

リバース エンジニアリング GraphQL のpersistedQuery 拡張機能

GraphQL は、MongoDB クエリと同様に、Web サイトのバックエンドから深くネストされた構造化データを取得するためのクエリ言語です。
リクエストは通常、次のような本文を持つ一般的な /graphql エンドポイントへの POST です。

しかし、大規模なデータ構造では、これは非効率的になります。POST リクエスト本文で大規模なクエリを送信することになります。これは (ほぼ常に) 同じであり、Web サイトの更新時にのみ変更されます。 POST リクエストはキャッシュできないなどの理由から、「persisted queries」と呼ばれる拡張機能が開発されました。これはスクレイピング防止の秘密ではありません。これに関する公開ドキュメントはここで読むことができます。
TLDR: クライアントはクエリ テキストの sha256 ハッシュを計算し、そのハッシュのみを送信します。さらに、これらすべてを GET リクエストのクエリ文字列に組み込んで、簡単にキャッシュできるようにすることもできます。以下は Zillow
からのリクエストの例です。
ご覧のとおり、これは、persistedQuery 拡張機能、クエリのハッシュ、クエリに埋め込まれる変数に関するメタデータにすぎません。
これは、expedia.com からの別のリクエストです。POST として送信されましたが、同じ拡張子が付いています。

これは主に Web サイトのパフォーマンスを最適化しますが、Web スクレイピングにはいくつかの課題が生じます。
- GET リクエストは通常、ブロックされる傾向が高くなります。
- 非表示のクエリ パラメータ: 完全なクエリがわからないため、Web サイトが「永続的なクエリが見つかりません」というエラーで応答した場合 (ハッシュだけでなく完全なクエリを送信するように求められます)、クエリを送信することはできません。送信してください。
- Web サイトが少しでも変更され、クライアントが新しいクエリを要求し始めると、たとえ古いクエリがまだ機能するとしても、サーバーはすぐにその ID/ハッシュを忘れてしまい、このハッシュを使用したリクエストは機能しなくなります。繰り返しますが、クエリ テキスト全体をサーバーに「通知」することはできないためです。
したがって、さまざまな理由で、クエリ テキスト全体を抽出する必要が生じる場合があります。 Web サイトの JavaScript を調べてみると、運が良ければクエリ テキスト全体が見つかるかもしれませんが、多くの場合、クエリ テキストは複数のフラグメントなどから何らかの形で動的に構築されています。
そこで、私たちはより良い方法を考え出しました。クライアント側の JavaScript にはまったく触れないということです。代わりに、クライアントがサーバーが知らないハッシュを使用しようとする状況をシミュレートしてみます。したがって、実行中のブラウザによって送信された (有効な) リクエストをインターセプトし、サーバーに渡す前にハッシュを偽のリクエストに変更する必要があります。
まさにこのユースケースに最適なツールが存在します。mitmproxy は、ユーザー自身のデバイス、Web サイト、またはアプリによって行われたリクエストをインターセプトし、単純な Python スクリプトでそれらを変更できるようにするオープンソース Python ライブラリです。
mitmproxy をダウンロードし、次のような Python スクリプトを準備します。
import json
def request(flow):
try:
dat = json.loads(flow.request.text)
dat[0]["extensions"]["persistedQuery"]["sha256Hash"] = "0d9e" # any bogus hex string here
flow.request.text = json.dumps(dat)
except:
pass
これは、mitmproxy がリクエストごとに実行するフックを定義します。リクエストの JSON 本文をロードし、ハッシュを任意の値に変更し、更新された JSON をリクエストの新しい本文として書き込みます。
ブラウザのリクエストを mitmproxy に再ルーティングすることも確認する必要があります。この目的のために、FoxyProxy と呼ばれるブラウザ拡張機能を使用します。 Firefox と Chrome の両方で利用できます。
次の設定でルートを追加するだけです:

これで、次のスクリプトを使用して mitmproxy を実行できるようになります: mitmweb -s script.py
これによりブラウザ タブが開き、傍受されたすべてのリクエストをリアルタイムで確認できます。

