

初の完全自動科学発見 AI システム、Transformer 作者のスタートアップ、Sakana AI が AI Scientist を発表


編集者 | ScienceAI
1年前、GoogleのTransformer論文の最後の著者であるLlion Jones氏は起業するために退職し、元Google研究者のDavid Ha氏と人工知能会社Sakana AIを共同設立した。さかな AI は、自然からインスピレーションを得た知能に基づいて新しい基礎モデルを作成すると主張しています。
さかなAIが解答用紙を提出しました。

Sakana AI は、自動科学研究とオープンディスカバリーのための世界初の AI システムである AI Scientist のリリースを発表します!
AI 科学者は、着想、コードの作成、実験の実行、結果の要約から、論文全体の執筆と査読の実施に至るまで、AI 主導の科学研究と発見の加速の新時代を導きます。
原理的には、人間の科学者と同じように、科学研究プロセスを継続的に繰り返し、オープンな方法でアイデアを反復的に発展させることができます。研究者らは、拡散モデリング、Transformer ベースの言語モデリング、学習ダイナミクスという機械学習の 3 つの異なるサブフィールドにそれを適用することで、その多用途性を実証しました。
各アイデアは、論文あたり 15 ドル未満で実装され、完全な論文に発展します。生成された論文を評価するために、研究者らは論文スコアの評価において人間に近いパフォーマンスを備えた自動レビューアを設計し、検証しました。
AI 科学者は、トップの機械学習カンファレンスの受理基準を超える論文を書くことができます。
AI Scientist の立ち上げは、科学研究における人工知能の可能性を最大限に実現するための重要な一歩を示しています。発見プロセスを自動化し、AI 主導のレビュー システムを統合することにより、科学技術の最も困難な分野におけるイノベーションと問題解決の無限の可能性への扉が開かれます。
「
AI 科学者: 完全に自動化されたオープンエンドの科学的発見に向けて」と題された関連研究が、8 月 12 日にプレプリント プラットフォーム arXiv で公開されました。
 紙のリンク:
紙のリンク:
人工知能が直面する課題の 1 つは、科学研究を実施し、新しい知識を発見できるエージェントを開発することです。最先端のモデルは、アイデアのブレインストーミング、コードの作成、予測タスクの実行など、人間の科学者にとって補助的なツールとして使用されてきましたが、それでも科学プロセスのほんの一部しか完了しません。
最新の研究で、Sakana AI の科学者たちは、完全に自動化された科学的発見のための初の包括的なフレームワークを提案し、最先端の大規模言語モデルが独立して研究を実施し、その結果を伝達できるようにします。
AI 科学者は、新しい研究アイデアを生成し、コードを作成し、実験を実行し、結果を視覚化し、完全な科学論文を書いて発見を説明し、評価のためのシミュレーション レビュー プロセスを実行できます。
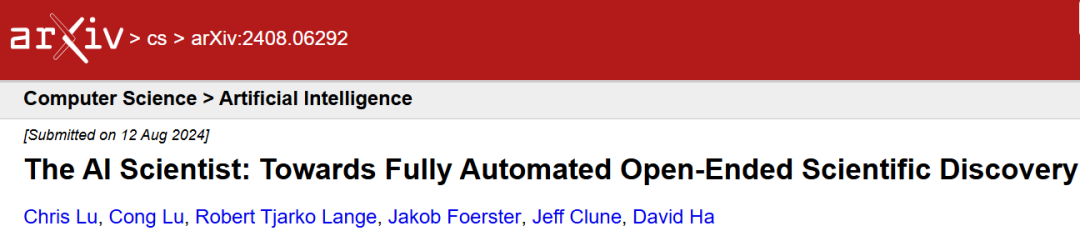
AI Scientist についてAI Scientist には、(1) アイデアの生成、(2) 実験の反復、(3) 論文執筆の 3 つの主要な段階があります。執筆が完了すると、研究者は LLM によって生成されたレビューを導入および検証し、結果として得られる論文の品質を評価します。
 イラスト: エンドツーエンドの LLM 主導の科学的発見プロセス AI 科学者の概念図。 (出典: 論文)
イラスト: エンドツーエンドの LLM 主導の科学的発見プロセス AI 科学者の概念図。 (出典: 論文)
研究者は AI 科学者に、人気のあるモデルやベンチマークの軽量ベースライン トレーニング実行を再現する開始コード テンプレートを提供します。たとえば、これはシェイクスピアに基づいて小さなトランスフォーマーをトレーニングするためのコードである可能性があります。これは、数分で完了できる自然言語処理で実行される古典的な概念実証トレーニングです。
