

CSV ファイルを DJANGO REST にアップロードする方法

CSV ファイルを Django REST にアップロードする (特にアトミック設定の場合) のは簡単な作業ですが、これから共有するいくつかのトリックを見つけるまでは戸惑い続けました。
この記事では、(フロントエンドの代わりに) postman を使用し、写真経由でリクエストを送信するために postman で設定する必要がある内容も共有します。
私たちが望むもの
- Django Rest 経由で CSV を DB にアップロード
- 操作をアトミックにします。つまり、CSV の行にエラーがあると、操作全体が完全にロールバックされます。そのため、CSV ファイルを切り取るストレス、つまり、切り取られた行の部分を特定するという頭痛の種を避けることができます。 DBと途中エラーでできなかったDB! (部分エントリー)。したがって、私たちは全か無かの物事を望んでいます !!
メソッド
- Django と Django REST がすでにインストールされていると仮定すると、最初のステップは、データ操作用の Python ライブラリである pandas をインストールすることです。
pip install pandas
- postman の次の手順: body タブで、form-data を選択し、キー (任意の名前) を追加します。同じセルで、セルの右端にマウスを置き、ドロップダウンを使用してオプションをテキストからファイルに変更します。これを実行すると、Postman は自動的にヘッダーの Content-Type を multipart/form-data に設定します。
値のセルで、[ファイルを選択] ボタンをクリックし、CSV をアップロードします。以下のスクリーンショットを確認してください

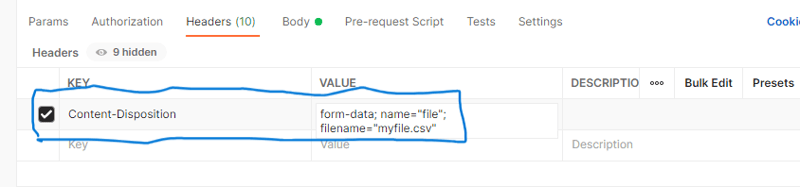
ヘッダーの下で、Content-Disposition と値を form-data に設定します。名前 = "ファイル";ファイル名 = "あなたのファイル名.csv"。 your_file_name.csv を実際のファイル名に置き換えます。以下のスクリーンショットを確認してください。
- Django ビューのコードは次のとおりです。
from rest_framework import status
from rest_framework.views import APIView
from rest_framework.parsers import FileUploadParser
from rest_framework.response import Response
from .models import BiodataModel
from django.db import transaction
import pandas as pd
class UploadCSVFile(APIView):
parser_classes = [FileUploadParser]
def post(self,request):
csv_file = request.FILES.get('file')
if not csv_file:
return Response({"error": "No file provided"}, status=status.HTTP_400_BAD_REQUEST)
# Validate file type
if not csv_file.name.endswith('.csv'):
return Response({"error": "File is not CSV type"}, status=status.HTTP_400_BAD_REQUEST)
df = pd.read_csv(csv_file, delimiter=',',skiprows=3,dtype=str).iloc[:-1]
df = df.where(pd.notnull(df), None)
bulk_data=[]
for index, row in df.iterrows():
try:
row_instance= BiodataModel(
name=row.get('name'),
age=row.get('age'),
address =row.get('address'))
row_instance.full_clean()
bulk_data.append(row_instance)
except Exception as e:
return Response({"error": f'Error at row {index + 2} -> {e}'}, status=status.HTTP_400_BAD_REQUEST)
try:
with transaction.atomic():
BiodataModel.objects.bulk_create(bulk_data)
except Exception as e:
return Response({"error": f'Bulk create error--{e}'}, status=status.HTTP_400_BAD_REQUEST)
return Response({"msg":"CSV file processed successfully"}, status=status.HTTP_201_CREATED)
上記のコードの説明:
コードは、必要なパッケージをインポートし、クラスベースのビューを定義し、パーサー クラス (FileUploadParser) を設定することから始まります。クラスの post メソッドの最初の部分は、request.FILES からファイルを取得し、その可用性を確認しようとします。
次に、マイナー検証で拡張子をチェックして CSV であることを確認します。
次の部分では、それを pandas データフレーム (スプレッドシートによく似ています) にロードします。
df = pd.read_csv(csv_file, delimiter=',',skiprows=3,dtype=str).iloc[:-1]
