大規模なモデルの反復速度がますます高速になるにつれて、トレーニング クラスターの規模もますます大きくなり、高頻度のソフトウェアとハードウェアの障害がトレーニング効率のさらなる向上を妨げる問題点となっています。トレーニングプロセス中のステータスを管理するのは、トレーニングの失敗を克服し、トレーニングの進行を確実にし、トレーニングの効率を向上させるための鍵となります。
最近、ByteDance Beanbao モデル チームと香港大学が共同で ByteCheckpoint を提案しました。これは、PyTorch ネイティブの大規模モデル チェックポイント システムであり、複数のトレーニング フレームワークと互換性があり、チェックポイントの効率的な読み取りと書き込みと自動再セグメント化をサポートしており、既存の方法と比較してパフォーマンスが大幅に向上し、使いやすさが向上します。この記事では、大規模モデルのトレーニング効率を向上させるために Checkpoint が直面する課題を紹介し、ByteCheckpoint のソリューションのアイデア、システム設計、I/O パフォーマンス最適化テクノロジー、ストレージ パフォーマンスと読み取りパフォーマンスのテストの実験結果を要約します。
メタ担当者は最近、16384 個の H100 80GB トレーニング クラスターでの Llama3 405B トレーニングの失敗率を明らかにしました。わずか 54 日間で 419 回の中断が発生し、平均 3 時間ごとにクラッシュが発生し、多くの実践者の注目を集めました。
業界でよく言われるように、大規模なトレーニング システムで唯一確実なのは、ソフトウェアとハードウェアの障害です。トレーニングの規模とモデルのサイズが増加するにつれて、ソフトウェアとハードウェアの障害を克服し、トレーニング効率を向上させることが、大規模なモデルの反復に影響を与える重要な要素となっています。
チェックポイントはトレーニング効率を向上させる鍵となっています。 Llama トレーニング レポートの中で、技術チームは、高い失敗率に対処するには、トレーニング プロセス中に頻繁にチェックポイントを実行して、トレーニング中のモデル、オプティマイザー、データ リーダーのステータスを保存し、データの損失を減らす必要があると述べました。トレーニングの進捗状況。
ByteDance Beanbao 大規模モデル チームと香港大学は最近、複数のトレーニング フレームワークと互換性のある PyTorch ネイティブである ByteCheckpoint と、チェックポイントの効率的な読み取りと書き込みと自動再実行をサポートする大規模モデル チェックポイント システムの結果を発表しました。セグメンテーション。
ベースライン方法と比較して、ByteCheckpoint はチェックポイント保存で最大 529.22 倍、ロードで最大 3.51 倍パフォーマンスが向上します。 最小限のユーザー インターフェイスとチェックポイントの自動再セグメント化機能により、ユーザーの獲得と使用コストが大幅に削減され、システムの使いやすさが向上します。

- ByteCheckpoint: LLM 開発のための統合チェックポイント システム
- 紙のリンク: https://team.doubao.com/zh/publication/bytecheckpoint-a-unified-checkpointing-system-for-llm-development?view_from =research
大規模モデルのトレーニングにおける Checkpoint テクノロジーの技術的課題 現在の Checkpoint 関連テクノロジーは、大規模モデルのトレーニング効率をサポートする上で、合計 4 つの課題に直面しています。 既存のシステム設計には欠陥があり、トレーニングの追加 I/O オーバーヘッドが大幅に増加します
- 産業レベルの大規模言語モデル (LLM) をトレーニングするプロセスでは、トレーニング ステータスがチェックポイント テクノロジ (チェックポイント機能) を保存して永続化します。通常、チェックポイントは 5 つの部分 (モデル、オプティマイザー、データ リーダー、乱数、およびユーザー定義の構成) で構成されます。このプロセスは多くの場合、トレーニングに数分レベルの障害をもたらし、トレーニングの効率に重大な影響を与えます。
リモート永続ストレージ システムを使用する大規模なトレーニング シナリオでは、既存のチェックポイント システムは、チェックポイント保存プロセス中に GPU から CPU へのメモリ コピー (D2H コピー)、シリアル化、ローカル保存、およびストレージへのアップロードを完全に利用しません。 . システムの各段階の実行の独立性。
さらに、チェックポイント アクセス タスクを共有するさまざまなトレーニング プロセスの並列処理の可能性は十分に検討されていません。これらのシステム設計の欠陥により、チェックポイントのトレーニングによって追加の I/O オーバーヘッドが増加します。 チェックポイントは再セグメント化が難しく、手動セグメンテーションスクリプトの開発とメンテナンスのオーバーヘッドが高すぎます
