

Python を使用して Target.com のレビューをスクレイピングする方法

導入
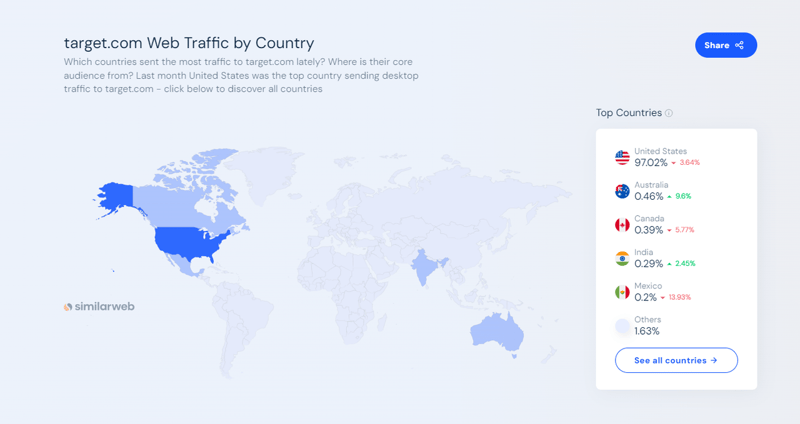
Target.com は、アメリカ最大の電子商取引およびショッピング マーケットプレイスの 1 つです。これにより、消費者は食料品や必需品から衣料品や電化製品に至るまで、あらゆるものをオンラインや店舗で買い物できるようになります。 2024 年 9 月の時点で、SimilarWeb のデータによると、Target.com は月間 1 億 6,600 万を超える Web トラフィックを集めています。
Target.com Web サイトでは、顧客レビュー、動的価格情報、製品比較、製品評価などが提供されます。これは、製品の傾向を追跡したり、競合他社の価格を監視したり、レビューを通じて顧客の感情を分析したいと考えているアナリスト、マーケティング チーム、企業、または研究者にとって貴重なデータ ソースです。
この記事では、次の方法を学びます:
- Web スクレイピング用に Python、Selenium、Beautiful Soup をセットアップしてインストールする
- Python を使用して Target.com から製品のレビューと評価を取得します
- ScraperAPI を使用して、Target.com のアンチスクレイピング メカニズムを効果的にバイパスします
- プロキシを実装して IP 禁止を回避し、スクレイピングのパフォーマンスを向上させます
この記事を最後まで読むと、Python、Selenium、ScraperAPI を使用して、ブロックされずに Target.com から製品のレビューと評価を収集する方法がわかります。また、スクレイピングしたデータを感情分析に使用する方法も学習します。
このチュートリアルを書いているときに興奮しているのであれば、すぐに始めてみましょう。?
TL;DR: ターゲット製品レビューのスクレイピング [完全なコード]
お急ぎの方のために、このチュートリアルで構築する完全なコード スニペットを次に示します。
import os
import time
from bs4 import BeautifulSoup
from dotenv import load_dotenv
from selenium.common.exceptions import NoSuchElementException, TimeoutException
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from seleniumwire import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# Load environment variables
load_dotenv()
def target_com_scraper():
"""
SCRAPER SETTINGS
- API_KEY: Your ScraperAPI key. Get your API Key ==> https://www.scraperapi.com/?fp_ref=eunit
"""
API_KEY = os.getenv("API_KEY", "yourapikey")
# ScraperAPI proxy settings (with HTTP and HTTPS variants)
scraper_api_proxies = {
'proxy': {
'http': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'https': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'no_proxy': 'localhost,127.0.0.1'
}
}
# URLs to scrape
url_list = [
"https://www.target.com/p/enclosed-cat-litter-box-xl-up-up/-/A-90310047?preselect=87059440#lnk=sametab",
]
# Store scraped data
scraped_data = []
# Setup Selenium options with proxy
options = Options()
# options.add_argument("--headless") # Uncomment for headless mode
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--disable-extensions")
options.add_argument("--disable-in-process-stack-traces")
options.add_argument("--window-size=1920,1080")
options.add_argument("--log-level=3")
options.add_argument("--disable-logging")
options.add_argument("--start-maximized")
# Initialize Selenium WebDriver
driver = webdriver.Chrome(service=ChromeService(
ChromeDriverManager().install()), options=options, seleniumwire_options=scraper_api_proxies)
def scroll_down_page(distance=100, delay=0.2):
"""
Scroll down the page gradually until the end.
Args:
- distance: Number of pixels to scroll by in each step.
- delay: Time (in seconds) to wait between scrolls.
"""
total_height = driver.execute_script(
"return document.body.scrollHeight")
scrolled_height = 0
while scrolled_height < total_height:
# Scroll down by 'distance' pixels
driver.execute_script(f"window.scrollBy(0, {distance});")
scrolled_height += distance
time.sleep(delay) # Pause between scrolls
# Update the total page height after scrolling
total_height = driver.execute_script(
"return document.body.scrollHeight")
print("Finished scrolling.")
try:
for url in url_list:
# Use Selenium to load the page
driver.get(url)
time.sleep(5) # Give the page time to load
# Scroll down the page
scroll_down_page()
# Extract single elements with Selenium
def extract_element_text(selector, description):
try:
# Wait for the element and extract text
element = WebDriverWait(driver, 5).until(
EC.visibility_of_element_located(
(By.CSS_SELECTOR, selector))
)
text = element.text.strip()
return text if text else None # Return None if the text is empty
except TimeoutException:
print(f"Timeout: Could not find {description}. Setting to None.")
return None
except NoSuchElementException:
print(f"Element not found: {description}. Setting to None.")