ローディング関数に渡される引数のいくつかについて説明します:
ハギプロウ
ロードされた CSV ファイルを読み取る際、この場合の CSV はネットワーク経由で渡されるため、ファイルの先頭と末尾にメタデータのようなものが追加されることに注意してください。これらは煩わしい場合があり、カンマ区切り値 (CSV) 形式ではないため、実際には解析時にエラーが発生する可能性があります。これは、メタデータとヘッダーを含む最初の 3 行をスキップして CSV の本文に直接配置するために、skiprows=3 を使用した理由を説明しています。 Skiprows を削除するか、より小さい数値を使用すると、次のようなエラーが発生する可能性があります: データのトークン化エラー。 C エラーが発生した場合、データがヘッダーから始まっていることに気づくかもしれません。
dtype=str
Panda は、特定の列のデータ型を推測することで賢明であることを証明することを好みます。すべての値を文字列として使用したかったので、 dtype=str
区切り文字
セルの分割方法を指定します。通常、デフォルトはカンマです。
iloc[:-1]
iloc を使用してデータフレームをスライスし、df の最後にあるメタデータを削除する必要がありました。
次に、次の行 df = df.where(pd.notnull(df), None) は、すべての NaNvalue を None に変換します。 NaN は、パンダが None を表すために使用する代用の値です。
次のブロックは少し難しいです。データフレーム内のすべての行をループし、BiodataModel で行データをインスタンス化し、一括作成では Django 検証をバイパスするため、full_clean() メソッドで (シリアライザー レベルではなく) モデル レベルの検証を実行し、作成操作を というリストに追加します。バルクデータ。はい、追加はまだ実行されていません!アトミックな操作 (バッチ レベルで) を実行しようとしているので、all または None が必要であることを思い出してください。行を個別に保存しても、all or none の動作は行われません。
それでは最後の重要な部分です。 transaction.atomic() ブロック (全か無かの動作を提供します) 内で、BiodataModel.objects.bulk_create(bulk_data) を実行して、すべての行を一度に保存します。
もう一つ。 for ループ内のインデックス変数と例外ブロックに注目してください。 Excel ファイルで見たときに、その値がその値が存在する行と正確に一致しなかったため、Exception ブロックのエラー メッセージで df.iterrows() から派生したインデックス変数に 2 を追加しました。 excel ブロックはあらゆるエラーをキャッチし、Excel で開いたときに正確な行番号を含むエラー メッセージを構築するため、アップロード者は Excel ファイル内の行を簡単に見つけることができます。
読んでいただきありがとうございます!!!
使用されるツールのバージョン
from rest_framework import status
from rest_framework.views import APIView
from rest_framework.parsers import FileUploadParser
from rest_framework.response import Response
from .models import BiodataModel
from django.db import transaction
import pandas as pd
class UploadCSVFile(APIView):
parser_classes = [FileUploadParser]
def post(self,request):
csv_file = request.FILES.get('file')
if not csv_file:
return Response({"error": "No file provided"}, status=status.HTTP_400_BAD_REQUEST)
# Validate file type
if not csv_file.name.endswith('.csv'):
return Response({"error": "File is not CSV type"}, status=status.HTTP_400_BAD_REQUEST)
df = pd.read_csv(csv_file, delimiter=',',skiprows=3,dtype=str).iloc[:-1]
df = df.where(pd.notnull(df), None)
bulk_data=[]
for index, row in df.iterrows():
try:
row_instance= BiodataModel(
name=row.get('name'),
age=row.get('age'),
address =row.get('address'))
row_instance.full_clean()
bulk_data.append(row_instance)
except Exception as e:
return Response({"error": f'Error at row {index + 2} -> {e}'}, status=status.HTTP_400_BAD_REQUEST)
try:
with transaction.atomic():
BiodataModel.objects.bulk_create(bulk_data)
except Exception as e:
return Response({"error": f'Bulk create error--{e}'}, status=status.HTTP_400_BAD_REQUEST)
