

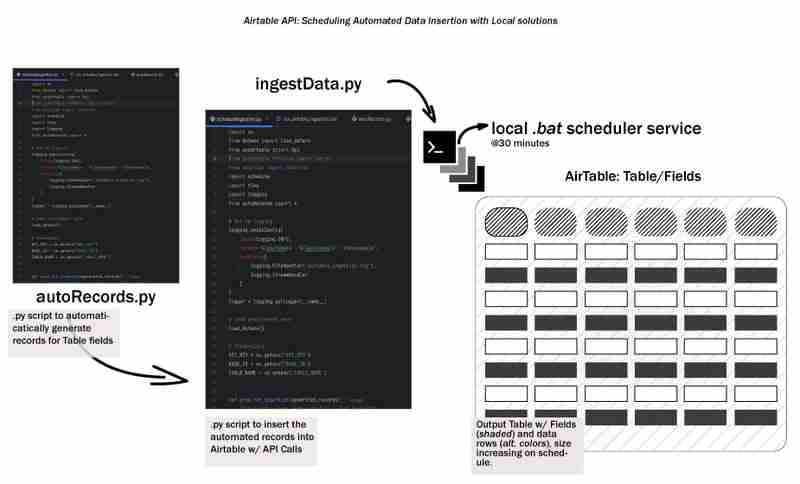
データのライフサイクル全体は、データを生成し、それを何らかの方法でどこかに保存することから始まります。これを初期段階のデータ ライフサイクルと呼び、ローカル ワークフローを使用して Airtable へのデータの取り込みを自動化する方法を検討します。開発環境のセットアップ、取り込みプロセスの設計、バッチ スクリプトの作成、ワークフローのスケジュール設定について説明します。これにより、物事をシンプルに、ローカル/再現可能に、アクセスしやすく保ちます。
まずはAirtableについてお話しましょう。 Airtable は、スプレッドシートのシンプルさとデータベースの構造を融合した強力で柔軟なツールです。情報の整理、プロジェクトの管理、タスクの追跡に最適で、無料利用枠もあります!
このプロジェクトは Python で開発するので、お気に入りの IDE を起動して仮想環境を作成します
# from your terminal python -m venv <environment_name> <environment_name>\Scripts\activate
Airtable を使い始めるには、Airtable の Web サイトにアクセスしてください。無料アカウントにサインアップしたら、新しいワークスペースを作成する必要があります。ワークスペースは、関連するすべてのテーブルとデータのコンテナーと考えてください。
次に、ワークスペース内に新しいテーブルを作成します。テーブルは基本的に、データを保存するスプレッドシートです。データの構造に一致するようにテーブルのフィールド (列) を定義します。
これはチュートリアルで使用されるフィールドの抜粋です。テキスト、日付、および 数値の組み合わせです:
スクリプトを Airtable に接続するには、API キーまたはパーソナル アクセス トークンを生成する必要があります。このキーはパスワードとして機能し、スクリプトが Airtable データと対話できるようにします。キーを生成するには、Airtable アカウント設定に移動し、API セクションを見つけて、指示に従って新しいキーを作成します。
*API キーを安全に保管してください。パブリックに共有したり、パブリック リポジトリにコミットしたりしないでください。 *
次に、requirements.txt をタッチします。この .txt ファイル内に次のパッケージを配置します:
pyairtable schedule faker python-dotenv
ここで pip install -rrequirements.txt を実行して、必要なパッケージをインストールします。
このステップはスクリプトを作成する場所です。.env は認証情報を保存する場所です。autoRecords.py - 定義されたフィールドと ingestData.py : Airtable にレコードを挿入します。
# from your terminal python -m venv <environment_name> <environment_name>\Scripts\activate
それはいいですね。この従業員データ ジェネレーターのブログ投稿に焦点を当てたサブトピック コンテンツをまとめましょう。
従業員データが関係するプロジェクトに取り組む場合、現実的なサンプル データを生成する信頼できる方法があれば役立つことがよくあります。人事管理システム、従業員ディレクトリ、またはその間のものを構築している場合でも、堅牢なテスト データにアクセスできると、開発が合理化され、アプリケーションの復元力が高まります。
このセクションでは、さまざまな関連フィールドを持つランダムな従業員レコードを生成する Python スクリプトについて説明します。このツールは、現実的なデータをアプリケーションに迅速かつ簡単に入力する必要がある場合に貴重な資産となります。
データ生成プロセスの最初のステップは、各従業員レコードの一意の識別子を作成することです。アプリケーションでは各従業員を一意に参照する方法が必要になる可能性が高いため、これは重要な考慮事項です。私たちのスクリプトには、次の ID を生成する簡単な関数が含まれています:
pyairtable schedule faker python-dotenv
この関数は、「N-#####」形式で一意の ID を生成します。数値はランダムな 5 桁の値です。この形式は、特定のニーズに合わせてカスタマイズできます。
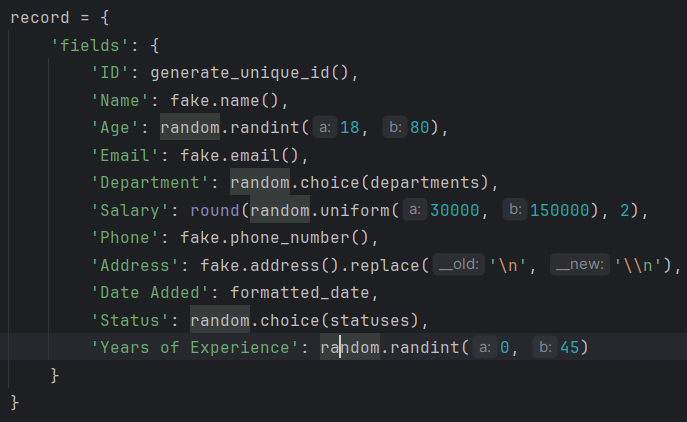
次に、従業員レコード自体を生成するコア関数を見てみましょう。 generate_random_records() 関数は、作成するレコードの数を入力として受け取り、辞書のリストを返します。各辞書は、さまざまなフィールドを持つ従業員を表します。
