

numpy&#s einsum の理不尽な有用性

導入
Python で最も便利なメソッド、np.einsum を紹介します。
np.einsum (および Tensorflow と JAX の対応するもの) を使用すると、複雑な行列とテンソルの演算を非常に明確かつ簡潔な方法で作成できます。 また、その明快さと簡潔さにより、テンソルの操作に伴う精神的な過負荷の多くが軽減されることもわかりました。
実際、学習と使用は非常に簡単です。 仕組みは次のとおりです:
np.einsum には添字文字列引数があり、1 つ以上のオペランドがあります。
numpy.einsum(subscripts : string, *operands : List[np.ndarray])
添字引数は、オペランドの軸を操作および結合する方法を numpy に指示する「ミニ言語」です。 最初は少し読みにくいですが、コツを掴めば悪くありません。
単一オペランド
最初の例として、np.einsum を使用して行列 A:
の軸を交換してみましょう (別名転置)。
M = np.einsum('ij->ji', A)
文字 i と j は、A の 1 番目と 2 番目の軸にバインドされます。Numpy は、出現する順序で文字を軸にバインドしますが、明示的であれば、numpy は使用する文字を気にしません。 たとえば、a と b を使用することもできますが、同じように機能します。
M = np.einsum('ab->ba', A)
ただし、オペランド内の軸と同じ数の文字を指定する必要があります。 A には 2 つの軸があるため、2 つの異なる文字を指定する必要があります。 次の例は、機能しません。下付き文字式にはバインドする文字が 1 文字しかないためです。i:
# broken
M = np.einsum('i->i', A)
一方、オペランドの軸が実際に 1 つだけの場合 (つまり、ベクトルです)、1 文字の添え字式は問題なく機能しますが、ベクトルをそのままにするためあまり役に立ちません。現状のまま:
m = np.einsum('i->i', a)
軸上の合計
しかし、この作戦はどうでしょうか? 右側にはiがありません。 これは有効ですか?
c = np.einsum('i->', a)
驚いたことに、そうです!
np.einsum の本質を理解するための最初の鍵は次のとおりです。軸が右側から 省略されている場合、軸は合計されます。

コード:
c = 0 I = len(a) for i in range(I): c += a[i]
合計の動作は単一の軸に限定されません。 たとえば、次の添字式を使用すると、2 つの軸を一度に合計できます: c = np.einsum('ij->', A):

両方の軸に対応する Python コードを次に示します。
c = 0
I,J = A.shape
for i in range(I):
for j in range(J):
c += A[i,j]
しかし、それだけではありません。創造力を発揮していくつかの軸を合計し、他の軸はそのままにすることもできます。 例: np.einsum('ij->i', A) は行列 A の行を合計し、長さ j の行合計のベクトルを残します:

コード:
numpy.einsum(subscripts : string, *operands : List[np.ndarray])
同様に、np.einsum('ij->j', A) は A の列を合計します。

コード:
M = np.einsum('ij->ji', A)
2 つのオペランド
単一のオペランドで実行できることには制限があります。 2 つのオペランドを使用すると、物事はさらに面白く (そして便利に) なります。
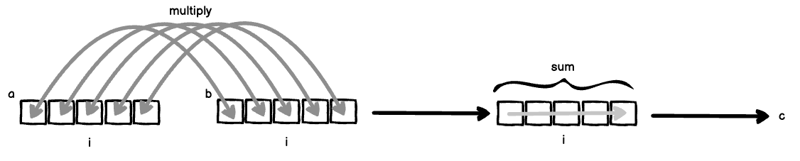
2 つのベクトル a = [a_1, a_2, ... ] と b = [a_1, a_2, ...] があると仮定します。
len(a) === len(b) の場合、次のように内積 (ドット積とも呼ばれます) を計算できます。
M = np.einsum('ab->ba', A)
ここでは 2 つのことが同時に起こっています:
- i は a と b の両方にバインドされているため、a と b は「並んで」から乗算されます: a[i] * b[i]。
- 右辺からインデックス i が除外されているため、それを除くために軸 i を合計します。
(1) と (2) を組み合わせると、古典的な内積が得られます。
コード:
# broken
M = np.einsum('i->i', A)
さて、添え字の式から i を省略しなかったと仮定しましょう。すべての a[i] と b[i] を乗算し、i の合計をしませんします。
m = np.einsum('i->i', a)

