Mamba は優れていますが、その開発はまだ初期段階です。
ディープラーニングアーキテクチャは数多くありますが、近年最も成功しているのは、複数のアプリケーション分野で支配的な地位を確立しているTransformerです。 このような成功の主な要因は、Transformer ベースのモデルが入力シーケンスに関連する部分に焦点を当ててコンテキストをより良く理解できるようにするアテンション メカニズムです。ただし、アテンション メカニズムの欠点は、計算オーバーヘッドが高く、入力サイズに応じて二次関数的に増加するため、非常に長いテキストの処理が困難になることです。 幸いなことに、大きな可能性を秘めた新しいアーキテクチャである構造化状態空間シーケンス モデル (SSM) が少し前に誕生しました。このアーキテクチャは、シーケンス データ内の複雑な依存関係を効率的にキャプチャできるため、Transformer の強力な敵となります。 このタイプのモデルの設計は、古典的な状態空間モデルに触発されており、リカレント ニューラル ネットワークと畳み込みニューラル ネットワークの融合モデルと考えることができます。これらは、ループ演算または畳み込み演算を使用して効率的に計算でき、計算オーバーヘッドをシーケンスの長さに応じて線形またはほぼ線形にスケールできるため、計算コストが大幅に削減されます。 より具体的には、SSM の最も成功した亜種の 1 つである Mamba のモデリング機能は、シーケンス長による線形スケーラビリティを維持しながら、既に Transformer に匹敵します。 Mamba はまず、入力に基づいて SSM を再パラメータ化するシンプルかつ効果的な選択メカニズムを導入します。これにより、モデルは無関係な情報をフィルターで除外しながら、必要かつ関連性のあるデータを無期限に保持できるようになります。 Mamba には、畳み込みの代わりにスキャンを使用してモデルを反復計算するハードウェア対応アルゴリズムが組み込まれており、その結果、A100 GPU で 3 倍の高速化が実現します。 図 1 に示すように、複雑な長いシーケンス データをモデル化する強力な機能と、ほぼ線形のスケーラビリティを備えた Mamba は、基本モデルとして登場し、コンピューター ビジョン、自然言語処理、医療など多くの分野に革命をもたらすと期待されています。他の研究および応用分野。 
そのため、Mamba の研究と応用に関する文献は目まぐるしく増加しており、包括的なレビューレポートは非常に有益です。最近、香港理工大学の研究チームがその寄稿文を arXiv で公開しました。
- 論文タイトル: A Survey of Mamba
- 論文アドレス: https://arxiv.org/pdf/2408.01129
このレビューレポートは、Mamba を複数の角度から調査しています。初心者が Mamba の基本的な動作メカニズムを学ぶのに役立つだけでなく、経験豊富な実践者が最新の進歩を理解するのにも役立ちます。 Mamba は人気のある研究方向であるため、この記事で紹介したレビュー以外にも、状態空間モデルやビジュアル Mamba に焦点を当てたレビューが多数作成されています。対応する論文を参照してください:
Mamba-360: ロングシーケンスモデリングのトランスフォーマー代替としての状態空間モデルの調査: arXiv:2404.16112
新世代ネットワークの代替となる状態空間モデル。トランスフォーマー: 調査。arXiv:2404.09516
ビジョンマンバ: 包括的な調査と分類法。arXiv:2405.04404
ビジュアルマンバに関する調査。arXiv:2404.15956
Mamba集中型リカレントニューラルネットワーク(RNN) 、Transformer の並列計算とアテンション メカニズム、および状態空間モデル (SSM) の線形特性。したがって、Mamba を完全に理解するには、まずこれら 3 つのアーキテクチャを理解する必要があります。 #🎜 🎜 #リカレント ニューラル ネットワーク (RNN) は内部メモリを保持する機能があるため、シーケンス データの処理に非常に優れています。
具体的には、標準 RNN は、各離散時間ステップ k で、前の時間ステップの隠れ状態とともにベクトルを処理し、別のベクトルを出力します。そして非表示状態を更新します。この隠れた状態は RNN のメモリとして使用でき、過去に確認された入力に関する情報を保持できます。この動的メモリにより、RNN はさまざまな長さのシーケンスを処理できるようになります。
つまり、RNN は、隠れた状態に保存されている履歴知識を使用して、時間的パターンを効果的にキャプチャできる非線形リカレント モデルです。
