

コンピューター グラフィックスに焦点を当てた世界トップの学術会議である SIGGRAPH が、新たなトレンドを生み出しています。
先週開催されたSIGGRAPH 2024カンファレンスにおいて、最優秀論文およびその他の賞のうち、上海科技大学MARS研究室のチームが最優秀論文の名誉ノミネートを2つ同時に受賞し、その研究成果は急速に工業化に向けて進んでいます。
著者は生成モデルの手法を使用して、想像力を複雑な 3D モデルに直接変換する新しい方法を切り開きます。文 最優秀論文にノミネートされている Clay と Dresscode は、3D 生成と 3D 衣服生成です。

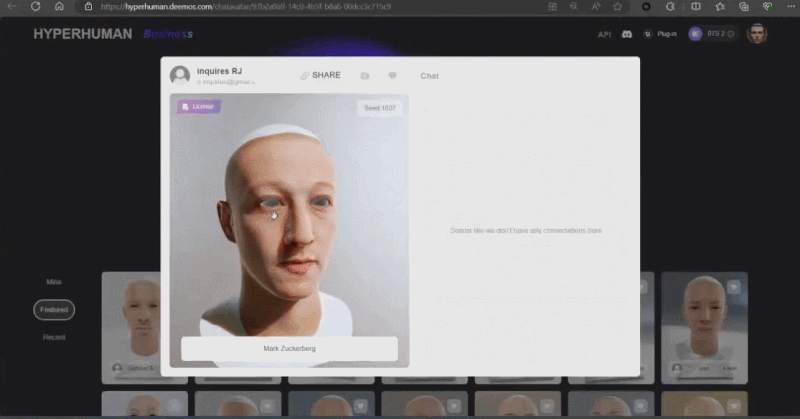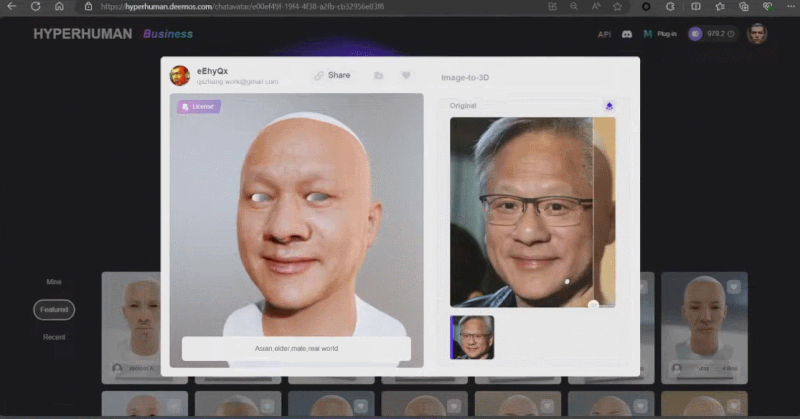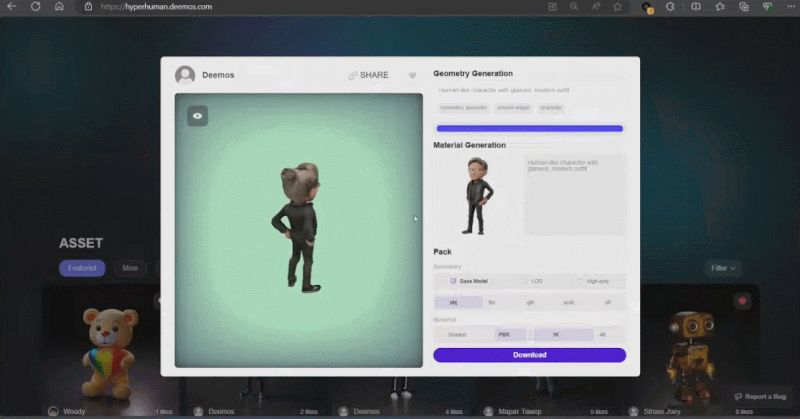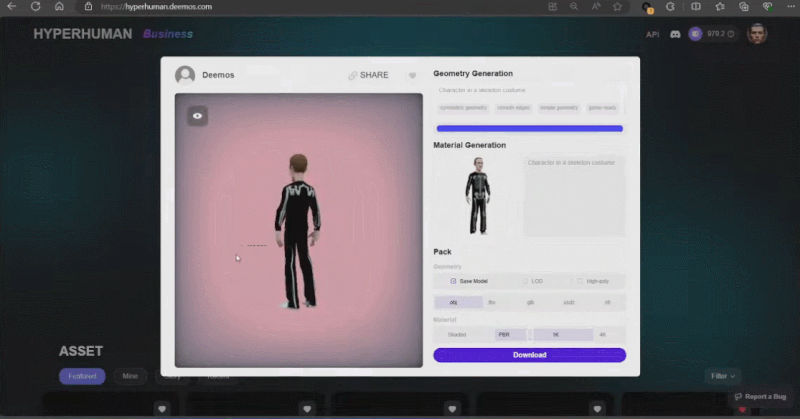
この論文の著者で大学院 2 年生でスタートアップ企業 Yingmo Technology の CTO である Zhang Qixuan 氏は、CLAY に基づく 3D 生成ソリューションを初めてデモンストレーションしました。昨年、Shadow Eye チームは、シンプルなテキスト プロンプト (プロンプト) を使用して、ザッカーバーグとジェンスン ファンのリアルな 3D モデルを構築し、SIGGRAPH リアルタイム ライブに参加した最初の中国チームとなりました。今年、同社の 3D 生成ソリューションは、単一の画像を入力として使用して、シャオ ザとラオ ファンの漫画画像をさまざまなスタイルで生成します。
これらの生成されたコンテンツの背後には、有名な彫刻家ロダンに敬意を表した新世代 3D AI エンジン Rodin があります。サイトに表示される 3D コンテンツは、ユーザーがアップロードした 1 つの画像から直接生成されます。Rodin は、アーティストによるさらなる修正と使用を容易にするために、PBR テクスチャと四角形サーフェスをさらに生成できます。
 3D ControlNet を使用すると、Rodin は AI が生成した形状を制御できます。単なるガイドとして提供されているため、単純な幾何学的要素をボクセルに変換し、参照画像のセマンティック情報に基づいて必要な 3D アセットに変換できます。
3D ControlNet を使用すると、Rodin は AI が生成した形状を制御できます。単なるガイドとして提供されているため、単純な幾何学的要素をボクセルに変換し、参照画像のセマンティック情報に基づいて必要な 3D アセットに変換できます。