- LLMのさまざまなトレーニング段階(SFTまたはSFTへの事前トレーニング) RLHF) と異なるタスク (トレーニング タスク間でチェックポイントを移行するとき (自動評価のためにさまざまなステージからチェックポイントを取得する) から)、通常は、新しい並列処理に適応するために、永続ストレージ システムに保存されたチェックポイント (チェックポイント リシャーディング) を再セグメント化する必要があります。ダウンストリーム タスクの構成と利用可能な GPU リソースの割り当て。
既存のチェックポイント システム [1、2、3、4] はすべて、並列処理構成と GPU リソースがストレージとロード中に変更されないことを前提としており、チェックポイントの再セグメント化の必要性を処理できません。現在、業界で一般的な解決策は、チェックポイントのマージまたは再分割スクリプトをさまざまなモデルにカスタマイズすることです。この方法では、開発とメンテナンスのオーバーヘッドが大きくなり、スケーラビリティが低くなります。 さまざまなトレーニング フレームワークの Checkpoint モジュールが断片化されているため、Checkpoint の統合管理とパフォーマンスの最適化に課題が生じています
- 業界のトレーニング プラットフォームでは、エンジニアや科学者がよくタスクの特性に基づいて連携し、トレーニングに適切なフレームワーク (Megatron-LM [5]、FSDP [6]、DeepSpeed [7]、veScale [8、9]) を選択し、チェックポイントをストレージ システムに保存します。ただし、これらのさまざまなトレーニング フレームワークには、独自の独立したチェックポイント形式と読み取りおよび書き込みモジュールがあります。トレーニング フレームワークごとにチェックポイント モジュールの設計が異なるため、統合されたチェックポイント管理と基盤となるシステムのパフォーマンスの最適化に課題が生じます。
分散トレーニングシステムのユーザーは複数の問題に直面しています
- トレーニングシステムのユーザー(AI研究者やエンジニア)の観点から、ユーザーが分散トレーニングシステムを使用する際のチェックポイントの方向性は、次の 3 つの問題に悩まされることがよくあります:
1) チェックポイントを効率的に保存し、トレーニングの効率に影響を与えずにチェックポイントを保存する方法。 2) チェックポイントを再セグメント化し、1 つの並列度で保存されたチェックポイントの新しい並列度に従って正しく読み取る方法。 3) トレーニング済みの製品をクラウド ストレージ システム (HDFS、S3 など) にアップロードし、複数のストレージ システムを手動で管理する方法。これはユーザーが学習して使用するのにコストがかかります。
上記の問題に対応して、ByteDance Beanbao モデル チームと香港大学の Wu Chuan 教授の研究室が共同で ByteCheckpoint を立ち上げました。
ByteCheckpoint は、複数のトレーニング フレームワークと統合され、複数のストレージ バックエンドをサポートし、チェックポイントを自動的に再セグメント化する機能を備えた高性能分散チェックポイント システムです。 ByteCheckpoint は、シンプルで使いやすいユーザー インターフェイスを提供し、ストレージとチェックポイントの読み取りパフォーマンスを向上させるための多数の I/O パフォーマンス最適化テクノロジを実装し、さまざまな並列構成を持つタスクでのチェックポイントの柔軟な移行をサポートします。 システム設計
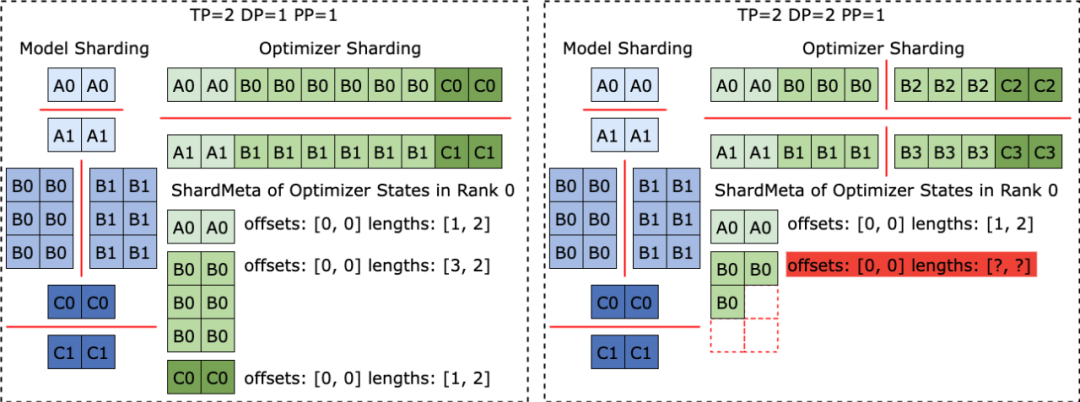
ByteCheckpointは、チェックポイント管理とトレーニングフレームワークと並列処理の分離を実現するために、メタデータ/テンソルデータ分離ストレージアーキテクチャを採用しています。さまざまなトレーニング フレームワークおよびオプティマイザーのモデルの Tensor スライス (Tensor Shard) はストレージ ファイルに保存され、メタ情報 (TensorMeta、ShardMeta、ByteMeta) はグローバルに一意のメタデータ ファイルに保存されます。
以下の図に示すように、チェックポイントを読み取るために異なる並列処理構成を使用する場合、各トレーニング プロセスは、プロセスに必要なテンソルの格納場所を取得するために、現在の並列処理に従ってクエリ メタ情報を設定するだけで済みます。次に、位置に従って直接読み取り、チェックポイントの自動再分割を実現します。
不規則なテンソルセグメンテーションに対する賢い解決策 さまざまなトレーニングフレームワークが実行されている場合、多くの場合、モデルまたはオプティマイザー内のテンソルの形状が1次元に平坦化され、それによってセットの通信パフォーマンスが向上します。この平坦化操作により、チェックポイント ストレージに不規則なテンソル シャーディング (不規則なテンソル シャーディング) という課題が生じます。 以下の図に示すように、Megatron-LM (NVIDIA が開発した分散大規模モデル トレーニング フレームワーク) と veScale (ByteDance が開発した PyTorch ネイティブの分散大規模モデル トレーニング フレームワーク) では、モデル パラメーターはオプティマイザーの状態に対応します。 1 つの次元にフラット化され、マージされてから、データの並列処理に従って分割されます。その結果、テンソルは異なるプロセスに不規則に分割され、テンソル スライスのメタ情報はオフセットと長さのタプルを使用して表現できず、保存と読み取りが困難になります。