変圧器セルフ アテンション メカニズムは、入力間のグローバルな依存関係を把握するのに役立ちます。これは、他の位置との相対的な重要性に基づいて各位置に重みを割り当てることによって行われます。より具体的には、最初に元の入力に対して線形変換が実行され、入力ベクトルのシーケンス x が 3 種類のベクトル (クエリ Q、キー K、値 V) に変換されます。
次に、正規化された注意スコア S を計算し、注意の重みを計算します。
単一のアテンション関数を実行することに加えて、マルチヘッド アテンションを実行することもできます。これにより、モデルはさまざまなタイプの関係をキャプチャし、入力シーケンスを複数の観点から理解できるようになります。マルチヘッド アテンションでは、複数セットのセルフ アテンション モジュールを使用して、入力シーケンスを並行して処理します。これらのヘッドはそれぞれ独立して動作し、標準のセルフアテンション メカニズムと同じ計算を実行します。
その後、各ヘッドの注意の重みが集計されて結合され、値ベクトルの加重和が得られます。この集約ステップにより、モデルは複数のヘッドからの情報を使用し、入力シーケンス内の多くの異なるパターンと関係をキャプチャできるようになります。 #🎜🎜## ## ## ##状態空間モデル (SSM) は、時間の経過に伴うシステムの動的な動作を記述するために使用できる伝統的な数学的フレームワークです。近年、SSM はサイバネティクス、ロボット工学、経済学などのさまざまな分野で広く使用されています。
その中核では、SSM は「状態」と呼ばれる一連の隠し変数を通じてシステムの動作を反映し、時間データの依存関係を効果的にキャプチャできるようにします。 。 RNN とは異なり、SSM は結合特性を持つ線形モデルです。具体的には、古典的な状態空間モデルは 2 つの重要な方程式 (状態方程式と観測方程式) を構築し、N 次元の隠れ状態 h (t) を通じて現在の時刻 t における入力 x と出力 y の関係をモデル化します。
細分化
機械学習のニーズを満たすために、SSM は離散化プロセス、つまり連続パラメータを離散パラメータに変換する必要があります。一般に、離散化法の目標は、連続時間を可能な限り等しい整数面積で K 個の離散間隔に分割することです。この目標を達成するために、SSM で採用される最も代表的なソリューションの 1 つはゼロ次ホールド (ZOH) です。これは、区間 Δ = [?_{?−1}, ?_? ] 上の関数値が一定に保たれることを前提としています。 Discrete SSM はリカレント ニューラル ネットワークに似た構造を持っているため、Transformer ベースのモデルよりも効率的に推論プロセスを実行できます。
#🎜🎜 #
離散 SSM は結合特性を持つ線形システムであるため、畳み込み計算とシームレスに統合できます。 -
写真2 RNN、Transformer、SSMの計算アルゴリズムを示します。
一方で、従来の RNN は非線形リカレント フレームワークに基づいて動作し、各計算は前の隠れ状態と現在の入力にのみ依存します。 この形式により、RNN は自己回帰推論中に出力を迅速に生成できますが、RNN が GPU の並列計算能力を十分に活用することが難しくなり、モデルのトレーニングが遅くなります。 一方、Transformer アーキテクチャは、複数の「クエリキー」ペアに対して行列の乗算を並列に実行し、行列の乗算をハードウェア リソースに効率的に割り当てることができるため、アテンションベースのモデルのトレーニングを高速化できます。ただし、Transformer ベースのモデルで応答または予測を生成する場合、推論プロセスに非常に時間がかかる可能性があります。 1 種類の計算のみをサポートする RNN や Transformer とは異なり、離散 SSM はその線形な性質により非常に柔軟であり、ループ計算と畳み込み計算の両方をサポートできます。この機能により、SSM は効率的な推論を実現できるだけでなく、並列トレーニングも実現できます。ただし、最も従来の SSM は時間不変である、つまり、その A、B、C、および Δ はモデル入力 x から独立していることに注意する必要があります。これにより、コンテキスト認識モデリング機能が制限され、選択コピーなどの特定のタスクで SSM のパフォーマンスが低下します。 Mamba-1: ハードウェア認識アルゴリズムを使用した選択的状態空間モデルMamba-1 は、構造化状態空間モデル、つまり高次多項式射影計算に基づく 3 つの革新的なテクノロジーを導入しています。 HiPPO の初期化、選択メカニズム、およびハードウェアを意識した計算。図 3 に示すように。これらの手法の目標は、SSM の長距離線形時系列モデリング機能を向上させることです。
