貢献者は、この ACL カンファレンスから多くのものを得ました。
6日間のACL 2024がタイのバンコクで開催されています。 
ACL は、計算言語学と自然言語処理の分野におけるトップの国際会議で、国際計算言語学協会が主催し、毎年開催されます。 ACL は NLP 分野における学術的影響力において常に第一位にランクされており、CCF-A 推奨会議でもあります。 今年の ACL カンファレンスは 62 回目であり、NLP の分野で 400 以上の最先端の作品が寄せられました。昨日の午後、カンファレンスは最優秀論文およびその他の賞を発表しました。今回は、優秀論文賞7件(未発表2件)、最優秀テーマ論文賞1件、優秀論文賞35件が受賞しました。 このカンファレンスでは、リソース賞 3 件、ソーシャル インパクト賞 3 件、タイム テスト賞 2 件も受賞しました。 また、このカンファレンスの生涯功績賞は、ニューヨーク大学コンピューターサイエンス学部のラルフ・グリッシュマン教授に授与されました。 
論文 1: ミッション: インポッシブル言語モデル
- 著者: Julie Kallini、Isabel Papadimitriou、Richard Futre ll、カイル・マホワルド、クリストファー・ポッツ
- 機関: スタンフォード大学、カリフォルニア大学アーバイン校、テキサス大学オースティン校
- 論文リンク: https://arxiv.org/abs/2401.06416
論文紹介: Chomsky et al.大規模言語モデル (LLM) は、人間が学習できるかどうかに関係なく、同じ学習能力を備えていると考えられています。しかし、この主張を裏付ける実験的証拠はほとんど発表されていません。 この研究では、人間が言語を学習することが不可能なものを合成することを目的として、不自然な語順と文法規則を使用して英語データを体系的に変更することによってそれぞれ設計された、さまざまな複雑さの一連の合成言語を開発しました。 この研究では、GPT-2 小型モデルがこれらの「不可能な言語」を学習する能力を評価するために広範な評価実験を実施し、トレーニング全体のさまざまな段階でこれらの評価を実施して、各言語の学習プロセスを比較しました。この研究の中心的な発見は、GPT-2は英語に比べて「不可能な言語」を学習するのが難しいということであり、チョムスキーらの主張に異議を唱えている。 さらに重要なのは、この研究が、そのアプローチが実りある研究の流れを切り開き、LLMが認知および類型調査ツールとしてどのように使用できるかを理解するために、さまざまな「不可能な言語」でさまざまなLLMアーキテクチャをテストできるようにすることを望んでいることです。 。 
論文 2: なぜ変圧器にとって敏感な機能は難しいのですか?
- 著者: Michael Hahn、Mark Rofin
- 論文リンク: https://arxiv. /abs/2402.09963
要約: 実験研究により、PARITY などの単純な形式言語の計算を学習する際の永続的な困難や、学習の難しさなど、トランスフォーマーの学習可能性に関するさまざまなバイアスと制限が特定されました。低レベル(低次)関数。しかし、理論的な理解は依然として限られており、既存の表現理論は現実的な学習能力を過大評価または過小評価しています。 この研究は、変圧器アーキテクチャの下では、損失関数のランドスケープ (損失ランドスケープ) が入力空間の感度によって制限されることを証明しています。出力が入力文字列の多くの部分に敏感な変圧器は、隔離された場所に配置されます。パラメータ空間内の点が変化し、一般化の結果として感度が低くなります。 この研究は、理論が、低感度および低次数に対する汎化バイアス、およびパリティ長の汎化の困難など、変圧器の学習能力とバイアスに関する広範な実験観察を統合していることを理論的および実験的に示しています。これは、変圧器の誘導バイアスを理解するには、原理上の表現力だけでなく、損失関数の状況も研究する必要があることを示唆しています。 
論文 3: 拡散モデルを使用した Oracle Bone Language の解読
- 著者: Haisu Guan、Huanxin Yang、Xinyu Wang、Shengwei Han、他
- 機関: 華中大学科学技術、アデレード大学、安養師範大学、華南理工大学
- 論文リンク: https://arxiv.org/pdf/2406.00684