return Response({"msg":"CSV file processed successfully"}, status=status.HTTP_201_CREATED)
以上がCSV ファイルを DJANGO REST にアップロードする方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1670
1670
 14
1428
52
1329
25
1276
29
1256
24
14
1428
52
1329
25
1276
29
1256
24

 Python vs. C:曲線と使いやすさの学習
Apr 19, 2025 am 12:20 AM
Python vs. C:曲線と使いやすさの学習
Apr 19, 2025 am 12:20 AM
Pythonは学習と使用が簡単ですが、Cはより強力ですが複雑です。 1。Python構文は簡潔で初心者に適しています。動的なタイピングと自動メモリ管理により、使いやすくなりますが、ランタイムエラーを引き起こす可能性があります。 2.Cは、高性能アプリケーションに適した低レベルの制御と高度な機能を提供しますが、学習しきい値が高く、手動メモリとタイプの安全管理が必要です。
 Pythonと時間:勉強時間を最大限に活用する
Apr 14, 2025 am 12:02 AM
Pythonと時間:勉強時間を最大限に活用する
Apr 14, 2025 am 12:02 AM
限られた時間でPythonの学習効率を最大化するには、PythonのDateTime、時間、およびスケジュールモジュールを使用できます。 1. DateTimeモジュールは、学習時間を記録および計画するために使用されます。 2。時間モジュールは、勉強と休息の時間を設定するのに役立ちます。 3.スケジュールモジュールは、毎週の学習タスクを自動的に配置します。
 Python vs. C:パフォーマンスと効率の探索
Apr 18, 2025 am 12:20 AM
Python vs. C:パフォーマンスと効率の探索
Apr 18, 2025 am 12:20 AM
Pythonは開発効率でCよりも優れていますが、Cは実行パフォーマンスが高くなっています。 1。Pythonの簡潔な構文とリッチライブラリは、開発効率を向上させます。 2.Cのコンピレーションタイプの特性とハードウェア制御により、実行パフォーマンスが向上します。選択を行うときは、プロジェクトのニーズに基づいて開発速度と実行効率を比較検討する必要があります。
 Python vs. C:重要な違いを理解します
Apr 21, 2025 am 12:18 AM
Python vs. C:重要な違いを理解します
Apr 21, 2025 am 12:18 AM
PythonとCにはそれぞれ独自の利点があり、選択はプロジェクトの要件に基づいている必要があります。 1)Pythonは、簡潔な構文と動的タイピングのため、迅速な開発とデータ処理に適しています。 2)Cは、静的なタイピングと手動メモリ管理により、高性能およびシステムプログラミングに適しています。
 Pythonの学習:2時間の毎日の研究で十分ですか?
Apr 18, 2025 am 12:22 AM
Pythonの学習:2時間の毎日の研究で十分ですか?
Apr 18, 2025 am 12:22 AM
Pythonを1日2時間学ぶだけで十分ですか?それはあなたの目標と学習方法に依存します。 1)明確な学習計画を策定し、2)適切な学習リソースと方法を選択します。3)実践的な実践とレビューとレビューと統合を練習および統合し、統合すると、この期間中にPythonの基本的な知識と高度な機能を徐々に習得できます。
 Python Standard Libraryの一部はどれですか:リストまたは配列はどれですか?
Apr 27, 2025 am 12:03 AM
Python Standard Libraryの一部はどれですか:リストまたは配列はどれですか?
Apr 27, 2025 am 12:03 AM
PythonListSarePartOfThestAndardarenot.liestareBuilting-in、versatile、forStoringCollectionsのpythonlistarepart。
 Python:自動化、スクリプト、およびタスク管理
Apr 16, 2025 am 12:14 AM
Python:自動化、スクリプト、およびタスク管理
Apr 16, 2025 am 12:14 AM
Pythonは、自動化、スクリプト、およびタスク管理に優れています。 1)自動化:OSやShutilなどの標準ライブラリを介してファイルバックアップが実現されます。 2)スクリプトの書き込み:Psutilライブラリを使用してシステムリソースを監視します。 3)タスク管理:スケジュールライブラリを使用してタスクをスケジュールします。 Pythonの使いやすさと豊富なライブラリサポートにより、これらの分野で優先ツールになります。
 Web開発用のPython:主要なアプリケーション
Apr 18, 2025 am 12:20 AM
Web開発用のPython:主要なアプリケーション
Apr 18, 2025 am 12:20 AM
Web開発におけるPythonの主要なアプリケーションには、DjangoおよびFlaskフレームワークの使用、API開発、データ分析と視覚化、機械学習とAI、およびパフォーマンスの最適化が含まれます。 1。DjangoandFlask Framework:Djangoは、複雑な用途の迅速な発展に適しており、Flaskは小規模または高度にカスタマイズされたプロジェクトに適しています。 2。API開発:フラスコまたはdjangorestFrameworkを使用して、Restfulapiを構築します。 3。データ分析と視覚化:Pythonを使用してデータを処理し、Webインターフェイスを介して表示します。 4。機械学習とAI:Pythonは、インテリジェントWebアプリケーションを構築するために使用されます。 5。パフォーマンスの最適化:非同期プログラミング、キャッシュ、コードを通じて最適化