return None
# Extract single elements
reviews_data = {}
reviews_data["secondary_rating"] = extract_element_text("div[data-test='secondary-rating']",
"secondary_rating")
reviews_data["rating_count"] = extract_element_text(
"div[data-test='rating-count']", "rating_count")
reviews_data["rating_histogram"] = extract_element_text("div[data-test='rating-histogram']",
"rating_histogram")
reviews_data["percent_recommended"] = extract_element_text("div[data-test='percent-recommended']",
"percent_recommended")
reviews_data["total_recommendations"] = extract_element_text("div[data-test='total-recommendations']",
"total_recommendations")
# Extract reviews from 'reviews-list'
scraped_reviews = []
# Use Beautiful Soup to extract other content
soup = BeautifulSoup(driver.page_source, 'html.parser')
# Select all reviews in the list using BeautifulSoup
reviews_list = soup.select("div[data-test='reviews-list'] > div")
for review in reviews_list:
# Create a dictionary to store each review's data
ratings = {}
# Extract title
title_element = review.select_one(
"h4[data-test='review-card--title']")
ratings['title'] = title_element.text.strip(
) if title_element else None
# Extract rating
rating_element = review.select_one("span[data-test='ratings']")
ratings['rating'] = rating_element.text.strip(
) if rating_element else None
# Extract time
time_element = review.select_one(
"span[data-test='review-card--reviewTime']")
ratings['time'] = time_element.text.strip(
) if time_element else None
# Extract review text
text_element = review.select_one(
"div[data-test='review-card--text']")
ratings['text'] = text_element.text.strip(
) if text_element else None
# Append each review to the list of reviews
scraped_reviews.append(ratings)
# Append the list of reviews to the main product data
reviews_data["reviews"] = scraped_reviews
# Append the overall data to the scraped_data list
scraped_data.append(reviews_data)
# Output the scraped data
print(f"Scraped data: {scraped_data}")
except Exception as e:
print(f"Error: {e}")
finally:
# Ensure driver quits after scraping
driver.quit()
if __name__ == "__main__":
target_com_scraper()
GitHub で完全なコードを確認してください: https://github.com/Eunit99/target_com_scraper。コードの各行を理解したいですか?一緒に Web スクレイパーを一から構築しましょう!
Python と ScraperAPI を使用して Target.com レビューをスクレイピングする方法
以前の記事では、Target.com の製品データを収集するために知っておくべきことをすべて説明しました。ただし、この記事では、Python と ScraperAPI を使用して Target.com をスクレイピングして製品の評価とレビューを取得する方法を説明することに重点を置きます。
前提条件
このチュートリアルに従って Target.com のスクレイピングを開始するには、最初にいくつかのことを行う必要があります。
1. ScraperAPI のアカウントを持っている
ScraperAPI の無料アカウントから始めてください。 ScraperAPI を使用すると、Web スクレイピング用の使いやすい API を使用して、複雑で高価な回避策を必要とせずに、何百万もの Web ソースからデータの収集を開始できます。
ScraperAPI は、最も困難なサイトでもロックを解除し、インフラストラクチャと開発コストを削減し、Web スクレイパーをより迅速に展開できるようにします。また、最初に試すための無料の 1,000 API クレジットも提供します。
2. テキストエディタまたはIDE
Visual Studio Code などのコード エディターを使用します。その他のオプションには、Sublime Text または PyCharm があります。
3. プロジェクトの要件と仮想環境のセットアップ
Target.com レビューのスクレイピングを開始する前に、次のことを確認してください:
- マシンにインストールされている Python (バージョン 3.10 以降)
- pip (Python パッケージ インストーラー)
Python プロジェクトの依存関係を管理し、競合を回避するには、仮想環境を使用することをお勧めします。
仮想環境を作成するには、ターミナルで次のコマンドを実行します:
import os
import time
from bs4 import BeautifulSoup
from dotenv import load_dotenv
from selenium.common.exceptions import NoSuchElementException, TimeoutException
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from seleniumwire import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# Load environment variables
load_dotenv()
def target_com_scraper():
"""
SCRAPER SETTINGS
- API_KEY: Your ScraperAPI key. Get your API Key ==> https://www.scraperapi.com/?fp_ref=eunit
"""
API_KEY = os.getenv("API_KEY", "yourapikey")
# ScraperAPI proxy settings (with HTTP and HTTPS variants)
scraper_api_proxies = {
'proxy': {
'http': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'https': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'no_proxy': 'localhost,127.0.0.1'
}
}
# URLs to scrape
url_list = [
"https://www.target.com/p/enclosed-cat-litter-box-xl-up-up/-/A-90310047?preselect=87059440#lnk=sametab",
]
# Store scraped data
scraped_data = []
# Setup Selenium options with proxy
options = Options()
# options.add_argument("--headless") # Uncomment for headless mode
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--disable-extensions")
options.add_argument("--disable-in-process-stack-traces")
options.add_argument("--window-size=1920,1080")
options.add_argument("--log-level=3")
options.add_argument("--disable-logging")
options.add_argument("--start-maximized")
# Initialize Selenium WebDriver
driver = webdriver.Chrome(service=ChromeService(
ChromeDriverManager().install()), options=options, seleniumwire_options=scraper_api_proxies)
def scroll_down_page(distance=100, delay=0.2):
"""
Scroll down the page gradually until the end.
Args:
- distance: Number of pixels to scroll by in each step.
- delay: Time (in seconds) to wait between scrolls.
"""
total_height = driver.execute_script(
"return document.body.scrollHeight")
scrolled_height = 0
while scrolled_height < total_height:
# Scroll down by 'distance' pixels
driver.execute_script(f"window.scrollBy(0, {distance});")
scrolled_height += distance
time.sleep(delay) # Pause between scrolls
# Update the total page height after scrolling
total_height = driver.execute_script(
"return document.body.scrollHeight")
print("Finished scrolling.")
try:
for url in url_list:
# Use Selenium to load the page
driver.get(url)
time.sleep(5) # Give the page time to load
# Scroll down the page
scroll_down_page()
# Extract single elements with Selenium
def extract_element_text(selector, description):
try:
# Wait for the element and extract text
element = WebDriverWait(driver, 5).until(
EC.visibility_of_element_located(
(By.CSS_SELECTOR, selector))
)
text = element.text.strip()
return text if text else None # Return None if the text is empty
except TimeoutException:
print(f"Timeout: Could not find {description}. Setting to None.")
return None
except NoSuchElementException:
print(f"Element not found: {description}. Setting to None.")
