

データベース操作のマスター: インデックス、表示、バックアップ、リカバリ

導入
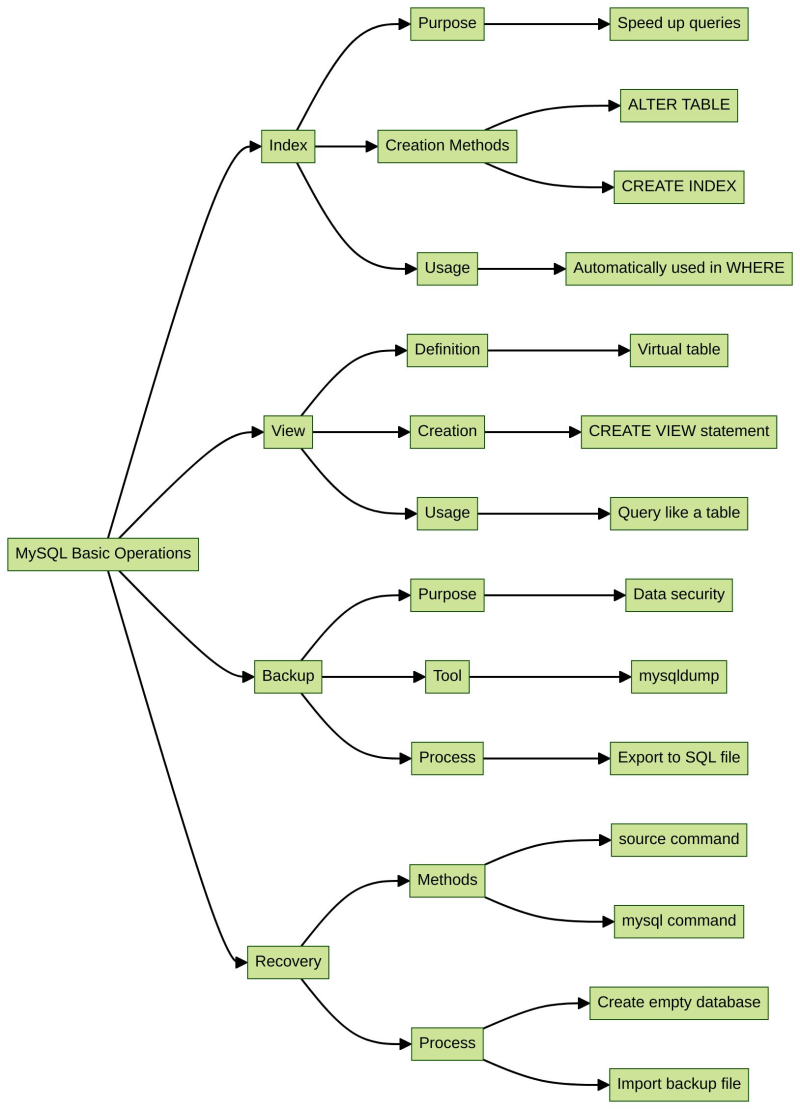
このラボでは、インデックス、ビュー、バックアップ、リカバリについて学び、実践します。これらの概念はデータベース管理者にとって非常に重要です。
学習目標
- インデックスの作成
- ビューの作成
- バックアップとリカバリ
準備
始める前に、環境を準備する必要があります。
MySQL サービスを開始し、root としてログインします。
cd ~/project sudo service mysql start mysql -u root
ファイルにデータをロードします。データベースを構築するには、MySQL コンソールに次のコマンドを入力する必要があります:
source ~/project/init-database.txt
索引
インデックスはテーブル関連の構造です。その役割は本のディレクトリに相当します。ディレクトリ内のページ番号に従ってコンテンツをすばやく見つけることができます。
インデックスが存在せず、レコード数が多いテーブルに対してクエリを実行する場合、検索条件に一致するすべてのレコードを 1 つずつ取り出して、条件に一致するレコードを返します。 。これには非常に時間がかかり、多数のディスク I/O 操作が発生します。
テーブルにインデックスが存在する場合、インデックス値によってテーブル内のデータをすばやく見つけることができるため、クエリ プロセスが大幅に高速化されます。
特定の列にインデックスを設定するには 2 つの方法があります:
ALTER TABLE table name ADD INDEX index name (column name); CREATE INDEX index name ON table name (column name);
これら 2 つのステートメントを使用してインデックスを作成しましょう。
従業員テーブルの id 列に idx_id インデックスを構築します。
ALTER TABLE employee ADD INDEX idx_id (id);
従業員テーブルの name 列に idx_name インデックスを構築します
CREATE INDEX idx_name ON employee (name);
クエリプロセスを高速化するためにインデックスを使用します。データが少ないとその不思議な力を感じることができません。ここでは、コマンド SHOW INDEX FROM table name を使用して、作成したばかりのインデックスを表示しましょう。
SHOW INDEX FROM employee;
MariaDB [mysql_labex]> ALTER TABLE employee ADD INDEX idx_id (id); Query OK, 0 rows affected (0.005 sec) Records: 0 Duplicates: 0 Warnings: 0 MariaDB [mysql_labex]> SHOW INDEX FROM employee; +----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Ignored | +----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+ | employee | 0 | PRIMARY | 1 | id | A | 5 | NULL | NULL | | BTREE | | | NO | | employee | 0 | phone | 1 | phone | A | 5 | NULL | NULL | | BTREE | | | NO | | employee | 1 | emp_fk | 1 | in_dpt | A | 5 | NULL | NULL | | BTREE | | | NO | | employee | 1 | idx_id | 1 | id | A | 5 | NULL | NULL | | BTREE | | | NO | | employee | 1 | idx_name | 1 | name | A | 5 | NULL | NULL | YES | BTREE | | | NO | +----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+ 5 rows in set (0.000 sec)
SELECT ステートメントを使用してクエリを実行すると、WHERE 条件によってインデックスが存在するかどうかが自動的に判断されます。
ビュー
ビューは、1 つ以上のテーブルから派生した仮想テーブルです。これは、データベース内のデータ全体を表示する必要がないように、システムによって提供される特別なデータを表示できるウィンドウのようなものです。興味のあるものに集中できます。
「ビューは仮想テーブルです」を解釈するにはどうすればよいですか?
- ビューの定義のみがデータベースに保存され、そのデータは元のテーブルに保存されます。
- ビューを使用してデータをクエリすると、データベースはそれに応じて元のテーブルからデータを抽出します。
