

DQN を使用したチェス エージェントの構築

最近、DQN ベースのチェス エージェントを実装しようとしました。
さて、DQN とチェスの仕組みを知っている人なら、それは愚かな考えだと言うでしょう。
そして...それはそうでしたが、それでも初心者の私はそれを楽しみました。この記事では、この作業中に私が学んだ洞察を共有します。
環境を理解する。
エージェント自体の実装を開始する前に、使用する環境を理解し、その上にカスタム ラッパーを作成して、トレーニング中にエージェントと対話できるようにする必要がありました。
-
kaggle_environments ライブラリのチェス環境を使用しました。
from kaggle_environments import make env = make("chess", debug=True)ログイン後にコピーログイン後にコピー
-
チェス ゲームの解析と検証に役立つ軽量の Python ライブラリである Chessnut も使用しました。
from Chessnut import Game initial_fen = env.state[0]['observation']['board'] game=Game(env.state[0]['observation']['board'])
ログイン後にコピーログイン後にコピー
この環境では、ボードの状態は FEN 形式で保存されます。

ボード上のすべての駒と現在アクティブなプレイヤーを表すコンパクトな方法を提供します。ただし、入力をニューラル ネットワークにフィードする予定だったので、状態の表現を変更する必要がありました。
FEN をマトリックス形式に変換する
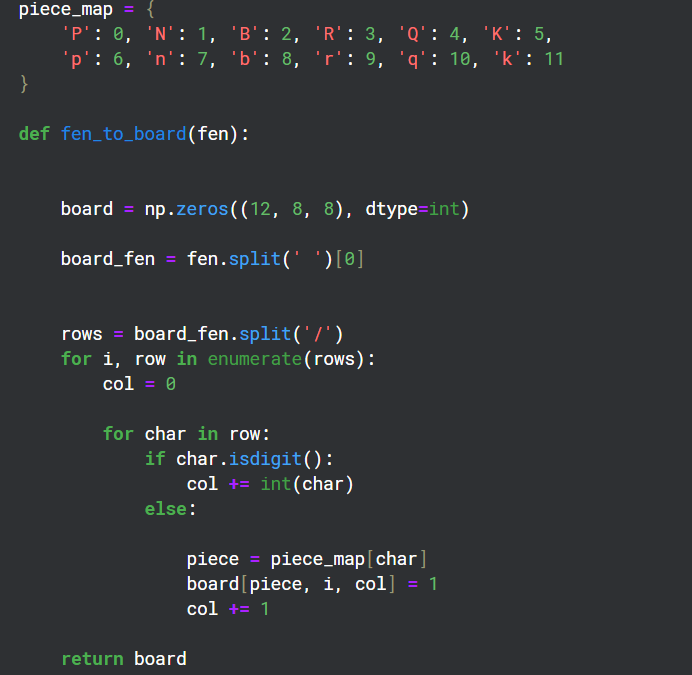
ボード上には 12 の異なるタイプの駒があるため、ボード上の各タイプの状態を表す 8x8 グリッドの 12 チャネルを作成しました。
環境のラッパーの作成
class EnvCust:
def __init__(self):
self.env = make("chess", debug=True)
self.game=Game(env.state[0]['observation']['board'])
print(self.env.state[0]['observation']['board'])
self.action_space=game.get_moves();
self.obs_space=(self.env.state[0]['observation']['board'])
def get_action(self):
return Game(self.env.state[0]['observation']['board']).get_moves();
def get_obs_space(self):
return fen_to_board(self.env.state[0]['observation']['board'])
def step(self,action):
reward=0
g=Game(self.env.state[0]['observation']['board']);
if(g.board.get_piece(Game.xy2i(action[2:4]))=='q'):
reward=7
elif g.board.get_piece(Game.xy2i(action[2:4]))=='n' or g.board.get_piece(Game.xy2i(action[2:4]))=='b' or g.board.get_piece(Game.xy2i(action[2:4]))=='r':
reward=4
elif g.board.get_piece(Game.xy2i(action[2:4]))=='P':
reward=2
g=Game(self.env.state[0]['observation']['board']);
g.apply_move(action)
done=False
if(g.status==2):
done=True
reward=10
elif g.status == 1:
done = True
reward = -5
self.env.step([action,'None'])
self.action_space=list(self.get_action())
if(self.action_space==[]):
done=True
else:
self.env.step(['None',random.choice(self.action_space)])
g=Game(self.env.state[0]['observation']['board']);
if g.status==2:
reward=-10
done=True
self.action_space=list(self.get_action())
return self.env.state[0]['observation']['board'],reward,done
このラッパーのポイントは、エージェントに対する報酬ポリシーと、トレーニング中に環境と対話するために使用されるステップ関数を提供することでした。
チェスナットは、ボードの現在の状態で可能な合法的な動きなどの情報を取得したり、ゲーム中にチェックメイトを認識したりするのに役立ちました。
チェックメイトと敵の駒を取り除くとプラスのポイントを与え、ゲームに負けるとマイナスのポイントを与える報酬ポリシーを作成しようとしました。
リプレイバッファの作成
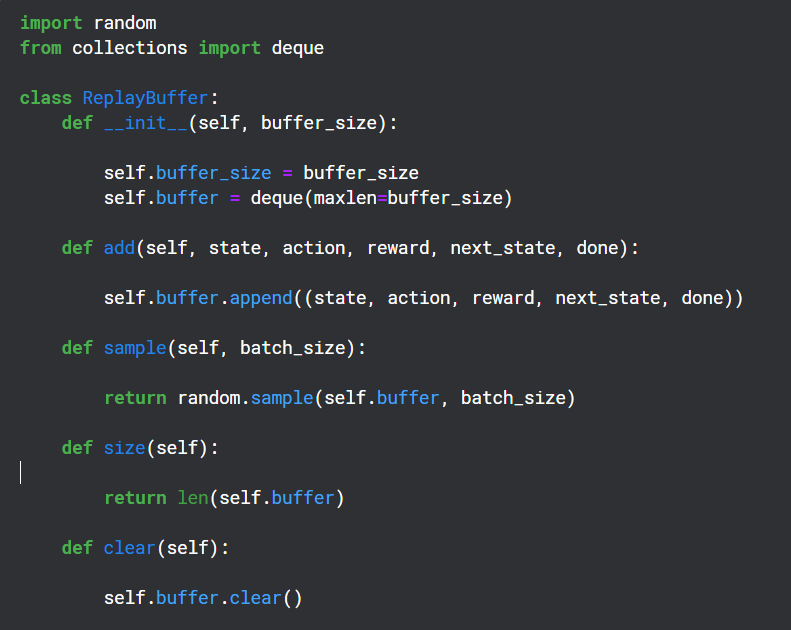
リプレイ バッファは、Q ネットワークによって出力された (状態、アクション、報酬、次の状態) を保存するためにトレーニング期間中に使用され、後でターゲット ネットワークのバックプロパゲーションにランダムに使用されます
補助機能


