

深層学習の分野における Transformer の大成功の鍵は、アテンション メカニズムです。アテンション メカニズムにより、Transformer ベースのモデルは入力シーケンスに関連する部分に焦点を当てることができ、コンテキストの理解が向上します。ただし、アテンション メカニズムの欠点は、計算オーバーヘッドが高く、入力サイズに応じて二次関数的に増加するため、Transformer が非常に長いテキストを処理することが困難になることです。
少し前に、Mamba の登場により、コンテキストの長さが増加するにつれて線形拡張を実現できるこの状況が打破されました。 Mamba のリリースにより、これらの状態空間モデル (SSM) は、シーケンス長による線形スケーラビリティを維持しながら、小規模から中規模で Transformer と同等、またはそれを超えることができるようになり、Mamba に有利な展開特性をもたらします。
簡単に言うと、Mamba はまず、入力に応じて SSM を再パラメータ化できる、シンプルだが効果的な選択メカニズムを導入します。これにより、モデルは無関係な情報や関連データを除外しながら、必要な情報を無期限に保持できるようになります。
最近、「ラマのマンバ: ハイブリッド モデルの蒸留と加速」というタイトルの論文で、アテンション層の重みを再利用することで、余分な計算を最小限に抑えながら、大きなトランスフォーマーを大規模なハイブリッド線形 RNN に蒸留できることが証明されました。ビルド品質のほとんどを維持しながら。