"https://airtable.com/app########/tbl######/viw####?blocks=show" BASE_ID = 'app########' TABLE_NAME = 'tbl######' API_KEY = '#######'
この関数は Faker ライブラリを使用して、名前、電子メール、電話番号、住所などのさまざまな従業員フィールドの現実的なデータを生成します。また、年齢範囲や給与範囲を妥当な値に制限するなど、いくつかの基本的な制約も含まれています。
この関数は辞書のリストを返します。各辞書は Airtable と互換性のある形式で従業員レコードを表します。
最後に、prepare_records_for_airtable() 関数を見てみましょう。この関数は、従業員レコードのリストを取得し、各レコードの「フィールド」部分を抽出します。これは、Airtable がデータのインポートに期待する形式です:
def generate_unique_id():
"""Generate a Unique ID in the format N-#####"""
return f"N-{random.randint(10000, 99999)}"
この関数はデータ構造を簡素化し、生成されたデータを Airtable や他のシステムと統合する際の作業を容易にします。
すべてをまとめる
このデータ生成ツールを使用するには、必要なレコード数を指定してgenerate_random_records() 関数を呼び出し、結果のリストを prepare_records_for_airtable() 関数に渡します。
# from your terminal python -m venv <environment_name> <environment_name>\Scripts\activate
これにより、ランダムな従業員レコードが 2 つ生成され、元の形式で印刷され、Airtable に適したフラット形式でレコードが印刷されます。
実行:
pyairtable schedule faker python-dotenv
出力:
"https://airtable.com/app########/tbl######/viw####?blocks=show" BASE_ID = 'app########' TABLE_NAME = 'tbl######' API_KEY = '#######'
現実的な従業員データの生成に加えて、スクリプトはそのデータを Airtable とシームレスに統合する機能も提供します
生成されたデータを Airtable に挿入する前に、プラットフォームへの接続を確立する必要があります。私たちのスクリプトは、pyairtable ライブラリを使用して Airtable API と対話します。まず、Airtable API キー、データを保存するベース ID とテーブル名など、必要な環境変数をロードします。
def generate_unique_id():
"""Generate a Unique ID in the format N-#####"""
return f"N-{random.randint(10000, 99999)}"
これらの認証情報を使用して、Airtable API クライアントを初期化し、操作したい特定のテーブルへの参照を取得できます。
def generate_random_records(num_records=10):
"""
Generate random records with reasonable constraints
:param num_records: Number of records to generate
:return: List of records formatted for Airtable
"""
records = []
# Constants
departments = ['Sales', 'Engineering', 'Marketing', 'HR', 'Finance', 'Operations']
statuses = ['Active', 'On Leave', 'Contract', 'Remote']
for _ in range(num_records):
# Generate date in the correct format
random_date = datetime.now() - timedelta(days=random.randint(0, 365))
formatted_date = random_date.strftime('%Y-%m-%dT%H:%M:%S.000Z')
record = {
'fields': {
'ID': generate_unique_id(),
'Name': fake.name(),
'Age': random.randint(18, 80),
'Email': fake.email(),
'Department': random.choice(departments),
