

Neo4j へのデータのロード
Aug 19, 2024 pm 04:40 PM前のブログでは、2 つのプラグイン APOC とグラフ データ サイエンス ライブラリ - GDS を使用して neo4j をローカルにインストールしてセットアップする方法を説明しました。このブログでは、おもちゃのデータセット (電子商取引 Web サイトの製品) を取得し、それを Neo4j に保存します。
Neo4j に十分なメモリを割り当てる
ユースケースで巨大なデータがある場合は、データのロードを開始する前に、十分な量のメモリが neo4j に割り当てられていることを確認してください。そのためには:
- 開くの右側にある 3 つの点 をクリックします

- フォルダーを開く をクリックします -> 構成

- neo4j.conf をクリックします
- neo4j.conf で heap を検索し、77 行目と 78 行目のコメントを解除して、256m を 2048m に変更します。これにより、neo4j のデータ ストレージに 2048mb が割り当てられるようになります。 .

ノードの作成
グラフには 2 つの主要コンポーネント ノードと関係があります。最初にノードを作成し、後で関係を確立しましょう。
私が使用しているデータはここにあります - data
ここにあるrequirements.txtを使用してPython仮想環境を作成します -requirements.txt
データをプッシュするためのさまざまな関数を定義しましょう。
必要なライブラリをインポートしています
import pandas as pd from neo4j import GraphDatabase from openai import OpenAI
- openai を使用して埋め込みを生成します
client = OpenAI(api_key="")
product_data_df = pd.read_csv('../data/product_data.csv')
- 埋め込みを生成するには
def get_embedding(text):
"""
Used to generate embeddings using OpenAI embeddings model
:param text: str - text that needs to be converted to embeddings
:return: embedding
"""
model = "text-embedding-3-small"
text = text.replace("\n", " ")
return client.embeddings.create(input=[text], model=model).data[0].embedding
- データセットに従って、2 つの一意のノード ラベルを持つことができます。Category: 製品のカテゴリ、Product: 製品の名前。カテゴリラベルを作成しましょう。neo4j はプロパティと呼ばれるものを提供します。これらは特定のノードのメタデータであると想像できます。ここで、name と embedding がプロパティです。したがって、カテゴリの名前とそれに対応する埋め込みを DB に保存しています。
def create_category(product_data_df):
"""
Used to generate queries for creating category nodes in neo4j
:param product_data_df: pandas dataframe - data
:return: query_list: list - list containing all create node queries for category
"""
cat_query = """CREATE (a:Category {name: '%s', embedding: %s})"""
distinct_category = product_data_df['Category'].unique()
query_list = []
for category in distinct_category:
embedding = get_embedding(category)
query_list.append(cat_query % (category, embedding))
return query_list
- 同様に製品ノードを作成できます。ここでのプロパティは、name、description、price、warranty_period、 になります。利用可能な在庫、レビュー評価、製品リリース日、埋め込み
def create_product(product_data_df):
"""
Used to generate queries for creating product nodes in neo4j
:param product_data_df: pandas dataframe - data
:return: query_list: list - list containing all create node queries for product
"""
product_query = """CREATE (a:Product {name: '%s', description: '%s', price: %d, warranty_period: %d,
available_stock: %d, review_rating: %f, product_release_date: date('%s'), embedding: %s})"""
query_list = []
for idx, row in product_data_df.iterrows():
embedding = get_embedding(row['Product Name'] + " - " + row['Description'])
query_list.append(product_query % (row['Product Name'], row['Description'], int(row['Price (INR)']),
int(row['Warranty Period (Years)']), int(row['Stock']),
float(row['Review Rating']), str(row['Product Release Date']), embedding))
return query_list
- 次に、上記の 2 つの関数によって生成されたクエリを実行する別の関数を作成しましょう。ユーザー名とパスワードを適切に更新してください。
def execute_bulk_query(query_list):
"""
Executes queries is a list one by one
:param query_list: list - list of cypher queries
:return: None
"""
url = "bolt://localhost:7687"
auth = ("neo4j", "neo4j@123")
with GraphDatabase.driver(url, auth=auth) as driver:
with driver.session() as session:
for query in query_list:
try:
session.run(query)
except Exception as error:
print(f"Error in executing query - {query}, Error - {error}")
- 完全なコード
import pandas as pd
from neo4j import GraphDatabase
from openai import OpenAI
client = OpenAI(api_key="")
product_data_df = pd.read_csv('../data/product_data.csv')
def preprocessing(df, columns_to_replace):
"""
Used to preprocess certain column in dataframe
:param df: pandas dataframe - data
:param columns_to_replace: list - column name list
:return: df: pandas dataframe - processed data
"""
df[columns_to_replace] = df[columns_to_replace].apply(lambda col: col.str.replace("'s", "s"))
df[columns_to_replace] = df[columns_to_replace].apply(lambda col: col.str.replace("'", ""))
return df
def get_embedding(text):
"""
Used to generate embeddings using OpenAI embeddings model
:param text: str - text that needs to be converted to embeddings
:return: embedding
"""
model = "text-embedding-3-small"
text = text.replace("\n", " ")
return client.embeddings.create(input=[text], model=model).data[0].embedding
def create_category(product_data_df):
"""
Used to generate queries for creating category nodes in neo4j
