

タンパク質と DNA の結合特異性を予測するために、USC チームが新しい幾何学的ディープラーニング手法を開発

編集者 | 大根の皮
タンパク質と DNA の結合特異性を予測することは、遺伝子制御を理解するのに役立つ、困難ですが重要な作業です。タンパク質-DNA複合体は通常、選択されたDNA標的に結合しますが、タンパク質はさまざまな程度の結合特異性で広範囲のDNA配列に結合します。この情報は、単一の構造内では直接アクセスできません。
この情報を得るために、南カリフォルニア大学とワシントン大学の研究者は、タンパク質-DNA 構造に基づいて結合特異性を予測するように設計された幾何学的な深層学習モデルである Deep Binding Specificity Predictor (DeepPBS) を提案しました。
DeepPBS は、界面残基の解釈可能なタンパク質重原子重要度スコアを抽出できます。これらのスコアは、タンパク質残基レベルで集計した場合の突然変異誘発実験によって検証されました。 DeepPBS を特定の DNA 配列をターゲットとする設計されたタンパク質に適用すると、実験的に測定された結合特異性を予測できることが示されました。
この研究は「タンパク質-DNA結合特異性の幾何学的深層学習」と題され、2024年8月5日に「Nature Methods」に掲載されました。

転写因子は、特定の DNA 配列に結合することによって生命プロセスを制御します。この結合メカニズムには、静電相互作用、デオキシリボースのスタッキング効果、および水素結合の形成が含まれます。
タンパク質-DNA の構造情報は通常、X 線結晶構造解析、核磁気共鳴分光法、極低温電子顕微鏡などの実験的方法を通じて取得され、タンパク質データ バンク (PDB) に保存されます。これらの構造は通常、結合した DNA 配列とその物理化学的相互作用を示しますが、考えられるすべての結合配列を網羅しているわけではありません。
一方、タンパク質結合マイクロアレイやSELEX-seqなどのハイスループット実験では、潜在的な結合配列の範囲を捕捉できますが、構造情報が不足しています。
したがって、転写因子の結合特異性を完全に理解するには、構造データとハイスループット実験データを組み合わせることが重要です。
現在、タンパク質ファミリー内の特定のタンパク質配列の結合特異性を予測することは、依然として困難で未解決の問題です。この困難は、結合コンテキストの構造変化と広大な機構の多様性によってさらに悪化します。
「タンパク質-DNA複合体の構造には、通常単一のDNA配列に結合するタンパク質が含まれています。遺伝子制御を理解するには、任意のDNA配列またはゲノム領域に対するタンパク質の結合特異性を理解することが重要です。」南カリフォルニア大学のレモ・ローズ教授。
