薬剤の合成経路に関するモデルの予測は、文献に記録されている経路と非常に一致しています。
さらに、3番目の薬剤については、モデルによって予測された合成経路も化学分野の専門家によって実現可能であることが認められています。これらの合成経路は、さまざまな反応タイプをカバーするだけでなく、環状化合物の合成や複数の反応中心が関与する単一ステップの逆合成予測などの複雑な状況も含みます。
上記の実験結果は、UAlign モデルが多様な反応タイプに対応できるだけでなく、実際の生産においても高い応用価値があることを十分に証明しています。これは、UAlign モデルが分子逆合成予測の分野で強力な実用性と柔軟性を備えており、薬物合成に効果的なソリューションを提供できることを示しています。

将来展望
その優れたパフォーマンスと柔軟性により、UAlign モデルはマルチステップ逆合成システムを構築する基礎として十分に機能します。さまざまな検索アルゴリズムや多目的最適化テクノロジと組み合わせて、効率的でインテリジェントな逆合成パス プランニング システムを形成できます。
さらに、著者は、UAlign アルゴリズムと高度なハードウェア機器の統合を積極的に検討し、創薬および合成プロセスの自動化を促進する自動化された無人研究室を作成し、化学研究および医薬品開発の分野に革命的な変化をもたらします。変化。
以上が化学逆合成 SOTA!上海交通大学のチームが効率的な逆合成予測を実現するSMILESアライメント技術を提案の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