アテンション レイヤーの 4 分の 1 を含む結果のハイブリッド モデルは、チャット ベンチマークで元の Transformer と同等のパフォーマンスを達成し、チャット ベンチマークと一般ベンチマークのデータを使用した場合のパフォーマンスを上回ります。オープンソースのハイブリッド Mamba モデル。兆トークンを使ってゼロからトレーニングされました。さらに、この研究では、Mamba モデルとハイブリッド モデルの推論を高速化する、ハードウェア対応の投機的デコード アルゴリズムを提案しています。

論文アドレス: https://arxiv.org/pdf/2408.15237
この研究で最もパフォーマンスの高いモデルは、Llama3-8B-Instruct Distilled からのものです。 、AlpacaEval 2 では GPT-4 と比較して長さ制御された勝率 29.61、MT-Bench では 7.35 の勝率を達成し、最良の命令調整された線形 RNN モデルを上回りました。
メソッド
知識蒸留 (KD) は、大きなモデル (教師モデル) から小さなモデル (学生モデル) モデルに知識を転送するために使用されるモデル圧縮手法です。 )、教師ネットワークの動作を模倣するように生徒ネットワークを訓練することを目的としています。この研究は、Transformer のパフォーマンスが元の言語モデルと同等になるように、Transformer を抽出することを目的としています。
この研究は、順送蒸留、教師あり微調整、方向性優先最適化を組み合わせた多段階蒸留法を提案しています。この方法は、通常の蒸留と比較して、より優れた複雑性と下流の評価結果を得ることができます。