その後、AI 科学者は、考えられる研究の方向性を自由に探索できます。テンプレートには、スタイル ファイルとセクション ヘッダー、および単純なプロット コードを含む LaTeX フォルダーも含まれています。通常、各実行は、トピック領域に関連する代表的な小規模実験から始まります。
研究者らは、「小規模な実験に集中することは、私たちの方法の根本的な制限ではなく、単に計算効率と私たちの装置の計算限界の問題です。
なぜ論文を書くことが重要なのでしょうか?」科学者の全体的な目標が科学的発見を自動化することであることを考えると、なぜ研究者は AI 科学者に人間の科学者と同じように論文を書くことを望むのでしょうか?たとえば、FunSearch や GNoME などの以前の AI システムは、かつては限られた分野で印象的な科学的発見を生み出しましたが、論文を書くことはできませんでした。
チームは、AI 科学者が研究結果を広めるために科学論文を書くことが重要であると考えています。第一に、論文を書くことは、人間が学んだことから利益を得る高度に解釈可能な方法を提供することです。第二に、書かれた論文を社内でレビューすることです。既存の機械学習カンファレンスの枠組みにより、科学者は評価を標準化できます。第三に、現代科学の誕生以来、科学論文が研究結果を広める主な媒体となってきました。
論文では自然言語を使用でき、プロットやコードを含めることができるため、あらゆる種類の科学研究や発見を柔軟に記述することができます。考えられる他のほとんどすべての形式は、何らかのデータまたは科学ジャンルに固定されています。より優れた代替手段が出現するまで(または人工知能によって発明される可能性がある)、AI 科学者をトレーニングして科学論文を書くことが、彼らをより広範な科学コミュニティに統合するために重要であるとチームは考えています。

イラスト: AI Scientist によって完全に独立して生成された「適応デュアルスケールノイズ除去」論文のプレビュー。 (出典: 論文)
コストについて
ここでのフレームワークは、トランスフォーマーベースの言語モデリング、ニューラルネットワーク学習ダイナミクス、拡散モデリングなど、機械学習のさまざまなサブフィールドで効率的に研究を行うのに十分な柔軟性を備えています。このシステムは費用対効果が高く、論文あたりのコストは約 15 ドルで、会議関連の論文を作成し、研究を民主化し (アクセスしやすさを高め)、科学の進歩を加速する能力を強調しています。
たとえば、AI Scientist に関する研究者による予備的な定性分析では、結果として得られる論文が広く有益で斬新なものであるか、少なくとも将来の研究に値するアイデアが含まれている可能性があることが示唆されています。
実験のためにチームが AI 科学者に割り当てた実際のコンピューティング量も、現在の基準からすると非常に少ないです。注目すべき点は、1 週間で数百の論文を生成した研究者の実験のほとんどが、単一の 8x NVIDIA H100 ノードのみを使用して実行されたことです。検索とフィルタリングの範囲が大規模に拡張されれば、より高品質の論文が生成される可能性があります。
このプロジェクトでは、AI Scientist の実行コストのほとんどは、LLM API コーディングと論文執筆のコストに関連していました。比較すると、LLM レビューアの実行に関連するコストと実験を実施するための計算コストは、全体のコストを削減するためにチームによって課された制約により、ごくわずかでした。
もちろん、AI 科学者が他の科学分野に適用されたり、大規模な計算実験に使用されたりした場合、このコスト分担は将来変更される可能性があります。
オープンモデルとクローズドモデル
生成された論文を定量的に評価し、最適化するために、研究者はまず自動論文レビューアを作成して検証しました。結果は、まだ最適化の余地がたくさんあるものの、LLM がかなり正確なレビューを生成し、さまざまな指標で人間と同等の結果を達成できることを示しています。