return None
# Extract single elements
reviews_data = {}
reviews_data["secondary_rating"] = extract_element_text("div[data-test='secondary-rating']",
"secondary_rating")
reviews_data["rating_count"] = extract_element_text(
"div[data-test='rating-count']", "rating_count")
reviews_data["rating_histogram"] = extract_element_text("div[data-test='rating-histogram']",
"rating_histogram")
reviews_data["percent_recommended"] = extract_element_text("div[data-test='percent-recommended']",
"percent_recommended")
reviews_data["total_recommendations"] = extract_element_text("div[data-test='total-recommendations']",
"total_recommendations")
# Extract reviews from 'reviews-list'
scraped_reviews = []
# Use Beautiful Soup to extract other content
soup = BeautifulSoup(driver.page_source, 'html.parser')
# Select all reviews in the list using BeautifulSoup
reviews_list = soup.select("div[data-test='reviews-list'] > div")
for review in reviews_list:
# Create a dictionary to store each review's data
ratings = {}
# Extract title
title_element = review.select_one(
"h4[data-test='review-card--title']")
ratings['title'] = title_element.text.strip(
) if title_element else None
# Extract rating
rating_element = review.select_one("span[data-test='ratings']")
ratings['rating'] = rating_element.text.strip(
) if rating_element else None
# Extract time
time_element = review.select_one(
"span[data-test='review-card--reviewTime']")
ratings['time'] = time_element.text.strip(
) if time_element else None
# Extract review text
text_element = review.select_one(
"div[data-test='review-card--text']")
ratings['text'] = text_element.text.strip(
) if text_element else None
# Append each review to the list of reviews
scraped_reviews.append(ratings)
# Append the list of reviews to the main product data
reviews_data["reviews"] = scraped_reviews
# Append the overall data to the scraped_data list
scraped_data.append(reviews_data)
# Output the scraped data
print(f"Scraped data: {scraped_data}")
except Exception as e:
print(f"Error: {e}")
finally:
# Ensure driver quits after scraping
driver.quit()
if __name__ == "__main__":
target_com_scraper()
4. 仮想環境のアクティブ化
オペレーティング システムに基づいて仮想環境をアクティブ化します:
python3 -m venv env
一部の IDE では、仮想環境を自動的にアクティブ化できます。
5. CSS セレクターとブラウザー開発ツールのナビゲートについての基本的な理解がある
この記事を効果的に進めるには、CSS セレクターの基本を理解することが不可欠です。 CSS セレクターは、Web ページ上の特定の HTML 要素をターゲットにするために使用され、これにより必要な情報を抽出できます。
また、Web ページの構造を検査して特定するには、ブラウザーの DevTools を使いこなすことが重要です。
プロジェクトのセットアップ
上記の前提条件を満たしたら、プロジェクトをセットアップします。まず、Target.com スクレイパーのソース コードを含むフォルダーを作成します。この場合、フォルダーに python-target-dot-com-scraper という名前を付けます。
次のコマンドを実行して、python-target-dot-com-scraper という名前のフォルダーを作成します。
# On Unix or MacOS (bash shell): /path/to/venv/bin/activate # On Unix or MacOS (csh shell): /path/to/venv/bin/activate.csh # On Unix or MacOS (fish shell): /path/to/venv/bin/activate.fish # On Windows (command prompt): \path\to\venv\Scripts\activate.bat # On Windows (PowerShell): \path\to\venv\Scripts\Activate.ps1
フォルダーに入り、次のコマンドを実行して新しい Python main.py ファイルを作成します。
mkdir python-target-dot-com-scraper
次のコマンドを実行して、requirements.txt ファイルを作成します。
cd python-target-dot-com-scraper && touch main.py
この記事では、Selenium と Beautiful Soup、および Python ライブラリの Webdriver Manager を使用して Web スクレイパーを構築します。 Selenium はブラウザの自動化を処理し、Beautiful Soup ライブラリは Target.com Web サイトの HTML コンテンツからデータを抽出します。同時に、Python 用 Webdriver Manager は、さまざまなブラウザーのドライバーを自動的に管理する方法を提供します。
requirements.txt ファイルに次の行を追加して、必要なパッケージを指定します。
touch requirements.txt
パッケージをインストールするには、次のコマンドを実行します:
selenium~=4.25.0 bs4~=0.0.2 python-dotenv~=1.0.1 webdriver_manager selenium-wire blinker==1.7.0 python-dotenv==1.0.1
Selenium を使用して Target.com 製品レビューを抽出する
このセクションでは、Target.com のこのような製品ページから製品の評価とレビューを取得する方法を段階的に説明します。
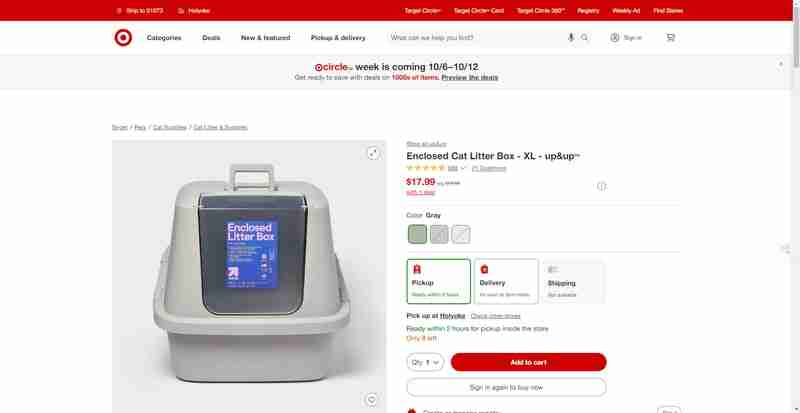
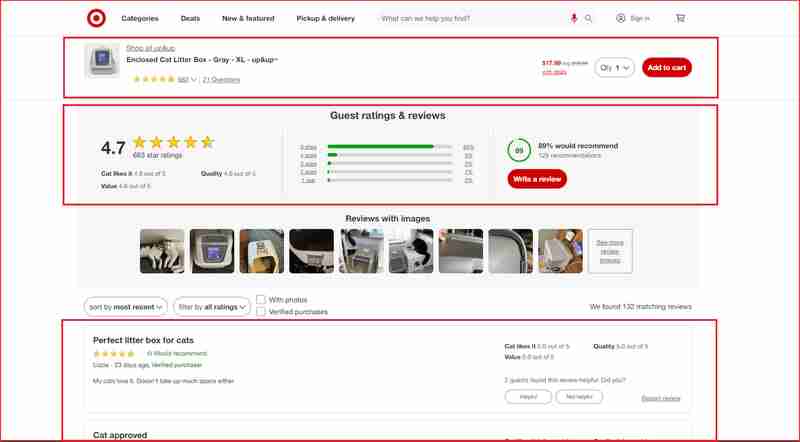
以下のスクリーンショットで強調表示されている Web サイトのこれらのセクションのレビューと評価に焦点を当てます。
さらに詳しく調べる前に、HTML 構造を理解し、抽出する情報をラップする HTML タグに関連付けられた DOM セレクターを特定する必要があります。次のセクションでは、Chrome DevTools を使用して Target.com のサイト構造を理解する方法を説明します。
Chrome DevTools を使用して Target.com のサイト構造を理解する
F12 を押すか、ページ上の任意の場所を右クリックして「検査」を選択して、Chrome DevTools を開きます。上記の URL からページを調べると、次のことがわかります:
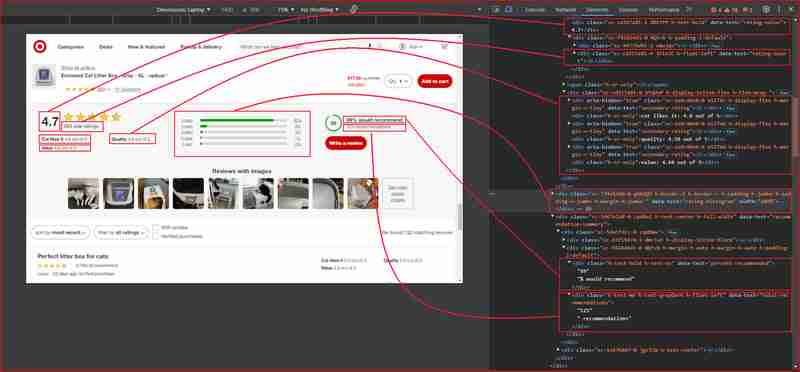