- View のデータは元のテーブルに格納されている内容に依存するため、テーブル内のデータが変更されると、View に表示される内容も変更されます。
- ビューをテーブルとして扱います。
ビューの作成に使用されるステートメント形式:
CREATE VIEW view name (column a, column b, column c) AS SELECT column 1, column 2, column 3 FROM table name;
ステートメントから、後半部分が SELECT ステートメントであることがわかります。これは、View を複数のテーブル上に構築することもできることを意味します。必要なのは、サブクエリを使用するか、SELECT ステートメントで結合することだけです。
次に、v_emp という 3 つの列 v_name、v_age、v_phone:
を含む単純なビューを作成しましょう。
CREATE VIEW v_emp (v_name,v_age,v_phone) AS SELECT name,age,phone FROM employee;
と入力します。
SELECT * FROM v_emp;
MariaDB [mysql_labex]> CREATE VIEW v_emp (v_name,v_age,v_phone) AS SELECT name,age,phone FROM employee; Query OK, 0 rows affected (0.003 sec) MariaDB [mysql_labex]> SELECT * FROM v_emp; +--------+-------+---------+ | v_name | v_age | v_phone | +--------+-------+---------+ | Tom | 26 | 119119 | | Jack | 24 | 120120 | | Jobs | NULL | 19283 | | Tony | NULL | 102938 | | Rose | 22 | 114114 | +--------+-------+---------+ 5 rows in set (0.000 sec)
バックアップ
セキュリティ上の理由から、データベース管理においてバックアップは非常に重要です。
エクスポートされたファイルはデータベース内のデータのみを保存しますが、バックアップはデータ、制約、インデックス、ビューなどを含むデータベース構造全体を新しいファイルに保存します。
mysqldump は、バックアップ用の MySQL の実用的なプログラムです。 CREATE、INSERT など、データベースを最初から再作成するために必要なすべてのコマンドを含む SQL スクリプト ファイルを生成します。
mysqldump バックアップを使用するためのステートメント:
mysqldump -u root database name > backup file name; #backup entire database mysqldump -u root database name table name > backup file name; #backup the entire table
データベース mysql_labex 全体をバックアップしてみてください。ファイルに bak.sql という名前を付けます。まず Ctrl+Z を押して MySQL コンソールを終了し、次にターミナルを開いてコマンドを入力します。
cd ~/project/ mysqldump -u root mysql_labex > bak.sql;
コマンド「ls」を使用すると、バックアップ ファイル bak.sql が表示されます。
cat bak.sql
-- MariaDB dump 10.19 Distrib 10.6.12-MariaDB, for debian-linux-gnu (x86_64) -- -- Host: localhost Database: mysql_labex -- ------------------------------------------------------ -- Server version 10.6.12-MariaDB-0ubuntu0.22.04.1 /*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */; /*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */; /*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */; /*!40101 SET NAMES utf8 */; /*!40103 SET @OLD_TIME_ZONE=@@TIME_ZONE */; /*!40103 SET TIME_ZONE='+00:00' */; /*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */; /*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */; /*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */; /*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */; ……
