

この記事では、公平な処理に関する前回の投稿に基づいて、Celery でのタスクの優先順位について説明します。タスクの優先順位は、カスタム基準に基づいてタスクに異なる優先レベルを割り当てることで、バックグラウンド処理の公平性と効率を高める方法を提供します。
タスクレベルの優先順位により、複雑な実装を行わずにタスクの実行をきめ細かく制御できます。すべてのタスクを優先度の値が割り当てられた単一のキューに送信することで、作業者は緊急度に基づいてタスクを処理できます。これにより、送信時間に関係なく公平な処理が保証されます。
たとえば、あるテナントが 100 個のタスクを送信し、その直後に別のテナントが 5 個のタスクを送信した場合、タスク レベルの優先度により、2 番目のテナントは 100 個のタスクがすべて完了するのを待つことができなくなります。
このアプローチでは、テナントのタスク数に基づいて優先度が動的に割り当てられます。 各テナントの最初のタスクは高い優先度で開始されますが、同時タスクが 10 個になるごとに優先度は低くなります。これにより、タスクが少ないテナントで不必要な遅延が発生することがなくなります。
まず、Celery と Redis をインストールします。
pip install celery redis
Redis をブローカーとして使用し、優先度ベースのタスク処理を有効にするように Celery を構成します。
from celery import Celery
app = Celery(
"tasks",
broker="redis://localhost:6379/0",
broker_connection_retry_on_startup=True,
)
app.conf.broker_transport_options = {
"priority_steps": list(range(10)),
"sep": ":",
"queue_order_strategy": "priority",
}
Redis を使用して各テナントのタスク数をキャッシュする動的優先度を計算するメソッドを定義します。
import redis
redis_client = redis.StrictRedis(host="localhost", port=6379, db=1)
def calculate_priority(tenant_id):
"""
Calculate task priority based on the number of tasks for the tenant.
"""
key = f"tenant:{tenant_id}:task_count"
task_count = int(redis_client.get(key) or 0)
return min(10, task_count // 10)
正常に完了したときにタスク数を減らすカスタム タスク クラスを作成します:
from celery import Task
class TenantAwareTask(Task):
def on_success(self, retval, task_id, args, kwargs):
tenant_id = kwargs.get("tenant_id")
if tenant_id:
key = f"tenant:{tenant_id}:task_count"
redis_client.decr(key, 1)
return super().on_success(retval, task_id, args, kwargs)
@app.task(name="tasks.send_email", base=TenantAwareTask)
def send_email(tenant_id, task_data):
"""
Simulate sending an email.
"""
sleep(1)
key = f"tenant:{tenant_id}:task_count"
task_count = int(redis_client.get(key) or 0)
logger.info("Tenant %s tasks: %s", tenant_id, task_count)
タスクのキーワード引数に tenant_id が含まれていることを確認して、さまざまなテナントのタスクをトリガーします。
if __name__ == "__main__":
tenant_id = 1
for _ in range(100):
priority = calculate_priority(tenant_id)
key = f"tenant:{tenant_id}:task_count"
redis_client.incr(key, 1)
send_email.apply_async(
kwargs={"tenant_id": tenant_id, "task_data": {}}, priority=priority
)
tenant_id = 2
for _ in range(10):
priority = calculate_priority(tenant_id)
key = f"tenant:{tenant_id}:task_count"
redis_client.incr(key, 1)
send_email.apply_async(
kwargs={"tenant_id": tenant_id, "task_data": {}}, priority=priority
)
完全なコードはここでご覧いただけます。
Celery ワーカーを起動し、タスクをトリガーします。
# Run the worker celery -A tasks worker --loglevel=info # Trigger the tasks python tasks.py
この設定は、Celery の優先キューを Redis と組み合わせて、テナントのアクティビティに基づいて優先順位を動的に調整することで公平なタスク処理を保証する方法を示しています。ワーカーの簡略化された出力を見てみましょう:
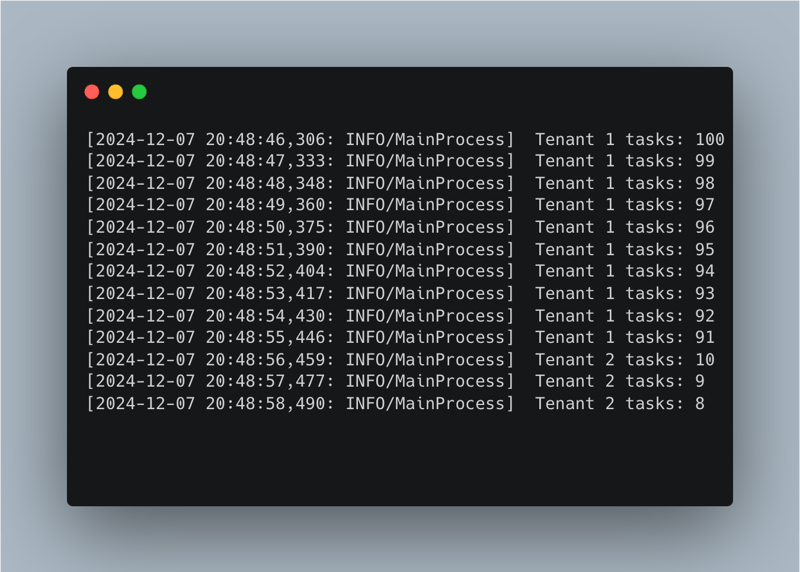
Celery と Redis によるタスクレベルの優先順位は、マルチテナント システムでの公平な処理を確保するための堅牢なソリューションを提供します。優先順位を動的に割り当て、単一のキューを活用することで、ビジネス要件を満たしながらシンプルさを維持できます。
タスクレベルの優先順位を実装するには多くの方法があります。たとえば、RabbitMQ を使用すると、コアで優先順位がサポートされるためより効率的ですが、タスクのカウントにも Redis を使用しているため、アーキテクチャ全体が簡素化されます。
これがお役に立てば幸いです。次回もご覧ください。
以上がセロリによる公正な処理の確保 - パート IIの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