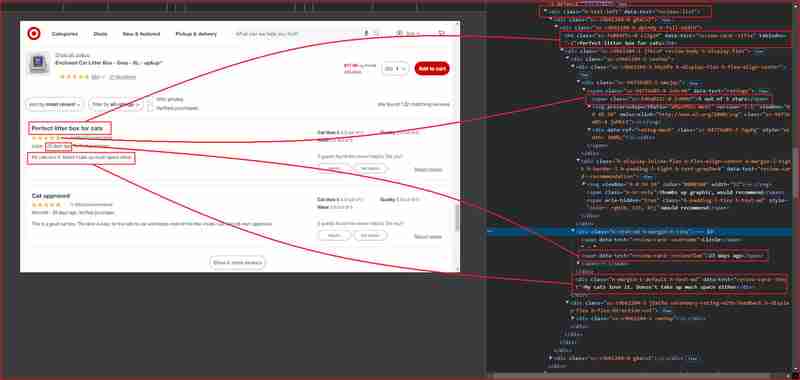
上の図から、Web スクレイパーが情報を抽出する対象となるすべての DOM セレクターを次に示します。
| Information | DOM selector | Value |
|---|---|---|
| Product ratings | ||
| Rating value | div[data-test='rating-value'] | 4.7 |
| Rating count | div[data-test='rating-count'] | 683 star ratings |
| Secondary rating | div[data-test='secondary-rating'] | 683 star ratings |
| Rating histogram | div[data-test='rating-histogram'] | 5 stars 85%4 stars 8%3 stars 3%2 stars 1%1 star 2% |
| Percent recommended | div[data-test='percent-recommended'] | 89% would recommend |
| Total recommendations | div[data-test='total-recommendations'] | 125 recommendations |
| Product reviews | ||
| Reviews list | div[data-test='reviews-list'] | Returns children elements corresponding to individual product review |
| Review card title | h4[data-test='review-card--title'] | Perfect litter box for cats |
| Ratings | span[data-test='ratings'] | 4.7 out of 5 stars with 683 reviews |
| Review time | span[data-test='review-card--reviewTime'] | 23 days ago |
| Review card text | div[data-test='review-card--text'] | My cats love it. Doesn't take up much space either |
ターゲット レビュー スクレーパーを構築する
これで、すべての要件の概要が説明され、Target.com の製品レビュー ページで関心のあるさまざまな要素が見つかりました。次のステップに進み、必要なモジュールをインポートします:
1. Selenium およびその他のモジュールのインポート
import os
import time
from bs4 import BeautifulSoup
from dotenv import load_dotenv
from selenium.common.exceptions import NoSuchElementException, TimeoutException
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from seleniumwire import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# Load environment variables
load_dotenv()
def target_com_scraper():
"""
SCRAPER SETTINGS
- API_KEY: Your ScraperAPI key. Get your API Key ==> https://www.scraperapi.com/?fp_ref=eunit
"""
API_KEY = os.getenv("API_KEY", "yourapikey")
# ScraperAPI proxy settings (with HTTP and HTTPS variants)
scraper_api_proxies = {
'proxy': {
'http': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'https': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'no_proxy': 'localhost,127.0.0.1'
}
}
# URLs to scrape
url_list = [
"https://www.target.com/p/enclosed-cat-litter-box-xl-up-up/-/A-90310047?preselect=87059440#lnk=sametab",
]
# Store scraped data
scraped_data = []
# Setup Selenium options with proxy
options = Options()
# options.add_argument("--headless") # Uncomment for headless mode
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--disable-extensions")
options.add_argument("--disable-in-process-stack-traces")
options.add_argument("--window-size=1920,1080")
options.add_argument("--log-level=3")
options.add_argument("--disable-logging")
options.add_argument("--start-maximized")
# Initialize Selenium WebDriver
driver = webdriver.Chrome(service=ChromeService(
ChromeDriverManager().install()), options=options, seleniumwire_options=scraper_api_proxies)
def scroll_down_page(distance=100, delay=0.2):
"""
Scroll down the page gradually until the end.
Args:
- distance: Number of pixels to scroll by in each step.
- delay: Time (in seconds) to wait between scrolls.
"""
total_height = driver.execute_script(
"return document.body.scrollHeight")
scrolled_height = 0
while scrolled_height < total_height:
# Scroll down by 'distance' pixels
driver.execute_script(f"window.scrollBy(0, {distance});")
scrolled_height += distance
time.sleep(delay) # Pause between scrolls
# Update the total page height after scrolling
total_height = driver.execute_script(
"return document.body.scrollHeight")
print("Finished scrolling.")
try:
for url in url_list:
# Use Selenium to load the page
driver.get(url)
time.sleep(5) # Give the page time to load
# Scroll down the page
scroll_down_page()
# Extract single elements with Selenium
def extract_element_text(selector, description):
try:
# Wait for the element and extract text
element = WebDriverWait(driver, 5).until(
EC.visibility_of_element_located(
(By.CSS_SELECTOR, selector))
)
text = element.text.strip()
return text if text else None # Return None if the text is empty
except TimeoutException:
print(f"Timeout: Could not find {description}. Setting to None.")
return None
except NoSuchElementException:
print(f"Element not found: {description}. Setting to None.")
