

IRIS-RAG-Gen: IRIS Vector Search を利用した ChatGPT RAG アプリケーションのパーソナライズ

コミュニティの皆様、
この記事では、私のアプリケーション iris-RAG-Gen を紹介します。
Iris-RAG-Gen は、IRIS Vector Search の機能を利用して、Streamlit Web フレームワーク、LangChain、OpenAI を利用して ChatGPT をパーソナライズする生成 AI 検索拡張生成 (RAG) アプリケーションです。アプリケーションは IRIS をベクター ストアとして使用します。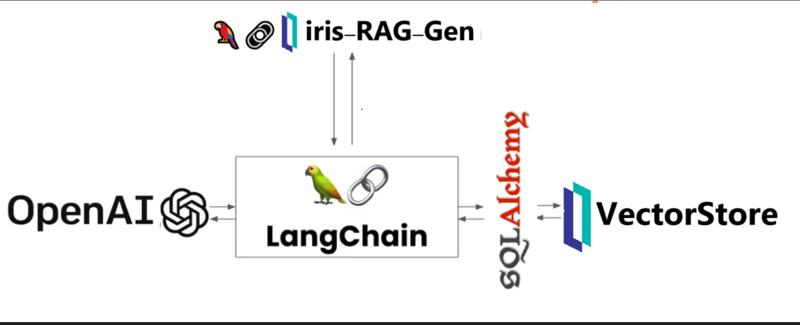
アプリケーションの機能
- ドキュメント (PDF または TXT) を IRIS に取り込む
- 選択した取り込まれたドキュメントとチャットします
- 取り込んだドキュメントを削除
- OpenAI ChatGPT
ドキュメント (PDF または TXT) を IRIS に取り込む
以下の手順に従ってドキュメントを取り込みます:
- OpenAI キーを入力してください
- ドキュメント (PDF または TXT) を選択
- ドキュメントの説明を入力
- 「ドキュメントの取り込み」ボタンをクリックします
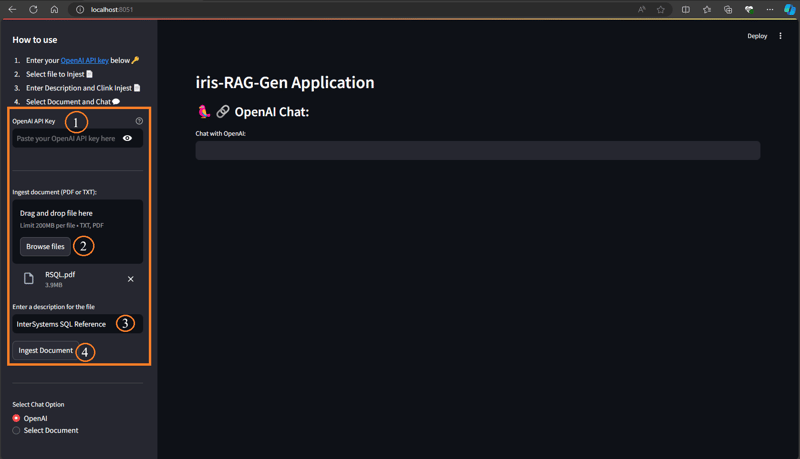
ドキュメントの取り込み機能は、ドキュメントの詳細を rag_documents テーブルに挿入し、「rag_document id」(rag_documents の ID)テーブルを作成してベクター データを保存します。

以下の Python コードは、選択したドキュメントをベクターに保存します。
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import PyPDFLoader, TextLoader
from langchain_iris import IRISVector
from langchain_openai import OpenAIEmbeddings
from sqlalchemy import create_engine,text
<span>class RagOpr:</span>
#Ingest document. Parametres contains file path, description and file type
<span>def ingestDoc(self,filePath,fileDesc,fileType):</span>
embeddings = OpenAIEmbeddings()
#Load the document based on the file type
if fileType == "text/plain":
loader = TextLoader(filePath)
elif fileType == "application/pdf":
loader = PyPDFLoader(filePath)
#load data into documents
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=400, chunk_overlap=0)
#Split text into chunks
texts = text_splitter.split_documents(documents)
#Get collection Name from rag_doucments table.