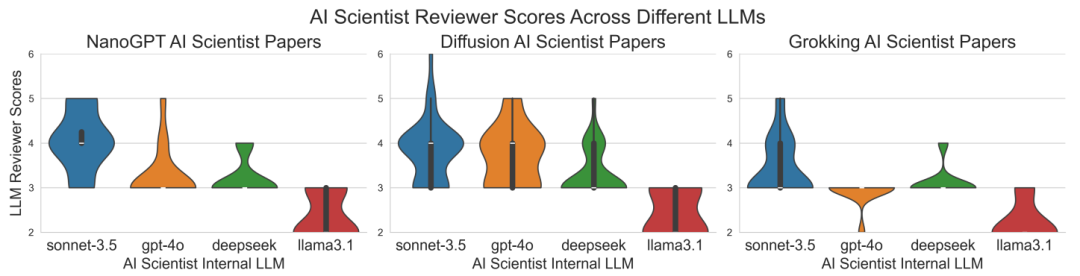
グラフィック: Violin グラフは、AI Scientist の査読者が作成した論文のスコアの分布を 3 つの領域と 4 つの基本モデルで示しています。 (出典: 論文)
AI Scientist によって生成された論文にこのレビューアーを適用すると、科学者は人間によるレビューを超えて論文評価を拡張できます。研究者らは、Sonnet 3.5 が一貫して最高の論文を生成し、その中には標準的な機械学習カンファレンスの自動論文査読者の合格基準を超えるものもあったことがわかりました。
しかし、チームは AI Scientist が Sonnet 3.5 のような単一モデルでリードを維持すると期待する理由はありません。研究者らは、オープン モデルを含むすべての最先端の LLM が今後も改善されると信じています。 LLM 間の競争により、LLM のコモディティ化と能力が大幅に向上します。
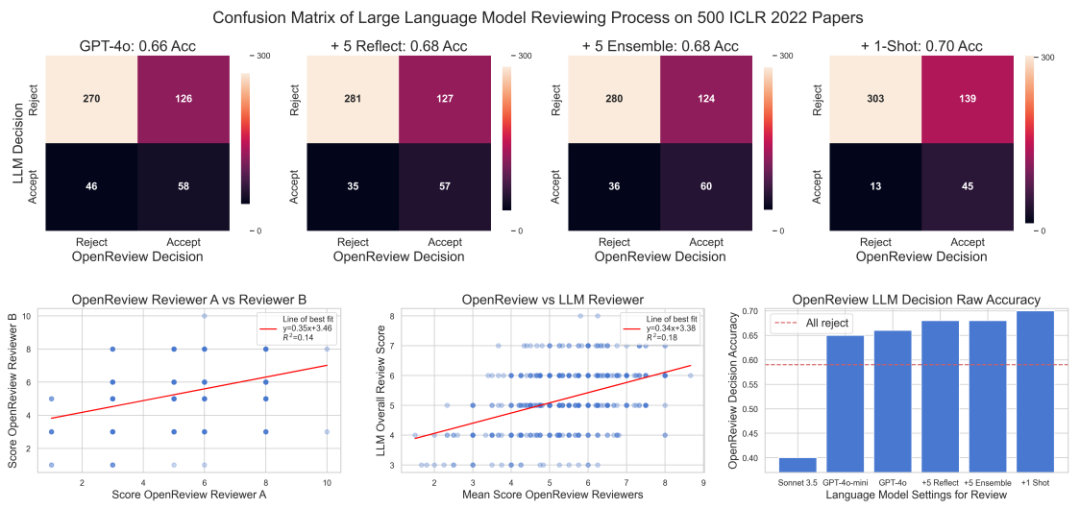
イラスト: GPT-4o を使用した ICLR 2022 OpenReview データに対する AI 科学者の論文レビュー プロセスの評価。 (出典: 論文)
このプロジェクトでは、研究者らは GPT-4o や Sonnet を含むさまざまな独自の LLM を研究しましたが、DeepSeek や Llama-3 などのオープン モデルの使用も調査しました。オープン モデルには、品質は若干低いものの、コストの削減、可用性の保証、透明性の向上、柔軟性の向上など、大きな利点があることがわかりました。
将来的に、研究者らは、提案された発見プロセスを使用して、オープンモデルを使用した閉ループシステムで自己改善型人工知能を生成することを目指しています。
今後の方向性
AI Scientist の当面の改善には、チャートやグラフをより適切に処理するためのビジュアル機能の統合、AI の出力を改善するための人間のフィードバックと対話の組み込み、AI Scientist がインターネットから新しいデータやデータを抽出できるようにすることが含まれる可能性があります。安全であれば、モデルは実験の範囲を自動的に拡張します。
さらに、AI 科学者は、自分の最良のアイデアをフォローアップしたり、自己参照的な方法で自分のコードに直接作業したりすることもできます。実際、プロジェクトのコードのほとんどは Aider によって書かれました。この枠組みを他の科学分野に拡張すれば、その影響はさらに拡大し、自動化された科学的発見の新時代への道が開かれる可能性があります。
重要なのは、将来の作業では、おそらく報告された結果のより詳細な自動検証を通じて、信頼性と幻覚の問題に対処する必要があるということです。これは、コードと実験を直接リンクするか、自動検証機能が結果を独立して再現できるかどうかを確認することによって実現できます。
エピローグ
AI Scientist は、機械学習における科学的発見の新時代の始まりを示します。AI エージェントの革新的な利点を AI 自体の研究プロセス全体にもたらし、科学者を無限の可能性を解き放つ世界に近づけます。創造性とイノベーションが世界で最も困難な問題を解決する世界。
最終的には、「私たちは、AI主導の研究者だけでなく、審査員、エリアチェア、会議全体も含めて、完全にAIによって推進される科学エコシステムを構想しています。しかし、私たちは人間の科学者の役割が弱まるとは考えていません。新しい技術に適応し、食物連鎖の上位に進むと、科学者の役割も変わるだろう」と研究者らは論文で述べている。
AI Scientist の現在の反復は、拡散モデリングやトランスフォーマーなどの実績のあるアイデアに基づいて革新する強力な能力を実証していますが、そのようなシステムが最終的に真にパラダイムを変えるアイデアを思いつくことができるかどうかは未解決の疑問のままです。