この研究では、Transformer からの知識のほとんどが元のモデルから転送された MLP 層に保持されていると想定しており、抽出された LLM の微調整と調整のステップに焦点を当てています。このフェーズでは、MLP レイヤーはフリーズされたままになり、Mamba レイヤーがトレーニングされます。
この研究では、線形 RNN と注意メカニズムの間には何らかの自然なつながりがあると考えています。アテンションの式は、ソフトマックスを削除することで線形化できます:
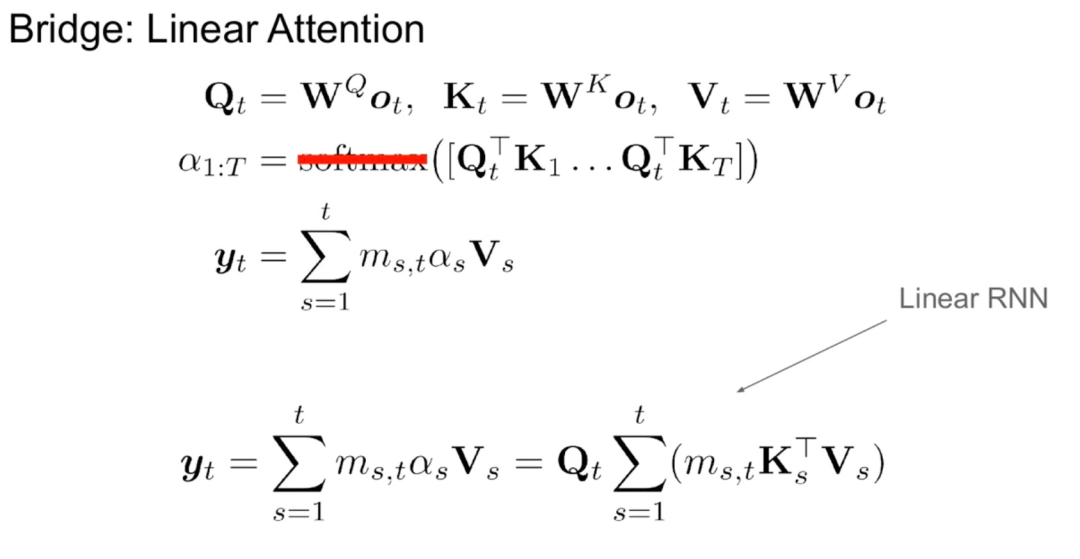
ただし、アテンションの線形化はモデルの機能の低下につながります。効率的な蒸留線形 RNN を設計するために、この研究では、効率的な方法で線形 RNN の容量を拡張しながら、元の Transformer のパラメータ化に可能な限り近づけます。この研究は、新しいモデルに元のアテンション関数を正確に取り込ませることを試みるものではなく、代わりに蒸留の開始点として線形化された形式を使用します。
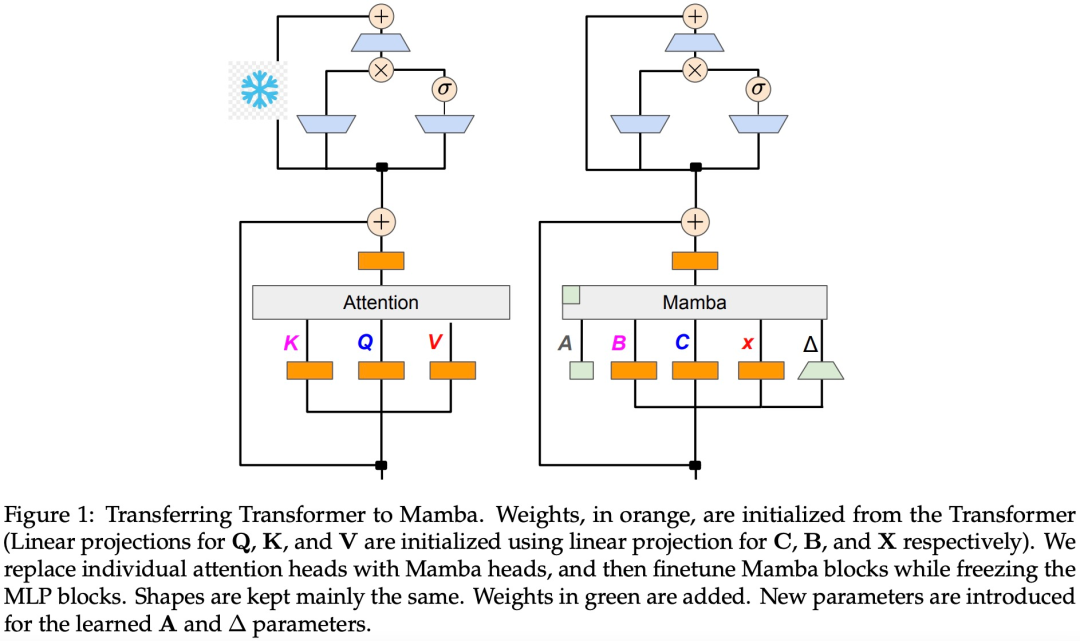
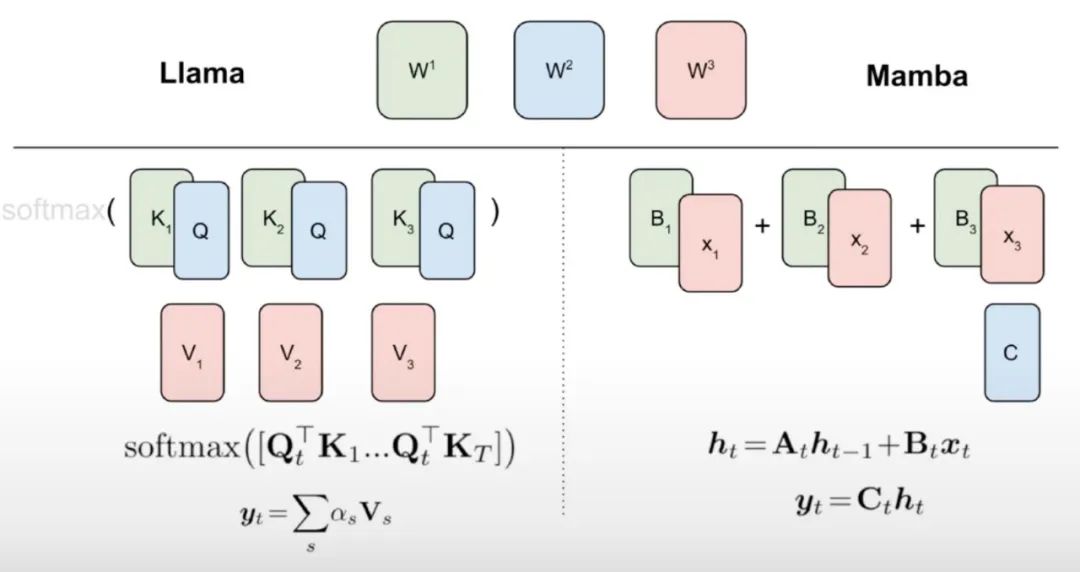
アルゴリズム 1 に示すように、この研究では、標準の Q、K、V ヘッドをアテンション メカニズムから Mamba 離散化に直接供給し、結果として得られる線形 RNN を適用します。これは、粗い初期化に線形アテンションを使用すると考えることができ、モデルは拡張された隠れ状態を通じてより豊富な相互作用を学習できるようになります。