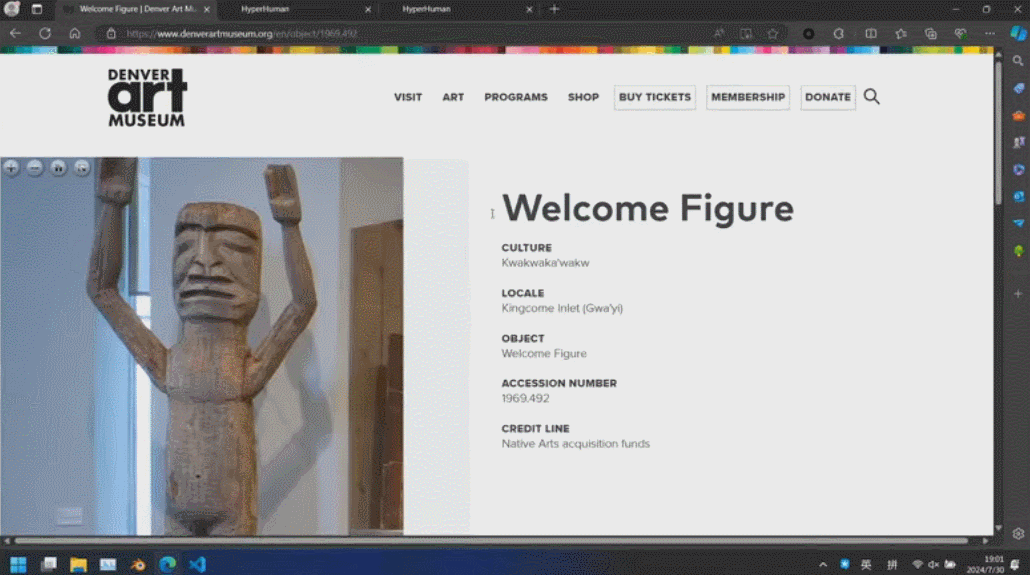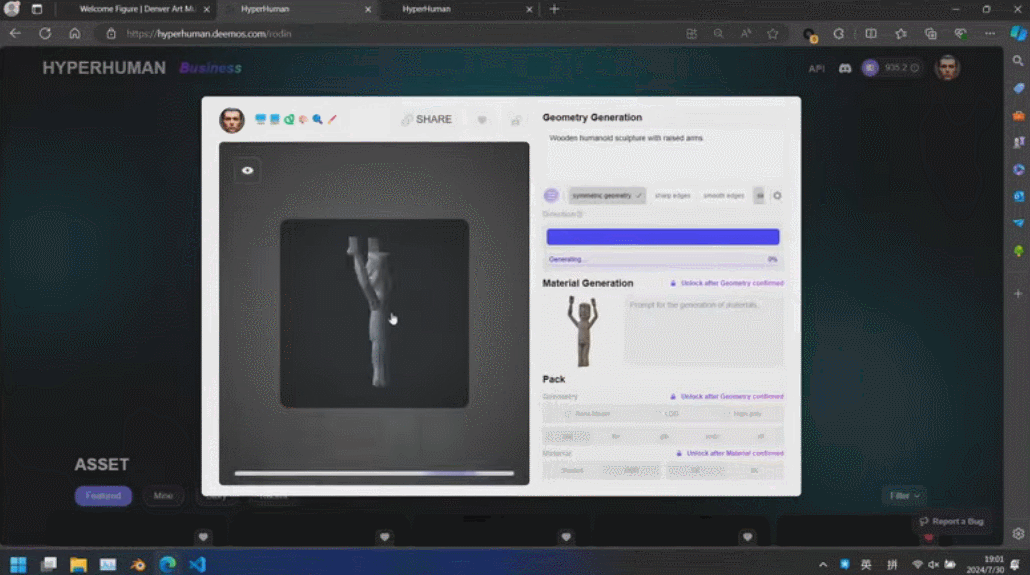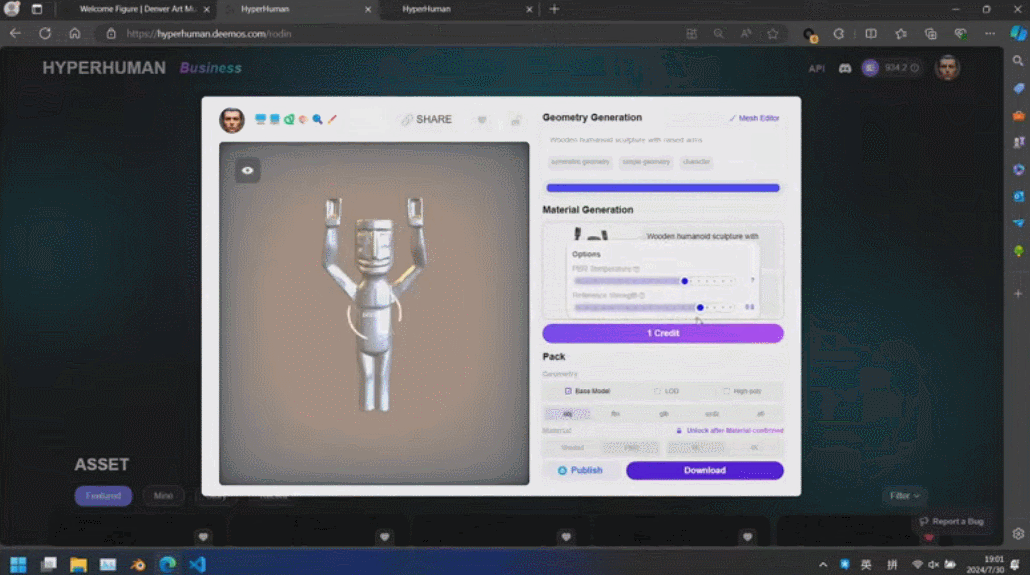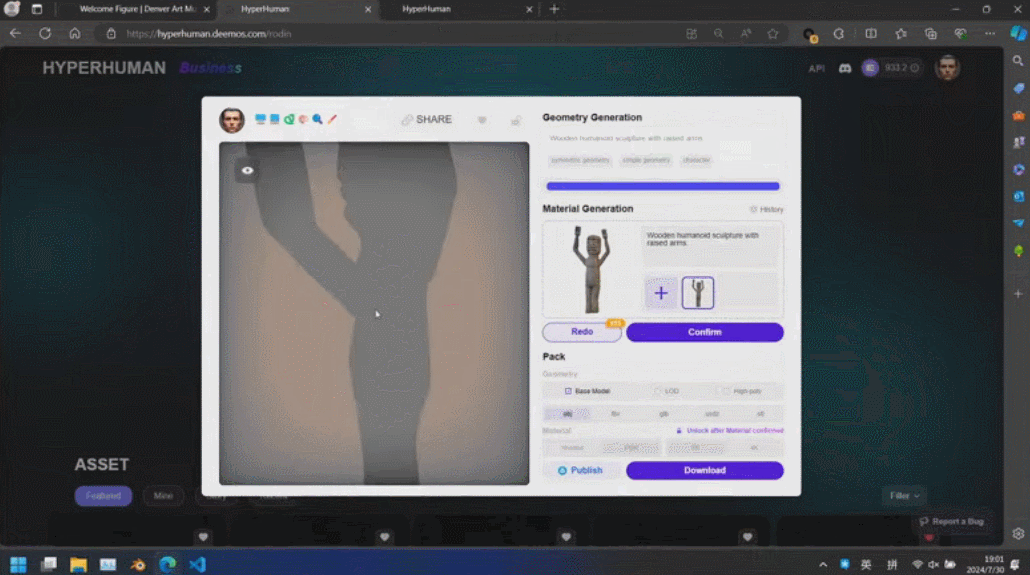 Rodin は、簡単な落書きなど、直接の手描きの絵もサポートしています。数枚の写真を使用して 3D キャラクターが生成され、子供の落書きが背景として木を生成しました。開発者は現場でリアルタイムに操作し、1 分で完全な 3D モデリング シーンを構築しました。司会者が真ん中にいる小さな怪物は誰なのかと尋ねると、張秋軒さんはユーモアたっぷりに「これはAIです」と答えた。
Rodin は、簡単な落書きなど、直接の手描きの絵もサポートしています。数枚の写真を使用して 3D キャラクターが生成され、子供の落書きが背景として木を生成しました。開発者は現場でリアルタイムに操作し、1 分で完全な 3D モデリング シーンを構築しました。司会者が真ん中にいる小さな怪物は誰なのかと尋ねると、張秋軒さんはユーモアたっぷりに「これはAIです」と答えた。
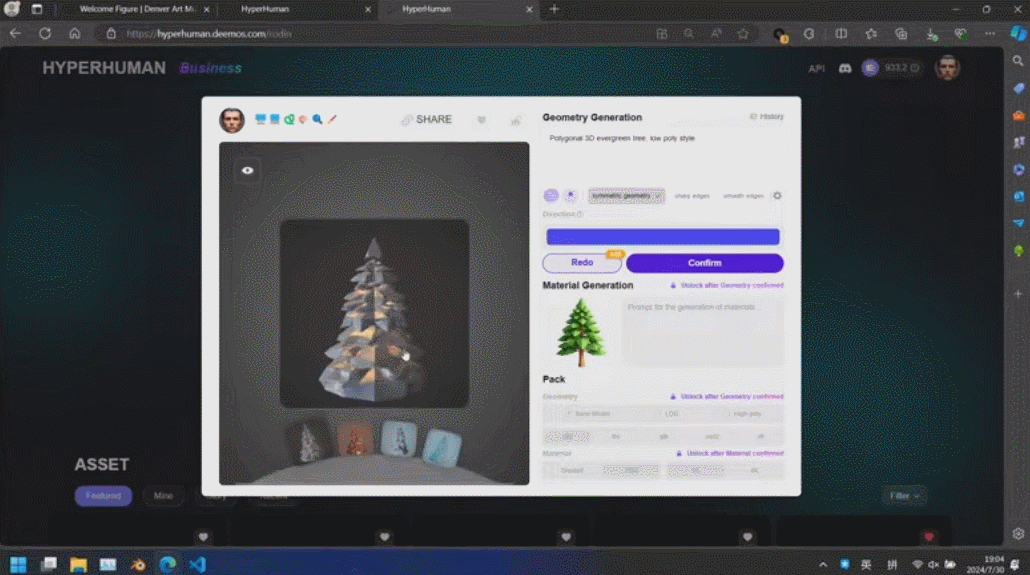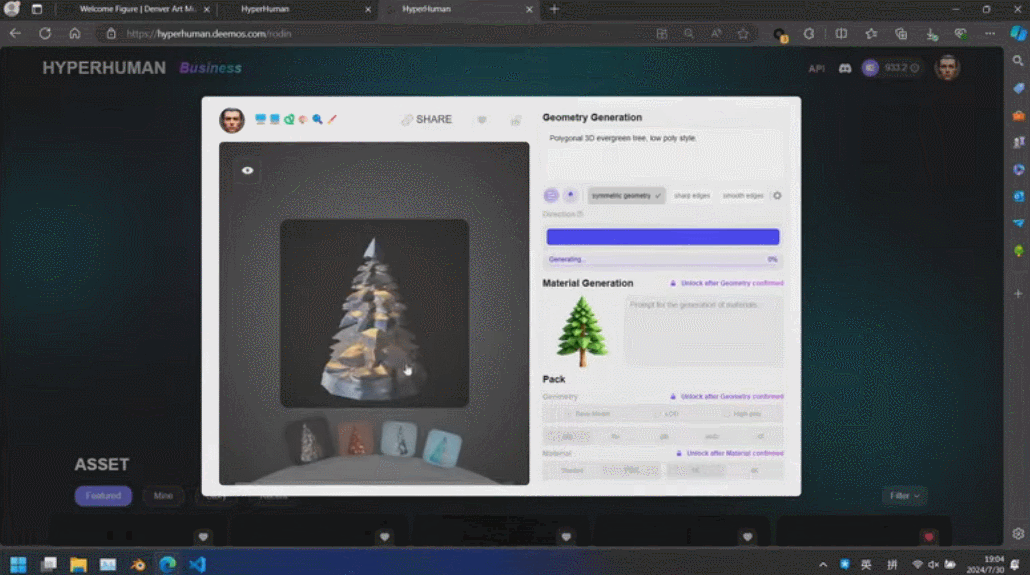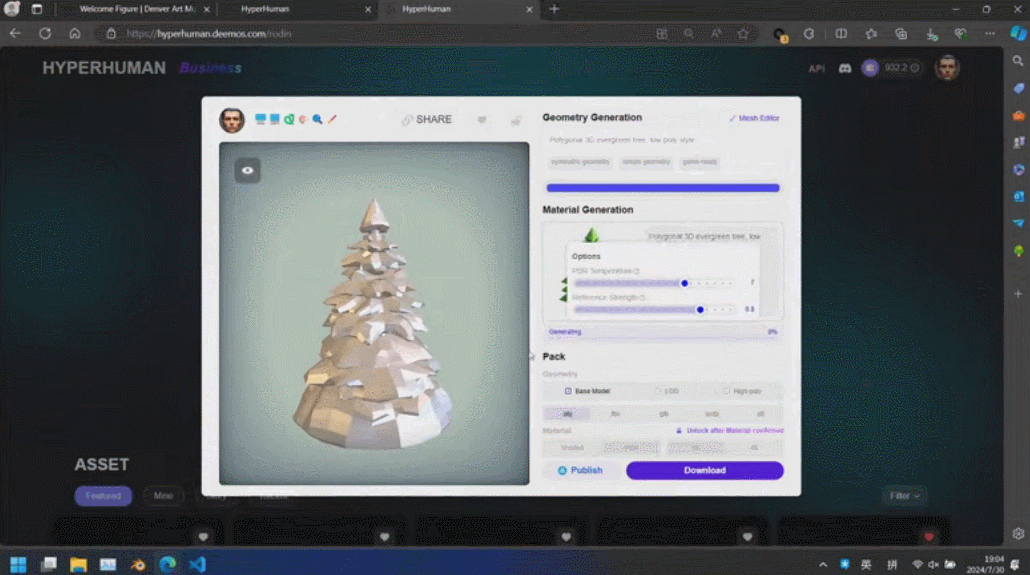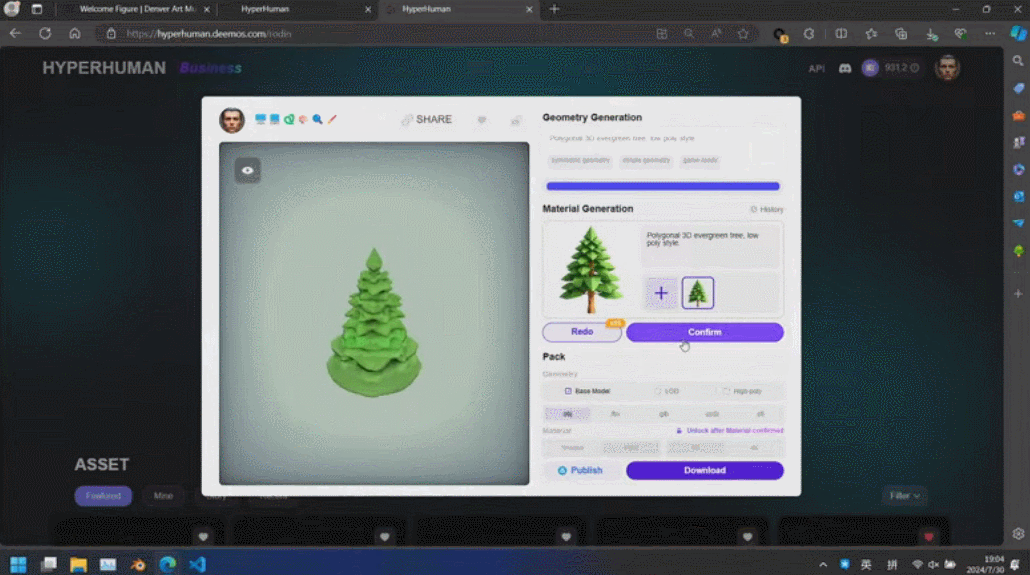 そういえば、最後に 3D モデルの生成がサークルの外に出たのは、実は SIGGRAPH でした。2021 年、NVIDIA はこのステージで Huang Renxun の 3D モデルを作成する方法を導入し、偽物と本物で世界に衝撃を与えました効果。
そういえば、最後に 3D モデルの生成がサークルの外に出たのは、実は SIGGRAPH でした。2021 年、NVIDIA はこのステージで Huang Renxun の 3D モデルを作成する方法を導入し、偽物と本物で世界に衝撃を与えました効果。
当時、3D モデルの生成はデジタル ヒューマンや仮想現実などのテクノロジーにとって重要であると考えられていました。しかし、高精度ボディスキャン+ディープラーニングによる再構成という高額なコストが、量産されない運命にあることは間違いありません。
AI 生成を使用する方が良い方法かもしれません。しかし、この方向で人々が提案する技術は、過去において常に「賞賛されるが普及しない」ものでした。 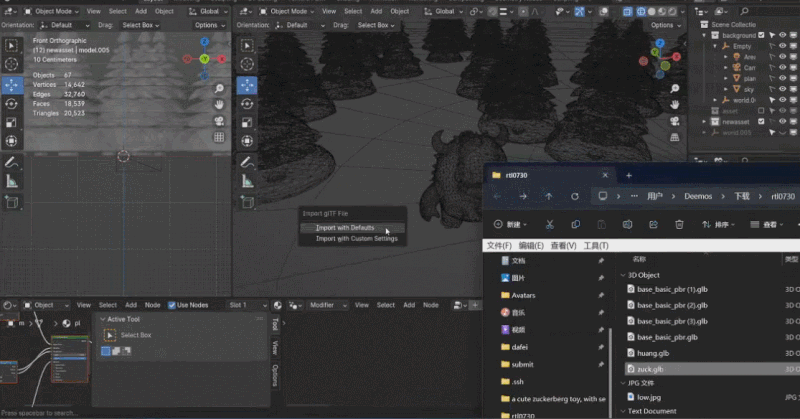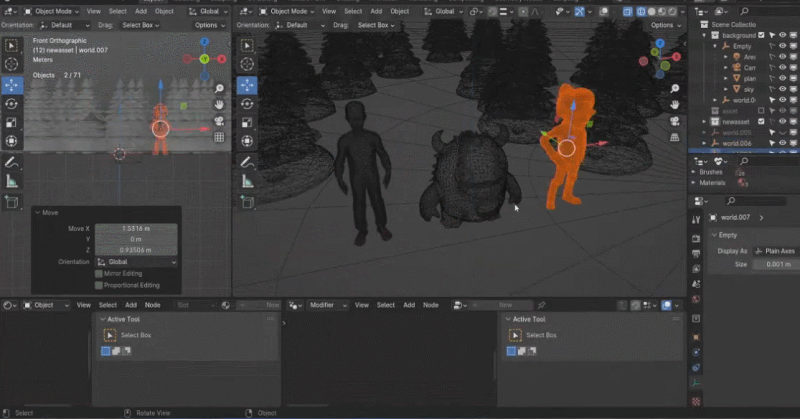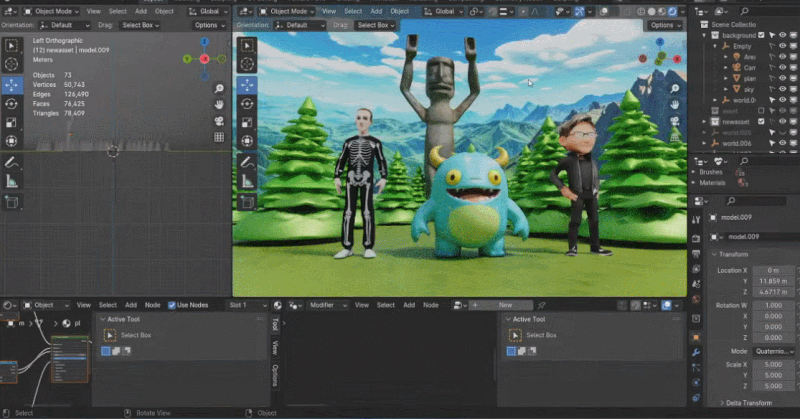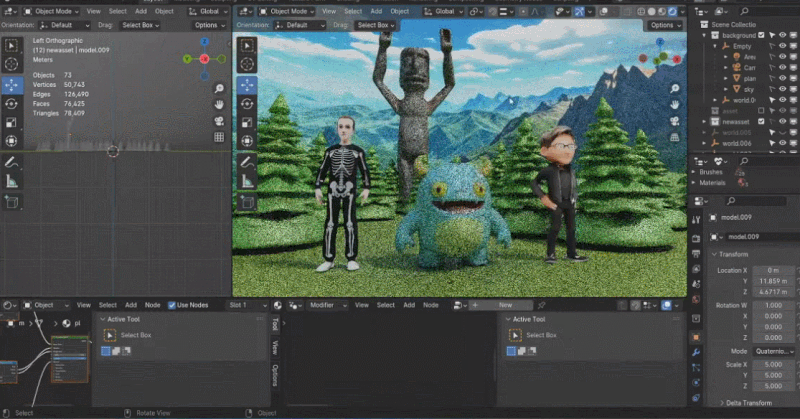