不規則なテンソルセグメンテーションの問題は、FSDP フレームワークにも存在します。 不規則にカットされたテンソル スライスを排除するために、FSDP フレームワークは、チェックポイントを保存する前に、すべてのプロセスで 1 次元テンソル スライスに対してオールギャザー セット通信と D2H コピー操作を実行して、完全に不規則に分割されたテンソルを取得します。このソリューションは、膨大な通信と頻繁な GPU-CPU 同期オーバーヘッドをもたらし、チェックポイント ストレージのパフォーマンスに重大な影響を与えます。 この問題に対処するために、ByteCheckpoint は非同期 Tensor Merging テクノロジーを提案しました。 ByteCheckpoint は、まず異なるプロセスで不規則に分割されたテンソルを見つけ出し、次に非同期 P2P 通信を使用してこれらの不規則なテンソルを異なるプロセスに分散してマージします。これらの不規則なテンソルに対するすべての P2P 通信の待機 (Wait) およびテンソル D2H コピー操作は、シリアル化フェーズに入ろうとするまで延期されます。これにより、頻繁な同期オーバーヘッドが排除され、他のチェックポイント ストレージ プロセスとの通信が重複して増加します。 次の図は、ByteCheckpoint のシステム アーキテクチャを示しています: API レイヤーは、さまざまなトレーニング フレームワークに対して、シンプルで使いやすく、統合された読み取りと書き込みを提供します (保存) および読み取り (ロード) インターフェイス。 プランナー層は、アクセス オブジェクトに基づいてさまざまなトレーニング プロセスのアクセス プランを生成し、それらを実行層に渡して実際の I/O タスクを実行します。 実行層は、高性能チェックポイント アクセスのためのさまざまな I/O 最適化テクノロジを使用して、I/O タスクを実行し、ストレージ層と対話します。 ストレージ層は、さまざまなストレージ バックエンドを管理し、I/O タスク中にさまざまなストレージ バックエンドに従って対応する最適化を実行します。 階層化された設計により、システムの拡張性が強化され、将来的にはより多くのトレーニング フレームワークとストレージ バックエンドがサポートされます。
ByteCheckpointのAPIの使用例は次のとおりです:
ByteCheckpoint menyediakan API minimalis, mengurangkan kos pengguna untuk bermula. Apabila menyimpan dan membaca Pusat Pemeriksaan, pengguna hanya perlu memanggil fungsi storan dan pemuatan, menghantar kandungan untuk disimpan dan dibaca, laluan sistem fail dan pelbagai pilihan pengoptimuman prestasi. Teknologi pengoptimuman prestasi I/O rajah di bawah, ByteCheckpoint Mereka bentuk saluran paip storan tak segerak sepenuhnya ( Save Pipeline), membahagikan pelbagai peringkat storan Checkpoint (pemindahan tensor P2P, replikasi D2H, pensirilan, menyimpan sistem fail setempat dan memuat naik) untuk mencapai pelaksanaan saluran paip yang cekap. Elakkan peruntukan memori berulang
Dalam proses penyalinan D2H, ByteCheckpoint menggunakan kolam memori yang disematkan (Kolam Memori Berpin), yang mengurangkan overhed masa peruntukan memori berulang. Selain itu, untuk mengurangkan overhed masa tambahan yang disebabkan oleh menunggu serentak untuk kitar semula kumpulan memori tetap dalam senario storan frekuensi tinggi, ByteCheckpoint menambah mekanisme penimbalan Ping-Pong berdasarkan kumpulan memori tetap. Dua kumpulan memori bebas secara bergilir-gilir memainkan peranan sebagai penimbal baca dan tulis, berinteraksi dengan pekerja GPU dan I/O yang melakukan operasi I/O seterusnya, meningkatkan lagi kecekapan storan.