回復
このラボの前半で、バックアップ ファイルを使用してデータベースを回復する練習をしました。次のようなコマンドを使用しました:
source ~/project/init-database.txt
このステートメントは、import-database.txt ファイルから mysql_labex データベースを復元します。
データベースを回復する別の方法がありますが、その前に、test という名前の空のデータベースを作成する必要があります。
mysql -u root CREATE DATABASE test;
MariaDB [(none)]> CREATE DATABASE test; Query OK, 1 row affected (0.000 sec) MariaDB [(none)]> SHOW DATABASES; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | mysql_labex | | performance_schema | | sys | | test | +--------------------+ 6 rows in set (0.000 sec)
Ctrl+Z で MySQL を終了します。 bak.sql をリカバリしてデータベースを テストします:
mysql -u root test < bak.sql
テスト データベース内のテーブルを表示するコマンドを入力することで、リカバリが成功したかどうかを確認できます。
mysql -u root USE test SHOW TABLES
MariaDB [(none)]> USE test; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed MariaDB [test]> SHOW TABLES; +----------------+ | Tables_in_test | +----------------+ | department | | employee | | project | | table_1 | +----------------+ 4 rows in set (0.000 sec)
We can see that the 4 tables have already been recovered to the test database.
Summary
Congratulations! You've completed the lab on other basic operations in MySQL. You've learned how to create indexes, views, and how to backup and recover a database.
? Practice Now: Other Basic Operations
Want to Learn More?
- ? Learn the latest MySQL Skill Trees
- ? Read More MySQL Tutorials
- ? Join our Discord or tweet us @WeAreLabEx
以上がデータベース操作のマスター: インデックス、表示、バックアップ、リカバリの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1672
1672
 14
1428
52
1332
25
1276
29
1256
24
14
1428
52
1332
25
1276
29
1256
24

 MySQLの役割:Webアプリケーションのデータベース
Apr 17, 2025 am 12:23 AM
MySQLの役割:Webアプリケーションのデータベース
Apr 17, 2025 am 12:23 AM
WebアプリケーションにおけるMySQLの主な役割は、データを保存および管理することです。 1.MYSQLは、ユーザー情報、製品カタログ、トランザクションレコード、その他のデータを効率的に処理します。 2。SQLクエリを介して、開発者はデータベースから情報を抽出して動的なコンテンツを生成できます。 3.MYSQLは、クライアントサーバーモデルに基づいて機能し、許容可能なクエリ速度を確保します。
 Innodb Redoログの役割を説明し、ログを元に戻します。
Apr 15, 2025 am 12:16 AM
Innodb Redoログの役割を説明し、ログを元に戻します。
Apr 15, 2025 am 12:16 AM
INNODBは、レドログと非論的なものを使用して、データの一貫性と信頼性を確保しています。 1.レドログは、クラッシュの回復とトランザクションの持続性を確保するために、データページの変更を記録します。 2.Undologsは、元のデータ値を記録し、トランザクションロールバックとMVCCをサポートします。
 MySQL対その他のプログラミング言語:比較
Apr 19, 2025 am 12:22 AM
MySQL対その他のプログラミング言語:比較
