Sora のリリース以来、AI ビデオ生成の分野はさらに「忙しく」なりました。過去数か月間、私たちは Jimeng、Runway Gen-3、Luma AI、Kuaishou Keling が順番に爆発するのを目撃してきました。 一目で AI によって生成されたものであると識別できる過去のモデルとは異なり、この大規模なビデオ モデルのバッチは、これまで見た中で「最高」である可能性があります。 しかし、ビデオ大規模言語モデル (LLM) の驚くべきパフォーマンスの背後には、非常に高いコストを必要とする、巨大で細かく注釈が付けられたビデオ データ セットがあります。最近、追加のトレーニングを必要としない多くの革新的な方法が研究分野で登場しました。つまり、トレーニングされた画像の大規模言語モデルを使用してビデオタスクを直接処理し、「高価な」トレーニングプロセスを回避します。 さらに、ほとんどの既存のビデオ LLM には 2 つの大きな欠点があります: (1) 限られたフレーム数のビデオ入力しか処理できないため、モデルが空間的および時間的な微妙な内容をキャプチャすることが困難になります。ビデオ; (2) 時間モデリング設計が欠けていますが、単にビデオの特徴を LLM に入力し、LLM の動きをモデル化する機能に完全に依存しています。 上記の問題に対応して、Apple 研究者は SlowFast-LLaVA (略して SF-LLaVA) を提案しました。このモデルは、Byte チームによって開発された LLaVA-NeXT アーキテクチャに基づいており、追加の微調整は必要なく、すぐに使用できます。研究チームは、動作認識の分野で成功した 2 ストリーム ネットワークに触発されて、ビデオ LLM 用の新しい SlowFast 入力メカニズムを設計しました。 簡単に言えば、SF-LLaVA は 2 つの異なる観察速度 (低速と高速) を通じてビデオ内の詳細と動きを理解します。
- 低速パス: 可能な限り多くの空間詳細を保持しながら、低フレーム レートで特徴を抽出します (例: 8 フレームごとに 24×24 トークンを保持)
- 高速パス: 高フレーム レートで実行しますが、空間プーリングのステップ サイズを大きくして、ビデオの解像度を下げて、より大きな時間的コンテキストをシミュレートし、アクションの一貫性を理解することに重点を置きます
これは、2 つの「目」を持つモデルと同等です。ゆっくりと細部に注意を払い、もう一方は素早く見て動きに注意を払います。これにより、ほとんどの既存のビデオ LLM の問題点が解決され、詳細な空間セマンティクスとより長い時間的コンテキストの両方をキャプチャできるようになります。 
論文リンク: https://arxiv.org/pdf/2407.15841実験結果は、SF-LLaVA がすべてのベンチマーク テストにおいて大幅な利点により既存のトレーニング不要の手法を上回っていることを示しています。慎重に微調整された SFT モデルと比較すると、SF-LLaVA は同等以上のパフォーマンスを実現します。 
下の図に示すように、SF-LLaVA は標準のトレーニング不要のビデオ LLM プロセスに従います。ビデオ V と質問 Q を入力として受け取り、対応する回答 A を出力します。 
Pour l'entrée, N images sont uniformément échantillonnées à partir de chaque vidéo de n'importe quelle taille et longueur, I = {I_1, I_2, ..., I_N}, et aucune combinaison ou disposition spéciale des images vidéo sélectionnées n'est requise. La caractéristique de fréquence extraite indépendamment dans l'unité de trame est F_v ∈ R^N×H×W, où H et W sont respectivement la hauteur et la largeur de la caractéristique de trame. La prochaine étape consiste à traiter davantage F_v selon des chemins lents et rapides et à les combiner pour former une représentation vidéo efficace. Le chemin lent échantillonne uniformément les caractéristiques du cadre de 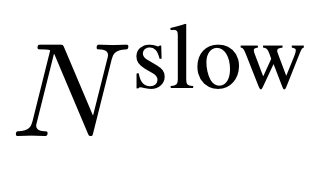 à partir de F_v, où