Pengimbangan beban
Dalam latihan selari data (Data-Parallel atau DP), model adalah berlebihan di antara kumpulan proses selari data yang berbeza (Kumpulan DP.ByteCheckpoint yang mengagihkan algoritma merah pengimbangan beban Sekata). model tensor kepada kumpulan proses yang berbeza untuk penyimpanan, meningkatkan kecekapan penyimpanan Checkpoint dengan berkesan.
Pengoptimuman baca checkpoint
Pemuatan berlebihan sifar
seperti yang ditunjukkan pada proses yang baru, seperti yang ditunjukkan dalam gambar perlu asal Baca sebahagian daripada kepingan tensor. ByteCheckpoint menggunakan teknologi bacaan separa fail atas permintaan (Bacaan Fail Separa) untuk terus membaca serpihan fail yang diperlukan dari storan jauh untuk mengelakkan memuat turun dan membaca data yang tidak diperlukan.
Dalam latihan selari data (Data-Parallel atau DP), model adalah berlebihan antara kumpulan proses selari data yang berbeza (Kumpulan DP), dan kumpulan proses yang berbeza akan berulang kali membaca kepingan tensor yang sama. Dalam senario latihan berskala besar, kumpulan proses yang berbeza menghantar sejumlah besar permintaan kepada sistem storan berterusan jauh (seperti HDFS) pada masa yang sama, yang akan memberi tekanan besar pada sistem storan.
Untuk menghapuskan pembacaan data berulang, mengurangkan permintaan yang dihantar ke HDFS melalui proses latihan, dan mengoptimumkan prestasi pemuatan, ByteCheckpoint mengagihkan tugas membaca kepingan tensor yang sama kepada proses yang berbeza dan membaca fail jauh semasa mengambil , lebar jalur terbiar antara GPU digunakan untuk penghantaran kepingan tensor. Konfigurasi Experimental Konfigurasi Konfigurasi
Pasukan menggunakan model Densegpt dan Sparsegpt (dilaksanakan berdasarkan struktur GPT-3 [10]), dengan jumlah parameter model yang berbeza dan berbeza rangka kerja latihan Ketepatan capaian Checkpoint, prestasi penyimpanan dan prestasi bacaan ByteCheckpoint dinilai dalam tugas latihan dengan saiz yang berbeza. Untuk butiran lanjut tentang konfigurasi eksperimen dan ujian ketepatan, sila rujuk kertas lengkap.