最新の研究では、南カリフォルニア大学とワシントン大学の研究者が結合特異性ディーププレディクター (DeepPBS) を導入しました。
Rohs 氏は次のように説明しました。「DeepPBS は、タンパク質と DNA の結合特異性を明らかにするためのハイスループット シーケンスや構造生物学の実験に代わる人工知能ツールです。」 図: DeepPBS フレームワークの概略図。 (出典: 論文)
この深層学習モデルは、タンパク質-DNA 相互作用の物理化学的および幾何学的コンテキストを捕捉して、特定のタンパク質-DNA 構造に基づいて位置重み行列 (PWM) として表現される結合特異性を予測することを目的としています。 DeepPBS はタンパク質ファミリー全体で機能し、構造決定と結合特異性決定実験の間の橋渡しとして機能します。 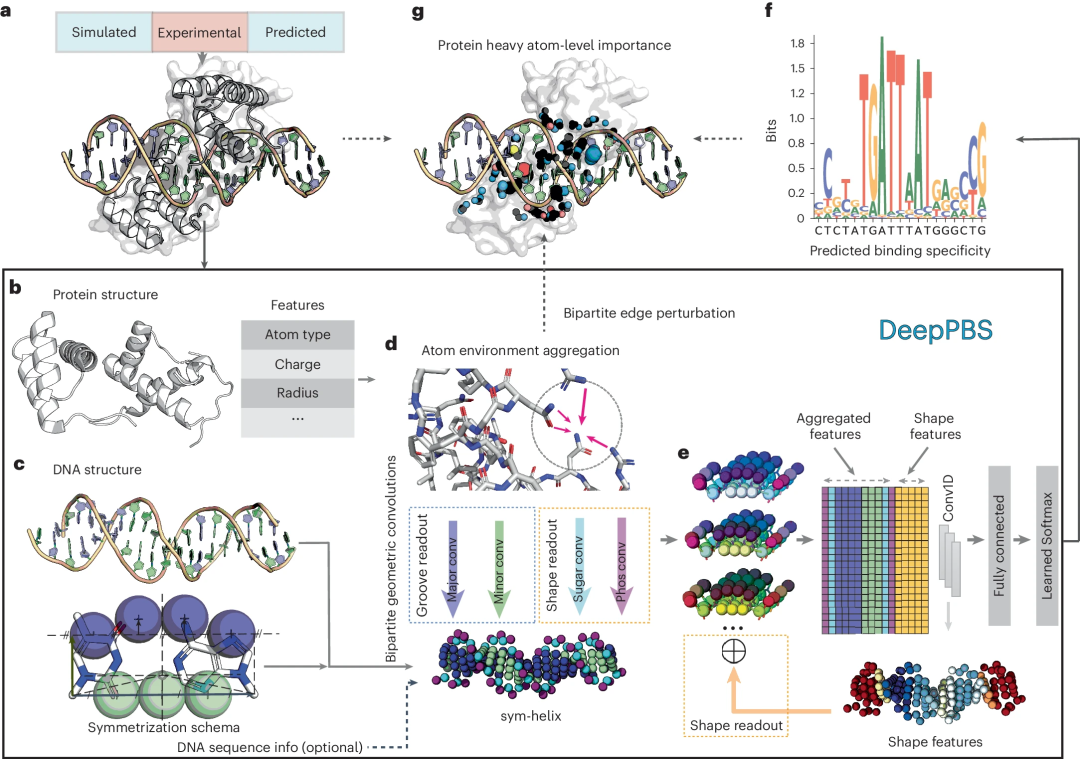
図: タンパク質ファミリー間の結合特異性を予測するための DeepPBS のパフォーマンス。 (出典: 論文)
DeepPBS への入力は実験構造に限定されません。 AlphaFold、OpenFold、RoseTTAFold などのタンパク質構造予測手法や、RoseTTAFoldNA (RFNA)、RoseTTAFold All-Atom、MELD-DNA、AlphaFold3 などのタンパク質-DNA 複合モデラーの急速な開発により、構造データが利用できるようになりました。分析 その数は指数関数的に増加しています。 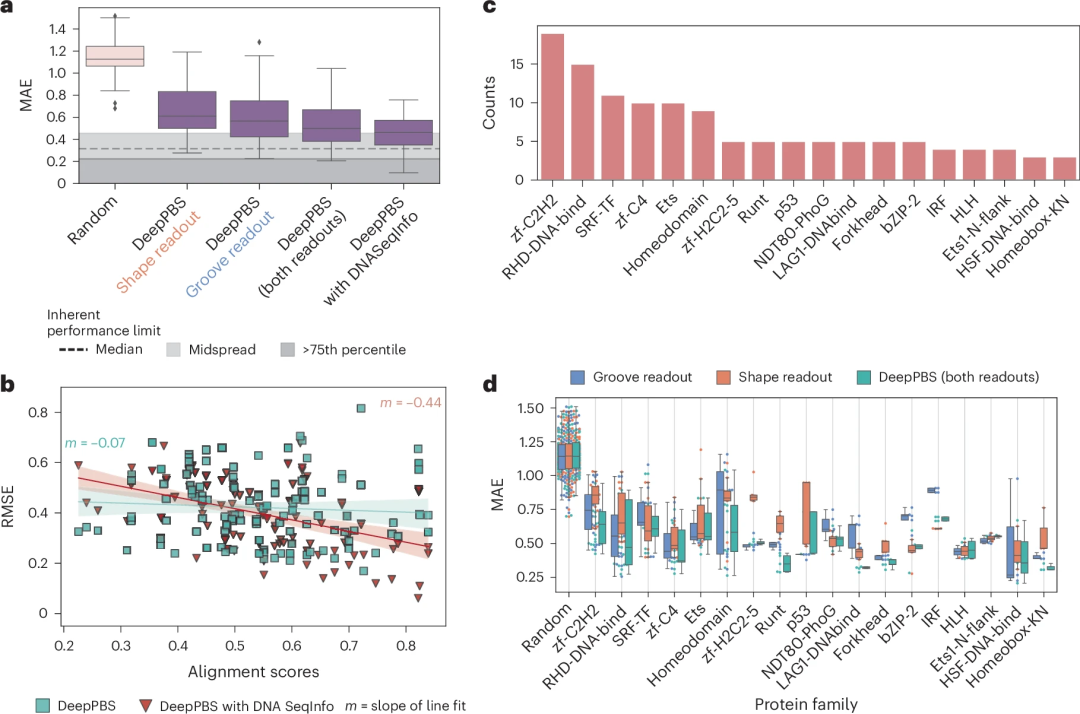
図: タンパク質-DNA 複合体の構造予測における DeepPBS の応用。 (出典: 論文)
解釈可能性の観点からは、DNA と相互作用するタンパク質内のさまざまな重原子の「相対重要度」(RI) スコアを DeepPBS から抽出できます。
がんの発生に重要なタンパク質のケーススタディとして、研究者らはこれらの RI スコアを通じて p53-DNA インターフェースを分析し、検証のために既存の文献にリンクしました。
そして、DeepPBS スコアは既存の知識とよく一致しており、アラニン スキャニング突然変異誘発実験と合理的な一致をもたらすように集計できます。
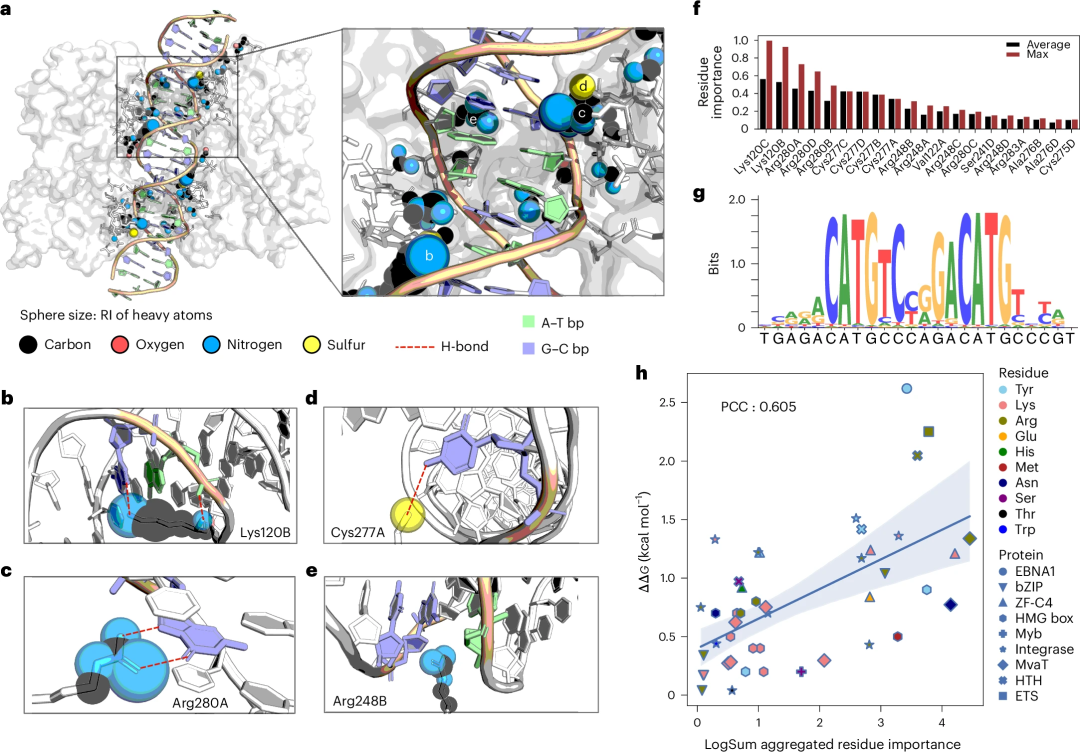
図: 研究および実験的検証を行うための例として、p53-DNA インターフェースの DeepPBS 重要度スコアの視覚化を取り上げます。 (出典: 論文)
追加の原理実証研究では、研究者らは、構造設計と DNA 突然変異誘発研究を組み合わせた最近の実験から得られた、特定の DNA 配列をターゲットとするインシリコ設計のタンパク質-DNA 複合体に DeepPBS を適用しました。 DeepPBS は、分子シミュレーションの軌跡の分析にも使用できます。