COLLECTION_NAME = self.get_collection_name(fileDesc,fileType)
# function to create collection_name table and store vector data in it.
db = IRISVector.from_documents(
embedding=embeddings,
documents=texts,
collection_name = COLLECTION_NAME,
connection_string=self.CONNECTION_STRING,
)
#Get collection name
<span>def get_collection_name(self,fileDesc,fileType):</span>
# check if rag_documents table exists, if not then create it
with self.engine.connect() as conn:
with conn.begin():
sql = text("""
SELECT *
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = 'SQLUser'
AND TABLE_NAME = 'rag_documents';
""")
result = []
try:
result = conn.execute(sql).fetchall()
except Exception as err:
print("An exception occurred:", err)
return ''
#if table is not created, then create rag_documents table first
if len(result) == 0:
sql = text("""
CREATE TABLE rag_documents (
description VARCHAR(255),
docType VARCHAR(50) )
""")
try:
result = conn.execute(sql)
except Exception as err:
print("An exception occurred:", err)
return ''
#Insert description value
with self.engine.connect() as conn:
with conn.begin():
sql = text("""
INSERT INTO rag_documents
(description,docType)
VALUES (:desc,:ftype)
""")
try:
result = conn.execute(sql, {'desc':fileDesc,'ftype':fileType})
except Exception as err:
print("An exception occurred:", err)
return ''
#select ID of last inserted record
sql = text("""
SELECT LAST_IDENTITY()
""")
try:
result = conn.execute(sql).fetchall()
except Exception as err:
print("An exception occurred:", err)
return ''
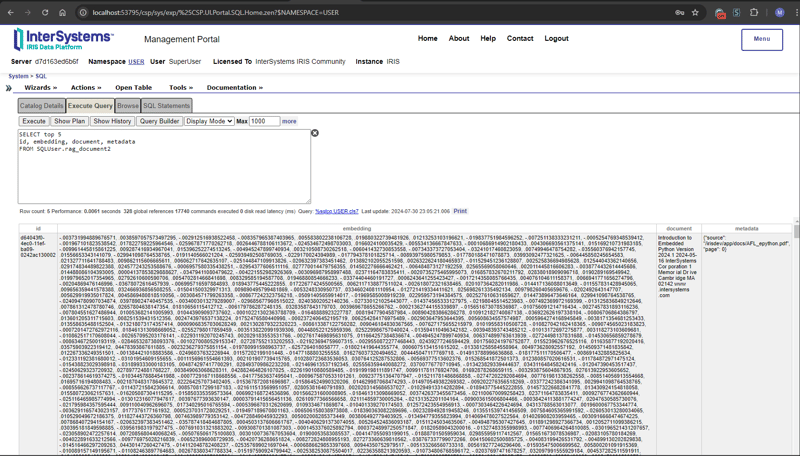
return "rag_document"+str(result[0][0])管理ポータルで以下の SQL コマンドを入力してベクター データを取得します
SELECT top 5 id, embedding, document, metadata FROM SQLUser.rag_document2
選択した取り込まれたドキュメントとチャットします
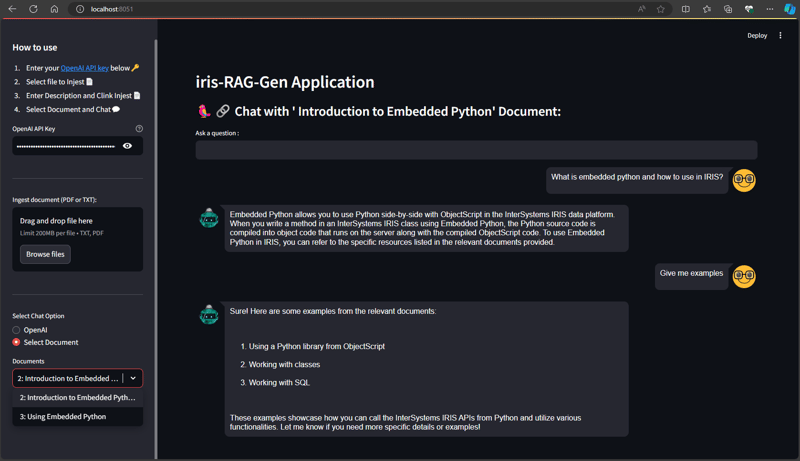
チャット オプションの選択セクションからドキュメントを選択し、質問を入力します。 アプリケーションはベクター データを読み取り、関連する回答を返します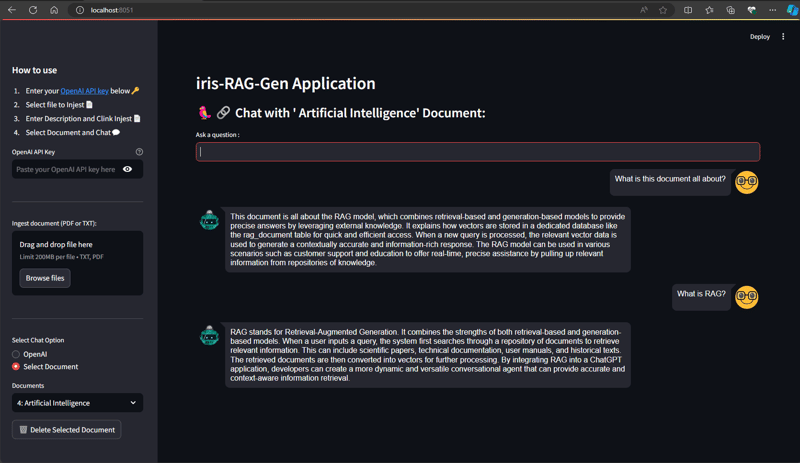