論文紹介: Oracle Bone Script (OBS) ) 約 3,000 年前の中国の殷王朝に起源を持つ言語は、多くの確立された文字体系よりも前の言語史の基礎です。何千もの碑文が発見されていますが、多くの甲骨は未解読のままであり、この古代言語は謎に包まれています。最新の AI テクノロジーの出現により、オラクル解読の新しい領域が開かれ、大規模なテキスト コーパスに大きく依存する従来の NLP 手法に課題が生じています。 この記事では、画像生成技術を使用して、Oracle の解読に最適化された拡散モデル、Oracle Bone Script Decipher (OBSD) を開発する新しい手法を紹介します。条件付き拡散戦略を利用して、OBSD は Oracle 解読のための重要な手がかりを生成し、AI を利用した古代言語分析の新しい方向性を切り開きました。有効性を検証するために、研究者らは Oracle データセットに対して広範な実験を実施し、その定量的な結果によって OBSD の有効性が証明されました。 
- 著者: Pietro Lesci、Clara Meister、Thomas Hofmann、Andreas Vlachos、Tiago Pimentel
- Instituteション: ケンブリッジ大学、チューリッヒ工科大学アカデミー
- 論文リンク: https://arxiv.org/pdf/2406.04327
論文紹介: 言語モデルにおける記憶を理解することには、モデルの訓練ダイナミクスの研究や予防など、実践的かつ社会的な意味があります。著作権侵害。これまでの研究では、記憶を「インスタンスを使用したトレーニング」と「そのインスタンスを予測するモデルの能力」の間の因果関係として定義されています。この定義は、反事実、つまりモデルがインスタンスを認識しなかった場合に何が起こったかを観察する能力に依存しています。既存の方法では、そのような反事実を計算効率よく正確に推定するのが困難です。さらに、これらの方法は通常、特定のモデル インスタンスのメモリではなく、モデル アーキテクチャのメモリを推定します。 この論文は、計量経済学的な差異設計に基づいて記憶を推定するための、原理に基づいた効率的な新しいアプローチを提案することで、重要なギャップを埋めています。この方法を使用すると、研究者はトレーニング プロセス全体を通じて少数のインスタンスでモデルの動作を観察するだけで、モデルのメモリ プロファイル、つまりトレーニング プロセス中のメモリの傾向を説明できます。 Pythia モデル スイートを使用した実験では、(i) メモリは大規模なモデルほど強力で永続的であること、(ii) データの順序と学習率によって決定されること、および (iii) さまざまなモデル サイズの傾向にわたって安定していることがわかりました。より大きなモデルのメモリは、より小さなモデルから予測できます。 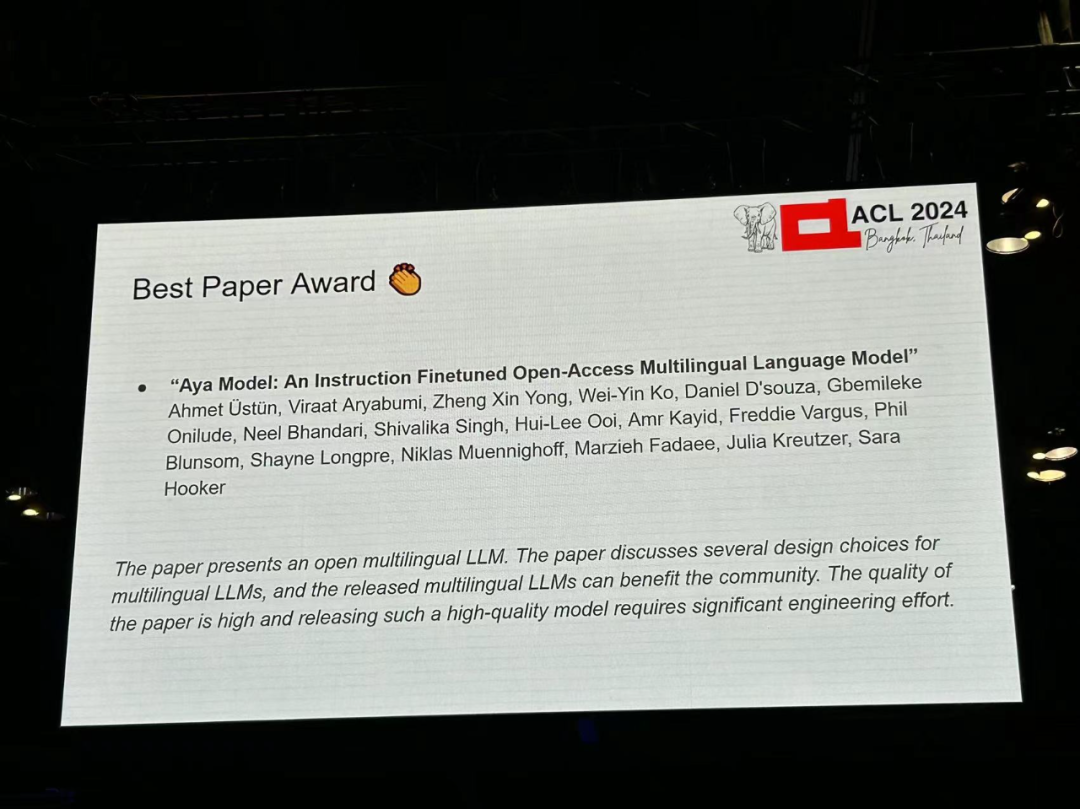
論文 5: アヤ モデル: 命令の微調整されたオープンアクセス多言語言語モデル
- 著者: Ahmet Üstün、Viraat Aryabumi、Zheng Xin Yong、Wei-ying Ko など
- 論文リンク: https://arxiv.org/pdf/2402.07827
論文紹介: 大規模言語モデル (LLM) における最近の進歩は、少数のデータに焦点を当てています-豊富な言語。他の言語を超えてブレークスルーへの道をどのように広げることができるでしょうか?この研究では、Aya という大規模な多言語生成言語モデルが導入されており、その 50% 以上が低リソースと考えられている 101 言語の指示に従います。 aya は、ほとんどのタスクで mT0 や BLOOMZ を上回り、2 倍の言語をカバーします。 さらに、この研究では広範な新しい評価スイートが導入され、最先端の多言語評価が 99 言語に拡張されています。最後に、この研究では、最適な微調整された混合物組成、データの枝刈り、モデルの毒性、バイアス、安全性についての詳細な調査が提供されます。 
- 著者: Liang Lu、Peiron Xie、David R. Mortensen
-
機関: CMU、University of南カリフォルニア
- 論文リンク: https://arxiv.org/pdf/2406.05930
受賞理由: この画期的な研究は、歴史言語学におけるプロトタイプ言語の再構築タスクを半自動化することを目的としており、新しい半言語を提案しています。監修されたアーキテクチャ。この方法は、「ネイティブ言語 - プロトタイプ」の再構築に「プロトタイプ - ネイティブ言語」の反映プロセスを導入することにより、以前の教師ありメソッドよりも優れた性能を発揮します。この論文は、ニューラル エンコーダ/デコーダなどの最新の計算モデルが言語学にどのように貢献できるかを示す良い例です。 
論文 7: 自然言語満足度: 問題分布の探索とトランスフォーマーベースの言語モデルの評価 (未公開) - 著者: Tharindu Madusanka、Ian Pratt-Hartmann、Riza Batista-Navarro