この研究では、Transformer のアテンション ヘッドを微調整された線形 RNN 層に直接置き換え、Transformer MLP 層を変更せずに維持し、トレーニングを行いません。このアプローチでは、キーと値を複数のヘッド間で共有するグループ化されたクエリ アテンションなど、他のコンポーネントも処理する必要があります。研究チームは、このアーキテクチャは多くの Mamba システムで使用されているものとは異なり、この初期化によりアテンション ブロックを線形 RNN ブロックに置き換えることができることに注目しました。
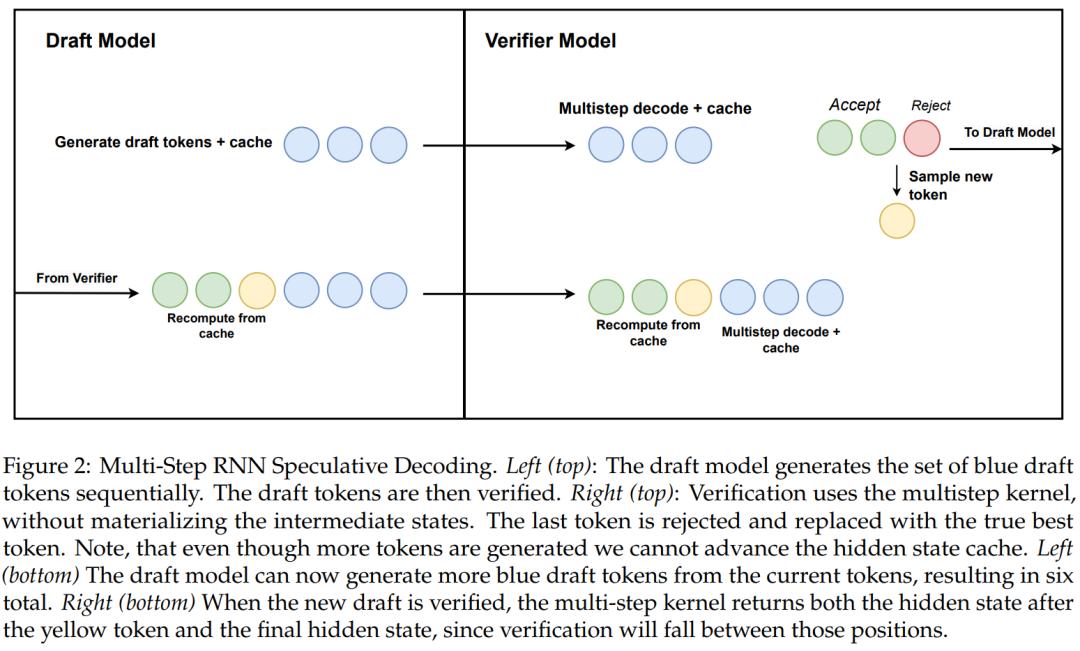
この研究では、ハードウェアを認識したマルチステップ生成を使用した線形 RNN 投機的復号のための新しいアルゴリズムも提案しています。
アルゴリズム 2 と図 2 は、完全なアルゴリズムを示しています。このアプローチでは、検証のために RNN の非表示状態をキャッシュに保持するだけであり、マルチステップ カーネルの成功に基づいて遅延的に処理を進めます。蒸留モデルにはトランスフォーマー層が含まれているため、この研究では投機的デコーディングもアテンション/RNN ハイブリッド アーキテクチャに拡張されています。この設定では、RNN 層はアルゴリズム 2 に従って検証を実行しますが、Transformer 層は並列検証のみを実行します。

この手法の有効性を検証するために、研究では Mamba 7B と Mamba 2.8B を推測のターゲット モデルとして使用しました。結果を表1に示す。