コード:
c = np.einsum('i->', a)
これは要素ごとの乗算 (または行列のアダマール積) とも呼ばれ、通常は numpy メソッド np.multiply を介して実行されます。
添字の公式には、外積と呼ばれる 3 番目のバリエーションがまだあります。
c = 0 I = len(a) for i in range(I): c += a[i]
この添字式では、a と b の軸は別々の文字にバインドされているため、別々の「ループ変数」として扱われます。 したがって、C には、すべての i と j に対して行列に配置されたエントリ a[i] * b[j] があります。

コード:
c = 0
I,J = A.shape
for i in range(I):
for j in range(J):
c += A[i,j]
3 つのオペランド
外積をさらに一歩進めて、3 オペランドのバージョンを次に示します。
I,J = A.shape
r = np.zeros(I)
for i in range(I):
for j in range(J):
r[i] += A[i,j]

3 つのオペランドの外積に相当する Python コードは次のとおりです。
I,J = A.shape
r = np.zeros(J)
for i in range(I):
for j in range(J):
r[j] += A[i,j]
さらに進むと、軸の右側に ik の代わりに ki を書くことで結果を転置するだけでなく、軸を省略して合計することを妨げるものは何もありません。 ->:
numpy.einsum(subscripts : string, *operands : List[np.ndarray])
同等の Python コードは次のようになります:
M = np.einsum('ij->ji', A)
これで、複雑なテンソル演算を簡単に指定する方法がわかっていただけたと思います。 numpy をより広範囲に使用したとき、複雑な tensor 演算を実装する必要があるときは必ず np.einsum に手を伸ばすようになりました。
私の経験では、np.einsum を使用すると、後でコードを読みやすくなります。上記の演算を添え字から直接読み取ることができます。「3 つのベクトルの外積、中間軸の合計、および最終結果の転置」 」。 複雑な一連の厄介な操作を読まなければならなかった場合、私は舌を巻くかもしれません。
実用的な例
実際的な例として、古典的な論文「Attending is All You Need」から、LLM の中心となる方程式を実装してみましょう。
式1 では、注意メカニズムについて説明します:

用語 に焦点を当てます。 QKT なぜなら、softmax は np.einsum とスケーリング係数では計算できないからです。 dk 1 適用するのは簡単です。
QKT term は、n 個のキーを使用した m 個のクエリのドット積を表します。 Q は行列に積み上げられた m 個の d 次元行ベクトルのコレクションであるため、Q の形状は md です。同様に、K は行列に積み上げられた n 個の d 次元行ベクトルのコレクションであるため、K の形状は md になります。
単一の Q と K の間の積は次のように記述されます:
np.einsum('md,nd->mn', Q, K)
添字方程式の記述方法により、行列の乗算の前に K を転置する必要がなくなったことに注意してください。

これは非常に簡単そうに見えますが、実際には、単なる伝統的な行列の乗算にすぎません。 しかし、まだ終わっていません。 Attending Is All You Need は マルチヘッド アテンション を使用します。これは、Q 行列と K 行列のインデックス付きコレクションに対して、実際に k 個の行列乗算が同時に発生することを意味します。 .
物事をもう少し明確にするために、製品を次のように書き換えることができます。 Q私K 私T .
つまり、Q と K の両方に追加の軸 i があることを意味します。
さらに、私たちがトレーニング環境にいる場合、おそらくそのような多頭の注意操作のバッチを実行していることになります。
おそらく、バッチ軸 b に沿ってサンプルのバッチに対して操作を実行したいと考えられます。 したがって、完成した製品は次のようになります:
numpy.einsum(subscripts : string, *operands : List[np.ndarray])
ここでは 4 軸テンソルを扱っているため、図を省略します。 しかし、前の図を「スタッキング」してマルチヘッド軸 i を取得し、次にそれらの「スタック」を「スタッキング」してバッチ軸 b を取得することをイメージできるかもしれません。
他の numpy メソッドを組み合わせてこのような操作をどのように実装するかを理解するのは困難です。 しかし、少し調べてみれば、何が起こっているかは明らかです。バッチ全体、行列 Q と K のコレクションに対して、行列乗算 Qt(K) を実行します。
さて、それは素晴らしいことではありませんか?
恥知らずなプラグ
創設者モードのグラインドを 1 年間行った後、仕事を探しています。 私はさまざまな技術分野とプログラミング言語で 15 年以上の経験があり、チームの管理も経験しました。 数学と統計が重点分野です。 DMして話しましょう!
以上がnumpy&#s einsum の理不尽な有用性の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1672
1672
 14
1428
52
1332
25
1276
29
1256
24
14
1428
52
1332
25
1276
29
1256
24