Chessnut は、「a2a3」のような UCI 形式で法的アクションを返しますが、ニューラル ネットワークと対話するために、基本パターンを使用して各アクションを個別のインデックスに変換しました。合計 64 個の正方形があるため、各手に対して 64*64 の一意のインデックスを持つことにしました。
64*64 のすべての手が合法であるわけではないことはわかっていますが、チェスナットを使用して合法性を処理でき、パターンも十分に単純でした。
ニューラルネットワークの構造
from kaggle_environments import make
env = make("chess", debug=True)
このニューラル ネットワークは、畳み込み層を使用して 12 チャネル入力を取り込み、有効なアクション インデックスを使用して報酬出力予測をフィルターで除外します。
エージェントの実装
from Chessnut import Game initial_fen = env.state[0]['observation']['board'] game=Game(env.state[0]['observation']['board'])
これは明らかに非常に基本的なモデルで、実際にうまく機能する可能性はありませんでした (実際にはうまく機能しませんでした)。しかし、DQN がどのように機能するかを少し理解するのに役立ちました。

以上がDQN を使用したチェス エージェントの構築の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7759
7759
 15
1644
14
1399
52
1293
25
1234
29
15
1644
14
1399
52
1293
25
1234
29

 LinuxターミナルでPythonバージョンを表示するときに発生する権限の問題を解決する方法は?
Apr 01, 2025 pm 05:09 PM
LinuxターミナルでPythonバージョンを表示するときに発生する権限の問題を解決する方法は?
Apr 01, 2025 pm 05:09 PM
LinuxターミナルでPythonバージョンを表示する際の許可の問題の解決策PythonターミナルでPythonバージョンを表示しようとするとき、Pythonを入力してください...
 中間の読書にどこでもfiddlerを使用するときにブラウザによって検出されないようにするにはどうすればよいですか?
Apr 02, 2025 am 07:15 AM
中間の読書にどこでもfiddlerを使用するときにブラウザによって検出されないようにするにはどうすればよいですか?
Apr 02, 2025 am 07:15 AM
fiddlereveryversings for the-middleの測定値を使用するときに検出されないようにする方法
 あるデータフレームの列全体を、Python内の異なる構造を持つ別のデータフレームに効率的にコピーする方法は?
Apr 01, 2025 pm 11:15 PM
あるデータフレームの列全体を、Python内の異なる構造を持つ別のデータフレームに効率的にコピーする方法は?
Apr 01, 2025 pm 11:15 PM
PythonのPandasライブラリを使用する場合、異なる構造を持つ2つのデータフレーム間で列全体をコピーする方法は一般的な問題です。 2つのデータがあるとします...
 プロジェクトの基本と問題駆動型の方法で10時間以内にコンピューター初心者プログラミングの基本を教える方法は?
Apr 02, 2025 am 07:18 AM
プロジェクトの基本と問題駆動型の方法で10時間以内にコンピューター初心者プログラミングの基本を教える方法は?
Apr 02, 2025 am 07:18 AM
10時間以内にコンピューター初心者プログラミングの基本を教える方法は?コンピューター初心者にプログラミングの知識を教えるのに10時間しかない場合、何を教えることを選びますか...
 uvicornは、serving_forever()なしでhttpリクエストをどのように継続的に聞いていますか?
Apr 01, 2025 pm 10:51 PM
uvicornは、serving_forever()なしでhttpリクエストをどのように継続的に聞いていますか?
Apr 01, 2025 pm 10:51 PM
UvicornはどのようにしてHTTPリクエストを継続的に聞きますか? Uvicornは、ASGIに基づく軽量のWebサーバーです。そのコア機能の1つは、HTTPリクエストを聞いて続行することです...


 Investing.comの反クローラーメカニズムをバイパスするニュースデータを取得する方法は?
Apr 02, 2025 am 07:03 AM
Investing.comの反クローラーメカニズムをバイパスするニュースデータを取得する方法は?
Apr 02, 2025 am 07:03 AM
Investing.comの反クラウリング戦略を理解する多くの人々は、Investing.com(https://cn.investing.com/news/latest-news)からのニュースデータをクロールしようとします。