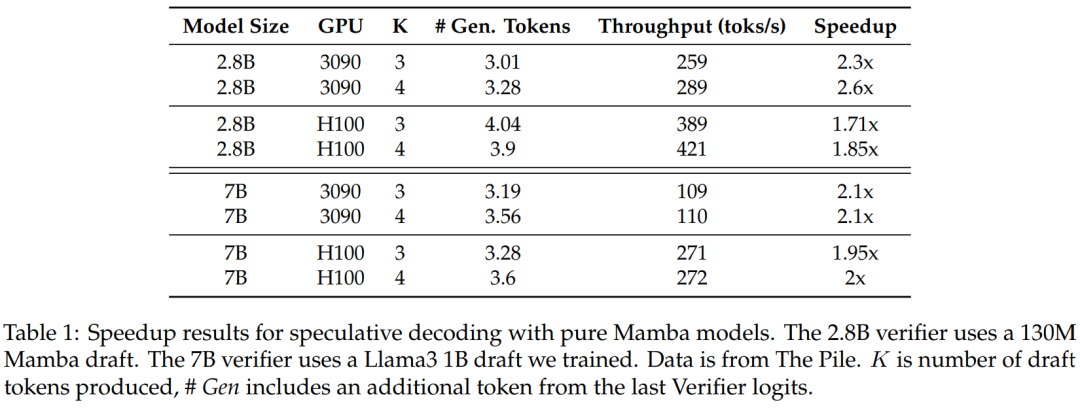
図 3 は、マルチステップ カーネル自体のパフォーマンス特性を示しています。
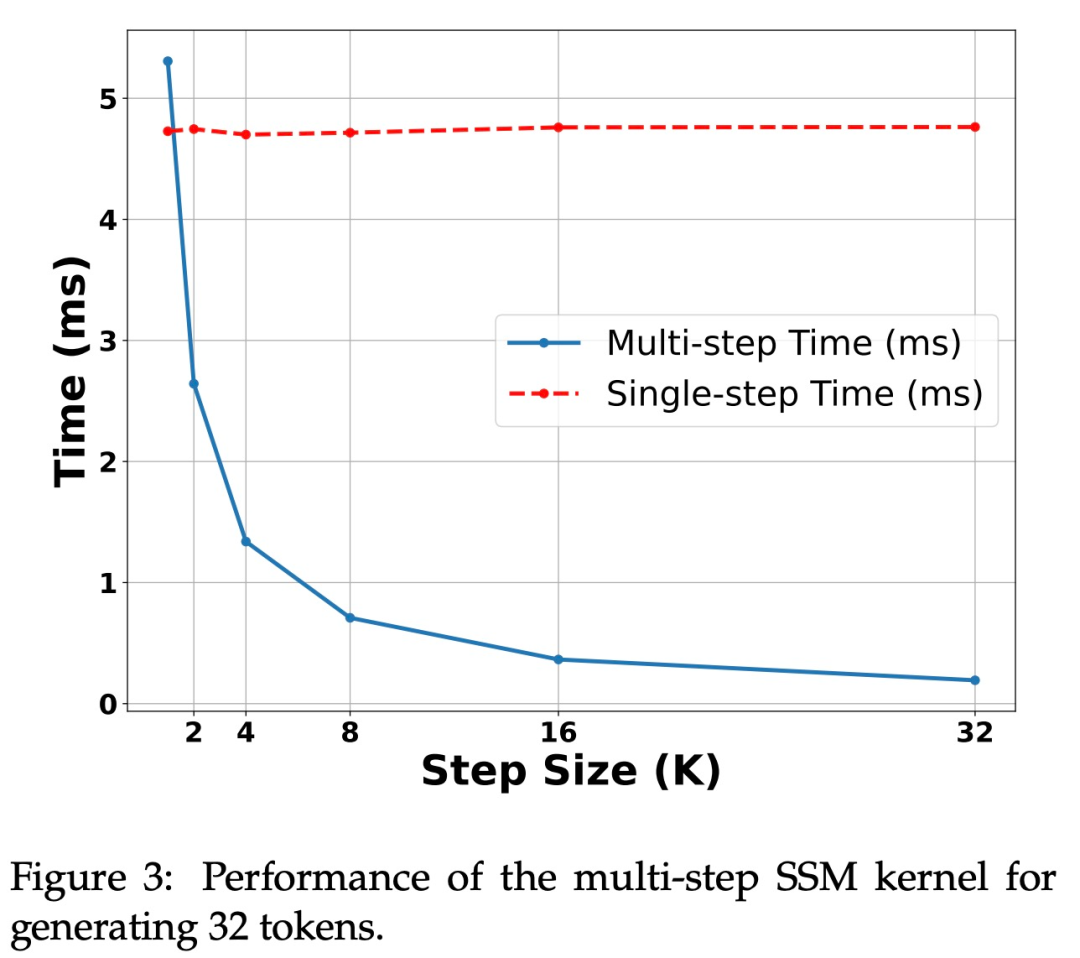
H100 GPU での高速化。上の表 1 に示すように、この研究で提案されたアルゴリズムは、Ampere GPU 上で強力なパフォーマンスを示しています。しかし、H100 GPU には大きな課題があります。これは主に、GEMM 操作が速すぎるため、キャッシュと再計算操作によって生じるオーバーヘッドがより顕著になるためです。実際、研究されたアルゴリズムの単純な実装 (複数の異なるカーネル呼び出しを使用) は、3090 GPU では大幅な高速化を達成しましたが、H100 ではまったく高速化されませんでした。
実験と結果
この研究では、実験に 2 つの LLM チャット モデルを使用します。Zephyr-7B は Mistral 7B モデルに基づいて微調整され、Llama-3 Instruct 8B.線形 RNN モデルの場合、この研究では、アテンション層がそれぞれ 50%、25%、12.5%、0% の Mamba と Mamba2 のハイブリッド バージョンを使用し、0% を純粋な Mamba モデルと呼びます。 Mamba2 は、主に最近の GPU アーキテクチャ向けに設計された Mamba のアーキテクチャ バリアントです。
チャット ベンチマークでの評価
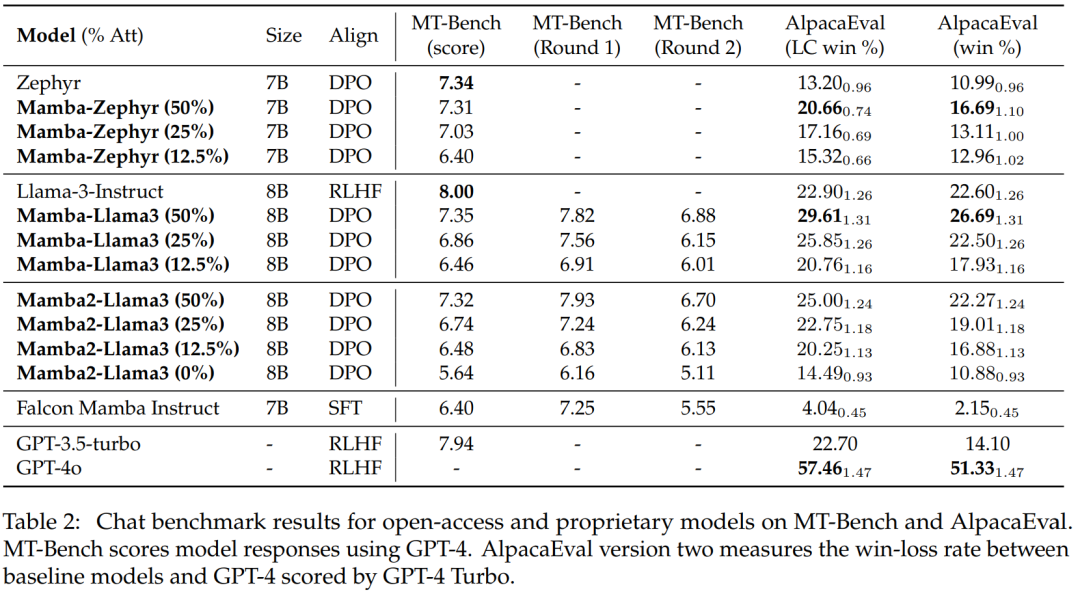