以下の Python コードは、選択したドキュメントをベクターに保存します:
from langchain_iris import IRISVector
from langchain_openai import OpenAIEmbeddings,ChatOpenAI
from langchain.chains import ConversationChain
from langchain.chains.conversation.memory import ConversationSummaryMemory
from langchain.chat_models import ChatOpenAI
<span>class RagOpr:</span>
<span>def ragSearch(self,prompt,id):</span>
#Concat document id with rag_doucment to get the collection name
COLLECTION_NAME = "rag_document"+str(id)
embeddings = OpenAIEmbeddings()
#Get vector store reference
db2 = IRISVector (
embedding_function=embeddings,
collection_name=COLLECTION_NAME,
connection_string=self.CONNECTION_STRING,
)
#Similarity search
docs_with_score = db2.similarity_search_with_score(prompt)
#Prepair the retrieved documents to pass to LLM
relevant_docs = ["".join(str(doc.page_content)) + " " for doc, _ in docs_with_score]
#init LLM
llm = ChatOpenAI(
temperature=0,
model_name="gpt-3.5-turbo"
)
#manage and handle LangChain multi-turn conversations
conversation_sum = ConversationChain(
llm=llm,
memory= ConversationSummaryMemory(llm=llm),
verbose=False
)
#Create prompt
template = f"""
Prompt: <span>{prompt}
Relevant Docuemnts: {relevant_docs}
"""</span>
#Return the answer
resp = conversation_sum(template)
return resp['response']
詳細については、iris-RAG-Gen 交換申請ページをご覧ください。
ありがとう
以上がIRIS-RAG-Gen: IRIS Vector Search を利用した ChatGPT RAG アプリケーションのパーソナライズの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1671
1671
 14
1428
52
1331
25
1276
29
1256
24
14
1428
52
1331
25
1276
29
1256
24

 Python vs. C:曲線と使いやすさの学習
Apr 19, 2025 am 12:20 AM
Python vs. C:曲線と使いやすさの学習
Apr 19, 2025 am 12:20 AM
Pythonは学習と使用が簡単ですが、Cはより強力ですが複雑です。 1。Python構文は簡潔で初心者に適しています。動的なタイピングと自動メモリ管理により、使いやすくなりますが、ランタイムエラーを引き起こす可能性があります。 2.Cは、高性能アプリケーションに適した低レベルの制御と高度な機能を提供しますが、学習しきい値が高く、手動メモリとタイプの安全管理が必要です。
 Pythonと時間:勉強時間を最大限に活用する
Apr 14, 2025 am 12:02 AM
Pythonと時間:勉強時間を最大限に活用する