return None
# Extract single elements
reviews_data = {}
reviews_data["secondary_rating"] = extract_element_text("div[data-test='secondary-rating']",
"secondary_rating")
reviews_data["rating_count"] = extract_element_text(
"div[data-test='rating-count']", "rating_count")
reviews_data["rating_histogram"] = extract_element_text("div[data-test='rating-histogram']",
"rating_histogram")
reviews_data["percent_recommended"] = extract_element_text("div[data-test='percent-recommended']",
"percent_recommended")
reviews_data["total_recommendations"] = extract_element_text("div[data-test='total-recommendations']",
"total_recommendations")
# Extract reviews from 'reviews-list'
scraped_reviews = []
# Use Beautiful Soup to extract other content
soup = BeautifulSoup(driver.page_source, 'html.parser')
# Select all reviews in the list using BeautifulSoup
reviews_list = soup.select("div[data-test='reviews-list'] > div")
for review in reviews_list:
# Create a dictionary to store each review's data
ratings = {}
# Extract title
title_element = review.select_one(
"h4[data-test='review-card--title']")
ratings['title'] = title_element.text.strip(
) if title_element else None
# Extract rating
rating_element = review.select_one("span[data-test='ratings']")
ratings['rating'] = rating_element.text.strip(
) if rating_element else None
# Extract time
time_element = review.select_one(
"span[data-test='review-card--reviewTime']")
ratings['time'] = time_element.text.strip(
) if time_element else None
# Extract review text
text_element = review.select_one(
"div[data-test='review-card--text']")
ratings['text'] = text_element.text.strip(
) if text_element else None
# Append each review to the list of reviews
scraped_reviews.append(ratings)
# Append the list of reviews to the main product data
reviews_data["reviews"] = scraped_reviews
# Append the overall data to the scraped_data list
scraped_data.append(reviews_data)
# Output the scraped data
print(f"Scraped data: {scraped_data}")
except Exception as e:
print(f"Error: {e}")
finally:
# Ensure driver quits after scraping
driver.quit()
if __name__ == "__main__":
target_com_scraper()
このコードでは、各モジュールが Web スクレイパーを構築するための特定の目的を果たします。
- OS は API キーなどの環境変数を処理します。
- ページの読み込み中に遅延が発生します。
- dotenv は .env ファイルから API キーを読み込みます。
- Selenium はブラウザの自動化と対話を可能にします。
- webdriver_manager は ChromeDriver を自動的にインストールします。
- BeautifulSoup はデータ抽出のために HTML を解析します。
- seleniumwire は、IP 禁止なしでスクレイピング用のプロキシを管理します。
2. Webドライバーのセットアップ
このステップでは、Selenium の Chrome WebDriver を初期化し、重要なブラウザ オプションを構成します。これらのオプションには、パフォーマンスを向上させるために不要な機能を無効にすること、ウィンドウ サイズの設定、ログの管理が含まれます。 webdriver.Chrome() を使用して WebDriver をインスタンス化し、スクレイピング プロセス全体を通じてブラウザを制御します。
python3 -m venv env
下へスクロール機能を作成する
このセクションでは、ページ全体をスクロールする関数を作成します。 Target.com Web サイトは、ユーザーが下にスクロールすると追加コンテンツ (レビューなど) を動的に読み込みます。
# On Unix or MacOS (bash shell): /path/to/venv/bin/activate # On Unix or MacOS (csh shell): /path/to/venv/bin/activate.csh # On Unix or MacOS (fish shell): /path/to/venv/bin/activate.fish # On Windows (command prompt): \path\to\venv\Scripts\activate.bat # On Windows (PowerShell): \path\to\venv\Scripts\Activate.ps1
scroll_down_page() 関数は、各スクロール間に短い一時停止 (遅延) を挟みながら、設定されたピクセル数 (距離) だけ Web ページを徐々にスクロールします。最初にページの合計の高さを計算し、一番下に到達するまで下にスクロールします。スクロールすると、プロセス中に読み込まれる可能性のある新しいコンテンツに対応するために、ページの合計の高さが動的に更新されます。
セレンとBeautifulSoupの組み合わせ
このセクションでは、Selenium と BeautifulSoup の長所を組み合わせて、効率的で信頼性の高い Web スクレイピング セットアップを作成します。 Selenium は、ページの読み込みや JavaScript でレンダリングされた要素の処理などの動的コンテンツの操作に使用されますが、BeautifulSoup は静的な HTML 要素の解析と抽出においてより効果的です。まず Selenium を使用して Web ページを移動し、製品の評価やレビュー数などの特定の要素が読み込まれるのを待ちます。これらの要素は Selenium の WebDriverWait 関数を使用して抽出され、データをキャプチャする前にデータが表示されることが保証されます。ただし、Selenium だけで個別のレビューを処理すると、複雑で非効率になる可能性があります。
BeautifulSoup を使用すると、ページ上の複数のレビューをループするプロセスが簡素化されます。 Selenium がページを完全にロードすると、BeautifulSoup は HTML コンテンツを解析してレビューを効率的に抽出します。 BeautifulSoup の select() メソッドと select_one() メソッドを使用すると、ページ構造をナビゲートし、各レビューのタイトル、評価、時間、テキストを収集できます。このアプローチにより、Selenium のみですべてを管理する場合と比較して、繰り返しの要素 (レビューのリストなど) をよりクリーンで構造化したスクレイピングが可能になり、HTML の処理に大きな柔軟性がもたらされます。
import os
import time
from bs4 import BeautifulSoup
from dotenv import load_dotenv
from selenium.common.exceptions import NoSuchElementException, TimeoutException
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from seleniumwire import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# Load environment variables
load_dotenv()
def target_com_scraper():
"""
SCRAPER SETTINGS
- API_KEY: Your ScraperAPI key. Get your API Key ==> https://www.scraperapi.com/?fp_ref=eunit
"""
API_KEY = os.getenv("API_KEY", "yourapikey")
# ScraperAPI proxy settings (with HTTP and HTTPS variants)
scraper_api_proxies = {
'proxy': {
'http': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'https': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'no_proxy': 'localhost,127.0.0.1'
}
}
# URLs to scrape
url_list = [
"https://www.target.com/p/enclosed-cat-litter-box-xl-up-up/-/A-90310047?preselect=87059440#lnk=sametab",
]
# Store scraped data
scraped_data = []
# Setup Selenium options with proxy
options = Options()
# options.add_argument("--headless") # Uncomment for headless mode
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--disable-extensions")
options.add_argument("--disable-in-process-stack-traces")
options.add_argument("--window-size=1920,1080")
options.add_argument("--log-level=3")
options.add_argument("--disable-logging")
options.add_argument("--start-maximized")
# Initialize Selenium WebDriver
driver = webdriver.Chrome(service=ChromeService(
ChromeDriverManager().install()), options=options, seleniumwire_options=scraper_api_proxies)
def scroll_down_page(distance=100, delay=0.2):
"""
Scroll down the page gradually until the end.
Args:
- distance: Number of pixels to scroll by in each step.
- delay: Time (in seconds) to wait between scrolls.