具体的には、初期化戦略はコヒーレントな隠れ状態行列を構築して、長距離記憶を効果的に促進できます。 次に、選択メカニズムにより、SSM に知覚可能なコンテンツの表現を取得する機能が与えられます。 最後に、トレーニング効率を向上させるために、Mamba には 2 つのハードウェア対応コンピューティング アルゴリズム (並列連想スキャンとメモリ再計算) も含まれています。 Mamba-2: State Space Dual Transformer は、パラメーター効率の高い微調整、壊滅的な忘却の軽減、モデルの量子化など、さまざまなテクノロジーの開発に影響を与えてきました。状態空間モデルでも、もともと Transformer 用に開発されたこれらの技術の恩恵を受けるために、Mamba-2 では新しいフレームワークである Structured State Space Duality (SSD) が導入されています。このフレームワークは理論的には SSM とさまざまな形態の注意を結び付けます。 本質的に、SSD は、Transformer で使用されるアテンション メカニズムと SSM で使用される線形時不変システムの両方が、半分離可能な行列変換と見なすことができることを示しています。 さらに、Albert Gu と Tri Dao は、選択的 SSM が半分離マスク行列を使用して実装された構造化線形アテンション メカニズムと同等であることも証明しました。 Mamba-2 は、ブロック分解行列乗算アルゴリズムを使用する、ハードウェアをより効率的に使用できる SSD に基づく計算方法を設計します。 具体的には、この行列変換を通じて状態空間モデルを半分離行列として扱うことにより、Mamba-2 はこの計算を行列ブロックに分解することができます。ここで、対角ブロックはブロック内計算を表します。一方、非対角ブロックは、SSM の隠れ状態分解によるブロック間計算を表します。この方法により、Mamba-2 は Mamba-1 の並列相関スキャンよりも 2 ~ 8 倍高速にトレーニングできると同時に、Transformer に匹敵するパフォーマンスを達成できます。 Mamba-1とMamba-2のブロックデザインを見てみましょう。図 4 は 2 つのアーキテクチャを比較しています。
Mamba-1 は SSM を中心に設計されており、選択的 SSM レイヤーは入力シーケンス X から Y へのマッピングを実行する役割を果たします。この設計では、最初に X の線形投影を作成した後、(A、B、C) の線形投影が使用されます。次に、入力トークンと状態行列が並列相関を使用して選択的 SSM ユニットを通じてスキャンされ、出力 Y が取得されます。その後、Mamba-1 はスキップ接続を採用して、機能の再利用を促進し、モデルのトレーニング中によく発生するパフォーマンスの低下を軽減します。最後に、このモジュールを標準の正規化と残留接続と交互にスタックすることによって、Mamba モデルが構築されます。 Mamba-2 に関しては、[X, A, B, C] から Y へのマッピングを作成するために SSD 層が導入されています。これは、標準的なアテンション アーキテクチャが Q、K、V 投影を並行して生成する方法と同様に、ブロックの先頭で単一の投影を使用して [X、A、B、C] を同時に処理することによって実現されます。 つまり、Mamba-2 ブロックは、Mamba-1 ブロックに基づいて、シーケンス線形射影を削除することによって簡略化されます。これにより、SSD ファブリックを Mamba-1 の並列選択スキャンよりも高速に計算できるようになります。さらに、トレーニングの安定性を向上させるために、Mamba-2 はスキップ接続の後に正規化層も追加します。 状態空間モデルとMambaは最近急速に発展しており、大きな可能性を秘めた基本モデルのバックボーンネットワークの選択肢となっています。 Mamba は自然言語処理タスクでは良好なパフォーマンスを発揮しますが、メモリ損失、さまざまなタスクへの一般化の難しさ、複雑なパターンでのパフォーマンスは Transformer ベースの言語モデルほど良くないなど、いくつかの問題がまだあります。これらの問題を解決するために、研究コミュニティは Mamba アーキテクチャに対する多くの改善を提案してきました。既存の研究は主に、変更ブロックの設計、スキャン パターン、メモリ管理に焦点を当てています。表 1 は、関連する研究をカテゴリー別にまとめたものです。
Mamba ブロックの設計と構造は、Mamba モデルの全体的なパフォーマンスに大きな影響を与えるため、これは主要な研究のホットスポットとなっています。
그림 5에서 볼 수 있듯이 새로운 Mamba 모듈을 구축하는 다양한 방법을 기반으로 기존 연구는 세 가지 범주로 나눌 수 있습니다.
