

vev、litellm、Agenta を使用して AI コード レビュー アシスタントを構築する

このチュートリアルでは、LLMOps のベスト プラクティスを使用して、本番環境に対応した AI プル リクエスト レビューアーを構築する方法を示します。 こちらからアクセスできる最後のアプリケーションは、公開 PR URL を受け入れ、AI によって生成されたレビューを返します。
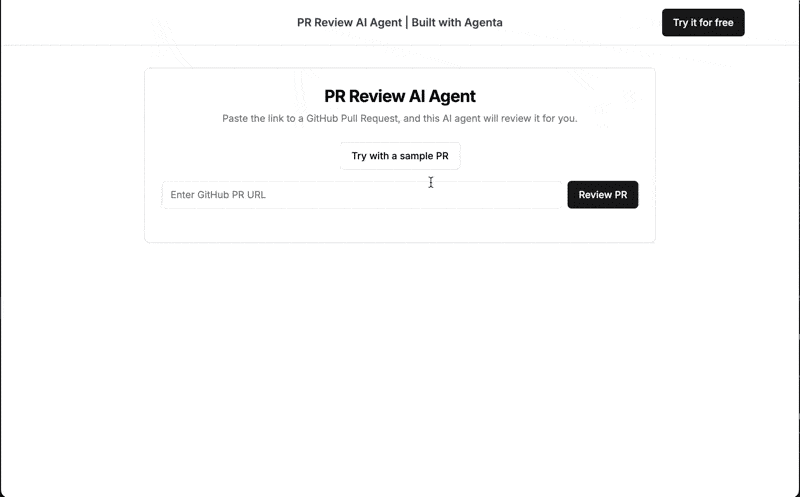
アプリケーションの概要
このチュートリアルの内容は次のとおりです。
- コード開発: GitHub から PR の差分を取得し、LLM 対話に LiteLLM を活用します。
- 可観測性: アプリケーションの監視とデバッグのために Agenta を実装します。
- プロンプト エンジニアリング: Agenta のプレイグラウンドを使用してプロンプトとモデルの選択を繰り返します。
- LLM 評価: 迅速なモデル評価のために、裁判官として LLM を採用します。
- デプロイ: アプリケーションを API としてデプロイし、v0.dev でシンプルな UI を作成します。
コアロジック
AI アシスタントのワークフローはシンプルです。PR URL を指定すると、GitHub から差分を取得し、レビューのために LLM に送信します。
GitHub の差分には次の方法でアクセスします:
<code>https://patch-diff.githubusercontent.com/raw/{owner}/{repo}/pull/{pr_number}.diff</code>この Python 関数は差分を取得します:
def get_pr_diff(pr_url):
# ... (Code remains the same)
return response.textLiteLLM は LLM のやり取りを容易にし、さまざまなプロバイダーにわたって一貫したインターフェイスを提供します。
prompt_system = """
You are an expert Python developer performing a file-by-file review of a pull request. You have access to the full diff of the file to understand the overall context and structure. However, focus on reviewing only the specific hunk provided.
"""
prompt_user = """
Here is the diff for the file:
{diff}
Please provide a critique of the changes made in this file.
"""
def generate_critique(pr_url: str):
diff = get_pr_diff(pr_url)
response = litellm.completion(
model=config.model,
messages=[
{"content": config.system_prompt, "role": "system"},
{"content": config.user_prompt.format(diff=diff), "role": "user"},
],
)
return response.choices[0].message.contentAgenta による可観測性の実装
Agenta は可観測性を強化し、入力、出力、データ フローを追跡してデバッグを容易にします。
Agenta を初期化し、LiteLLM コールバックを構成します:
import agenta as ag ag.init() litellm.callbacks = [ag.callbacks.litellm_handler()]
Agenta デコレータを使用したインストゥルメント機能:
@ag.instrument()
def generate_critique(pr_url: str):
# ... (Code remains the same)
return response.choices[0].message.contentAGENTA_API_KEY 環境変数 (Agenta から取得) を設定し、オプションでセルフホスティング用の AGENTA_HOST を設定します。

