AIxivコラムは、本サイト上で学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。提出メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
単体テストはソフトウェア開発プロセスの重要なリンクであり、主に使用されます。ソフトウェア内のテスト可能な最小のユニット、関数、またはモジュールが期待どおりに動作することを確認します。単体テストの目的は、それぞれの独立したコード フラグメントがその機能を正しく実行できることを確認することであり、これはソフトウェアの品質と開発効率を向上させる上で非常に重要です。 ただし、大規模なモデルだけでは、テスト対象の複雑な関数 (環状複雑度が 10 を超える) の高カバレッジのテスト サンプル セットを生成できません。この問題点を解決するために、北京大学の Li Ge 教授のチームは、テスト ケースのカバレッジを向上させる新しい方法を提案しました。この方法では、プログラム スライシング (メソッド スライシング) を使用して、テスト対象の複雑な関数をセマンティクスに基づいていくつかの単純なフラグメントに分解します。大規模なモデルでは、単純なフラグメントごとにテスト ケースが個別に生成されます。単一のテスト ケースを生成する場合、大規模なモデルはテスト対象の元の関数の一部を分析するだけでよいため、分析の困難さが軽減され、このフラグメントをカバーする単体テストの生成も困難になります。このプロモーションにより、テスト サンプル セット全体のコード カバレッジを向上させることができます。 関連論文「HITS: メソッド スライシングによる高カバレッジ LLM ベースの単体テスト生成」が、最近 ASE 2024 によって出版されました (第 39 回 IEEE/ACM 国際会議で)。自動ソフトウェアエンジニアリング )を受け入れます。 
論文アドレス: https://www.arxiv.org/pdf/2408.11324HITS はプログラムシャーディングに大規模モデルを使用しているプログラムのシャーディングとは、セマンティクスに基づいてプログラムをいくつかの問題解決段階に分割することを指します。プログラムは、問題の解決策を形式的に表現したものです。問題の解決策は通常、複数のステップで構成され、各ステップはプログラム内のコードのスライスに対応します。次の図に示すように、カラー ブロックはコードの一部と問題を解決するためのステップに対応します。 
HITS では、大規模なモデルを効率的にカバーできる各コード部分の単体テスト コードを設計する必要があります。上の図を例にとると、図に示すようなスライスを取得すると、HITS では大規模モデルがスライス 1 (緑)、スライス 2 (青)、スライス 3 (赤) のテスト サンプルをそれぞれ生成する必要があります。スライス 1 に対して生成されたテスト サンプルは、スライス 2 とスライス 3 に関係なく、可能な限りスライス 1 をカバーする必要があります。同じことが他のコード部分にも当てはまります。 HITS が機能する理由は 2 つあります。まず、大規模なモデルでは、対象となるコードの量を減らすことを検討する必要があります。上の図を例にとると、スライス 3 のテスト サンプルを生成するときは、スライス 3 の条件分岐のみを考慮する必要があります。スライス 3 の一部の条件付き分岐をカバーするには、スライス 1 とスライス 2 のカバレッジに対するこの実行パスの影響を考慮せずに、スライス 1 とスライス 2 で実行パスを見つけるだけで済みます。第 2 に、セマンティクス (問題解決ステップ) に基づいてセグメント化されたコード部分は、大規模なモデルがコード実行の中間状態を把握するのに役立ちます。コードの後のブロックのテスト ケースを生成するには、前のコードによって引き起こされたプログラムの状態の変化を考慮する必要があります。コード ブロックは実際の問題解決手順に従ってセグメント化されるため、前のコード ブロックの操作を自然言語で記述することができます (上図の注釈に示すように)。現在の大規模言語モデルのほとんどは、自然言語とプログラミング言語の混合トレーニングの産物であるため、優れた自然言語要約は、大規模モデルがコードによって引き起こされるプログラム状態の変化をより正確に把握するのに役立ちます。 HITS はプログラム シャーディングに大規模なモデルを使用します。問題解決の手順は通常、プログラマーの主観を反映した自然言語で表現されるため、優れた自然言語処理能力を持つ大規模なモデルを直接使用できます。具体的には、HITS はコンテキスト内学習を使用して大規模なモデルを呼び出します。チームは実際のシナリオでの過去の実践経験を利用して、いくつかのプログラム シャーディング サンプルを手動で作成しました。数回の調整の後、プログラム シャーディングに対する大規模モデルの効果は研究チームの期待に応えました。 