3D は、モデルが視覚的に適切に動作するだけでは十分ではなく、マテリアルの表現方法やパッチなど、特定の業界標準に準拠する必要もあります。計画、構造がいかに合理的であるか。人間の業界標準と一致しない場合、生成された結果には多くの調整が必要となり、実稼働環境に適用することが困難になります。
大規模言語モデル (LLM) が人間の価値観に合わせる必要があるのと同様に、3D 生成された AI モデルも複雑な 3D 業界標準に合わせる必要があります。
より実用的なソリューションが登場しました: 3D ネイティブ上海科技大学 MARS 研究室の最優秀論文候補の 1 つ - CLAY により、業界は上記の問題に対する実現可能な解決策、つまり 3D を確認できるようになりましたネイティブ。
過去 2 年間で、3D 生成の技術的ルートは 2D 次元強化とネイティブ 3D の 2 つのカテゴリに大別できることがわかっています。
2D-Dimensionalitätsverbesserung ist ein Prozess zur Erzielung einer dreidimensionalen Rekonstruktion durch ein 2D-Diffusionsmodell in Kombination mit Methoden wie NeRF. Da sie mit großen Mengen an 2D-Bilddaten trainiert werden können, führen solche Modelle tendenziell zu unterschiedlichen Ergebnissen. Aufgrund der unzureichenden 3D-Vorhergehenden Fähigkeiten des 2D-Diffusionsmodells ist diese Art von Modell jedoch nur begrenzt in der Lage, die 3D-Welt zu verstehen, und neigt dazu, Ergebnisse mit unangemessenen geometrischen Strukturen (z. B. Menschen oder Tiere mit mehreren Köpfen) zu generieren.