"""
total_height = driver.execute_script(
"return document.body.scrollHeight")
scrolled_height = 0
while scrolled_height < total_height:
# Scroll down by 'distance' pixels
driver.execute_script(f"window.scrollBy(0, {distance});")
scrolled_height += distance
time.sleep(delay) # Pause between scrolls
# Update the total page height after scrolling
total_height = driver.execute_script(
"return document.body.scrollHeight")
print("Finished scrolling.")
try:
for url in url_list:
# Use Selenium to load the page
driver.get(url)
time.sleep(5) # Give the page time to load
# Scroll down the page
scroll_down_page()
# Extract single elements with Selenium
def extract_element_text(selector, description):
try:
# Wait for the element and extract text
element = WebDriverWait(driver, 5).until(
EC.visibility_of_element_located(
(By.CSS_SELECTOR, selector))
)
text = element.text.strip()
return text if text else None # Return None if the text is empty
except TimeoutException:
print(f"Timeout: Could not find {description}. Setting to None.")
return None
except NoSuchElementException:
print(f"Element not found: {description}. Setting to None.")
return None
# Extract single elements
reviews_data = {}
reviews_data["secondary_rating"] = extract_element_text("div[data-test='secondary-rating']",
"secondary_rating")
reviews_data["rating_count"] = extract_element_text(
"div[data-test='rating-count']", "rating_count")
reviews_data["rating_histogram"] = extract_element_text("div[data-test='rating-histogram']",
"rating_histogram")
reviews_data["percent_recommended"] = extract_element_text("div[data-test='percent-recommended']",
"percent_recommended")
reviews_data["total_recommendations"] = extract_element_text("div[data-test='total-recommendations']",
"total_recommendations")
# Extract reviews from 'reviews-list'
scraped_reviews = []
# Use Beautiful Soup to extract other content
soup = BeautifulSoup(driver.page_source, 'html.parser')
# Select all reviews in the list using BeautifulSoup
reviews_list = soup.select("div[data-test='reviews-list'] > div")
for review in reviews_list:
# Create a dictionary to store each review's data
ratings = {}
# Extract title
title_element = review.select_one(
"h4[data-test='review-card--title']")
ratings['title'] = title_element.text.strip(
) if title_element else None
# Extract rating
rating_element = review.select_one("span[data-test='ratings']")
ratings['rating'] = rating_element.text.strip(
) if rating_element else None
# Extract time
time_element = review.select_one(
"span[data-test='review-card--reviewTime']")
ratings['time'] = time_element.text.strip(
) if time_element else None
# Extract review text
text_element = review.select_one(
"div[data-test='review-card--text']")
ratings['text'] = text_element.text.strip(
) if text_element else None
# Append each review to the list of reviews
scraped_reviews.append(ratings)
# Append the list of reviews to the main product data
reviews_data["reviews"] = scraped_reviews
# Append the overall data to the scraped_data list
scraped_data.append(reviews_data)
# Output the scraped data
print(f"Scraped data: {scraped_data}")
except Exception as e:
print(f"Error: {e}")
finally:
# Ensure driver quits after scraping
driver.quit()
if __name__ == "__main__":
target_com_scraper()
Python Selenium でのプロキシの使用: ヘッドレス ブラウザとの複雑な対話
複雑な Web サイト、特に Target.com のような強力なボット対策が施されている Web サイトをスクレイピングする場合、IP 禁止、レート制限、アクセス制限などの課題が頻繁に発生します。このようなタスクに Selenium を使用するのは、特にヘッドレス ブラウザを展開する場合には複雑になります。ヘッドレス ブラウザでは GUI なしで対話できますが、この環境でプロキシを手動で管理するのは困難になります。プロキシ設定を構成し、IP をローテーションし、JavaScript レンダリングなどのその他の操作を処理する必要があるため、スクレイピングが遅くなり、失敗しやすくなります。
対照的に、ScraperAPI はプロキシを自動的に管理することで、このプロセスを大幅に合理化します。 Selenium で手動構成を扱うのではなく、ScraperAPI のプロキシ モードはリクエストを複数の IP アドレスに分散し、IP 禁止、レート制限、地理的制限を気にせずにスムーズなスクレイピングを保証します。これは、動的コンテンツや複雑なサイト操作を処理するために追加のコーディングが必要となるヘッドレス ブラウザを使用する場合に特に役立ちます。
Selenium を使用した ScraperAPI のセットアップ
ScraperAPI のプロキシ モードと Selenium の統合は、プロキシを簡単に構成できるツールである Selenium Wire を使用することで簡素化されます。簡単なセットアップは次のとおりです:
- ScraperAPI にサインアップ: アカウントを作成し、API キーを取得します。
- Selenium Wire のインストール: pip install selenium-wire を実行して、標準の Selenium を Selenium Wire に置き換えます。
- プロキシの構成: WebDriver 設定で ScraperAPI のプロキシ プールを使用して、IP ローテーションを簡単に管理します。
この構成を統合すると、ヘッドレス ブラウザ環境でプロキシを手動で管理する手間を省き、動的ページとのよりスムーズな対話、IP アドレスの自動回転、レート制限のバイパスが可能になります。
以下のスニペットは、Python で ScraperAPI のプロキシを構成する方法を示しています。
import os
import time
from bs4 import BeautifulSoup
from dotenv import load_dotenv
from selenium.common.exceptions import NoSuchElementException, TimeoutException
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from seleniumwire import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# Load environment variables
load_dotenv()
def target_com_scraper():
"""
SCRAPER SETTINGS
- API_KEY: Your ScraperAPI key. Get your API Key ==> https://www.scraperapi.com/?fp_ref=eunit
"""
API_KEY = os.getenv("API_KEY", "yourapikey")
# ScraperAPI proxy settings (with HTTP and HTTPS variants)
scraper_api_proxies = {
'proxy': {
'http': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'https': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'no_proxy': 'localhost,127.0.0.1'
}
}
# URLs to scrape
url_list = [
"https://www.target.com/p/enclosed-cat-litter-box-xl-up-up/-/A-90310047?preselect=87059440#lnk=sametab",
]
# Store scraped data
scraped_data = []
# Setup Selenium options with proxy
options = Options()
# options.add_argument("--headless") # Uncomment for headless mode
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--disable-extensions")
options.add_argument("--disable-in-process-stack-traces")
options.add_argument("--window-size=1920,1080")
options.add_argument("--log-level=3")
options.add_argument("--disable-logging")
options.add_argument("--start-maximized")
# Initialize Selenium WebDriver
driver = webdriver.Chrome(service=ChromeService(
ChromeDriverManager().install()), options=options, seleniumwire_options=scraper_api_proxies)
def scroll_down_page(distance=100, delay=0.2):
"""
Scroll down the page gradually until the end.
Args:
- distance: Number of pixels to scroll by in each step.
- delay: Time (in seconds) to wait between scrolls.