引用: この論文では、論理推論のための合成評価データセットについて明確に説明しています。これは、どの能力が測定されているかが明確でない大規模な推論データセットを適切に補完します。理論的には、一部のサブセットが他のサブセットよりも難しいと予想される理由が実際にあり、これらの予想は論文で検証されています。各カテゴリ内で、著者は真に困難なケースをサンプリングすることに特別な注意を払っています。
ACL Time Test Award は、自然言語処理と計算言語学の分野に長期的な影響を与えた名誉論文を 10 年前 (2014 年) と 2014 年に分けて表彰します。 25 年前 最初の 2 つの賞 (1999 年) は、年間最大 2 つの論文に授与されました。
 Paper 1: GloVe: Global Vectors for Word Representation
Paper 1: GloVe: Global Vectors for Word Representation
- Authors: Jeffrey Pennington, Richard Socher, Christopher D. Manning
- Institution: Stanford University
- Paper link: https:// /aclanthology.org/D14-1162.pdf
About the paper: Methods for learning vector space representations of words have been successful in capturing fine-grained semantic and syntactic rules using vector arithmetic, but syntactic rules still remain opaque. This study analyzes and clarifies what properties the model needs to have in order for syntactic rules to appear in word vectors. This research proposes a new global log-linear regression model - GloVe, designed to learn vector representations of words. This model combines the advantages of global matrix factorization and local context window methods. GloVe achieves the best performance of 75% on the word analogy task and outperforms related models on the word similarity task and named entity recognition. Reason for the award: Word embeddings were the cornerstone of deep learning methods for natural language processing (NLP) between 2013 and 2018, and continue to exert significant influence. Not only do they enhance the performance of NLP tasks, but they also have a significant impact on computational semantics, such as on word similarity and analogy. The two most influential word embedding methods are probably skip-gram/CBOW and GloVe. Compared with skip-gram, GloVe was proposed later. Its relative advantage lies in its conceptual simplicity, optimizing vector space similarity directly based on the distribution characteristics between words, rather than indirectly as a set of parameters from a simplified language modeling perspective. 