- 통합 방법: Mamba 블록을 다른 모델과 통합하여 더 나은 결과와 효율성 달성 균형;
- 교체 방법: 다른 모델 프레임워크의 기본 레이어를 Mamba 블록으로 대체합니다.
- 수정 방법: 클래식 Mamba 블록 내의 구성 요소를 수정합니다.
병렬 상관 스캔은 Mamba 모델의 핵심 구성 요소입니다. 그 목표는 선택 메커니즘으로 인해 발생하는 계산 문제를 해결하고 훈련 프로세스 속도를 향상시키는 것입니다. 메모리 요구 사항을 줄입니다. 이는 시변 SSM의 선형 특성을 활용하여 하드웨어 수준에서 코어 융합 및 재계산을 설계함으로써 달성됩니다. 그러나 Mamba의 단방향 시퀀스 모델링 패러다임은 이미지, 비디오 등 다양한 데이터에 대한 포괄적인 학습에 도움이 되지 않습니다.
이 문제를 완화하기 위해 일부 연구자들은 Mamba 모델의 성능을 향상하고 훈련 프로세스를 용이하게 하는 새롭고 효율적인 스캐닝 방법을 모색했습니다. 그림 6에서 볼 수 있듯이 스캐닝 모드 개발 측면에서 기존 연구 결과는 두 가지 범주로 나눌 수 있습니다. 입력 입체 스캐닝 방법: 차원, 채널 또는 규모에 걸쳐 모델 입력을 스캐닝하며 계층형 스캐닝, 시공간 스캐닝 및 하이브리드 스캐닝의 세 가지 범주로 더 나눌 수 있습니다.
RNN과 유사하게 상태 공간 모델 내에서 숨겨진 상태의 메모리는 이전 단계의 정보를 효과적으로 저장하므로 SSM Influence의 전반적인 성능에 매우 중요합니다. . Mamba는 메모리 초기화를 위해 HiPPO 기반 방법을 도입했지만 레이어 이전에 숨겨진 정보를 전송하고 무손실 메모리 압축을 달성하는 등 SSM 장치에서 메모리를 관리하는 것은 여전히 어렵습니다.
이를 위해 일부 선구적인 연구에서는 메모리 초기화, 압축, 연결을 포함한 다양한 솔루션을 제안했습니다. Mamba를 다양한 데이터에 적응시키세요Mamba 아키텍처는 선택적 상태 공간 모델의 확장으로 순환 모델의 기본 특성을 가지므로 텍스트, 시간 처리에 매우 적합합니다. 시리즈, 음성과 같은 시퀀스 데이터에 대한 보편적인 기본 모델입니다.
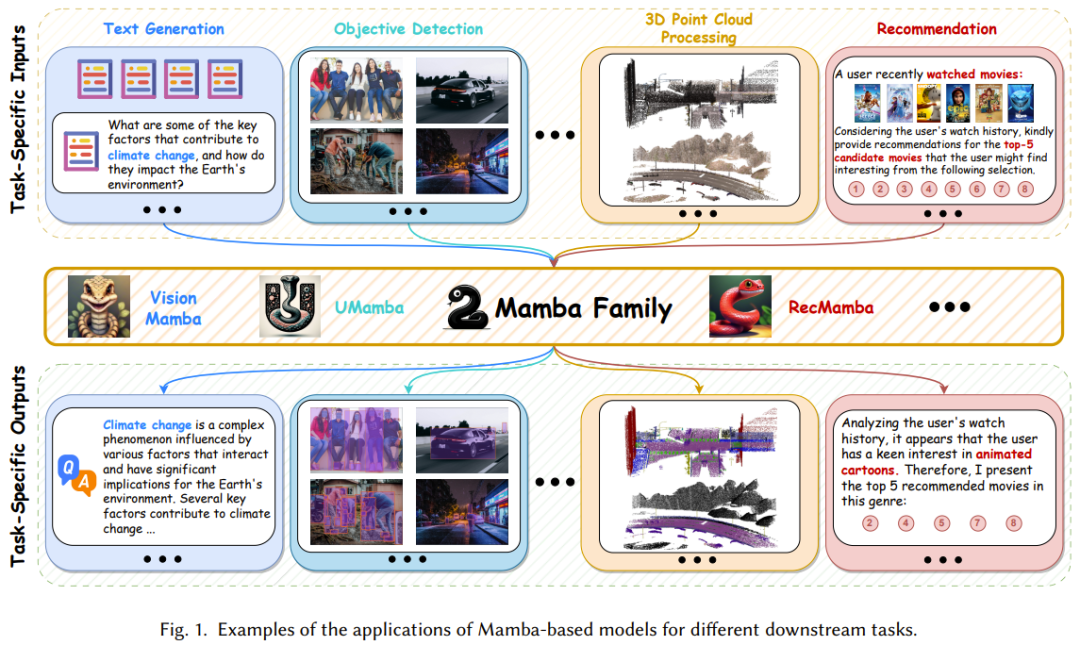
그뿐만 아니라, 최근 일부 선구적인 연구에서는 그림 7과 같이 Mamba 아키텍처의 적용 시나리오를 확장하여 시퀀스 데이터 처리뿐 아니라 이미지, 지도 등의 분야에서도 사용할 수 있게 되었습니다. .