"""
total_height = driver.execute_script(
"return document.body.scrollHeight")
scrolled_height = 0
while scrolled_height < total_height:
# Scroll down by 'distance' pixels
driver.execute_script(f"window.scrollBy(0, {distance});")
scrolled_height += distance
time.sleep(delay) # Pause between scrolls
# Update the total page height after scrolling
total_height = driver.execute_script(
"return document.body.scrollHeight")
print("Finished scrolling.")
try:
for url in url_list:
# Use Selenium to load the page
driver.get(url)
time.sleep(5) # Give the page time to load
# Scroll down the page
scroll_down_page()
# Extract single elements with Selenium
def extract_element_text(selector, description):
try:
# Wait for the element and extract text
element = WebDriverWait(driver, 5).until(
EC.visibility_of_element_located(
(By.CSS_SELECTOR, selector))
)
text = element.text.strip()
return text if text else None # Return None if the text is empty
except TimeoutException:
print(f"Timeout: Could not find {description}. Setting to None.")
return None
except NoSuchElementException:
print(f"Element not found: {description}. Setting to None.")
return None
# Extract single elements
reviews_data = {}
reviews_data["secondary_rating"] = extract_element_text("div[data-test='secondary-rating']",
"secondary_rating")
reviews_data["rating_count"] = extract_element_text(
"div[data-test='rating-count']", "rating_count")
reviews_data["rating_histogram"] = extract_element_text("div[data-test='rating-histogram']",
"rating_histogram")
reviews_data["percent_recommended"] = extract_element_text("div[data-test='percent-recommended']",
"percent_recommended")
reviews_data["total_recommendations"] = extract_element_text("div[data-test='total-recommendations']",
"total_recommendations")
# Extract reviews from 'reviews-list'
scraped_reviews = []
# Use Beautiful Soup to extract other content
soup = BeautifulSoup(driver.page_source, 'html.parser')
# Select all reviews in the list using BeautifulSoup
reviews_list = soup.select("div[data-test='reviews-list'] > div")
for review in reviews_list:
# Create a dictionary to store each review's data
ratings = {}
# Extract title
title_element = review.select_one(
"h4[data-test='review-card--title']")
ratings['title'] = title_element.text.strip(
) if title_element else None
# Extract rating
rating_element = review.select_one("span[data-test='ratings']")
ratings['rating'] = rating_element.text.strip(
) if rating_element else None
# Extract time
time_element = review.select_one(
"span[data-test='review-card--reviewTime']")
ratings['time'] = time_element.text.strip(
) if time_element else None
# Extract review text
text_element = review.select_one(
"div[data-test='review-card--text']")
ratings['text'] = text_element.text.strip(
) if text_element else None
# Append each review to the list of reviews
scraped_reviews.append(ratings)
# Append the list of reviews to the main product data
reviews_data["reviews"] = scraped_reviews
# Append the overall data to the scraped_data list
scraped_data.append(reviews_data)
# Output the scraped data
print(f"Scraped data: {scraped_data}")
except Exception as e:
print(f"Error: {e}")
finally:
# Ensure driver quits after scraping
driver.quit()
if __name__ == "__main__":
target_com_scraper()
この設定では、ScraperAPI プロキシ サーバーに送信されたリクエストが Target.com Web サイトにリダイレクトされ、実際の IP が隠蔽され、Target.com Web サイトのアンチスクレイピング メカニズムに対する堅牢な防御が提供されます。プロキシは、JavaScript レンダリングの render=true などのパラメータを含めたり、地理位置情報の country_code を指定したりすることでカスタマイズすることもできます。
Target.com から収集されたレビュー データ
以下の JSON コードは、Target Reviews Scraper を使用した応答のサンプルです。
python3 -m venv env
Cloud Target.com レビュー スクレーパーの使用方法
環境をセットアップしたり、コードの作成方法を知ったり、プロキシを設定したりせずに、Target.com のレビューをすぐに取得したい場合は、Target Scraper API を使用して必要なデータを無料で取得できます。 Target Scraper API は Apify プラットフォームでホストされており、セットアップを必要とせずにすぐに使用できます。
Apify にアクセスし、[無料で試す] をクリックして今すぐ開始してください。

ターゲットレビューを使用したセンチメント分析
Target.com のレビューと評価のデータが得られたので、このデータを理解しましょう。これらのレビューと評価のデータは、特定の製品またはサービスに関する顧客の意見に関する貴重な洞察を提供します。これらのレビューを分析することで、一般的な賞賛や苦情を特定し、顧客満足度を測定し、将来の行動を予測して、これらのレビューを実用的な洞察に変えることができます。
主な視聴者をより深く理解し、マーケティング戦略と製品戦略を改善する方法を模索しているマーケティング専門家またはビジネスオーナーとして。以下に、このデータを実用的な洞察に変換して、マーケティング活動を最適化し、製品戦略を改善し、顧客エンゲージメントを高めるいくつかの方法を示します。
- 製品の改善: よくある顧客の苦情や賞賛を特定し、製品の機能を微調整します。
- 顧客サービスの向上: 否定的なレビューを早期に検出して問題に対処し、顧客満足度を維持します。
- マーケティング キャンペーンの最適化: ポジティブなフィードバックからの洞察を利用して、パーソナライズされたターゲットを絞ったキャンペーンを作成します。
ScraperAPI を使用して大規模なレビュー データを大規模に収集することで、センチメント分析を自動化および拡張でき、より適切な意思決定と成長が可能になります。
対象製品レビューのスクレイピングに関するよくある質問
Target.com の製品ページをスクレイピングすることは合法ですか?
はい、Target.com を悪用して製品の評価やレビューなどの公開情報を入手することは合法です。ただし、この公開情報には個人情報が含まれる可能性があることに留意することが重要です。
私たちは、Web スクレイピングの法的側面と倫理的考慮事項についてブログ投稿を書きました。詳細については、こちらをご覧ください。
Target.com はスクレイパーをブロックしますか?
はい、Target.com は自動スクレーパーをブロックするためにさまざまなアンチスクレイピング対策を実装しています。これらには、IP ブロッキング、レート制限、CAPTCHA チャレンジが含まれます。これらはすべて、スクレイパーやボットからの過剰な自動リクエストを検出して停止するように設計されています。
Target.com によるブロックを回避するにはどうすればよいですか?
Target.com によるブロックを回避するには、リクエストの速度を遅くし、ユーザー エージェントをローテーションし、CAPTCHA 解決テクニックを使用し、反復的または高頻度のリクエストを避ける必要があります。これらの方法とプロキシを組み合わせると、検出の可能性を減らすことができます。
また、Target Scraper API や Scraping API などの専用スクレイパーを使用して、Target.com の制限を回避することも検討してください。
Target.com をスクレイピングするにはプロキシを使用する必要がありますか?