Paper 2: Measures of Distributional Similarity
- Institution: Cornell University
- Paper link: https://aclanthology .org/P99-1004.pdf
About the paper: The author studies distribution similarity measures with the aim of improving probability estimates of unseen co-occurrence events. Their contribution is threefold: an empirical comparison of a wide range of measures; a classification of similarity functions based on the information they contain; and the introduction of a new function that is superior in assessing underlying agent distributions . 
Lifetime Achievement AwardACL’s Lifetime Achievement Award is presented to Ralph Grishman. Ralph Grishman is a professor in the Department of Computer Science at New York University, focusing on research in the field of natural language processing (NLP). He is the founder of the Proteus Project, which has made significant contributions to information extraction (IE) and advanced the field. 
He also developed the Java Extraction Toolkit (JET), a widely used information extraction tool that provides multiple language analysis components such as sentence segmentation, named entity annotation, temporal expression annotation and normalization, part-of-speech tagging, part parsing and Coreference analysis. These components can be combined into pipelines according to different applications, which can be used for interactive analysis of single sentences or batch analysis of entire documents. In addition, JET provides simple tools for document annotation and display, and includes complete processes for extraction of entities, relationships, and events following the ACE (Automatic Content Extraction) specification. Professor Grishman’s work covers multiple core issues in NLP and has had a profound impact on modern language processing technology.
- Paper 1: Quantized Side Tuning: Fast and Memory-Efficient Tuning of Quantized Large Language Models
- Authors: Zhengxin Zhang, Dan Zhao, Xupeng Miao , Gabriele Oliaro, Zhihao Zhang, Qing Li, Yong Jiang, Zhihao Jia
- Institutions: CMU, Tsinghua University, Pengcheng Laboratory, etc.
-
Paper link: https://arxiv.org/pdf/2401.07159
- Paper 2: L-Eval: Instituting Standardized Evaluation for Long Context Language Models
- Authors: Chenxin An, Shansan Gong, Ming Zhong, Xingjian Zhao, Mukai Li, Jun Zhang, Lingpeng Kong, Xipeng Qiu
- Institutions: Fudan University, University of Hong Kong, University of Illinois at Urbana-Champaign, Shanghai AI Lab
- Paper link: https://arxiv.org/abs/2307.11088
- Paper 3: Causal-Guided Active Learning for Debiasing Large Language Models
- Paper link: https://openreview.net/forum?id=idp_1Q6F-lC
- Paper 4: CausalGym: Benchmarking causal interpretability methods on linguistic tasks
- Authors: Aryaman Arora, Dan Jurafsky, Christopher Potts
- Institution: Stanford University
-
Paper link: https://arxiv.org/abs/2402.12560
- Paper 5: Don't Hallucinate, Abstain: Identifying LLM Knowledge Gaps via Multi-LLM Collaboration
- Authors: Shangbin Feng, Weijia Shi, Yike Wang, Wenxuan Ding, Vidhisha Balachandran, Yulia Tsvetkov
- Institutions: University of Washington, University of California, Berkeley, Hong Kong University of Science and Technology, CMU
- Paper link: https://arxiv.org/abs/2402.00367
- Paper 6: Speech Translation with Speech Foundation Models and Large Language Models: What is There and What is Missing?
- Author: Marco Gaido, Sara Papi, Matteo Negri, Luisa Bentivogli
-
Institution: Bruno Kessler Foundation, Italy
- Paper link: https://arxiv.org/abs/2402.12025
- Paper 7: Must NLP be Extractive?