LLM プレイグラウンドの作成
Agenta のカスタム ワークフロー機能は、反復開発のための IDE のようなプレイグラウンドを提供します。 次のコード スニペットは、構成と Agenta との統合を示しています:
from pydantic import BaseModel, Field
from typing import Annotated
import agenta as ag
import litellm
from agenta.sdk.assets import supported_llm_models
# ... (previous code)
class Config(BaseModel):
system_prompt: str = prompt_system
user_prompt: str = prompt_user
model: Annotated[str, ag.MultipleChoice(choices=supported_llm_models)] = Field(default="gpt-3.5-turbo")
@ag.route("/", config_schema=Config)
@ag.instrument()
def generate_critique(pr_url:str):
diff = get_pr_diff(pr_url)
config = ag.ConfigManager.get_from_route(schema=Config)
response = litellm.completion(
model=config.model,
messages=[
{"content": config.system_prompt, "role": "system"},
{"content": config.user_prompt.format(diff=diff), "role": "user"},
],
)
return response.choices[0].message.contentAgenta によるサービスの提供と評価
- アプリ名と API キーを指定して
agenta initを実行します。 agenta variant serve app.pyを実行します。
これにより、エンドツーエンドのテストのために Agenta のプレイグラウンドを通じてアプリケーションにアクセスできるようになります。 評価には LLM-as-a-judge が使用されます。 評価者のプロンプトは次のとおりです:
<code>You are an evaluator grading the quality of a PR review. CRITERIA: ... (criteria remain the same) ANSWER ONLY THE SCORE. DO NOT USE MARKDOWN. DO NOT PROVIDE ANYTHING OTHER THAN THE NUMBER</code>
評価者のユーザープロンプト:
<code>https://patch-diff.githubusercontent.com/raw/{owner}/{repo}/pull/{pr_number}.diff</code>
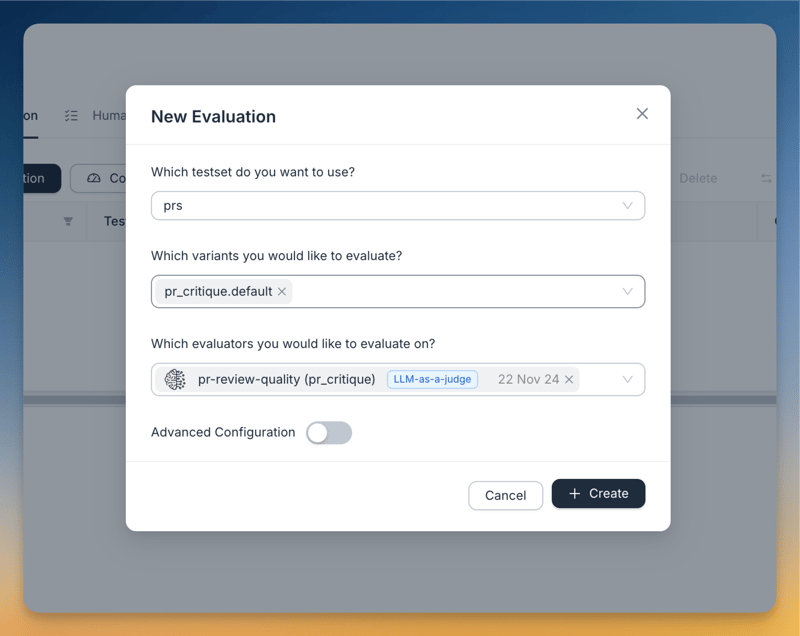
デプロイメントとフロントエンド
導入は Agenta の UI を通じて行われます:
- 概要ページに移動します。
- 選択したバリアントの横にある 3 つの点をクリックします。
- 「本番環境へのデプロイ」を選択します。

迅速な UI 作成には v0.dev フロントエンドが使用されました。
次のステップと結論
将来の改善には、プロンプト改良、完全なコードコンテキストの組み込み、大きな差分の処理が含まれます。 このチュートリアルでは、Agenta と LiteLLM を使用して本番環境に対応した AI プル リクエスト レビューアーを構築、評価、デプロイする方法を示します。

以上がvev、litellm、Agenta を使用して AI コード レビュー アシスタントを構築するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1670
1670
 14
1428
52
1329
25
1274
29
1256
24
14
1428
52
1329
25
1274
29
1256
24