はい、Target.com を効果的にスクレイピングするにはプロキシの使用が不可欠です。プロキシはリクエストを複数の IP アドレスに分散するのに役立ち、ブロックされる可能性を最小限に抑えます。 ScraperAPI プロキシはあなたの IP を隠し、アンチスクレイピング システムがあなたのアクティビティを検出することをより困難にします。
まとめ
この記事では、Python、Selenium を使用して Target.com の評価とレビュー スクレーパーを構築する方法、および ScraperAPI を使用して Target.com のアンチスクレイピング メカニズムを効果的にバイパスし、IP 禁止を回避してスクレイピング パフォーマンスを向上させる方法を学びました。
このツールを使用すると、顧客からの貴重なフィードバックを効率的かつ確実に収集できます。
このデータを収集したら、次のステップは感情分析を使用して重要な洞察を明らかにすることです。顧客レビューを分析することで、企業として製品の強みを特定し、問題点に対処し、マーケティング戦略を最適化して顧客のニーズをより適切に満たすことができます。
Target Scraper API を使用して大規模なデータ収集を行うことで、レビューを継続的に監視し、顧客の感情を常に把握して、製品開発を改良し、よりターゲットを絞ったマーケティング キャンペーンを作成できるようになります。
シームレスな大規模データ抽出のために今すぐ ScraperAPI を試すか、Cloud Target.com レビュー Scraper を使用してください!
その他のチュートリアルや素晴らしいコンテンツについては、Twitter (X) @eunit99 をフォローしてください
以上がPython を使用して Target.com のレビューをスクレイピングする方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1675
1675
 14
1429
52
1333
25
1278
29
1257
24
14
1429
52
1333
25
1278
29
1257
24

 Python vs. C:曲線と使いやすさの学習
Apr 19, 2025 am 12:20 AM
Python vs. C:曲線と使いやすさの学習
Apr 19, 2025 am 12:20 AM
Pythonは学習と使用が簡単ですが、Cはより強力ですが複雑です。 1。Python構文は簡潔で初心者に適しています。動的なタイピングと自動メモリ管理により、使いやすくなりますが、ランタイムエラーを引き起こす可能性があります。 2.Cは、高性能アプリケーションに適した低レベルの制御と高度な機能を提供しますが、学習しきい値が高く、手動メモリとタイプの安全管理が必要です。
 Pythonの学習:2時間の毎日の研究で十分ですか?
Apr 18, 2025 am 12:22 AM
Pythonの学習:2時間の毎日の研究で十分ですか?
Apr 18, 2025 am 12:22 AM
Pythonを1日2時間学ぶだけで十分ですか?それはあなたの目標と学習方法に依存します。 1)明確な学習計画を策定し、2)適切な学習リソースと方法を選択します。3)実践的な実践とレビューとレビューと統合を練習および統合し、統合すると、この期間中にPythonの基本的な知識と高度な機能を徐々に習得できます。
 Python vs. C:パフォーマンスと効率の探索
Apr 18, 2025 am 12:20 AM
Python vs. C:パフォーマンスと効率の探索
Apr 18, 2025 am 12:20 AM
Pythonは開発効率でCよりも優れていますが、Cは実行パフォーマンスが高くなっています。 1。Pythonの簡潔な構文とリッチライブラリは、開発効率を向上させます。 2.Cのコンピレーションタイプの特性とハードウェア制御により、実行パフォーマンスが向上します。選択を行うときは、プロジェクトのニーズに基づいて開発速度と実行効率を比較検討する必要があります。
 Python vs. C:重要な違いを理解します
Apr 21, 2025 am 12:18 AM
Python vs. C:重要な違いを理解します
Apr 21, 2025 am 12:18 AM
PythonとCにはそれぞれ独自の利点があり、選択はプロジェクトの要件に基づいている必要があります。 1)Pythonは、簡潔な構文と動的タイピングのため、迅速な開発とデータ処理に適しています。 2)Cは、静的なタイピングと手動メモリ管理により、高性能およびシステムプログラミングに適しています。
 Python Standard Libraryの一部はどれですか:リストまたは配列はどれですか?
Apr 27, 2025 am 12:03 AM
Python Standard Libraryの一部はどれですか:リストまたは配列はどれですか?
Apr 27, 2025 am 12:03 AM
PythonListSarePartOfThestAndardarenot.liestareBuilting-in、versatile、forStoringCollectionsのpythonlistarepart。
 Python:自動化、スクリプト、およびタスク管理
Apr 16, 2025 am 12:14 AM
Python:自動化、スクリプト、およびタスク管理
Apr 16, 2025 am 12:14 AM
Pythonは、自動化、スクリプト、およびタスク管理に優れています。 1)自動化:OSやShutilなどの標準ライブラリを介してファイルバックアップが実現されます。 2)スクリプトの書き込み:Psutilライブラリを使用してシステムリソースを監視します。 3)タスク管理:スケジュールライブラリを使用してタスクをスケジュールします。 Pythonの使いやすさと豊富なライブラリサポートにより、これらの分野で優先ツールになります。
 科学コンピューティングのためのPython:詳細な外観
Apr 19, 2025 am 12:15 AM
科学コンピューティングのためのPython:詳細な外観
Apr 19, 2025 am 12:15 AM
科学コンピューティングにおけるPythonのアプリケーションには、データ分析、機械学習、数値シミュレーション、視覚化が含まれます。 1.numpyは、効率的な多次元配列と数学的関数を提供します。 2。ScipyはNumpy機能を拡張し、最適化と線形代数ツールを提供します。 3. Pandasは、データ処理と分析に使用されます。 4.matplotlibは、さまざまなグラフと視覚的な結果を生成するために使用されます。
 Web開発用のPython:主要なアプリケーション
Apr 18, 2025 am 12:20 AM
Web開発用のPython:主要なアプリケーション
Apr 18, 2025 am 12:20 AM
Web開発におけるPythonの主要なアプリケーションには、DjangoおよびFlaskフレームワークの使用、API開発、データ分析と視覚化、機械学習とAI、およびパフォーマンスの最適化が含まれます。 1。DjangoandFlask Framework:Djangoは、複雑な用途の迅速な発展に適しており、Flaskは小規模または高度にカスタマイズされたプロジェクトに適しています。 2。API開発:フラスコまたはdjangorestFrameworkを使用して、Restfulapiを構築します。 3。データ分析と視覚化:Pythonを使用してデータを処理し、Webインターフェイスを介して表示します。 4。機械学習とAI:Pythonは、インテリジェントWebアプリケーションを構築するために使用されます。 5。パフォーマンスの最適化:非同期プログラミング、キャッシュ、コードを通じて最適化