- Institution : Charles Darwin University
- Paper link: https://drive.google.com/file/d/1hvF7_WQrou6CWZydhymYFTYHnd3ZIljV/view
- Paper 8: IRCoder: Intermediate Representations Make Language Models Robust Multilingual Code Gen erators
- Authors: Indraneil Paul, Goran Glavaš, Iryna Gurevych
- Institution: TU Darmstadt, etc.
-
Paper link: https://arxiv.org/abs/2403.03894
- Paper 9: MultiLegalPile: A 689GB Multilingual Legal Corpus
- Authors: Matthias Stürmer, Veton Matoshi, etc.
- Institutions: University of Bern, Stanford University, etc.
- Paper link: https://arxiv.org/ pdf/2306.02069
- Paper 10: PsySafe: A Comprehensive Framework for Psychological-based Attack, Defense, and Evaluation of Multi-agent System Safety
- Authors: Zaibin Zhang , Yongting Zhang , Lijun Li , Hongzhi Gao, Lijun Wang, Huchuan Lu, Feng Zhao, Yu Qiao, Jing Shao
- Institution: Shanghai Artificial Intelligence Laboratory, Dalian University of Technology, University of Science and Technology of China
- Paper link: https://arxiv .org/pdf/2401.11880
- Paper 11: Can Large Language Models be Good Emotional Supporter? Mitigating Preference Bias on Emotional Support Conversation
- Author: Dongjin Kang, Sunghwan Kim, etc.
- Institution: Yonsei University, etc.
- Paper link: https://arxiv.org/pdf/2402.13211
- Paper 12: Political Compass or Spinning Arrow? Towards More Meaningful Evaluations for Values and Opinions in Large Language Models
- Authors: Paul Röttger, Valentin Hofmann, etc.
- Institutions: Bocconi University, Allen Institute for Artificial Intelligence, etc.
- Paper link: https://arxiv.org/pdf/ 2402.16786
- Paper 13: Same Task, More Tokens: the Impact of Input Length on the Reasoning Performance of Large Language Models
- Author: Mosh Levy, Alon Jacoby, Yoav Goldberg
- Institution: Pakistan Elan University, Allen Institute for Artificial Intelligence
- Paper link: https://arxiv.org/pdf/2402.14848
- Paper 14: Do Llamas Work in English? On the Latent Language of Multilingual Transformers
- Authors: Chris Wendler, Veniamin Veselovsky, etc.
-
- Paper 15: Getting Serious about Humor: Crafting Humor Datasets with Unfunny Large Language Models
Authors: Zachary Horvitz, Jingru Chen, etc.
Institutions: Columbia University, EPFL Paper link: https://arxiv.org/pdf/2403.00794
- Paper 16: Estimating the Level of Dialectness Predicts Inter-annotator Agreement in Multi-dialect Arabic Datasets
Author: Amr Keleg, Walid Magdy , Sharon Goldwater
Institution: University of EdinburghPaper link: https://arxiv.org/pdf/2405.11282
- Paper 17: G-DlG: Towards Gradient-based Dlverse and hiGh-quality Instruction Data Selection for Machine Translation
Authors: Xingyuan Pan, Luyang Huang, Liyan Kang, Zhicheng Liu, Yu Lu, Shanbo Cheng
Institution: ByteDance ResearchPaper link: https: https://arxiv.org/pdf/2405.12915 -
Paper link: https://openreview.net/pdf?id=9AV_zM56pwj
Paper 19: SPZ: A Semantic Perturbation-based Data Augmentation Method with Zonal-Mixing for Alzheimer's Disease Detection
Authors: FangFang Li, Cheng Huang, PuZhen Su, Jie Yin
Paper 20: Greed is All You Need: An Evaluation of Tokenizer Inference MethodsInstitution: Ben Guri, Negev Ann University, MIT
Authors: Omri Uzan, Craig W.Schmidt, Chris Tanner, Yuval Pinter
-
Paper link: https://arxiv.org/abs/2403.01289
Paper 21: Language Complexity and Speech Recognition Accuracy: Orthographic Complexity Hurts, Phonological Complexity Doesn't
-
Institution: University of Notre Dame (USA)
-
Author: Chihiro Taquchi, David Chiang
-
Paper link : https://arxiv.org/abs/2406.09202
Paper 22: Steering Llama 2 via Contrastive Activation Addition
-
Institutions: Anthropic, Harvard University, University of Göttingen (Germany), Center for Human-Compatible AI
-
Authors: Nina Rimsky, Nick Gabrieli, Julian Schulz, Meg Tong, Evan J Hubinger, Alexander Matt Turner