 Python vs. C:曲線と使いやすさの学習
Apr 19, 2025 am 12:20 AM
Python vs. C:曲線と使いやすさの学習
Apr 19, 2025 am 12:20 AM
Pythonは学習と使用が簡単ですが、Cはより強力ですが複雑です。 1。Python構文は簡潔で初心者に適しています。動的なタイピングと自動メモリ管理により、使いやすくなりますが、ランタイムエラーを引き起こす可能性があります。 2.Cは、高性能アプリケーションに適した低レベルの制御と高度な機能を提供しますが、学習しきい値が高く、手動メモリとタイプの安全管理が必要です。
 Pythonと時間:勉強時間を最大限に活用する
Apr 14, 2025 am 12:02 AM
Pythonと時間:勉強時間を最大限に活用する
Apr 14, 2025 am 12:02 AM
限られた時間でPythonの学習効率を最大化するには、PythonのDateTime、時間、およびスケジュールモジュールを使用できます。 1. DateTimeモジュールは、学習時間を記録および計画するために使用されます。 2。時間モジュールは、勉強と休息の時間を設定するのに役立ちます。 3.スケジュールモジュールは、毎週の学習タスクを自動的に配置します。
 Python vs. C:パフォーマンスと効率の探索
Apr 18, 2025 am 12:20 AM
Python vs. C:パフォーマンスと効率の探索
Apr 18, 2025 am 12:20 AM
Pythonは開発効率でCよりも優れていますが、Cは実行パフォーマンスが高くなっています。 1。Pythonの簡潔な構文とリッチライブラリは、開発効率を向上させます。 2.Cのコンピレーションタイプの特性とハードウェア制御により、実行パフォーマンスが向上します。選択を行うときは、プロジェクトのニーズに基づいて開発速度と実行効率を比較検討する必要があります。
 Pythonの学習:2時間の毎日の研究で十分ですか?
Apr 18, 2025 am 12:22 AM
Pythonの学習:2時間の毎日の研究で十分ですか?
Apr 18, 2025 am 12:22 AM
Pythonを1日2時間学ぶだけで十分ですか?それはあなたの目標と学習方法に依存します。 1)明確な学習計画を策定し、2)適切な学習リソースと方法を選択します。3)実践的な実践とレビューとレビューと統合を練習および統合し、統合すると、この期間中にPythonの基本的な知識と高度な機能を徐々に習得できます。
 Python vs. C:重要な違いを理解します
Apr 21, 2025 am 12:18 AM
Python vs. C:重要な違いを理解します
Apr 21, 2025 am 12:18 AM
PythonとCにはそれぞれ独自の利点があり、選択はプロジェクトの要件に基づいている必要があります。 1)Pythonは、簡潔な構文と動的タイピングのため、迅速な開発とデータ処理に適しています。 2)Cは、静的なタイピングと手動メモリ管理により、高性能およびシステムプログラミングに適しています。
 Python Standard Libraryの一部はどれですか:リストまたは配列はどれですか?
Apr 27, 2025 am 12:03 AM
Python Standard Libraryの一部はどれですか:リストまたは配列はどれですか?
Apr 27, 2025 am 12:03 AM
PythonListSarePartOfThestAndardarenot.liestareBuilting-in、versatile、forStoringCollectionsのpythonlistarepart。
 Python:自動化、スクリプト、およびタスク管理
Apr 16, 2025 am 12:14 AM
Python:自動化、スクリプト、およびタスク管理
Apr 16, 2025 am 12:14 AM
Pythonは、自動化、スクリプト、およびタスク管理に優れています。 1)自動化:OSやShutilなどの標準ライブラリを介してファイルバックアップが実現されます。 2)スクリプトの書き込み:Psutilライブラリを使用してシステムリソースを監視します。 3)タスク管理:スケジュールライブラリを使用してタスクをスケジュールします。 Pythonの使いやすさと豊富なライブラリサポートにより、これらの分野で優先ツールになります。
 Web開発用のPython:主要なアプリケーション
Apr 18, 2025 am 12:20 AM
Web開発用のPython:主要なアプリケーション
Apr 18, 2025 am 12:20 AM
Web開発におけるPythonの主要なアプリケーションには、DjangoおよびFlaskフレームワークの使用、API開発、データ分析と視覚化、機械学習とAI、およびパフォーマンスの最適化が含まれます。 1。DjangoandFlask Framework:Djangoは、複雑な用途の迅速な発展に適しており、Flaskは小規模または高度にカスタマイズされたプロジェクトに適しています。 2。API開発:フラスコまたはdjangorestFrameworkを使用して、Restfulapiを構築します。 3。データ分析と視覚化:Pythonを使用してデータを処理し、Webインターフェイスを介して表示します。 4。機械学習とAI:Pythonは、インテリジェントWebアプリケーションを構築するために使用されます。 5。パフォーマンスの最適化:非同期プログラミング、キャッシュ、コードを通じて最適化