Dalam ujian prestasi storan, pasukan membandingkan saiz model dan rangka kerja latihan yang berbeza semasa proses latihan, kaedah Checkpoint, Bytecheckpoint dan Baseline setiap 50 atau 100 langkah masa menyekat (Gerai Checkpoint) disebabkan oleh latihan. Terima kasih kepada pengoptimuman prestasi tulis yang mendalam, ByteCheckpoint telah mencapai prestasi tinggi dalam pelbagai senario percubaan Dalam tugas latihan 576-kad SparseGPT 110B - Megatron-LM, ia telah mencapai prestasi 10% lebih tinggi daripada garis dasar. kaedah penyimpanan. Peningkatan prestasi ialah 66.65~74.55 kali, malah ia boleh mencapai peningkatan prestasi sebanyak 529.22 kali dalam tugas latihan DenseGPT 10B-FSDP 256 kad.
Dalam ujian prestasi baca, pasukan membandingkan masa pemuatan kaedah yang berbeza untuk membaca pusat pemeriksaan berdasarkan keselarian tugas hiliran. ByteCheckpoint mencapai peningkatan prestasi 1.55 hingga 3.37 kali berbanding kaedah garis dasar. Pasukan mendapati bahawa peningkatan prestasi ByteCheckpoint adalah lebih ketara berbanding kaedah garis dasar Megatron-LM. Ini kerana Megatron-LM perlu menjalankan skrip luar talian untuk memecah semula pusat pemeriksaan yang diedarkan sebelum membaca pusat pemeriksaan kepada konfigurasi selari baharu. Sebaliknya, ByteCheckpoint boleh terus melakukan pembahagian semula pusat pemeriksaan automatik tanpa menjalankan skrip luar talian dan melengkapkan bacaan dengan cekap.
Akhir sekali, mengenai perancangan masa depan ByteCheckpoint, pasukan berharap untuk bermula dari dua aspek: Pertama, mencapai matlamat jangka panjang untuk menyokong pemeriksaan yang cekap untuk tugas latihan kelompok GPU berskala ultra besar. Kedua, merealisasikan pengurusan pusat pemeriksaan keseluruhan kitaran hayat latihan model besar, menyokong pusat pemeriksaan dalam semua senario, daripada pra-latihan (Pra-Latihan), kepada penalaan halus terselia (SFT), kepada pembelajaran pengukuhan (RLHF). ) dan penilaian (Penilaian) dan senario lain. Pasukan Model Besar ByteDance Beanbao telah ditubuhkan pada 2023. Ia komited untuk membangunkan teknologi model besar AI yang paling maju dalam industri dan menjadi pasukan penyelidikan bertaraf dunia pembangunan teknologi dan masyarakat. Pada masa ini, pasukan terus menarik bakat cemerlang untuk menyertainya yang tegar, terbuka dan penuh semangat inovatif adalah kata kunci suasana pasukan untuk terus belajar dan berkembang, dan tidak takut dengan Cabaran dan mengejar kecemerlangan. Berharap dapat bekerjasama dengan bakat teknikal dengan semangat inovatif dan rasa tanggungjawab untuk menggalakkan peningkatan kecekapan latihan model besar dan mencapai lebih banyak kemajuan dan hasil. Rujukan Teknologi Fail dan Penyimpanan (FAST 21) 2021.[2] Eisenman, Assaf, et al mengenai Reka Bentuk dan Pelaksanaan Sistem Rangkaian (NSDI 22).[3] Wang, Zhuang, et al mengenai Prinsip Sistem Operasi 2023.[4] Gupta, Tanmaey, et al Sistem. 2024.[5] Shoeybi, Mohammad, et al. "Megatron-lm: Melatih model bahasa berbilion-bilion menggunakan model pracetak arXiv:1909.08053 (2019). [6] Zhao, Yanli, et al. "Pytorch fsdp: pengalaman menskalakan data berpecah sepenuhnya selari." "Deepspeed: Pengoptimuman sistem membolehkan melatih model pembelajaran mendalam dengan lebih 100 bilion parameter." "{MegaScale}: Menskalakan latihan model bahasa besar kepada lebih daripada 10,000 {GPU}." Rangka Kerja Latihan https://github.com/volcengine/veScale[10] Brown, Tom, et al. : 1877-1901.以上がLlama3 のトレーニングが 3 時間ごとにクラッシュしますか?ビッグビーンバッグモデルと HKU チームがサクサクの Wanka トレーニングを改善の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。




























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