「研究者にとって、よく研究されているタンパク質ファミリーに限定されず、すべてのタンパク質に有効な方法を見つけることが重要です。この方法により、新しいタンパク質を設計することも可能になります。」と Rohs 氏は言いました。
図: 特定の DNA 配列をターゲットとするコンピュータで設計された HTH スキャフォールドに DeepPBS を適用する。 (出典: 論文)
DeepPBS の現在のバージョンには固有の制限があります。二本鎖 DNA 用に調整されていますが、一本鎖 DNA、RNA、または化学修飾された塩基にはまだ機能しません。
ただし、このモデルは、これらのさまざまなシナリオや他のポリマー間相互作用、さらには機構的な突然変異にも対応できるように拡張される可能性があります。 DeepPBS アーキテクチャは、アプリケーションとエンジニアリングの強化に関して最適化および拡張できます。
それにもかかわらず、Rohs 氏は、DeepPBS には幅広い用途があるだろうと述べました。この新しい研究アプローチは、がん細胞の特定の変異を標的とする新薬や治療法の設計を加速するとともに、合成生物学における新たな発見やRNA研究への応用につながる可能性があります。
DeepPBS: https://deeppbs.usc.edu
以上がタンパク質と DNA の結合特異性を予測するために、USC チームが新しい幾何学的ディープラーニング手法を開発の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1670
1670
 14
1428
52
1329
25
1276
29
1256
24
14
1428
52
1329
25
1276
29
1256
24

 Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
このサイトは6月27日、JianyingはByteDanceの子会社であるFaceMeng Technologyによって開発されたビデオ編集ソフトウェアであり、Douyinプラットフォームに依存しており、基本的にプラットフォームのユーザー向けに短いビデオコンテンツを作成すると報告しました。 Windows、MacOS、その他のオペレーティング システム。 Jianyingは会員システムのアップグレードを正式に発表し、インテリジェント翻訳、インテリジェントハイライト、インテリジェントパッケージング、デジタルヒューマン合成などのさまざまなAIブラックテクノロジーを含む新しいSVIPを開始しました。価格的には、クリッピングSVIPの月額料金は79元、年会費は599元(当サイト注:月額49.9元に相当)、継続月額サブスクリプションは月額59元、継続年間サブスクリプションは、年間499元(月額41.6元に相当)です。さらに、カット担当者は、ユーザーエクスペリエンスを向上させるために、オリジナルのVIPに登録している人は、
