この記事では、AIの検索された世代(RAG)の約束と現実を探ります。 RAGの機能、潜在的な利点、および実装中に発生した実際の課題と、開発されたソリューションと残りの質問を調べます。これは、RAGの能力とAIにおけるその進化する役割についての包括的な理解を提供します。
伝統的な生成AIは、時代遅れの情報や「幻覚」事実に依存することに苦しんでいます。 RAGは、AIにリアルタイムのデータアクセスを提供し、精度と関連性を向上させることにより、これに対処します。ただし、それは普遍的な解決策ではなく、特定のアプリケーションに基づいて適応が必要です。
 ラグの仕組み:
ラグの仕組み:
RAGは、応答生成中に外部の現在の情報を組み込むことにより、生成モデルを強化します。 プロセスには次のものが含まれます
クエリ開始:
ユーザーは質問をします。
-
検索のためのエンコーディング:クエリはテキスト埋め込み(デジタル表現)に変換されます。
- 関連データ取得:セマンティック検索では、埋め込みを使用して、キーワードだけでなく、意図に焦点を当てたデータセットから関連するデータを見つけます。
回答生成:- RAGシステムは、AIの知識を取得したデータと組み合わせて、コンテキストに関連する応答を作成します。
-
画像ソース
rag開発:
ragシステムの構築には:が含まれます
データ収集:関連する外部データ(教科書、マニュアルなど)を収集します。
データチャンキングとフォーマット:
大きなデータセットをより小さくて管理可能な部分に分解します。- >
データの埋め込み:
データチャンクを数値ベクトルに変換して、効率的な分析。
-
データ検索開発:クエリの意図を理解するためにセマンティック検索の実装。
- プロンプトの準備:CRAFTINTING PROMSTSを作成して、LLMの取得データの使用をガイドします。
しかし、このプロセスは、多くの場合、プロジェクト固有の課題を克服するために調整が必要です。
- ragの約束:
RAGは、より正確で関連性のある応答を提供し、ユーザーエクスペリエンスを改善することにより、情報の検索を簡素化することを目指しています。 また、企業はより良い意思決定のためにデータを活用することができます。 主な利点は次のとおりです
-
精度ブースト:誤った情報、時代遅れの回答、信頼できない情報源への依存度の低減。
- 会話検索:情報を見つけるための自然で人間のような相互作用を有効にします。
現実世界の課題:
有望である間、Ragは完璧な解決策ではありません。 私たちの経験は、いくつかの課題を強調しています:
AIは、取得した情報を誤解または誤用する可能性があります。
会話の検索のニュアンス:不完全またはコンテキストスイッチングクエリの処理は困難です。
データベースナビゲーション:大規模なデータベースを効率的に検索することが重要です
幻覚:AIは、データが利用できない場合に情報を発明する可能性があります。
「正しい」アプローチを見つける:単一のRAGアプローチは、さまざまなプロジェクトやデータセットで機能しない場合があります。
キーテイクアウトとragの未来:
重要なポイントには、適応性、継続的な改善、効果的なデータ管理の必要性が含まれます。 ぼろきれの未来には、
コンテキストの強化:会話のニュアンスをよりよく処理するためにNLPを改善しました。
より広範な実装:さまざまな業界でのより広い採用。
- 既存の課題に対する革新的なソリューション:幻覚のような問題への対処。
- 結論として、RAGは重要な可能性を提供しますが、その利点を完全に実現するために継続的な開発と適応が必要です。
以上が検索された世代:革命または過剰普及?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。


 ラグの仕組み:
ラグの仕組み: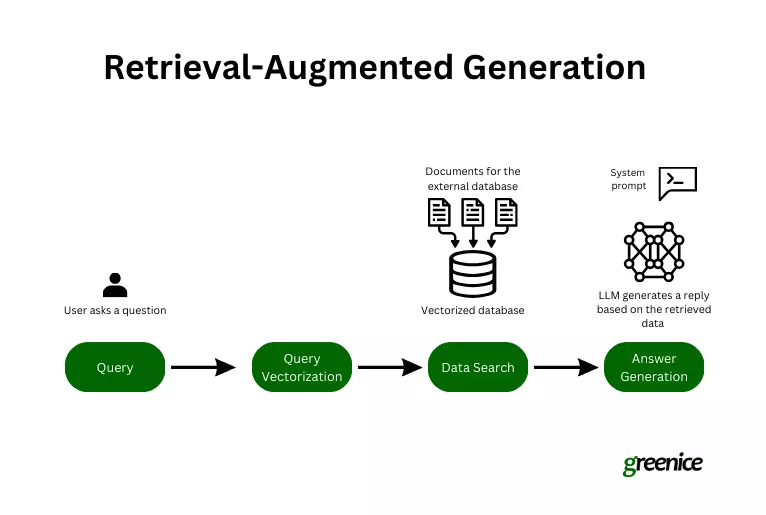 rag開発:
rag開発: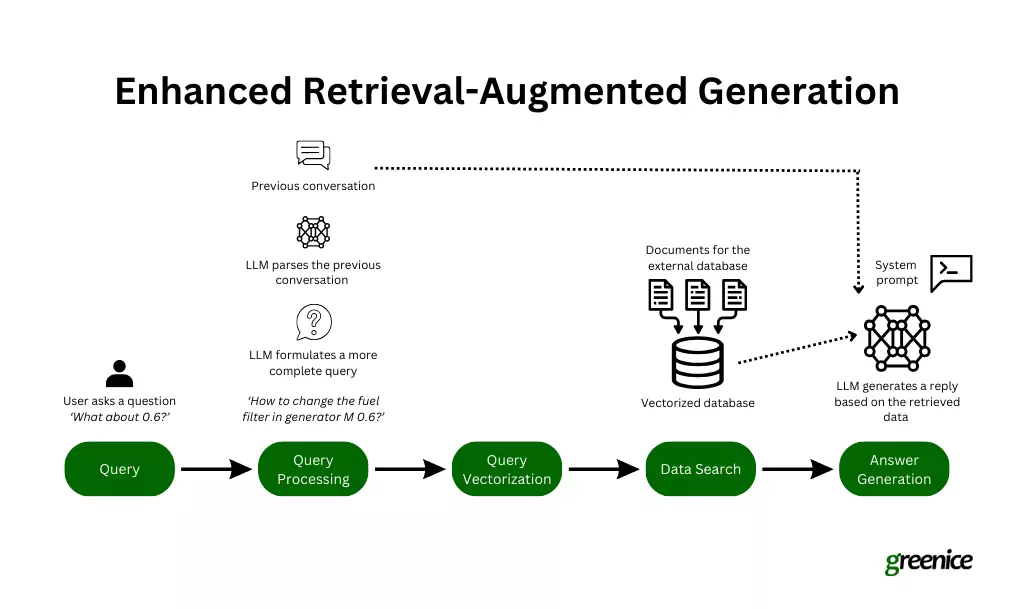
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