将来のバージョンの AI Scientists は、拡散モデリングと同じくらい影響力のあるアイデアを思いつくことができるでしょうか、あるいは次の Transformer アーキテクチャを思いつくことができるでしょうか?機械は最終的に、人工ニューラル ネットワークや情報理論と同じくらい基本的な概念を発明できるようになるのでしょうか?
「AI Scientist は人間の科学者にとって優れたパートナーになると信じていますが、それは時間が経てばわかります。」
GitHub オープンソース アドレス: http://github.com/SakanaAI/AI-Scientist
:https://arxiv.org/abs/2408.06292
参考コンテンツ:
http://sakana.ai/ai-scientist/
https://x.com/SakanaAILabs/status/ 1823178623513239992
https://mp.weixin.qq.com/s/-jjXBJAkdMEyl2JhRgwdaA
以上が初の完全自動科学発見 AI システム、Transformer 作者のスタートアップ、Sakana AI が AI Scientist を発表の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1667
1667
 14
1426
52
1328
25
1273
29
1255
24
14
1426
52
1328
25
1273
29
1255
24

 Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
このサイトは6月27日、JianyingはByteDanceの子会社であるFaceMeng Technologyによって開発されたビデオ編集ソフトウェアであり、Douyinプラットフォームに依存しており、基本的にプラットフォームのユーザー向けに短いビデオコンテンツを作成すると報告しました。 Windows、MacOS、その他のオペレーティング システム。 Jianyingは会員システムのアップグレードを正式に発表し、インテリジェント翻訳、インテリジェントハイライト、インテリジェントパッケージング、デジタルヒューマン合成などのさまざまなAIブラックテクノロジーを含む新しいSVIPを開始しました。価格的には、クリッピングSVIPの月額料金は79元、年会費は599元(当サイト注:月額49.9元に相当)、継続月額サブスクリプションは月額59元、継続年間サブスクリプションは、年間499元(月額41.6元に相当)です。さらに、カット担当者は、ユーザーエクスペリエンスを向上させるために、オリジナルのVIPに登録している人は、
 「Defect Spectrum」は、従来の欠陥検出の限界を打ち破り、超高精度かつ豊富なセマンティックな産業用欠陥検出を初めて実現します。
Jul 26, 2024 pm 05:38 PM
「Defect Spectrum」は、従来の欠陥検出の限界を打ち破り、超高精度かつ豊富なセマンティックな産業用欠陥検出を初めて実現します。
Jul 26, 2024 pm 05:38 PM
現代の製造において、正確な欠陥検出は製品の品質を確保するための鍵であるだけでなく、生産効率を向上させるための核心でもあります。ただし、既存の欠陥検出データセットには、実際のアプリケーションに必要な精度や意味論的な豊富さが欠けていることが多く、その結果、モデルが特定の欠陥カテゴリや位置を識別できなくなります。この問題を解決するために、広州香港科技大学と Simou Technology で構成されるトップの研究チームは、産業欠陥に関する詳細かつ意味的に豊富な大規模なアノテーションを提供する「DefectSpectrum」データセットを革新的に開発しました。表 1 に示すように、他の産業データ セットと比較して、「DefectSpectrum」データ セットは最も多くの欠陥注釈 (5438 個の欠陥サンプル) と最も詳細な欠陥分類 (125 個の欠陥カテゴリ) を提供します。