 「Defect Spectrum」は、従来の欠陥検出の限界を打ち破り、超高精度かつ豊富なセマンティックな産業用欠陥検出を初めて実現します。
Jul 26, 2024 pm 05:38 PM
「Defect Spectrum」は、従来の欠陥検出の限界を打ち破り、超高精度かつ豊富なセマンティックな産業用欠陥検出を初めて実現します。
Jul 26, 2024 pm 05:38 PM
現代の製造において、正確な欠陥検出は製品の品質を確保するための鍵であるだけでなく、生産効率を向上させるための核心でもあります。ただし、既存の欠陥検出データセットには、実際のアプリケーションに必要な精度や意味論的な豊富さが欠けていることが多く、その結果、モデルが特定の欠陥カテゴリや位置を識別できなくなります。この問題を解決するために、広州香港科技大学と Simou Technology で構成されるトップの研究チームは、産業欠陥に関する詳細かつ意味的に豊富な大規模なアノテーションを提供する「DefectSpectrum」データセットを革新的に開発しました。表 1 に示すように、他の産業データ セットと比較して、「DefectSpectrum」データ セットは最も多くの欠陥注釈 (5438 個の欠陥サンプル) と最も詳細な欠陥分類 (125 個の欠陥カテゴリ) を提供します。
 NVIDIA 対話モデル ChatQA はバージョン 2.0 に進化し、コンテキストの長さは 128K と記載されています
Jul 26, 2024 am 08:40 AM
NVIDIA 対話モデル ChatQA はバージョン 2.0 に進化し、コンテキストの長さは 128K と記載されています
Jul 26, 2024 am 08:40 AM
オープンな LLM コミュニティは百花繚乱の時代です Llama-3-70B-Instruct、QWen2-72B-Instruct、Nemotron-4-340B-Instruct、Mixtral-8x22BInstruct-v0.1 などがご覧いただけます。優秀なパフォーマーモデル。しかし、GPT-4-Turboに代表される独自の大型モデルと比較すると、オープンモデルには依然として多くの分野で大きなギャップがあります。一般的なモデルに加えて、プログラミングと数学用の DeepSeek-Coder-V2 や視覚言語タスク用の InternVL など、主要な領域に特化したいくつかのオープン モデルが開発されています。