à partir de F_v, où  . Des recherches antérieures ont montré qu'une mise en commun appropriée dans la dimension spatiale peut améliorer l'efficacité et la robustesse de la génération vidéo. Par conséquent, l’équipe de recherche a appliqué un processus de pooling avec un pas de σ_h×σ_w sur F_v pour obtenir la caractéristique finale :
. Des recherches antérieures ont montré qu'une mise en commun appropriée dans la dimension spatiale peut améliorer l'efficacité et la robustesse de la génération vidéo. Par conséquent, l’équipe de recherche a appliqué un processus de pooling avec un pas de σ_h×σ_w sur F_v pour obtenir la caractéristique finale : 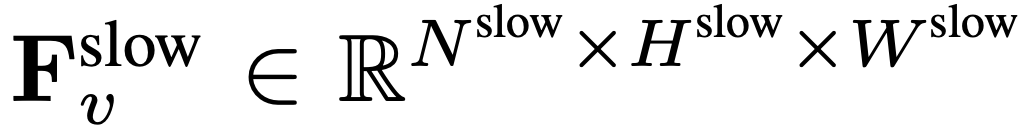 , où
, où 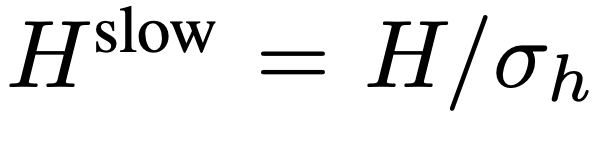 ,
, 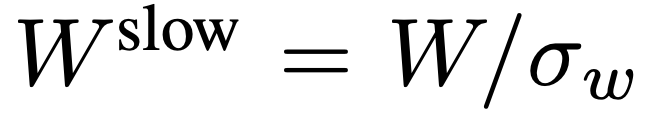 . L’ensemble du processus du chemin lent est illustré dans l’équation 2.
. L’ensemble du processus du chemin lent est illustré dans l’équation 2. 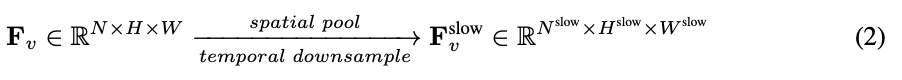
Le chemin rapide préserve toutes les fonctionnalités d'image dans F_v pour capturer autant que possible le contexte temporel à longue portée de la vidéo. Plus précisément, l’équipe de recherche utilise un pas de regroupement spatial  pour sous-échantillonner de manière agressive F_v afin d’obtenir la caractéristique finale
pour sous-échantillonner de manière agressive F_v afin d’obtenir la caractéristique finale 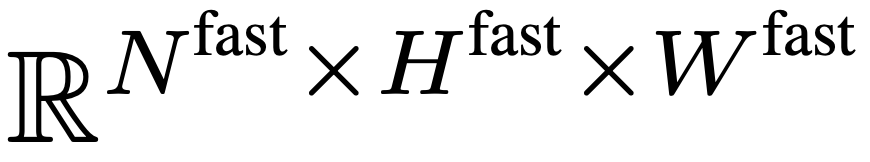 . L'équipe de recherche a mis en place
. L'équipe de recherche a mis en place  ,
, 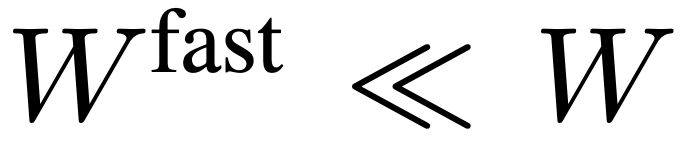 afin que la voie rapide puisse se concentrer sur la simulation du contexte temporel et des signaux de mouvement. L’ensemble du processus du chemin lent est illustré dans l’équation 3.
afin que la voie rapide puisse se concentrer sur la simulation du contexte temporel et des signaux de mouvement. L’ensemble du processus du chemin lent est illustré dans l’équation 3. 