이 연구의 목표는 Mamba의 뛰어난 장거리 종속성을 최대한 활용하고 학습 및 추론 과정에서 효율성을 활용하는 것입니다. 표 2는 이러한 결과를 간략하게 요약합니다. 시퀀스 데이터는 특정 순서로 수집되고 정리된 데이터를 말하며, 데이터 포인트의 순서가 중요합니다. 이 검토 보고서는 자연어, 비디오, 시계열, 음성 및 인간 동작 데이터를 포함한 다양한 시퀀스 데이터에 대한 Mamba의 적용을 포괄적으로 요약합니다. 자세한 내용은 원본 논문을 참조하세요. 비순차 데이터는 시퀀스 데이터와 달리 특정 순서를 따르지 않습니다. 데이터 포인트는 데이터의 의미에 큰 영향을 주지 않고 어떤 순서로든 구성될 수 있습니다. 이러한 고유 순서 부족은 데이터의 시간적 종속성을 캡처하도록 특별히 설계된 반복 모델(RNN, SSM 등)의 경우 어려울 수 있습니다. 놀랍게도 최근 일부 연구에 따르면 Mamba(SSM 대표)가 이미지, 지도, 포인트 클라우드 데이터를 포함한 비순차적 데이터를 효율적으로 처리할 수 있게 되었습니다. AI의 인식 및 장면 이해 능력을 향상시키기 위해 언어(순차 데이터), 이미지(비순차 데이터) 등 다중 모달 데이터를 통합할 수 있습니다. 이러한 통합은 매우 가치 있고 보완적인 정보를 제공할 수 있습니다. 최근에는 다중 모드 대형 언어 모델(MLLM)이 가장 인기 있는 연구 초점이 되었습니다. 이 유형의 모델은 강력한 언어 표현 및 논리적 추론 능력을 포함하여 대형 언어 모델(LLM)의 강력한 기능을 계승합니다. Transformer가 해당 분야에서 지배적인 방법이 되었지만 Mamba는 혼합 소스 데이터를 정렬하고 시퀀스 길이에 따른 선형 복잡성 확장을 달성하는 성능으로 인해 Mamba가 다중 모드 학습에서 Transformer를 대체할 가능성이 높습니다. 다음은 Mamba 기반 모델의 주목할만한 응용 프로그램입니다. 팀은 이러한 애플리케이션을 자연어 처리, 컴퓨터 비전, 음성 분석, 약물 발견, 추천 시스템, 로봇공학 및 자율 시스템 등의 카테고리로 분류했습니다. 여기서는 너무 많이 소개하지 않겠습니다. 자세한 내용은 원본 문서를 참조하세요. Mamba 일부 분야에서 뛰어난 성과를 거두었지만, 전반적으로 Mamba 연구는 아직 초기 단계이며, 앞으로 극복해야 할 과제가 남아 있습니다. 물론 이러한 도전은 기회이기도 합니다.
- Mamba 기반 기본 모델을 개발하고 개선하는 방법
- 모델 효율성을 높이기 위해 GPU 및 TPU와 같은 하드웨어 사용을 극대화하는 하드웨어 인식 컴퓨팅을 완벽하게 구현하는 방법; Mamba를 개선하는 방법 보안 및 견고성, 공정성, 설명 가능성 및 개인 정보 보호에 대한 추가 연구가 필요한 모델의 신뢰성
- 변환기 분야에서 매개변수 효율적인 미세 조정과 같은 새로운 기술을 사용하는 방법 그리고 완화, 검색 증강 생성(RAG)을 망각하는 치명적인 경우가 있습니다.
-
以上がトランスフォーマーの最強のライバル、マンバがこの記事でわかるの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