'Salary': round(random.uniform(30000, 150000), 2),
'Phone': fake.phone_number(),
'Address': fake.address().replace('\n', '\n'), # Escape newlines
'Date Added': formatted_date,
'Status': random.choice(statuses),
'Years of Experience': random.randint(0, 45)
}
}
records.append(record)
return records
これで接続が設定されたので、前のセクションのgenerate_random_records() 関数を使用して従業員レコードのバッチを作成し、それらを Airtable に挿入できます。
def prepare_records_for_airtable(records):
"""Convert records from nested format to flat format for Airtable"""
return [record['fields'] for record in records]
prep_for_insertion() 関数は、generate_random_records() によって返されたネストされたレコード形式を、Airtable API が期待するフラット形式に変換する役割を果たします。データの準備が完了したら、table.batch_create() メソッドを使用して、単一の一括操作でレコードを挿入します。
統合プロセスが堅牢でデバッグが容易であることを保証するために、いくつかの基本的なエラー処理およびログ機能も組み込まれています。データ挿入プロセス中にエラーが発生した場合、スクリプトはトラブルシューティングに役立つエラー メッセージを記録します。
if __name__ == "__main__":
records = generate_random_records(2)
print(records)
prepared_records = prepare_records_for_airtable(records)
print(prepared_records)
以前のスクリプトの強力なデータ生成機能とここで示す統合機能を組み合わせることで、Airtable ベースのアプリケーションに現実的な従業員データを迅速かつ確実に入力できます。
データ取り込みプロセスを完全に自動化するには、Python スクリプトを定期的に実行するバッチ スクリプト (.bat ファイル) を作成します。これにより、手動介入なしでデータ取り込みが自動的に行われるように設定できます。
ここでは、ingestData.py スクリプトの実行に使用できるバッチ スクリプトの例を示します。
python autoRecords.py
このスクリプトの重要な部分を分析してみましょう:
このバッチ スクリプトが自動的に実行されるようにスケジュールするには、Windows タスク スケジューラを使用できます。手順の概要を次に示します:

これで、Windows タスク スケジューラは指定された間隔でバッチ スクリプトを自動的に実行し、Airtable データが手動介入なしで定期的に更新されるようになります。
これは、テスト、開発、さらにはデモンストレーションの目的でも非常に貴重なツールとなる可能性があります。
このガイドでは、必要な開発環境をセットアップする方法、取り込みプロセスを設計する方法、タスクを自動化するバッチ スクリプトを作成する方法、無人実行のワークフローをスケジュールする方法を学習しました。現在、私たちはローカル オートメーションの力を活用してデータ取り込み操作を合理化し、Airtable を活用したデータ エコシステムから貴重な洞察を引き出す方法をしっかりと理解しています。
自動データ取り込みプロセスを設定したので、この基盤に基づいて Airtable データからさらに多くの価値を引き出す方法はたくさんあります。コードを試し、新しいユースケースを探索し、その経験をコミュニティと共有することをお勧めします。
始めるためのアイデアをいくつか紹介します:
可能性は無限大です!この自動化されたデータ取り込みプロセスをどのように構築し、Airtable データから新しい洞察と価値を引き出すかを見るのが楽しみです。ためらわずに実験し、コラボレーションし、進捗状況を共有してください。私はあなたをサポートするためにここにいます。
完全なコード https://github.com/AkanimohOD19A/scheduling_airtable_insertion を参照してください。完全なビデオ チュートリアルも準備中です。
以上がローカル ワークフロー: Airtable へのデータ取り込みのオーケストレーションの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