表 2 は、チャット ベンチマークでのモデルのパフォーマンスを示しています。比較される主なモデルは、大規模な Transformer モデルです。結果は次のことを示しています:
蒸留されたハイブリッド Mamba モデル (50%) は、MT ベンチマークの教師モデルと同様のスコアを達成し、LC 勝率と点で AlpacaEval ベンチマークの教師モデルよりわずかに優れています。全体的な勝率。
蒸留されたハイブリッド Mamba (25% および 12.5%) のパフォーマンスは、MT ベンチマークの教師モデルよりもわずかに劣りますが、AlpcaaEval のパラメーターが増えても、依然として一部の大型 Transformer よりも優れています。
蒸留された純粋な (0%) Mamba モデルの精度は大幅に低下します。
蒸留されたハイブリッド モデルのパフォーマンスが、5T トークンを超えるトークンを使用して最初からトレーニングされた Falcon Mamba よりも優れていることは注目に値します。
一般的なベンチマーク評価
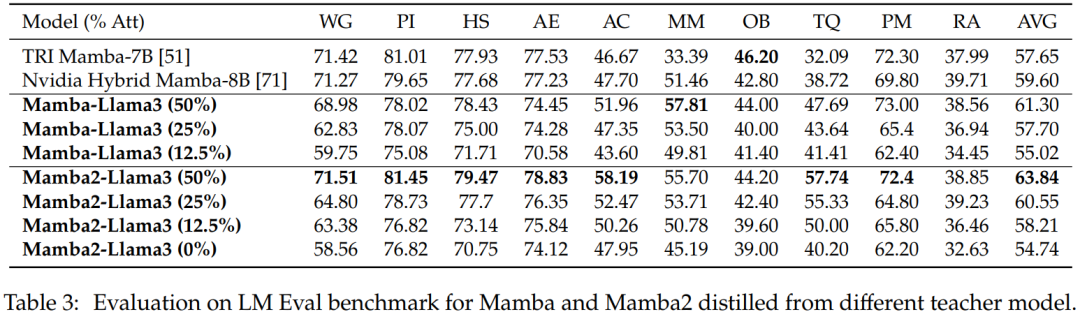
ゼロサンプル評価。表 3 は、LM Eval ベンチマークでのさまざまな教師モデルから抽出された Mamba と Mamba2 のゼロショット パフォーマンスを示しています。 Llama-3 Instruct 8B から抽出されたハイブリッド Mamba-Llama3 モデルおよび Mamba2-Llama3 モデルは、ゼロからトレーニングされたオープンソースの TRI Mamba モデルおよび Nvidia Mamba モデルと比較して、パフォーマンスが向上します。