Enfin, les caractéristiques vidéo agrégées sont obtenues : 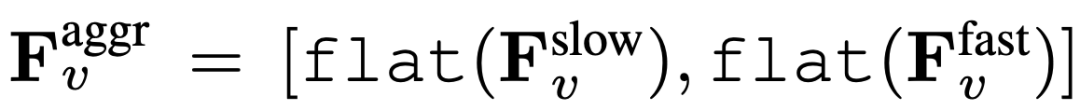 , où flat et [, ] représentent respectivement les opérations d'aplatissement et de concaténation. Comme le montre l'expression,
, où flat et [, ] représentent respectivement les opérations d'aplatissement et de concaténation. Comme le montre l'expression, 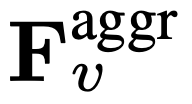 ne nécessite aucun jeton spécial pour séparer les chemins lents et rapides. SF-LLaVA utilise un total de
ne nécessite aucun jeton spécial pour séparer les chemins lents et rapides. SF-LLaVA utilise un total de 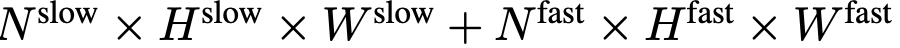 jetons vidéo. Les caractéristiques visuelles de la vidéo
jetons vidéo. Les caractéristiques visuelles de la vidéo  seront combinées avec des informations textuelles (telles que les questions posées par les utilisateurs) et envoyées comme données d'entrée à un grand modèle de langage (LLM) pour traitement. Le processus SlowFast est illustré dans l'équation 4.
seront combinées avec des informations textuelles (telles que les questions posées par les utilisateurs) et envoyées comme données d'entrée à un grand modèle de langage (LLM) pour traitement. Le processus SlowFast est illustré dans l'équation 4. 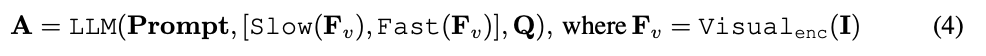