:param product_data_df: pandas dataframe - data
:return: query_list: list - list containing all create node queries for category
"""
cat_query = """CREATE (a:Category {name: '%s', embedding: %s})"""
distinct_category = product_data_df['Category'].unique()
query_list = []
for category in distinct_category:
embedding = get_embedding(category)
query_list.append(cat_query % (category, embedding))
return query_list
def create_product(product_data_df):
"""
Used to generate queries for creating product nodes in neo4j
:param product_data_df: pandas dataframe - data
:return: query_list: list - list containing all create node queries for product
"""
product_query = """CREATE (a:Product {name: '%s', description: '%s', price: %d, warranty_period: %d,
available_stock: %d, review_rating: %f, product_release_date: date('%s'), embedding: %s})"""
query_list = []
for idx, row in product_data_df.iterrows():
embedding = get_embedding(row['Product Name'] + " - " + row['Description'])
query_list.append(product_query % (row['Product Name'], row['Description'], int(row['Price (INR)']),
int(row['Warranty Period (Years)']), int(row['Stock']),
float(row['Review Rating']), str(row['Product Release Date']), embedding))
return query_list
def execute_bulk_query(query_list):
"""
Executes queries is a list one by one
:param query_list: list - list of cypher queries
:return: None
"""
url = "bolt://localhost:7687"
auth = ("neo4j", "neo4j@123")
with GraphDatabase.driver(url, auth=auth) as driver:
with driver.session() as session:
for query in query_list:
try:
session.run(query)
except Exception as error:
print(f"Error in executing query - {query}, Error - {error}")
# PREPROCESSING
product_data_df = preprocessing(product_data_df, ['Product Name', 'Description'])
# CREATE CATEGORY
query_list = create_category(product_data_df)
execute_bulk_query(query_list)
# CREATE PRODUCT
query_list = create_product(product_data_df)
execute_bulk_query(query_list)
人間関係を築く
- Category と Product の間にリレーションシップを作成します。リレーションシップの名前は CATEGORY_CONTAINS_PRODUCT になります。
from neo4j import GraphDatabase
import pandas as pd
product_data_df = pd.read_csv('../data/product_data.csv')
def preprocessing(df, columns_to_replace):
"""
Used to preprocess certain column in dataframe
:param df: pandas dataframe - data
:param columns_to_replace: list - column name list
:return: df: pandas dataframe - processed data
"""
df[columns_to_replace] = df[columns_to_replace].apply(lambda col: col.str.replace("'s", "s"))
df[columns_to_replace] = df[columns_to_replace].apply(lambda col: col.str.replace("'", ""))
return df
def create_category_food_relationship_query(product_data_df):
"""
Used to create relationship between category and products
:param product_data_df: dataframe - data
:return: query_list: list - cypher queries
"""
query = """MATCH (c:Category {name: '%s'}), (p:Product {name: '%s'}) CREATE (c)-[:CATEGORY_CONTAINS_PRODUCT]->(p)"""
query_list = []
for idx, row in product_data_df.iterrows():
query_list.append(query % (row['Category'], row['Product Name']))
return query_list
def execute_bulk_query(query_list):
"""
Executes queries is a list one by one
:param query_list: list - list of cypher queries
:return: None
"""
url = "bolt://localhost:7687"
auth = ("neo4j", "neo4j@123")
with GraphDatabase.driver(url, auth=auth) as driver:
with driver.session() as session:
for query in query_list:
try:
session.run(query)
except Exception as error:
print(f"Error in executing query - {query}, Error - {error}")
# PREPROCESSING
product_data_df = preprocessing(product_data_df, ['Product Name', 'Description'])
# CATEGORY - FOOD RELATIONSHIP
query_list = create_category_food_relationship_query(product_data_df)
execute_bulk_query(query_list)
- MATCH クエリを使用して、すでに作成されたノードと照合することで、それらの間の関係を確立します。
作成されたノードの視覚化
開く アイコンの上にマウスを置き、neo4j ブラウザ をクリックして、作成したノードを視覚化します。
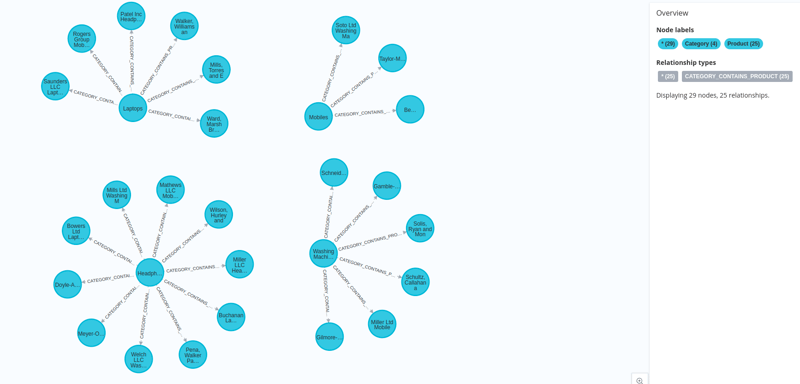
データは埋め込みとともに neo4j にロードされます。
今後のブログでは、Python を使用してグラフ クエリ エンジンを構築し、取得したデータを使用して拡張生成を行う方法を説明します。
これがお役に立てば幸いです...また会いましょう !!!
LinkedIn - https://www.linkedin.com/in/praveenr2998/
Github - https://github.com/praveenr2998/Creating-Lightweight-RAG-Systems-With-Graphs/tree/main/push_data_to_db
以上がNeo4j へのデータのロードの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

人気の記事


人気の記事

ホットな記事タグ

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7281
7281
 9
1622
14
1342
46
1258
25
1205
29
9
1622
14
1342
46
1258
25
1205
29