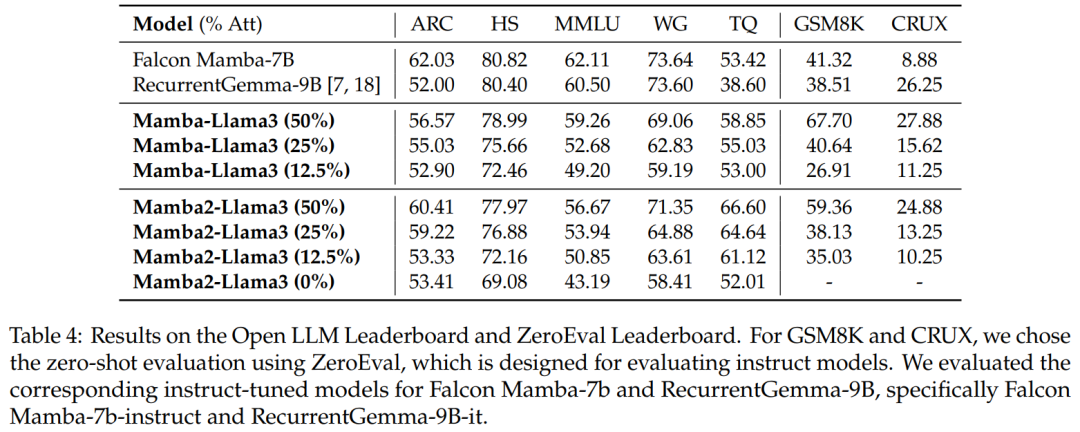
ベンチマーク評価。表 4 は、蒸留されたハイブリッド モデルのパフォーマンスが、Open LLM Leaderboard の最高のオープンソース線形 RNN モデルに匹敵し、同時に GSM8K および CRUX の対応するオープンソース命令モデルを上回っていることを示しています。
ハイブリッド投機的デコーディング
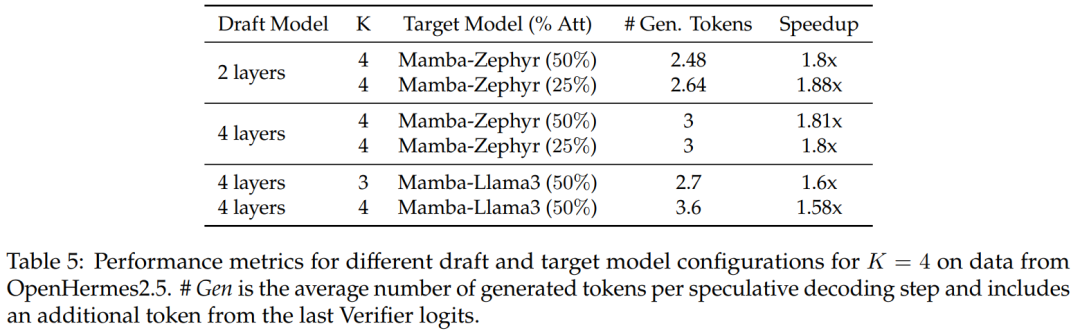
50% および 25% 蒸留モデルについて、非投機的ベースラインと比較したこの研究では、 Zephyr-Hybridで1.8倍以上の高速化を実現。
実験では、この研究でトレーニングされた 4 層ドラフト モデルがより高い受信率を達成することも示されていますが、ドラフト モデルのサイズが増加するため、追加のオーバーヘッドも大きくなります。今後の作業では、この研究はこれらのドラフト モデルの縮小に焦点を当てます。
他の蒸留方法との比較: 表 6 (左) は、さまざまなモデル バリアントの複雑さを比較しています。この研究では、シード プロンプトとして Ultrachat を使用してエポック内で蒸留を実行し、混乱度を比較しました。さらに多くのレイヤーを削除すると、状況が悪化することがわかりました。この研究ではまた、蒸留方法を以前のベースラインと比較し、新しい方法の方が劣化が小さいのに対し、蒸留ハイエナ モデルははるかに小さいモデルを使用して WikiText データセットでトレーニングされ、より大きな混乱度の劣化を示したことがわかりました。