Eine Reihe neuerer Rekonstruktionsbemühungen mit mehreren Ansichten haben dieses Problem bis zu einem gewissen Grad gemildert, indem den Trainingsdaten des 2D-Diffusionsmodells 2D-Bilder mit mehreren Ansichten von 3D-Assets hinzugefügt wurden. Die Einschränkung besteht jedoch darin, dass der Ausgangspunkt solcher Methoden 2D-Bilder sind. Sie konzentrieren sich daher auf die Qualität der generierten Bilder und nicht auf die Wahrung der geometrischen Genauigkeit. Daher sind die generierten Geometrien häufig unvollständig und weisen keine Details auf.
Mit anderen Worten: 2D-Daten erfassen nur eine Seite oder Projektion der realen Welt und können daher einen dreidimensionalen Inhalt nicht vollständig beschreiben. und die generierten Ergebnisse sind immer noch. Es sind viele Änderungen erforderlich und es ist schwierig, Industriestandards zu erfüllen.
Angesichts dieser Einschränkungen wählte das Forschungsteam von CLAY einen anderen Weg – 3D-nativ.
Diese Route trainiert generative Modelle direkt aus 3D-Datensätzen und extrahiert umfangreiche 3D-Priors aus einer Vielzahl von 3D-Geometrien. Dadurch kann das Modell geometrische Merkmale besser „verstehen“ und bewahren.
Allerdings muss dieser Modelltyp groß genug sein, um mit leistungsstarken Generierungsfunktionen „entstehen“ zu können, und größere Modelle müssen auf größeren Datensätzen trainiert werden. Wie wir alle wissen, sind hochwertige 3D-Datensätze sehr knapp und teuer, was das erste Problem ist, das die native 3D-Route lösen muss.
In diesem CLAY-Artikel verwenden Forscher maßgeschneiderte Datenverarbeitungspipelines, um mehrere 3D-Datensätze zu analysieren und effektive Techniken zur Skalierung des generativen Modells vorzuschlagen.
Konkret beginnt ihr Datenverarbeitungsprozess mit einem maßgeschneiderten Neuvernetzungsalgorithmus, um 3D-Daten in wasserdichte Netze umzuwandeln und dabei Dinge wie harte Kanten und flache Oberflächen sorgfältig zu bewahren. Darüber hinaus nutzten sie GPT-4V, um detaillierte Anmerkungen zu erstellen, die wichtige geometrische Merkmale hervorheben.
Nachdem der obige Verarbeitungsprozess durchlaufen wurde, werden viele Datensätze zu dem extrem großen 3D-Modelldatensatz kombiniert, der für das CLAY-Modelltraining verwendet wird. Bisher wurden diese Datensätze aufgrund unterschiedlicher Formate und mangelnder Konsistenz nie zusammen zum Trainieren generativer 3D-Modelle verwendet. Der verarbeitete kombinierte Datensatz behält eine konsistente Darstellung und kohärente Anmerkungen bei, was die Verallgemeinerung generativer Modelle erheblich verbessern kann.