-
Paper link: https://arxiv.org/abs/2312.06681
Paper 23: EconAgent: Large Language Model-Empowered Agents for Simulating Macroeconomic Activities
-
Institution: Tsinghua University - Shenzhen International Graduate School, Tsinghua University
-
Authors: Nian Li, Chen Gao , Mingyu Li, Yong Li, Qingmin Liao
-
Paper link: https://arxiv.org/abs/2310.10436
Paper 24: M4LE: A Multi-Ability Multi-Range Multi- Task Multi-Domain Long-Context Evaluation Benchmark for Large Language Models
-
Institutions: Chinese University of Hong Kong, Huawei Noah's Ark Laboratory, Hong Kong University of Science and Technology
-
Authors: Wai-Chung Kwan, Xingshan Zeng, Yufei Wang, Yusen Sun, Liangyou Li, Lifeng Shang, Qun Liu, Kam-Fai Wong
-
Paper link: https://arxiv.org/abs/2310.19240
Paper 25: CHECKWHY: Causal Fact Verification via Argument Structure
-
Author: Jiasheng Si, Yibo Zhao, Yingjie Zhu, Haiyang Zhu, Wenpeng Lu, Deyu Zhou
- On Paper 26: On EFFICIENT and Statistics. U darmstadt , Apple Inc.
Paper link: https://arxiv.org/pdf/2405.11919
Paper 27: Emulated Disalignment: Safety Alignment for Large Language Models May Backfire!Author : Zhanhui Zhou, Jie Liu, Zhichen Dong, Jiaheng Liu, Chao Yang, Wanli Ouyang, Yu QiaoInstitution: Shanghai Artificial Intelligence Laboratory
Paper link: https://arxiv.org/pdf/2402.12343
Paper 28: IndicLLMSuite: A Blueprint for Creating Pre-training and Fine-Tuning Datasets for Indian LanguagesAuthor: Mohammed Safi Ur Rahman Khan, Priyam Mehta, Ananth Sankar, etc.-
Institutions: Nilekani Center at AI4Bharat, Indian Institute of Technology (Madras), Microsoft, etc.
Paper link: https://arxiv.org/pdf/2403.06350
Paper 29: MultiPICo: Multilingual Perspectivist lrony CorpusAuthors: Silvia Casola, Simona Frenda, Soda Marem Lo, Erhan Sezerer, etc. Institutions: University of Turin, aqua-tech, Amazon Development Center (Italy), etc.
Paper link: https://assets.amazon.science/08/83/9b686f424c89b08e8fa0a6e1d020/multipico-multilingual-perspectivist-irony-corpus.pdf
Paper 30: MMToM-QA: Multimodal Theory of Mind Question AnsweringAuthors: Chuanyang Jin, Yutong Wu, Jing Cao, jiannan Xiang, etc.Institutions: New York University, Harvard University, MIT, University of California, San Diego, University of Virginia, Johns Hopkins University
Paper link: https://arxiv.org/pdf/2401.08743
Paper 31: MAP's not dead yet: Uncovering true language model modes by conditioning away degeneracyAuthor: Davis Yoshida , Kartik Goyal, Kevin GimpelInstitution: Toyota Institute of Technology Chicago, Georgia Institute of Technology
Paper link: https://arxiv.org/pdf/2311.08817
Paper 32 : NounAtlas: Filling the Gap in Nominal Semantic Role LabelingAuthor: Roberto Navigli, Marco Lo Pinto, Pasquale Silvestri, etc.
Paper 33: The Earth is Flat because... lnvestigating LLMs' Belief towards Misinformation via PersuasiveConversationAuthors: Rongwu Xu, Brian S. Lin, Shujian Yang, Tiangi Zhang, etc.Institutions: Tsinghua University, Shanghai Jiao Tong University, Stanford University, Nanyang Technological University
Paper link: https://arxiv.org/pdf/2312.09085
Paper 34: Let's Go Real Talk: Spoken Dialogue Model for Face-to-Face ConversationAuthor: Se Jin Park, Chae Won Kim, Hyeongseop Rha, Minsu Kim, etc. Institution: Korea Advanced Institute of Science and Technology (KAIST)
Paper link: https://arxiv.org/pdf/2406.07867
Paper 35 :Word Embeddings Are Steers for Language ModelsAuthors: Chi Han, Jialiang Xu, Manling Li, Yi Fung, Chenkai Sun, Nan Jiang, Tarek F. Abdelzaher, Heng JiInstitution: University of Illinois at Urbana - Champaign
Paper link: https://arxiv.org/pdf/2305.12798
-
Best Theme Paper Award
Paper: OLMo: Accelerating the Science of Language Models
- Authors: Dirk Groeneveld, Iz Beltagy, etc.