 結晶相問題を解決するための数百万の結晶データを使用したトレーニング、深層学習手法 PhAI が Science 誌に掲載
Aug 08, 2024 pm 09:22 PM
結晶相問題を解決するための数百万の結晶データを使用したトレーニング、深層学習手法 PhAI が Science 誌に掲載
Aug 08, 2024 pm 09:22 PM
編集者 |KX 今日に至るまで、単純な金属から大きな膜タンパク質に至るまで、結晶学によって決定される構造の詳細と精度は、他のどの方法にも匹敵しません。しかし、最大の課題、いわゆる位相問題は、実験的に決定された振幅から位相情報を取得することのままです。デンマークのコペンハーゲン大学の研究者らは、結晶相の問題を解決するための PhAI と呼ばれる深層学習手法を開発しました。数百万の人工結晶構造とそれに対応する合成回折データを使用して訓練された深層学習ニューラル ネットワークは、正確な電子密度マップを生成できます。この研究では、この深層学習ベースの非経験的構造解法は、従来の非経験的計算法とは異なり、わずか 2 オングストロームの解像度で位相問題を解決できることが示されています。これは、原子解像度で利用可能なデータのわずか 10% ~ 20% に相当します。
 NVIDIA 対話モデル ChatQA はバージョン 2.0 に進化し、コンテキストの長さは 128K と記載されています
Jul 26, 2024 am 08:40 AM
NVIDIA 対話モデル ChatQA はバージョン 2.0 に進化し、コンテキストの長さは 128K と記載されています
Jul 26, 2024 am 08:40 AM
オープンな LLM コミュニティは百花繚乱の時代です Llama-3-70B-Instruct、QWen2-72B-Instruct、Nemotron-4-340B-Instruct、Mixtral-8x22BInstruct-v0.1 などがご覧いただけます。優秀なパフォーマーモデル。しかし、GPT-4-Turboに代表される独自の大型モデルと比較すると、オープンモデルには依然として多くの分野で大きなギャップがあります。一般的なモデルに加えて、プログラミングと数学用の DeepSeek-Coder-V2 や視覚言語タスク用の InternVL など、主要な領域に特化したいくつかのオープン モデルが開発されています。
 Google AI が IMO 数学オリンピック銀メダルを獲得、数理推論モデル AlphaProof が発売、強化学習が復活
Jul 26, 2024 pm 02:40 PM
Google AI が IMO 数学オリンピック銀メダルを獲得、数理推論モデル AlphaProof が発売、強化学習が復活
Jul 26, 2024 pm 02:40 PM
AI にとって、数学オリンピックはもはや問題ではありません。木曜日、Google DeepMind の人工知能は、AI を使用して今年の国際数学オリンピック IMO の本当の問題を解決するという偉業を達成し、金メダル獲得まであと一歩のところまで迫りました。先週終了したばかりの IMO コンテストでは、代数、組合せ論、幾何学、数論を含む 6 つの問題が出題されました。 Googleが提案したハイブリッドAIシステムは4問正解で28点を獲得し、銀メダルレベルに達した。今月初め、UCLA 終身教授のテレンス・タオ氏が、100 万ドルの賞金をかけて AI 数学オリンピック (AIMO Progress Award) を宣伝したばかりだったが、予想外なことに、AI の問題解決のレベルは 7 月以前にこのレベルまで向上していた。 IMO に関する質問を同時に行うのが最も難しいのは、最も歴史が長く、規模が最も大きく、最も否定的な IMO です。
 PRO | なぜ MoE に基づく大規模モデルがより注目に値するのでしょうか?