表 6 (右) は、SFT または DPO を単独で使用してもあまり改善されないのに対し、SFT + DPO を使用すると最高のスコアが得られることを示しています。
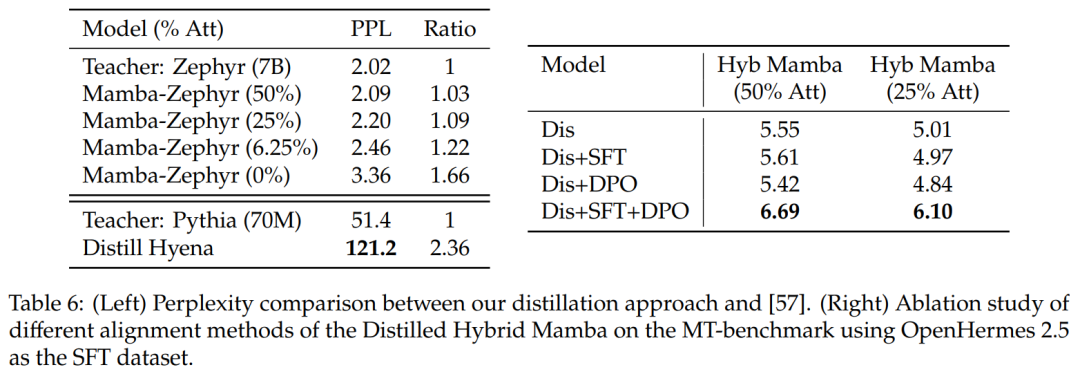
表 7 は、いくつかの異なるモデルのアブレーション研究を比較しています。表 7 (左) は、さまざまな初期化を使用した蒸留結果を示し、表 7 (右) は、プログレッシブ蒸留と Mamba とのアテンション レイヤーのインターリーブによる小さなゲインを示しています。
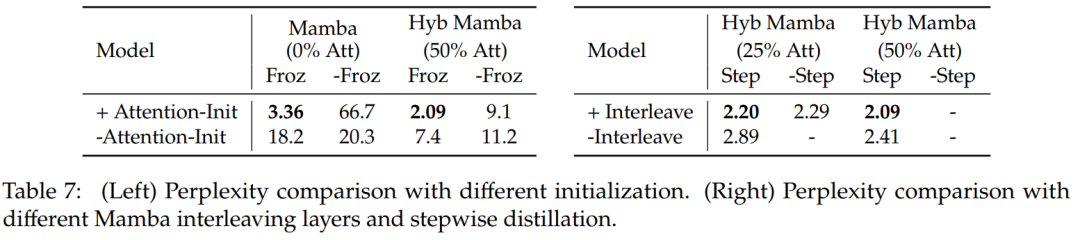
表 8 は、2 つの異なる初期化方法を使用したハイブリッド モデルのパフォーマンスを比較しています。結果は、アテンションの重みの初期化が重要であることを確認しています。

表 9 は、Mamba ブロックを使用したモデルと使用しないモデルのパフォーマンスを比較しています。 Mamba ブロックを含むモデルは、Mamba ブロックを含まないモデルよりもパフォーマンスが大幅に向上します。これは、Mamba レイヤーの追加が重要であること、およびパフォーマンスの向上が残りのアテンション メカニズムのみによるものではないことを裏付けています。

興味のある読者は、論文の原文を読んで研究内容をさらに詳しく知ることができます。
以上がMamba の作者による新作: Llama3 をハイブリッド線形 RNN に蒸留するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