 結晶相問題を解決するための数百万の結晶データを使用したトレーニング、深層学習手法 PhAI が Science 誌に掲載
Aug 08, 2024 pm 09:22 PM
結晶相問題を解決するための数百万の結晶データを使用したトレーニング、深層学習手法 PhAI が Science 誌に掲載
Aug 08, 2024 pm 09:22 PM
編集者 |KX 今日に至るまで、単純な金属から大きな膜タンパク質に至るまで、結晶学によって決定される構造の詳細と精度は、他のどの方法にも匹敵しません。しかし、最大の課題、いわゆる位相問題は、実験的に決定された振幅から位相情報を取得することのままです。デンマークのコペンハーゲン大学の研究者らは、結晶相の問題を解決するための PhAI と呼ばれる深層学習手法を開発しました。数百万の人工結晶構造とそれに対応する合成回折データを使用して訓練された深層学習ニューラル ネットワークは、正確な電子密度マップを生成できます。この研究では、この深層学習ベースの非経験的構造解法は、従来の非経験的計算法とは異なり、わずか 2 オングストロームの解像度で位相問題を解決できることが示されています。これは、原子解像度で利用可能なデータのわずか 10% ~ 20% に相当します。
 Google AI が IMO 数学オリンピック銀メダルを獲得、数理推論モデル AlphaProof が発売、強化学習が復活
Jul 26, 2024 pm 02:40 PM
Google AI が IMO 数学オリンピック銀メダルを獲得、数理推論モデル AlphaProof が発売、強化学習が復活
Jul 26, 2024 pm 02:40 PM
AI にとって、数学オリンピックはもはや問題ではありません。木曜日、Google DeepMind の人工知能は、AI を使用して今年の国際数学オリンピック IMO の本当の問題を解決するという偉業を達成し、金メダル獲得まであと一歩のところまで迫りました。先週終了したばかりの IMO コンテストでは、代数、組合せ論、幾何学、数論を含む 6 つの問題が出題されました。 Googleが提案したハイブリッドAIシステムは4問正解で28点を獲得し、銀メダルレベルに達した。今月初め、UCLA 終身教授のテレンス・タオ氏が、100 万ドルの賞金をかけて AI 数学オリンピック (AIMO Progress Award) を宣伝したばかりだったが、予想外なことに、AI の問題解決のレベルは 7 月以前にこのレベルまで向上していた。 IMO に関する質問を同時に行うのが最も難しいのは、最も歴史が長く、規模が最も大きく、最も否定的な IMO です。
 PRO | なぜ MoE に基づく大規模モデルがより注目に値するのでしょうか?