L'équipe de recherche a mené une évaluation complète des performances de SF-LLaVA, en le comparant aux modèles SOTA actuels sans formation (tels que IG-VLM et LLoVi) dans plusieurs tâches de réponse à des questions vidéo. En outre, ils l’ont comparé à des LLM vidéo tels que VideoLLaVA et PLLaVA qui ont été supervisés et affinés (SFT) sur des ensembles de données vidéo. Réponse aux questions vidéo ouvertesComme le montre le tableau ci-dessous, dans la tâche de réponse aux questions vidéo ouvertes, SF-LLaVA fonctionne mieux que les méthodes sans formation existantes dans tous les benchmarks. Plus précisément, lorsqu'il est équipé de LLM de tailles de paramètres respectivement 7B et 34B, SF-LLaVA est 2,1 % et 5,0 % plus élevé que IGVLM sur MSRVTT-QA, 5,7 % et 1,5 % plus élevé sur TGIF-QA et 5,7 % et 1,5 % plus élevé sur ActivityNet -2,0% et 0,8% plus élevé sur le QA. Même par rapport à la méthode SFT affinée, SF-LLaVA affiche des performances comparables dans la plupart des benchmarks, uniquement sur le benchmark ActivityNet-QA, PLLaVA et LLaVA-NeXT-VideoDPO surpassent légèrement One chip. 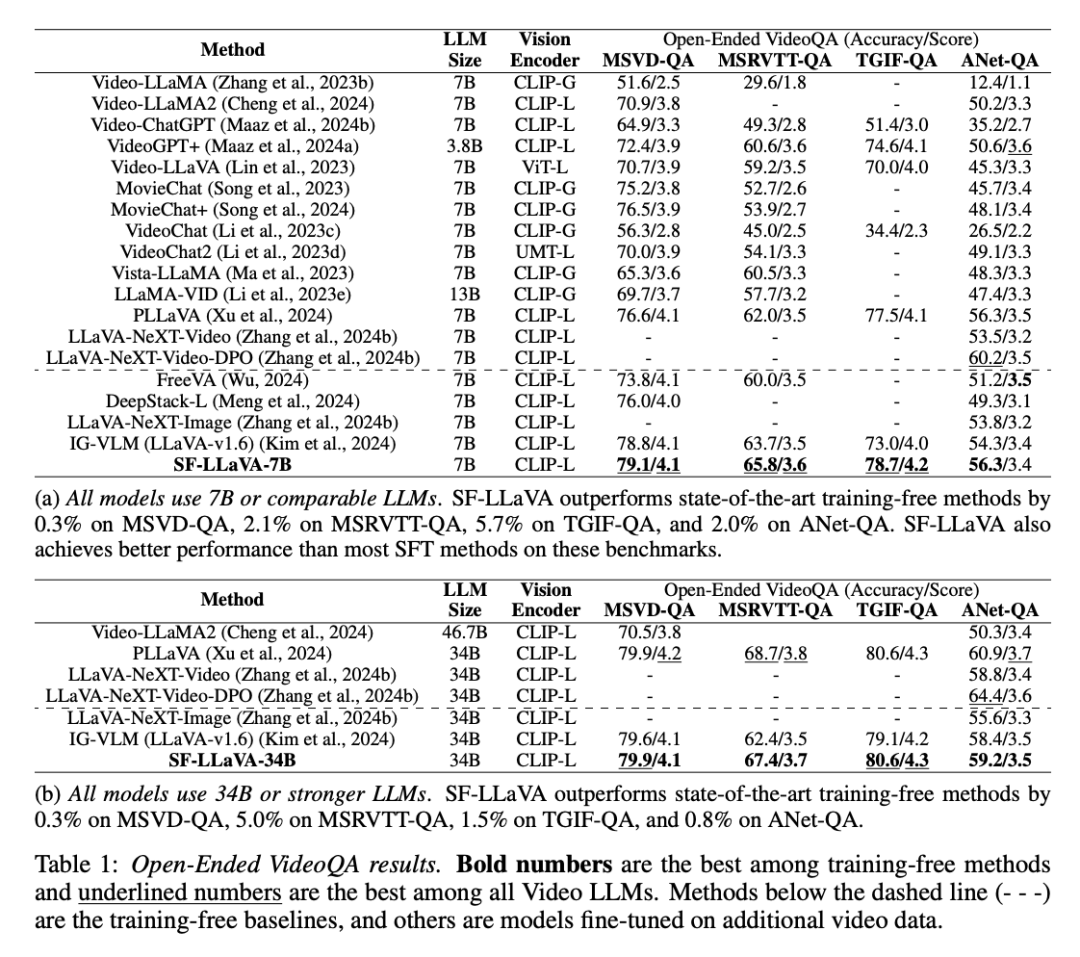
Questions et réponses vidéo à choix multiplesComme le montre le tableau ci-dessous, SF-LLaVA surpasse les autres méthodes sans formation en matière de questions et réponses vidéo à choix multiples dans tous les benchmarks. Dans l'ensemble de données EgoSchema, qui nécessite un raisonnement complexe à long terme, les versions SF-LLaVA7B et 34B ont obtenu des scores supérieurs de 11,4 % et 2,2 % à ceux du modèle IG-VLM, respectivement. Bien que VideoTree soit en tête des benchmarks car il s'agit d'un modèle propriétaire basé sur GPT-4, les performances sont bien supérieures à celles du LLM open source. Le modèle SF-LLaVA 34B obtient également de meilleurs résultats sur EgoSchema par rapport à la méthode SFT, ce qui confirme la puissance de la conception SlowFast dans la gestion de vidéos longues. 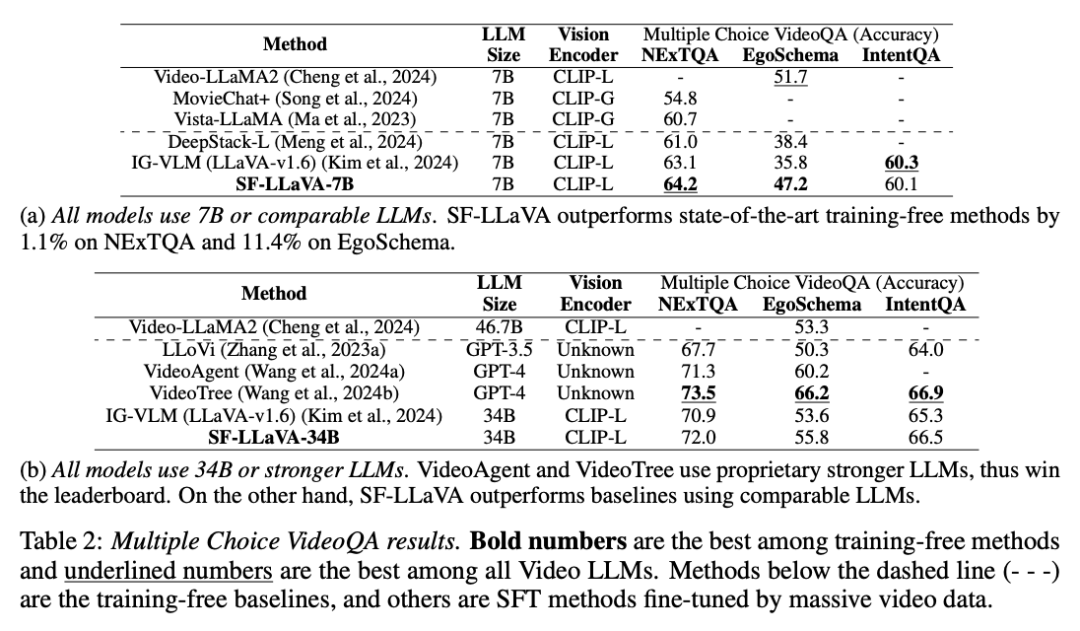
Comme le montre le tableau 3, pour la tâche de génération de texte vidéo, SF-LLaVA présente également certains avantages. Le SF-LLaVA-34B a dépassé toutes les références sans formation en termes de performances globales. Bien qu'en termes d'orientation des détails, SF-LLaVA soit légèrement inférieur à LLaVA-NeXT-Image. Basé sur la conception SlowFast, SF-LLaVA peut couvrir un contexte temporel plus long avec moins de jetons visuels et est donc particulièrement performant dans les tâches de compréhension temporelle. De plus, SF-LLaVA-34B surpasse également la plupart des méthodes SFT en termes de performances vidéo Vincent. 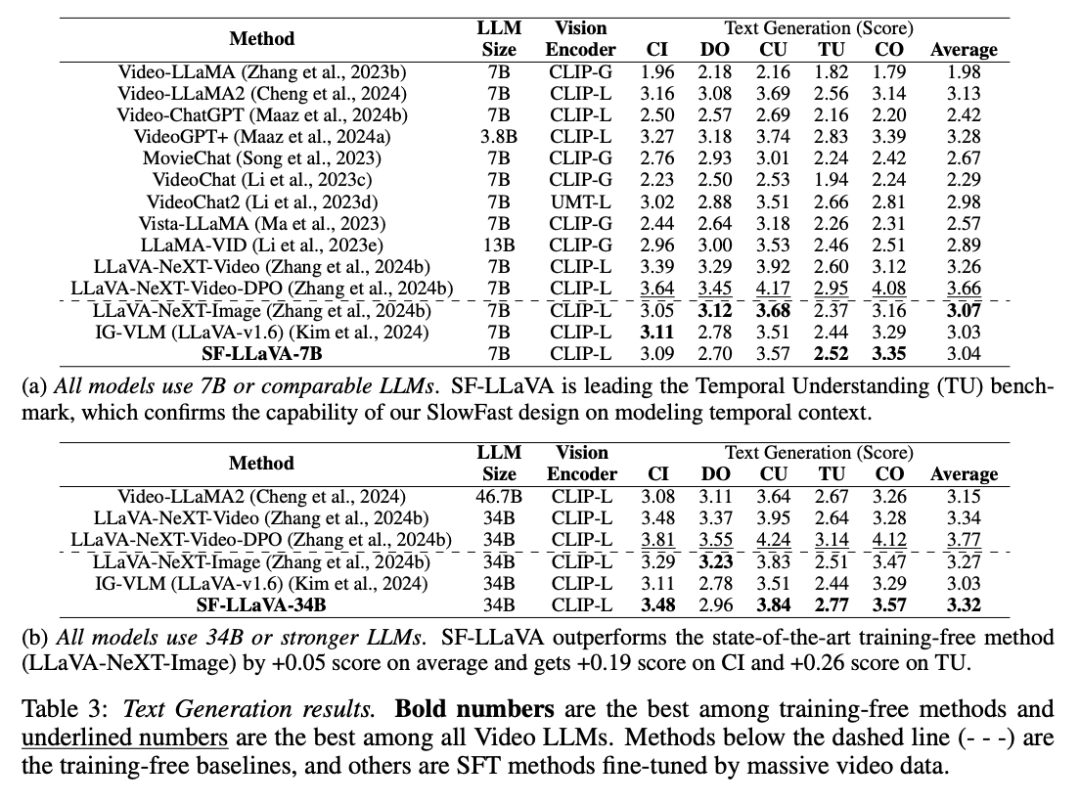
Pour plus de détails, veuillez vous référer au document original. 以上がビデオモデルに速い目と遅い目を追加すると、Apple のトレーニング不要の新しいメソッドはすべての SOTA を数秒で上回りますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。































![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