Aug 07, 2024 pm 07:08 PM
PRO | なぜ MoE に基づく大規模モデルがより注目に値するのでしょうか?
Aug 07, 2024 pm 07:08 PM
2023 年には、AI のほぼすべての分野が前例のない速度で進化しています。同時に、AI は身体化されたインテリジェンスや自動運転などの主要な分野の技術的限界を押し広げています。マルチモーダルの流れのもと、AI大型モデルの主流アーキテクチャとしてのTransformerの状況は揺るがされるだろうか? MoE (専門家混合) アーキテクチャに基づく大規模モデルの検討が業界の新しいトレンドになっているのはなぜですか?ラージ ビジョン モデル (LVM) は、一般的な視覚における新たなブレークスルーとなる可能性がありますか? ...過去 6 か月間にリリースされたこのサイトの 2023 PRO メンバー ニュースレターから、上記の分野の技術トレンドと業界の変化を詳細に分析し、新しい分野での目標を達成するのに役立つ 10 の特別な解釈を選択しました。準備してください。この解釈は 2023 年の Week50 からのものです
 新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
編集者 |ScienceAI 質問応答 (QA) データセットは、自然言語処理 (NLP) 研究を促進する上で重要な役割を果たします。高品質の QA データ セットは、モデルの微調整に使用できるだけでなく、大規模言語モデル (LLM) の機能、特に科学的知識を理解し推論する能力を効果的に評価することもできます。現在、医学、化学、生物学、その他の分野をカバーする多くの科学 QA データ セットがありますが、これらのデータ セットにはまだいくつかの欠点があります。まず、データ形式は比較的単純で、そのほとんどが多肢選択式の質問であり、評価は簡単ですが、モデルの回答選択範囲が制限され、科学的な質問に回答するモデルの能力を完全にテストすることはできません。対照的に、自由回答型の Q&A
 Transformer に基づく浙江大学の化学逆合成予測モデルは、Nature サブジャーナルで 60.8% に達しました。
Aug 06, 2024 pm 07:34 PM
Transformer に基づく浙江大学の化学逆合成予測モデルは、Nature サブジャーナルで 60.8% に達しました。
Aug 06, 2024 pm 07:34 PM
編集者 | KX 逆合成は創薬や有機合成において重要なタスクであり、そのプロセスを高速化するために AI の使用が増えています。既存の AI 手法はパフォーマンスが不十分で、多様性が限られています。実際には、化学反応は多くの場合、反応物と生成物の間にかなりの重複を伴う局所的な分子変化を引き起こします。これに触発されて、浙江大学のHou Tingjun氏のチームは、単一ステップの逆合成予測を分子列編集タスクとして再定義し、標的分子列を反復的に改良して前駆体化合物を生成することを提案した。そして、高品質かつ多様な予測を実現できる編集ベースの逆合成モデルEditRetroを提案する。広範な実験により、このモデルが標準ベンチマーク データ セット USPTO-50 K で優れたパフォーマンスを達成し、トップ 1 の精度が 60.8% であることが示されました。