特定のパスに移動してリクエスト セクションのクエリを確認すると、ハッシュがガベージ値に置き換えられていることがわかります。
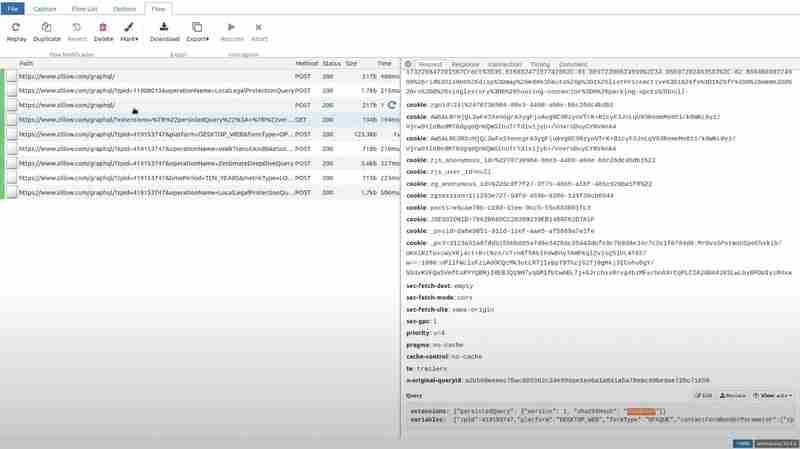
ここで、Zillow にアクセスして、拡張機能に試した特定のパスを開いて応答セクションに移動すると、クライアント側で PersistedQueryNotFound エラーが発生します。

Zillow のフロントエンドは、クエリ全体を POST リクエストとして送信します。

この POST リクエストからクエリとハッシュを直接抽出します。 Zillow サーバーがこのハッシュを忘れないようにするために、まったく同じクエリとハッシュを使用してこの POST リクエストを定期的に実行します。これにより、サーバーのキャッシュが消去またはリセットされたり、Web サイトが変更された場合でも、スクレイパーは引き続き動作します。
結論
永続化クエリは、GraphQL API の強力な最適化ツールであり、ペイロード サイズを最小限に抑え、GET リクエストのキャッシュを有効にすることで Web サイトのパフォーマンスを向上させます。ただし、これらは主にサーバーに保存されたハッシュへの依存と、それらのハッシュが無効になる可能性があるため、Web スクレイピングにとって重大な課題も引き起こします。
mitmproxy を使用して GraphQL リクエストをインターセプトおよび操作すると、複雑なクライアント側 JavaScript を深く掘り下げることなく完全なクエリ テキストを明らかにする効率的なアプローチが得られます。サーバーに PersistedQueryNotFound エラーで応答するように強制することで、完全なクエリ ペイロードをキャプチャし、それをスクレイピング目的に利用できます。抽出されたクエリを定期的に実行すると、サーバー側のキャッシュのリセットが発生したり、Web サイトが進化した場合でも、スクレイパーは機能し続けることが保証されます。
以上がリバース エンジニアリング GraphQL のpersistedQuery 拡張機能の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1675
1675
 14
1429
52
1333
25
1278
29
1257
24
14
1429
52
1333
25
1278
29
1257
24

