

皆さん、こんにちは!これが私の最初の記事です。
この記事では、SQL クエリステートメントがどのように実行されるかを紹介します
以下は MySQL アーキテクチャ図です:
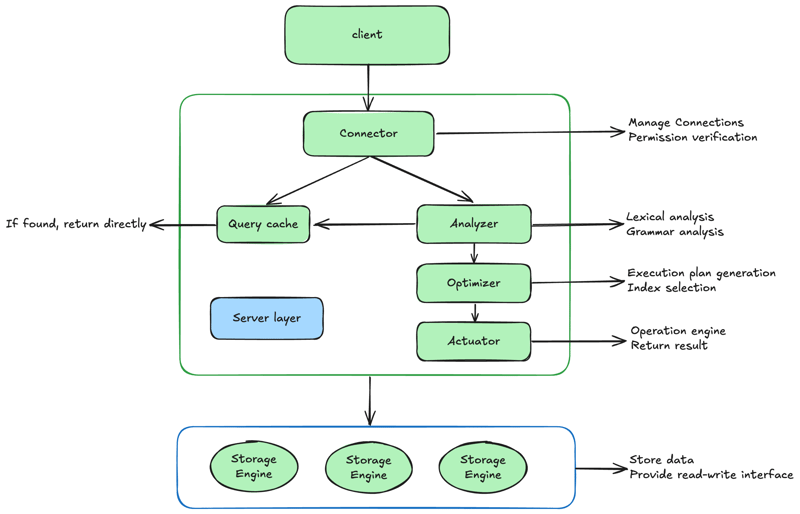
一般に、MySQl はサーバーとストレージ エンジン層の 2 つの部分に分割できます。
サーバー層には、コネクタ、クエリ キャッシュ、パーサー、オプティマイザ、エグゼキュータなどが含まれ、MySQL のコア サービス関数のほとんどと、すべての組み込み関数 (日付、時刻、計算、暗号化など) が含まれています。機能)。ストアド プロシージャ、トリガー、ビューなどのすべてのクロスストレージ エンジン機能は、このレイヤーで実装されます。
ストレージ エンジン層は、データの保存と取得を担当します。そのアーキテクチャはプラグインベースであり、InnoDB、MyISAM、Memory などの複数のストレージ エンジンをサポートしています。 MySQL 5.5.5 から、InnoDB が MySQL のデフォルトのストレージ エンジンになりました。
エンジン=メモリを指定した create table ステートメントを使用して、テーブルを作成するときにメモリ エンジンを指定できます。
異なるストレージ エンジンが同じサーバー層を共有します
最初のステップはデータベースに接続することです。これにはコネクタが必要です。コネクタは、クライアントとの接続を確立し、許可を取得し、接続を維持および管理する責任があります。接続コマンドは次のとおりです:
mysql -h$ip -P$port -u$user -p
このコマンドは、サーバーとの接続を確立するために使用されます。クラシック TCP ハンドシェイクが完了すると、コネクタはプロバイダーのユーザー名とパスワードを使用して ID を認証します。
これは、接続が正常に確立されると、管理者がユーザーの権限に加えた変更は既存の接続の権限に影響を与えないことを意味します。新しい接続のみが、更新された権限設定を使用します。
接続が確立された後、後続のアクションがない場合、接続はアイドル状態に入ります。これは、show processlist コマンドを使用して確認できます。

クライアントが非アクティブな状態が長時間続くと、コネクタは自動的に切断されます。期間は wait_timeout パラメータによって制御され、デフォルトは 8 時間です。
接続が終了し、クライアントがリクエストを送信すると、次のエラー メッセージが表示されます: クエリ中に MySQL サーバーへの接続が失われました。続行するには、再接続してリクエストを実行する必要があります。
データベースでは、永続接続は、クライアントが接続に成功した後、継続的なリクエストに対して同じ接続を維持する接続を指します。短い接続とは、数回のクエリ後に切断し、後続のクエリのために再接続することを指します。
接続プロセスは複雑であるため、開発中の接続の作成を最小限に抑えること、つまり可能な限り永続的な接続を使用することをお勧めします。
ただし、永続接続を使用すると、実行中に使用される一時メモリが接続オブジェクト内で管理されるため、MySQL のメモリ使用量が大幅に増加する可能性があります。これらのリソースは、接続が終了した場合にのみ解放されます。永続的な接続が蓄積すると、過剰なメモリ使用量が発生し、システムが MySQL を強制終了 (OOM) し、予期しない再起動が発生する可能性があります。
解決策:
注: MySQL 8.0 以降、その欠点が利点を上回るため、クエリ キャッシュ機能は完全に削除されました。
MySQL はクエリ リクエストを受信すると、まずクエリ キャッシュをチェックして、このクエリが以前に実行されたかどうかを確認します。以前に実行されたクエリとその結果は、キーと値のペアとしてメモリにキャッシュされます。キーはクエリ ステートメントであり、値は結果です。キーがクエリ キャッシュで見つかった場合、値はクライアントに直接返されます。
クエリがクエリ キャッシュに見つからない場合、プロセスは続行されます。
クエリ キャッシュはなぜ良いことよりも害を及ぼすのでしょうか?