Apr 14, 2025 am 12:02 AM
限られた時間でPythonの学習効率を最大化するには、PythonのDateTime、時間、およびスケジュールモジュールを使用できます。 1. DateTimeモジュールは、学習時間を記録および計画するために使用されます。 2。時間モジュールは、勉強と休息の時間を設定するのに役立ちます。 3.スケジュールモジュールは、毎週の学習タスクを自動的に配置します。
 Python vs. C:パフォーマンスと効率の探索
Apr 18, 2025 am 12:20 AM
Python vs. C:パフォーマンスと効率の探索
Apr 18, 2025 am 12:20 AM
Pythonは開発効率でCよりも優れていますが、Cは実行パフォーマンスが高くなっています。 1。Pythonの簡潔な構文とリッチライブラリは、開発効率を向上させます。 2.Cのコンピレーションタイプの特性とハードウェア制御により、実行パフォーマンスが向上します。選択を行うときは、プロジェクトのニーズに基づいて開発速度と実行効率を比較検討する必要があります。
 Pythonの学習:2時間の毎日の研究で十分ですか?
Apr 18, 2025 am 12:22 AM
Pythonの学習:2時間の毎日の研究で十分ですか?
Apr 18, 2025 am 12:22 AM
Pythonを1日2時間学ぶだけで十分ですか?それはあなたの目標と学習方法に依存します。 1)明確な学習計画を策定し、2)適切な学習リソースと方法を選択します。3)実践的な実践とレビューとレビューと統合を練習および統合し、統合すると、この期間中にPythonの基本的な知識と高度な機能を徐々に習得できます。
 Python vs. C:重要な違いを理解します
Apr 21, 2025 am 12:18 AM
Python vs. C:重要な違いを理解します
Apr 21, 2025 am 12:18 AM
PythonとCにはそれぞれ独自の利点があり、選択はプロジェクトの要件に基づいている必要があります。 1)Pythonは、簡潔な構文と動的タイピングのため、迅速な開発とデータ処理に適しています。 2)Cは、静的なタイピングと手動メモリ管理により、高性能およびシステムプログラミングに適しています。
 Python Standard Libraryの一部はどれですか:リストまたは配列はどれですか?
Apr 27, 2025 am 12:03 AM
Python Standard Libraryの一部はどれですか:リストまたは配列はどれですか?
Apr 27, 2025 am 12:03 AM
PythonListSarePartOfThestAndardarenot.liestareBuilting-in、versatile、forStoringCollectionsのpythonlistarepart。
 Python:自動化、スクリプト、およびタスク管理
Apr 16, 2025 am 12:14 AM
Python:自動化、スクリプト、およびタスク管理
Apr 16, 2025 am 12:14 AM
Pythonは、自動化、スクリプト、およびタスク管理に優れています。 1)自動化:OSやShutilなどの標準ライブラリを介してファイルバックアップが実現されます。 2)スクリプトの書き込み:Psutilライブラリを使用してシステムリソースを監視します。 3)タスク管理:スケジュールライブラリを使用してタスクをスケジュールします。 Pythonの使いやすさと豊富なライブラリサポートにより、これらの分野で優先ツールになります。
 科学コンピューティングのためのPython:詳細な外観
Apr 19, 2025 am 12:15 AM
科学コンピューティングのためのPython:詳細な外観
Apr 19, 2025 am 12:15 AM
科学コンピューティングにおけるPythonのアプリケーションには、データ分析、機械学習、数値シミュレーション、視覚化が含まれます。 1.numpyは、効率的な多次元配列と数学的関数を提供します。 2。ScipyはNumpy機能を拡張し、最適化と線形代数ツールを提供します。 3. Pandasは、データ処理と分析に使用されます。 4.matplotlibは、さまざまなグラフと視覚的な結果を生成するために使用されます。