- Institution: Allen Institute for Artificial Intelligence, University of Washington, etc.
- Paper link : https://arxiv.org/pdf/2402.00838
Citation: This work is an important step toward transparency and reproducibility in training large language models, something the community is achieving Much needed for progress (or at least for other researchers who are not industry giants to contribute). 3 papers won the Resource Paper Award. Paper 1: Latxa: An Open Language Model and Evaluation Suite for BasqueInstitution: University of the Basque Country, Spain
- Authors: Julen Etxaniz, Oscar Sainz, Naiara Perez, Itziar Aldabe, German Rigau, Eneko Agirre, Aitor Ormazabal, Mikel Artetxe, Aitor Soroa
- Link: https://arxiv.org/pdf/2403.20266
Case for award: This paper describes the corpus collection in detail , details of dataset evaluation. Although relevant to Basque language research, this methodology can be extended to the construction of large models for other low-resource languages. Paper 2: Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research
- Institution: Allen Institute for Artificial Intelligence, University of California, Berkeley, etc.
- Author: Luca Soldaini, Rodney Kinney, etc.
- Link: https://arxiv.org/abs/2402.00159
Reason for the award: This paper demonstrates the importance of data management when preparing data sets for training large language models . This provides very valuable insights to a wide range of people within the community. Paper 3: AppWorld: A Controllable World of Apps and People for Benchmarking Interactive Coding Agents
- Institutions: State University of New York at Stony Brook, Allen Institute for Artificial Intelligence, etc.
- Authors: Harsh Trivedi, Tushar Khot, etc.
- Link: https://arxiv.org/abs/2407.18901
Reasons for the award: This research is very important and amazing in building interactive environment simulation and evaluation work. It will encourage everyone to produce more hard-core dynamic benchmarks for the community. 3 papers won the Social Impact Award. Paper 1: How Johnny Can Persuade LLMs to Jailbreak Them: Rethinking Persuasion to Challenge AI Safety by Humanizing LLMs
-
Authors: Yi Zeng, Hongpeng Lin, Jingwen Zhang, Diyi Yang, etc.
- Institutions: Virginia Tech, Renmin University of China, University of California, Davis, Stanford University
- Paper link: https://arxiv.org/pdf/2401.06373
Reason for award: This article explores the topic of AI security - jailbreaking, examining a method developed within the field of social science research. The research is very interesting and has the potential to have a significant impact on the community. Paper 2: DIALECTBENCH: A NLP Benchmark for Dialects, Varieties, and Closely-Related Languages
-
Author: Fahim Faisal, Orevaoghene Ahia, Aarohi Srivastava, Kabir Ahuja, etc.
- Institutions: George Mason University, University of Washington, University of Notre Dame, RC Athena
- Paper link: https://arxiv.org/pdf/2403.11009
Citation for award: Dialect variation is an important area in NLP and artificial intelligence An understudied phenomenon. However, from the perspective of language and society, its research is of extremely high value and has important implications for applications. This paper proposes a very novel benchmark to study this problem in the LLM era. Paper 3: Having Beer after Prayer? Measuring Cultural Bias in Large Language Models
- Author: Tarek Naous, Michael J. Ryan, Alan Ritter, Wei Xu
- Institution: Georgia Institute of Technology
- Paper link: https://arxiv.org/pdf/2305.14456
Reason for the award: This article demonstrates an important issue in the LLM era: cultural bias.This paper examines the Arabic culture and locale and shows that we need to take cultural differences into account when designing LLMs. Therefore, the same study can be replicated in other cultures to generalize and assess whether other cultures are also affected by this issue.
以上がACL 2024 賞の発表: HuaTech による Oracle 解読に関する最優秀論文の 1 つ、GloVe Time Test Awardの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。



















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