 Python vs. JavaScript:学習曲線と使いやすさ
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:学習曲線と使いやすさ
Apr 16, 2025 am 12:12 AM
Pythonは、スムーズな学習曲線と簡潔な構文を備えた初心者により適しています。 JavaScriptは、急な学習曲線と柔軟な構文を備えたフロントエンド開発に適しています。 1。Python構文は直感的で、データサイエンスやバックエンド開発に適しています。 2。JavaScriptは柔軟で、フロントエンドおよびサーバー側のプログラミングで広く使用されています。
 JavaScriptとWeb:コア機能とユースケース
Apr 18, 2025 am 12:19 AM
JavaScriptとWeb:コア機能とユースケース
Apr 18, 2025 am 12:19 AM
Web開発におけるJavaScriptの主な用途には、クライアントの相互作用、フォーム検証、非同期通信が含まれます。 1)DOM操作による動的なコンテンツの更新とユーザーインタラクション。 2)ユーザーエクスペリエンスを改善するためにデータを提出する前に、クライアントの検証が実行されます。 3)サーバーとのリフレッシュレス通信は、AJAXテクノロジーを通じて達成されます。
 JavaScript in Action:実際の例とプロジェクト
Apr 19, 2025 am 12:13 AM
JavaScript in Action:実際の例とプロジェクト
Apr 19, 2025 am 12:13 AM
現実世界でのJavaScriptのアプリケーションには、フロントエンドとバックエンドの開発が含まれます。 1)DOM操作とイベント処理を含むTODOリストアプリケーションを構築して、フロントエンドアプリケーションを表示します。 2)node.jsを介してRestfulapiを構築し、バックエンドアプリケーションをデモンストレーションします。
 JavaScriptエンジンの理解:実装の詳細
Apr 17, 2025 am 12:05 AM
JavaScriptエンジンの理解:実装の詳細
Apr 17, 2025 am 12:05 AM
JavaScriptエンジンが内部的にどのように機能するかを理解することは、開発者にとってより効率的なコードの作成とパフォーマンスのボトルネックと最適化戦略の理解に役立つためです。 1)エンジンのワークフローには、3つの段階が含まれます。解析、コンパイル、実行。 2)実行プロセス中、エンジンはインラインキャッシュや非表示クラスなどの動的最適化を実行します。 3)ベストプラクティスには、グローバル変数の避け、ループの最適化、constとletsの使用、閉鎖の過度の使用の回避が含まれます。
 Python vs. JavaScript:コミュニティ、ライブラリ、リソース
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript:コミュニティ、ライブラリ、リソース
Apr 15, 2025 am 12:16 AM
PythonとJavaScriptには、コミュニティ、ライブラリ、リソースの観点から、独自の利点と短所があります。 1)Pythonコミュニティはフレンドリーで初心者に適していますが、フロントエンドの開発リソースはJavaScriptほど豊富ではありません。 2)Pythonはデータサイエンスおよび機械学習ライブラリで強力ですが、JavaScriptはフロントエンド開発ライブラリとフレームワークで優れています。 3)どちらも豊富な学習リソースを持っていますが、Pythonは公式文書から始めるのに適していますが、JavaScriptはMDNWebDocsにより優れています。選択は、プロジェクトのニーズと個人的な関心に基づいている必要があります。
 Python vs. JavaScript:開発環境とツール
Apr 26, 2025 am 12:09 AM
Python vs. JavaScript:開発環境とツール
Apr 26, 2025 am 12:09 AM
開発環境におけるPythonとJavaScriptの両方の選択が重要です。 1)Pythonの開発環境には、Pycharm、Jupyternotebook、Anacondaが含まれます。これらは、データサイエンスと迅速なプロトタイピングに適しています。 2)JavaScriptの開発環境には、フロントエンドおよびバックエンド開発に適したnode.js、vscode、およびwebpackが含まれます。プロジェクトのニーズに応じて適切なツールを選択すると、開発効率とプロジェクトの成功率が向上する可能性があります。
 JavaScript通訳者とコンパイラにおけるC/Cの役割
Apr 20, 2025 am 12:01 AM
JavaScript通訳者とコンパイラにおけるC/Cの役割
Apr 20, 2025 am 12:01 AM
CとCは、主に通訳者とJITコンパイラを実装するために使用されるJavaScriptエンジンで重要な役割を果たします。 1)cは、JavaScriptソースコードを解析し、抽象的な構文ツリーを生成するために使用されます。 2)Cは、Bytecodeの生成と実行を担当します。 3)Cは、JITコンパイラを実装し、実行時にホットスポットコードを最適化およびコンパイルし、JavaScriptの実行効率を大幅に改善します。
 Python vs. JavaScript:ユースケースとアプリケーションと比較されます
Apr 21, 2025 am 12:01 AM
Python vs. JavaScript:ユースケースとアプリケーションと比較されます
Apr 21, 2025 am 12:01 AM
Pythonはデータサイエンスと自動化により適していますが、JavaScriptはフロントエンドとフルスタックの開発により適しています。 1. Pythonは、データ処理とモデリングのためにNumpyやPandasなどのライブラリを使用して、データサイエンスと機械学習でうまく機能します。 2。Pythonは、自動化とスクリプトにおいて簡潔で効率的です。 3. JavaScriptはフロントエンド開発に不可欠であり、動的なWebページと単一ページアプリケーションの構築に使用されます。 4. JavaScriptは、node.jsを通じてバックエンド開発において役割を果たし、フルスタック開発をサポートします。