Aug 07, 2024 pm 07:08 PM
PRO | なぜ MoE に基づく大規模モデルがより注目に値するのでしょうか?
Aug 07, 2024 pm 07:08 PM
2023 年には、AI のほぼすべての分野が前例のない速度で進化しています。同時に、AI は身体化されたインテリジェンスや自動運転などの主要な分野の技術的限界を押し広げています。マルチモーダルの流れのもと、AI大型モデルの主流アーキテクチャとしてのTransformerの状況は揺るがされるだろうか? MoE (専門家混合) アーキテクチャに基づく大規模モデルの検討が業界の新しいトレンドになっているのはなぜですか?ラージ ビジョン モデル (LVM) は、一般的な視覚における新たなブレークスルーとなる可能性がありますか? ...過去 6 か月間にリリースされたこのサイトの 2023 PRO メンバー ニュースレターから、上記の分野の技術トレンドと業界の変化を詳細に分析し、新しい分野での目標を達成するのに役立つ 10 の特別な解釈を選択しました。準備してください。この解釈は 2023 年の Week50 からのものです
 新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
編集者 |ScienceAI 質問応答 (QA) データセットは、自然言語処理 (NLP) 研究を促進する上で重要な役割を果たします。高品質の QA データ セットは、モデルの微調整に使用できるだけでなく、大規模言語モデル (LLM) の機能、特に科学的知識を理解し推論する能力を効果的に評価することもできます。現在、医学、化学、生物学、その他の分野をカバーする多くの科学 QA データ セットがありますが、これらのデータ セットにはまだいくつかの欠点があります。まず、データ形式は比較的単純で、そのほとんどが多肢選択式の質問であり、評価は簡単ですが、モデルの回答選択範囲が制限され、科学的な質問に回答するモデルの能力を完全にテストすることはできません。対照的に、自由回答型の Q&A
 AlphaFold 3 が発売され、タンパク質とすべての生体分子の相互作用と構造をこれまでよりもはるかに高い精度で包括的に予測します。
Jul 16, 2024 am 12:08 AM
AlphaFold 3 が発売され、タンパク質とすべての生体分子の相互作用と構造をこれまでよりもはるかに高い精度で包括的に予測します。
Jul 16, 2024 am 12:08 AM
エディター | Radish Skin 2021 年の強力な AlphaFold2 のリリース以来、科学者はタンパク質構造予測モデルを使用して、細胞内のさまざまなタンパク質構造をマッピングし、薬剤を発見し、既知のあらゆるタンパク質相互作用の「宇宙地図」を描いてきました。ちょうど今、Google DeepMind が AlphaFold3 モデルをリリースしました。このモデルは、タンパク質、核酸、小分子、イオン、修飾残基を含む複合体の結合構造予測を実行できます。 AlphaFold3 の精度は、これまでの多くの専用ツール (タンパク質-リガンド相互作用、タンパク質-核酸相互作用、抗体-抗原予測) と比較して大幅に向上しました。これは、単一の統合された深層学習フレームワーク内で、次のことを達成できることを示しています。