対象となるコード スニペットを指定すると、対応するテスト サンプルを生成するには、次の 3 つの手順を実行する必要があります: 1. フラグメントの入力を分析する; 2. 大規模なモデルに初期テスト サンプルを生成するように指示するプロンプトを構築する; 3. ルールの後処理を使用する;大型モデルのセルフデバッグ調整 サンプルが正しく動作するかテストします。 フラグメントの入力を分析します。これは、フラグメントによって受け入れられたすべての外部入力を抽出して、その後のプロンプト使用のためにカバーすることを意味します。外部入力は、このフラグメントが適用される前のフラグメントによって定義されたローカル変数、テスト対象メソッドの仮パラメータ、フラグメント内で呼び出されるメソッド、および外部変数を指します。外部入力の値は対象となるフラグメントの実行を直接決定するため、この情報を抽出して大規模モデルをプロンプトすることは、的を絞った方法でテスト ケースを設計するのに役立ちます。研究チームは、大規模なモデルが外部入力を抽出する優れた能力を備えていることを実験で発見したため、HITS ではこのタスクを完了するために大規模なモデルが使用されています。 次に、HITS は、大規模モデルがテスト サンプルを生成するようにガイドする思考連鎖プロンプトを構築します。推論の手順は次のとおりです。最初のステップは、外部入力を与え、対象となるコード部分のさまざまな条件分岐の順列と組み合わせを分析することです。たとえば、組み合わせ 1、文字列 a には、文字 'x'、整数変数 i は負でない必要があります。組み合わせ 2 では、文字列 a は空でない必要があり、整数変数 i は素数である必要があります。 2 番目のステップでは、前のステップの組み合わせごとに、実際のパラメーターの特性やグローバル変数の設定を含む (ただしこれらに限定されない)、テスト対象の対応するコードが実行される環境の性質を分析します。 3 番目のステップは、組み合わせごとにテスト サンプルを生成することです。研究チームは、大規模なモデルが命令を正しく理解して実行できるように、各ステップのサンプルを手作業で構築しました。 最後に、HITS により、大規模なモデルによって生成されたテスト サンプルが、後処理と自己デバッグを通じて正しく実行できるようになります。大規模なモデルによって生成されたテスト サンプルは、多くの場合、直接使用することが困難であり、テスト サンプルが正しく書かれていないことにより、さまざまなコンパイル エラーや実行時エラーが発生します。研究チームは、独自の観察と既存の論文の要約に基づいて、いくつかのルールと一般的なエラー修復ケースを設計しました。まずはルールに従って修正してみます。ルールを修復できない場合は、大規模モデルのセルフ デバッグ機能を使用して修復してください。一般的なエラーの修復ケースが大規模モデルの参照用のプロンプトに表示されます。 
연구팀은 HITS가 호출하는 대형 모델로 gpt-3.5-turbo를 사용하고, 대형 모델에서 학습한 Java 프로젝트의 복잡한 함수(사이클복잡도 10보다 큰)에 대한 HITS와 다른 대규모 모델 기반 단위 테스트 방법 및 evosuite를 사용한 코드 적용 범위는 학습되지 않았습니다. 실험 결과에 따르면 HITS는 비교 방법에 비해 성능이 크게 향상되었습니다.
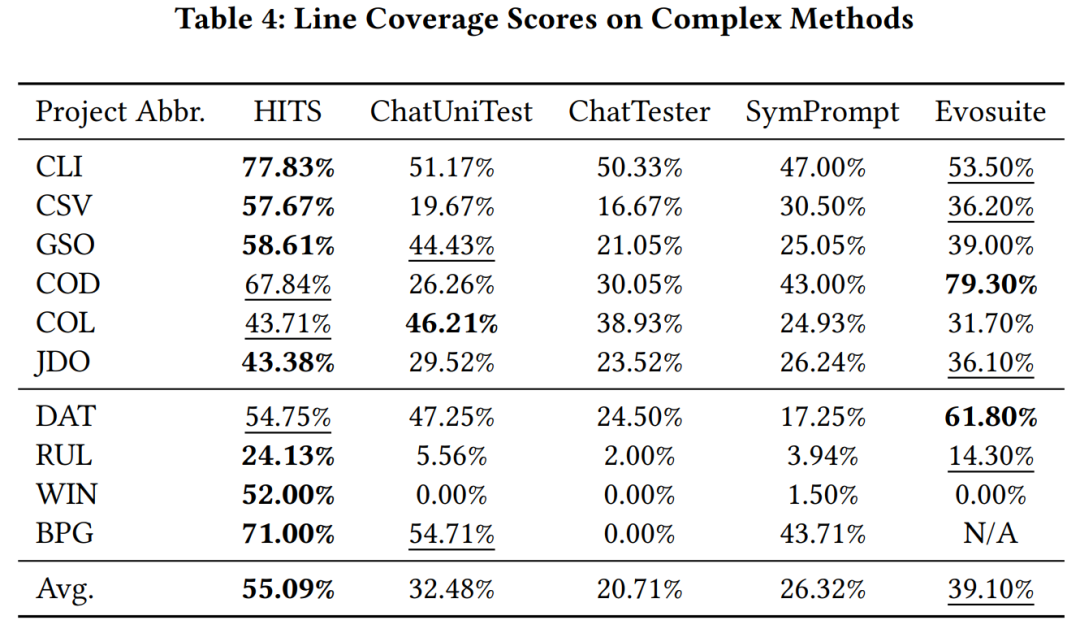


코드 적용 범위를 개선합니다. 그림과 같습니다.
이 경우 기준 방법으로 생성된 테스트 샘플은 슬라이스 2의 빨간색 코드 조각을 완전히 포함하지 못했습니다. 그러나 HITS는 슬라이스 2에 중점을 두었기 때문에 참조하는 외부 변수를 분석하고 "빨간색 코드 조각을 커버하려면 '인수' 변수가 비어 있지 않아야 한다"는 속성을 포착하고 테스트를 구축했습니다. 이 속성을 기반으로 한 샘플은 빨간색 지역 코드 적용 범위를 성공적으로 달성했습니다.
단위 테스트 범위를 개선하고 시스템 신뢰성과 안정성을 높여 소프트웨어 품질을 향상시킵니다. HITS는 프로그램 샤딩 실험을 통해 이 기술이 전체 테스트 샘플 세트의 코드 적용 범위를 크게 향상시킬 수 있을 뿐만 아니라, 향후 팀이 개발 오류를 발견하고 수정하는 데 도움이 될 것으로 기대합니다. 실제 시나리오 실습 초기에 소프트웨어 제공 품질을 향상시킵니다.
以上が北京大学 Li Ge のチームは、コード テスト カバレッジを大幅に向上させる、大規模モデルの単一テストを生成する新しい方法を提案しました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。



















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