CLAY, das mit diesem Datensatz trainiert wurde, enthält ein generatives 3D-Modell mit bis zu 1,5 Milliarden Parametern. Um sicherzustellen, dass der Informationsverlust von der Datensatzkonvertierung über den impliziten Ausdruck bis zur Ausgabe so gering wie möglich ist, haben sie lange Zeit mit der Überprüfung und Verbesserung verbracht und schließlich eine neue und effiziente 3D-Ausdrucksmethode erforscht. Insbesondere haben sie das neuronale Felddesign in 3DShape2VecSet übernommen, um eine kontinuierliche und vollständige Oberfläche zu beschreiben, und es mit einem speziell entwickelten geometrischen VAE mit mehreren Auflösungen kombiniert, um Punktwolken unterschiedlicher Auflösung zu verarbeiten und so eine Anpassung an die latente Vektorgröße (latent) zu ermöglichen Größe).

Um die Modellerweiterung zu erleichtern, verwendet CLAY einen minimalistischen Latent Diffusion Transformer (DiT). Es besteht aus einem Transformator, kann sich an die Größe des latenten Vektors anpassen und verfügt über eine große Modellskalierbarkeit. Darüber hinaus führt CLAY auch ein progressives Trainingsschema ein, indem die latente Vektorgröße und die Modellparameter schrittweise erhöht werden. 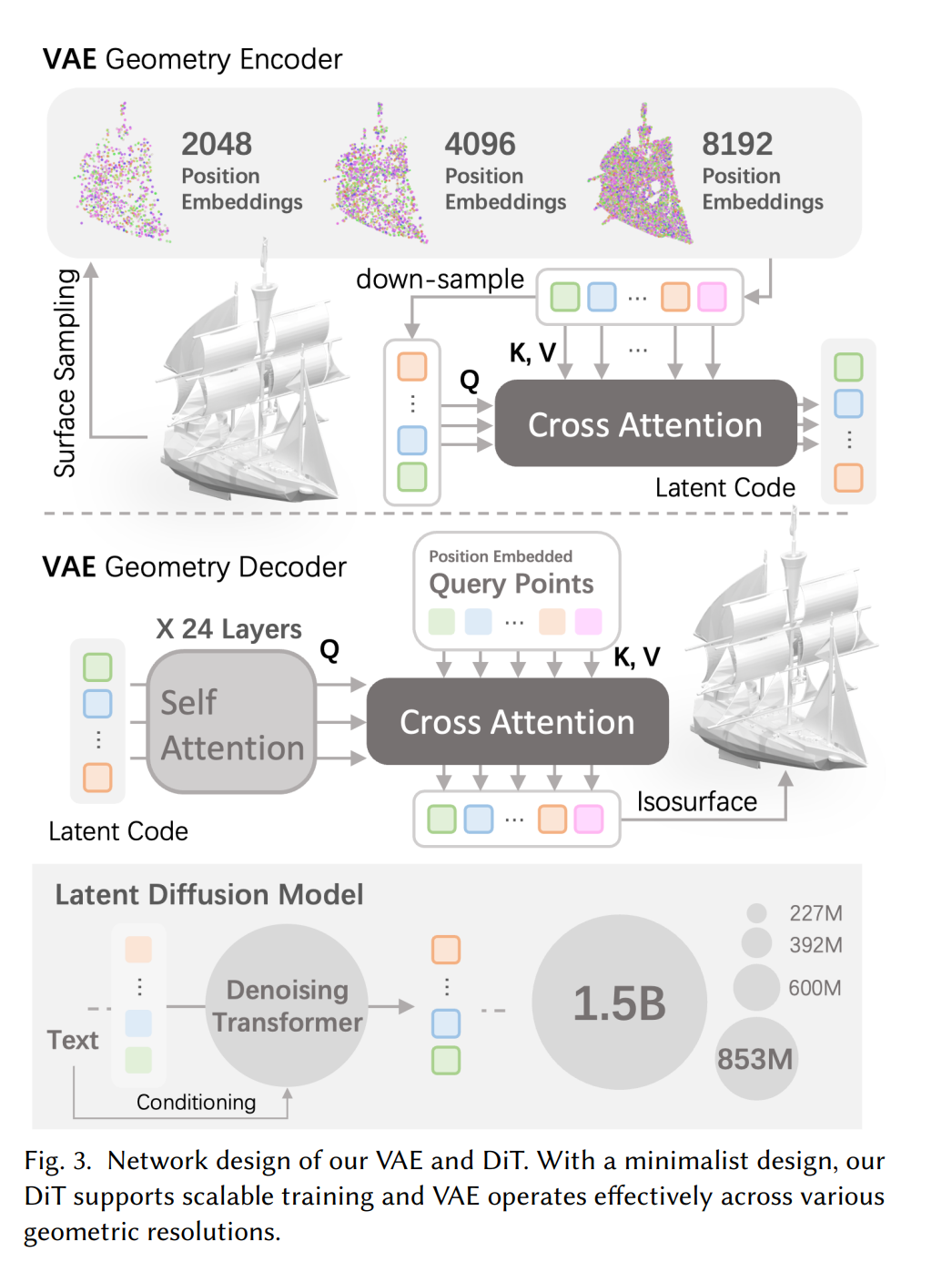
Schließlich erreicht CLAY eine präzise Kontrolle der Geometrie, und Benutzer können die Komplexität, den Stil usw. (sogar Zeichen) der Geometriegenerierung steuern, indem sie Eingabeaufforderungswörter anpassen. Im Vergleich zu früheren Methoden kann CLAY schnell detaillierte Geometrie erzeugen und wichtige geometrische Merkmale wie flache Oberflächen und strukturelle Integrität gewährleisten.