クエリ キャッシュの無効化が非常に頻繁に発生します。テーブルを更新すると、そのテーブルに関連するすべてのクエリ キャッシュがクリアされるため、テーブルが静的構成テーブルでない限り、キャッシュ ヒット率が非常に低くなります。
MySQL は、クエリ キャッシュを使用するための「オンデマンド」方式を提供します。パラメータ query_cache_type を DEMAND に設定すると、SQL ステートメントはデフォルトでクエリ キャッシュを使用しなくなります。クエリ キャッシュを使用するには、SQL_CACHE:
を明示的に指定できます。
mysql -h$ip -P$port -u$user -p
クエリ キャッシュがヒットしない場合は、ステートメントの実行プロセスが開始されます。 MySQL はまず何をすべきかを理解する必要があるため、SQL ステートメントを解析します。
パーサーは最初に字句解析を実行します。文字列とスペースで構成される入力 SQL ステートメントは MySQL によって分析され、各部分が何を表しているかを特定します。たとえば、select はクエリ ステートメント、T はテーブル名、ID は列として識別されます。
字句解析の後、構文解析が実行されます。字句解析の結果に基づいて、構文アナライザーは SQL ステートメントが MySQL の構文規則に準拠しているかどうかを判断します。
構文エラーがある場合は、「SQL 構文にエラーがあります」のようなエラー メッセージが表示されます。たとえば、次のクエリでは、select キーワードのスペルが間違っています:
select SQL_CACHE * from T where ID=10;
解析後、MySQL はユーザーが何をしたいのかを認識します。次に、オプティマイザがその方法を決定します。
オプティマイザーは、テーブルに複数のインデックスがある場合に使用するインデックス、またはクエリに複数のテーブルが含まれる場合のテーブル結合の順序を決定します。たとえば、次のクエリでは:
mysql> elect * from t where ID=1; ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'elect * from t where ID=1' at line 1
クエリは、t1 または t2 から値を取得することで開始できます。どちらのアプローチでも論理的には同じ結果が得られますが、パフォーマンスは異なる場合があります。オプティマイザーの役割は、最も効率的なプランを選択することです。
最適化フェーズの後、プロセスはエグゼキュータに進みます。
エグゼキューターがクエリの実行を開始します。
実行前に、現在の接続にテーブルをクエリする権限があるかどうかが最初にチェックされます。そうでない場合は、権限が不十分であることを示すエラーが返されます。 (クエリキャッシュから結果を返すときにも権限チェックが実行されます。)
権限が付与されると、テーブルが開かれ、実行が続行されます。このプロセス中、エグゼキューターはテーブルのエンジン定義に基づいてストレージ エンジンと対話します。
たとえば、テーブル T に ID 列のインデックスがないとします。エグゼキュータの実行プロセスは次のようになります:
この時点で、クエリは完了です。
インデックス付きテーブルの場合、プロセスには、エンジンの事前定義メソッドを使用して、「最初に一致する行」と「次に一致する行」を繰り返しフェッチすることが含まれます。
スロー クエリ ログの rows_examined フィールドは、クエリの実行中にスキャンされた行数を示します。この値は、エグゼキューターがエンジンを呼び出してデータ行を取得するたびに蓄積されます。
場合によっては、エグゼキューターへの 1 回の呼び出しで、エンジン内の内部で複数の行をスキャンする必要がある場合があります。したがって、エンジンによってスキャンされた行数は、必ずしも rows_examined と等しくなりません。
読んでいただきありがとうございます!この記事がお役に立てば幸いです。
以上がSQL クエリ ステートメントはどのように実行されるかの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