 Python vs. C:曲線と使いやすさの学習
Apr 19, 2025 am 12:20 AM
Python vs. C:曲線と使いやすさの学習
Apr 19, 2025 am 12:20 AM
Pythonは学習と使用が簡単ですが、Cはより強力ですが複雑です。 1。Python構文は簡潔で初心者に適しています。動的なタイピングと自動メモリ管理により、使いやすくなりますが、ランタイムエラーを引き起こす可能性があります。 2.Cは、高性能アプリケーションに適した低レベルの制御と高度な機能を提供しますが、学習しきい値が高く、手動メモリとタイプの安全管理が必要です。
 Pythonと時間:勉強時間を最大限に活用する
Apr 14, 2025 am 12:02 AM
Pythonと時間:勉強時間を最大限に活用する
Apr 14, 2025 am 12:02 AM
限られた時間でPythonの学習効率を最大化するには、PythonのDateTime、時間、およびスケジュールモジュールを使用できます。 1. DateTimeモジュールは、学習時間を記録および計画するために使用されます。 2。時間モジュールは、勉強と休息の時間を設定するのに役立ちます。 3.スケジュールモジュールは、毎週の学習タスクを自動的に配置します。
 Python vs. C:パフォーマンスと効率の探索
Apr 18, 2025 am 12:20 AM
Python vs. C:パフォーマンスと効率の探索
Apr 18, 2025 am 12:20 AM
Pythonは開発効率でCよりも優れていますが、Cは実行パフォーマンスが高くなっています。 1。Pythonの簡潔な構文とリッチライブラリは、開発効率を向上させます。 2.Cのコンピレーションタイプの特性とハードウェア制御により、実行パフォーマンスが向上します。選択を行うときは、プロジェクトのニーズに基づいて開発速度と実行効率を比較検討する必要があります。
 Pythonの学習:2時間の毎日の研究で十分ですか?
Apr 18, 2025 am 12:22 AM
Pythonの学習:2時間の毎日の研究で十分ですか?
Apr 18, 2025 am 12:22 AM
Pythonを1日2時間学ぶだけで十分ですか?それはあなたの目標と学習方法に依存します。 1)明確な学習計画を策定し、2)適切な学習リソースと方法を選択します。3)実践的な実践とレビューとレビューと統合を練習および統合し、統合すると、この期間中にPythonの基本的な知識と高度な機能を徐々に習得できます。
 Python vs. C:重要な違いを理解します
Apr 21, 2025 am 12:18 AM
Python vs. C:重要な違いを理解します
Apr 21, 2025 am 12:18 AM
PythonとCにはそれぞれ独自の利点があり、選択はプロジェクトの要件に基づいている必要があります。 1)Pythonは、簡潔な構文と動的タイピングのため、迅速な開発とデータ処理に適しています。 2)Cは、静的なタイピングと手動メモリ管理により、高性能およびシステムプログラミングに適しています。
 Python Standard Libraryの一部はどれですか:リストまたは配列はどれですか?
Apr 27, 2025 am 12:03 AM
Python Standard Libraryの一部はどれですか:リストまたは配列はどれですか?
Apr 27, 2025 am 12:03 AM
PythonListSarePartOfThestAndardarenot.liestareBuilting-in、versatile、forStoringCollectionsのpythonlistarepart。
 Python:自動化、スクリプト、およびタスク管理
Apr 16, 2025 am 12:14 AM
Python:自動化、スクリプト、およびタスク管理
Apr 16, 2025 am 12:14 AM
Pythonは、自動化、スクリプト、およびタスク管理に優れています。 1)自動化:OSやShutilなどの標準ライブラリを介してファイルバックアップが実現されます。 2)スクリプトの書き込み:Psutilライブラリを使用してシステムリソースを監視します。 3)タスク管理:スケジュールライブラリを使用してタスクをスケジュールします。 Pythonの使いやすさと豊富なライブラリサポートにより、これらの分野で優先ツールになります。
 科学コンピューティングのためのPython:詳細な外観
Apr 19, 2025 am 12:15 AM
科学コンピューティングのためのPython:詳細な外観
Apr 19, 2025 am 12:15 AM
科学コンピューティングにおけるPythonのアプリケーションには、データ分析、機械学習、数値シミュレーション、視覚化が含まれます。 1.numpyは、効率的な多次元配列と数学的関数を提供します。 2。ScipyはNumpy機能を拡張し、最適化と線形代数ツールを提供します。 3. Pandasは、データ処理と分析に使用されます。 4.matplotlibは、さまざまなグラフと視覚的な結果を生成するために使用されます。