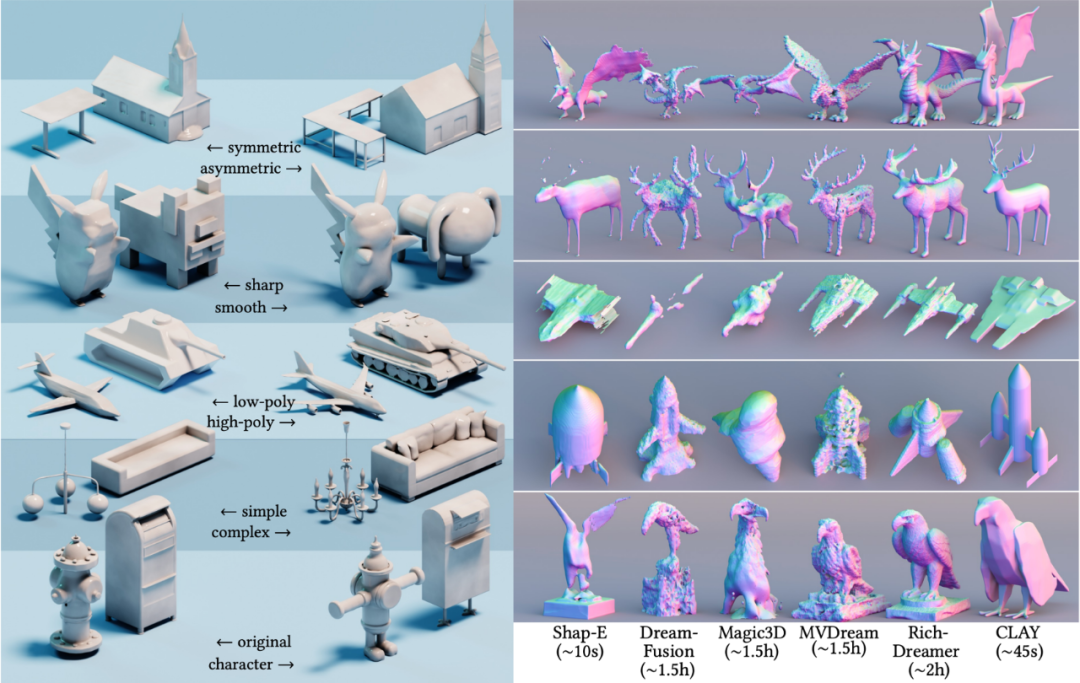
Einige Ergebnisse in der Arbeit demonstrieren vollständig die Vorteile nativer 3D-Pfade. Die folgende Abbildung zeigt die ersten drei Proben des nächsten Nachbarn, die der Forscher aus dem Datensatz abgerufen hat. Die von CLAY generierte hochwertige Geometrie stimmt mit den Eingabeaufforderungswörtern überein, unterscheidet sich jedoch von den Beispielen im Datensatz und weist einen ausreichenden Reichtum und die Fähigkeit auf, aus großen Modellen hervorzugehen.

Um die direkte Nutzung der generierten digitalen Assets in bestehenden CG-Produktionspipelines zu ermöglichen, haben die Forscher außerdem eine zweistufige Lösung gewählt:
1. Die geometrische Optimierung gewährleistet strukturelle Integrität und Kompatibilität bei gleichzeitiger Beibehaltung der Ästhetik und der funktionalen Verfeinerung Form des Modells, wie z. B. Viereckigkeit, UV-Ausdehnung usw.;
2. Die Materialsynthese verleiht dem Modell eine realistische Textur. Zusammengenommen verwandeln diese Schritte ein grobes Netz in ein besser nutzbares Asset in einer digitalen Umgebung.
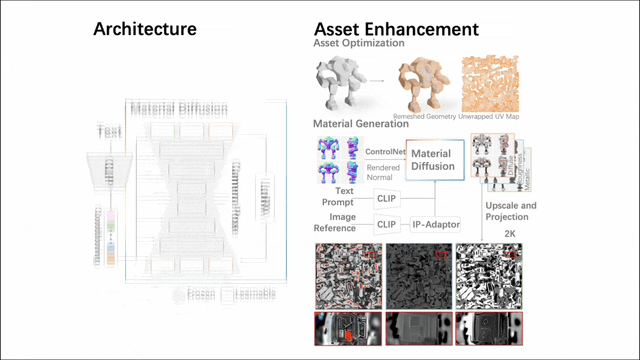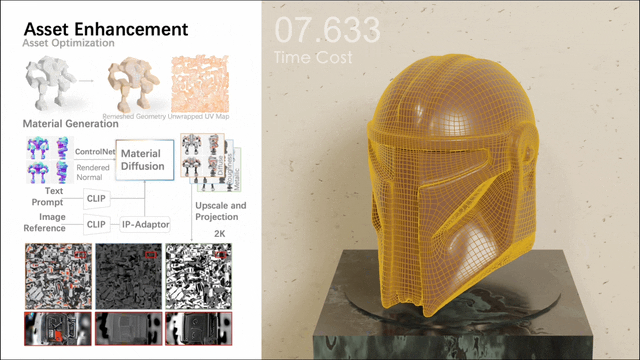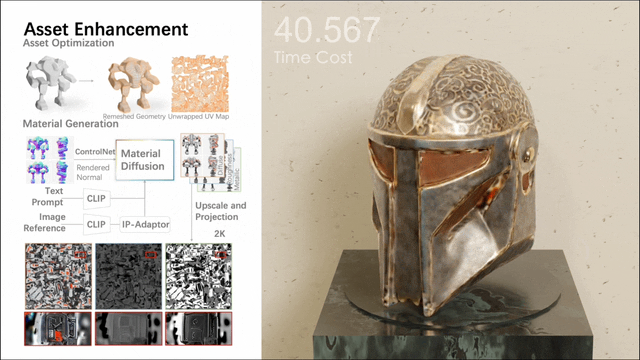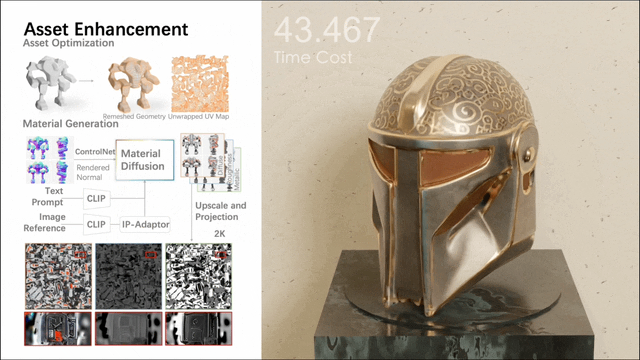
Unter anderem umfasst die zweite Stufe ein Multi-View-Materialdiffusionsmodell mit fast 1 Milliarde Parametern. Nach der Quadrifizierung des Netzes und der UV-Abwicklung wird über einen Multi-View-Ansatz ein PBR-Material generiert, das dann auf UV-Karten zurückprojiziert wird. Das Modell generiert realistischere PBR-Materialien als frühere Methoden, was zu realistischen Renderings führt.