Apr 19, 2025 am 12:22 AM
他のプログラミング言語と比較して、MySQLは主にデータの保存と管理に使用されますが、Python、Java、Cなどの他の言語は論理処理とアプリケーション開発に使用されます。 MySQLは、データ管理のニーズに適した高性能、スケーラビリティ、およびクロスプラットフォームサポートで知られていますが、他の言語は、データ分析、エンタープライズアプリケーション、システムプログラミングなどのそれぞれの分野で利点があります。
 初心者向けのMySQL:データベース管理を開始します
Apr 18, 2025 am 12:10 AM
初心者向けのMySQL:データベース管理を開始します
Apr 18, 2025 am 12:10 AM
MySQLの基本操作には、データベース、テーブルの作成、およびSQLを使用してデータのCRUD操作を実行することが含まれます。 1.データベースの作成:createdatabasemy_first_db; 2。テーブルの作成:createTableBooks(idintauto_incrementprimarykey、titlevarchary(100)notnull、authorvarchar(100)notnull、published_yearint); 3.データの挿入:InsertIntoBooks(タイトル、著者、公開_year)VA
 InnoDBバッファープールとそのパフォーマンスの重要性を説明してください。
Apr 19, 2025 am 12:24 AM
InnoDBバッファープールとそのパフォーマンスの重要性を説明してください。
Apr 19, 2025 am 12:24 AM
Innodbbufferpoolは、データをキャッシュしてページをインデックス作成することにより、ディスクI/Oを削減し、データベースのパフォーマンスを改善します。その作業原則には次のものが含まれます。1。データ読み取り:Bufferpoolのデータを読む。 2。データの書き込み:データを変更した後、bufferpoolに書き込み、定期的にディスクに更新します。 3.キャッシュ管理:LRUアルゴリズムを使用して、キャッシュページを管理します。 4.読みメカニズム:隣接するデータページを事前にロードします。 BufferPoolのサイジングと複数のインスタンスを使用することにより、データベースのパフォーマンスを最適化できます。
 MySQL対その他のデータベース:オプションの比較
Apr 15, 2025 am 12:08 AM
MySQL対その他のデータベース:オプションの比較
Apr 15, 2025 am 12:08 AM
MySQLは、Webアプリケーションやコンテンツ管理システムに適しており、オープンソース、高性能、使いやすさに人気があります。 1)PostgreSQLと比較して、MySQLは簡単なクエリと高い同時読み取り操作でパフォーマンスが向上します。 2)Oracleと比較して、MySQLは、オープンソースと低コストのため、中小企業の間でより一般的です。 3)Microsoft SQL Serverと比較して、MySQLはクロスプラットフォームアプリケーションにより適しています。 4)MongoDBとは異なり、MySQLは構造化されたデータおよびトランザクション処理により適しています。
 MySQL:構造化データとリレーショナルデータベース
Apr 18, 2025 am 12:22 AM
MySQL:構造化データとリレーショナルデータベース
Apr 18, 2025 am 12:22 AM
MySQLは、テーブル構造とSQLクエリを介して構造化されたデータを効率的に管理し、外部キーを介してテーブル間関係を実装します。 1.テーブルを作成するときにデータ形式と入力を定義します。 2。外部キーを使用して、テーブル間の関係を確立します。 3。インデックス作成とクエリの最適化により、パフォーマンスを改善します。 4.データベースを定期的にバックアップおよび監視して、データのセキュリティとパフォーマンスの最適化を確保します。
 MySQLの学習:新しいユーザー向けの段階的なガイド
Apr 19, 2025 am 12:19 AM
MySQLの学習:新しいユーザー向けの段階的なガイド
Apr 19, 2025 am 12:19 AM
MySQLは、データストレージ、管理、分析に適した強力なオープンソースデータベース管理システムであるため、学習する価値があります。 1)MySQLは、SQLを使用してデータを操作するリレーショナルデータベースであり、構造化されたデータ管理に適しています。 2)SQL言語はMySQLと対話するための鍵であり、CRUD操作をサポートします。 3)MySQLの作業原則には、クライアント/サーバーアーキテクチャ、ストレージエンジン、クエリオプティマイザーが含まれます。 4)基本的な使用には、データベースとテーブルの作成が含まれ、高度な使用にはJoinを使用してテーブルの参加が含まれます。 5)一般的なエラーには、構文エラーと許可の問題が含まれ、デバッグスキルには、構文のチェックと説明コマンドの使用が含まれます。 6)パフォーマンスの最適化には、インデックスの使用、SQLステートメントの最適化、およびデータベースの定期的なメンテナンスが含まれます。