Damit CLAY mehr Aufgaben unterstützen kann, haben die Forscher auch eine 3D-Version von ControlNet entwickelt. Die minimalistische Architektur ermöglicht die effiziente Unterstützung der Zustandskontrolle verschiedener Modi. Sie implementierten mehrere Beispielbedingungen, die Benutzer problemlos bereitstellen können, darunter Text (nativ unterstützt) sowie Bilder/Skizzen, Voxel, Multiview-Bilder, Punktwolken und Begrenzungsrahmen) und eine Teilpunktwolke mit einem Begrenzungsrahmen. Diese Bedingungen können einzeln oder in Kombination angewendet werden, sodass das Modell Inhalte basierend auf einer einzelnen Bedingung originalgetreu generieren oder mehrere Bedingungen kombinieren kann, um 3D-Inhalte mit Stil und Benutzerkontrolle zu erstellen, was eine breite Palette kreativer Möglichkeiten bietet.
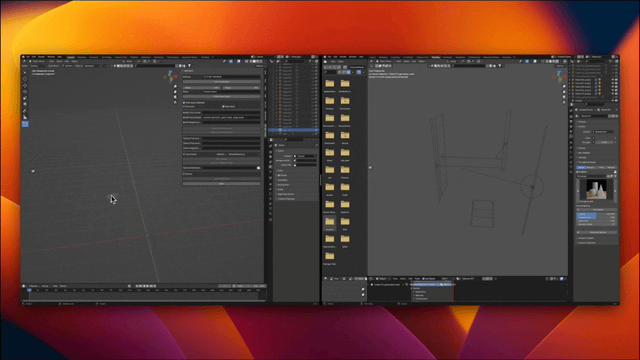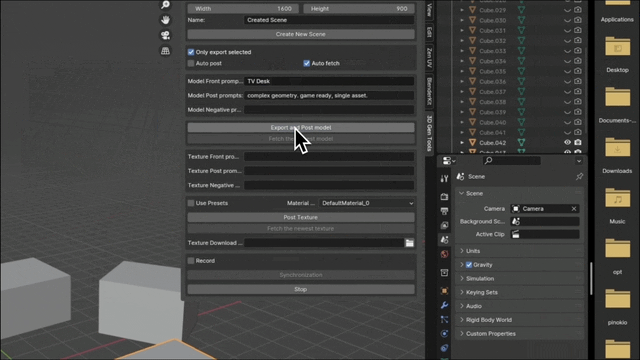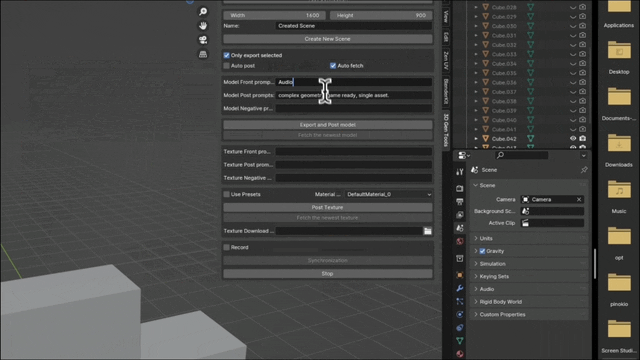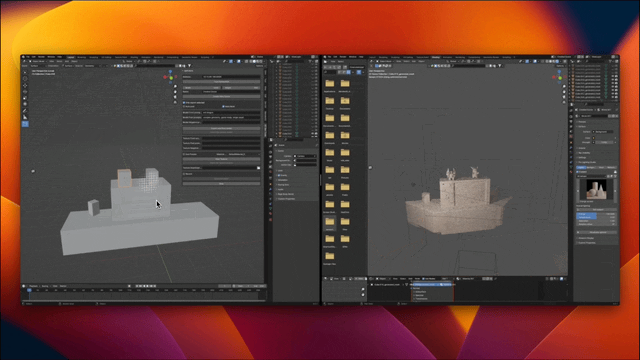
Darüber hinaus unterstützt CLAY auch direkt Low-Rank Adaptation (LoRA) auf den Aufmerksamkeitsebenen von DiT. Dies ermöglicht eine effiziente Feinabstimmung, sodass der generierte 3D-Inhalt an einen bestimmten Stil angepasst werden kann.

Anhand dieser Designs ist nicht schwer zu erkennen, dass das Design von CLAY von Anfang an auf Anwendungsszenarien abzielt, was sich stark von einigen rein akademischen Untersuchungen unterscheidet.
Dadurch lässt sich das Modell auch schnell umsetzen: Rodin ist mittlerweile für viele 3D-Entwickler zum häufig verwendeten 3D-Generator geworden.文 Sie können auf klicken, um den Originaltext zu lesen und auf das Rodin-Erlebnisprodukt zuzugreifen (es wird empfohlen, die PC-Seite zu öffnen).

Das MARS-Laborteam der Shanghai University of Science and Technology, das zu CLAY beigetragen hat, wurde in den 50 Jahren seit der Gründung von SIGGRAPH im Jahr 2023 als erstes chinesisches Team für die Echtzeit-Live-Sitzung ausgewählt. Das hat es getan stand zum zweiten Mal in Folge auf dieser Bühne.
 Shadow Eye Technology erforscht den Weg der nativen 3D-KI und entwickelt 3D-Produkte, die kurz vor der Produktionsreife stehen, wodurch die Schwelle für die 3D-Erstellung deutlich gesenkt wird.
Shadow Eye Technology erforscht den Weg der nativen 3D-KI und entwickelt 3D-Produkte, die kurz vor der Produktionsreife stehen, wodurch die Schwelle für die 3D-Erstellung deutlich gesenkt wird.
Die auf CLAY basierende 3D-Generierungstechnologie gibt nicht nur die Richtung der Branche vor, sondern wird auch eine positive Rolle bei der Generierung von Bildern und Videos spielen. Denn aus Sicht der Informationsentropie ist der Spielraum für das Modell umso größer, je weniger Informationen Sie bereitstellen. Durch 3D-Modellierung kann die Konvergenzrichtung verankert und die Steuerbarkeit der Bild- und Videoerzeugung verbessert werden.
Der 3D-Bereich selbst ist jedoch nicht so einfach wie Bilder und Videos. Erst wenn die vollständige Kette abgeschlossen ist, werden Benutzer beginnen, die Fähigkeiten von 3D + KI wirklich zu akzeptieren. Dieser Teil der Arbeit kann über die API des Partners oder von dessen Team selbst erledigt werden. 
Ich freue mich auf die weitere Implementierung neuer Technologien in der Zukunft.
以上が2 つの論文が同時に最優秀論文賞にノミネートされました。SIGGRAPH の最初のリアルタイム ライブ中国チームは、生成 AI を使用して 3D 世界を作成しました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



