

事業計画と起業家精神のためのAI駆動のスマートガイドの開発

あなたが中程度のメンバーでない場合は、このリンクで完全なストーリーを読むことができます。 ChatGPTの発売と次の大規模な言語モデル(LLMS)の急増後、幻覚、知識の削減日、および組織または人固有の情報を提供できないことの固有の制限はすぐに明らかになり、主要なものと見なされました。欠点。これらの問題に対処するために、検索拡張生成(RAG)メソッドはすぐに外部データをLLMに統合し、特定の知識ベースからの質問に答えるために行動を導く牽引力を獲得しました。 興味深いことに、RAGに関する最初の論文は2020年にFacebook AI Research(現在のMeta AI)の研究者によって掲載されましたが、その可能性が完全に実現されたのはChatGptの出現までではありませんでした。それ以来、停止はありませんでした。より高度で複雑なRAGフレームワークが導入され、このテクノロジーの精度が向上するだけでなく、マルチモーダルデータに対処することができ、幅広いアプリケーションの可能性を拡大しました。このトピックについては、次の記事で詳細に書きました。文脈的マルチモーダルRAG、ビジネスアプリケーションのマルチモーダルAI検索、情報抽出およびマッチメイキングプラットフォームについて説明しました。
マルチモーダルデータを大規模な言語モデルに統合します
マルチモーダルAIビジネスアプリケーションの検索ai駆動の情報抽出とマッチメイキング
RAGテクノロジーの拡大する状況と新たなデータアクセス要件により、静的な知識ベースからの質問に答えるレトリバーのみのRAGの機能は、他の多様な知識ソースとツールを統合することで拡張できることがわかりました。など:
複数のデータベース(たとえば、ベクトルデータベースと知識グラフで構成される知識ベース) 最近の情報にアクセスするためのリアルタイムWeb検索
外部API株式市場の動向などの特定のデータを収集したり、Slackチャネルや電子メールアカウントなどの企業固有のツールからデータを収集したりする データ分析、レポートライティング、文献レビュー、人々の検索など、データ分析、レポートの執筆、人々の検索などのタスクのツール。
複数のソースからの情報を比較および統合します。- これを達成するには、ぼろきれはクエリに基づいて最適な知識ソースおよび/またはツールを選択できる必要があります。 AIエージェントの出現により、クエリに基づいて最良のアクションコースを選択できる「
- エージェントラグ 」のアイデアが導入されました。この記事では、特定のエージェントRAGアプリケーションを開発します。これは、
- このエージェントのぼろきれの特別なことは何ですか?
-
さまざまなオープンソースモデルを選択するオプション ( - 応答の品質を向上させるための取得ドキュメントのグレーディング、およびグレーディングに基づいてWeb検索をインテリジェントに呼び出す。 応答タイプを選択するためのオプション:Concise、moderate、、または説明。 具体的には、この記事は次のトピックを中心に構成されています データの解析llamaparse を使用して知識ベースを構築します Langgraphを使用してエージェントワークフローを開発します 無料のオープンソースモデルを使用して、高度なエージェントRAG(以下、Smart Business GuideまたはSBGと呼ばれる)を開発する
- このアプリケーションのコード全体は、githubにあります。 アプリケーションコードは2つで構成されています。pyファイル:_AGENTICrag.py。 streamlit グラフィカルユーザーインターフェイス。
- _grade_documents_:ユーザーのクエリに基づいて、取得したチャンクの関連性を評価します。 _route_after_grading _:グレーディングに基づいて、検索されたドキュメントで応答をGenreateTまたはWeb検索に進むかどうかを決定します。
- websearch
- :Tavily Search EngineのAPIを使用してWebソースから情報を取得します。 Generate
- :提供されたコンテキストを使用してユーザーのクエリへの応答を生成します(Vector Storeおよび/またはWeb検索から取得した情報)。 _get_contact_tool_:フィンランドの移民サービスに関連する事前定義された信頼できるURLから連絡先情報を取得します。 _
- get_tax_info _:事前定義された信頼できるURLから税関連の情報を取得します _get_registration_info _:事前定義された信頼できるURLからフィンランドの会社登録プロセスの詳細を取得します。 _
- get_licensing_info_:フィンランドでのビジネスを始めるために必要なライセンスと許可に関する情報を取得します。 _ hybrid_search
- _:ドキュメントの検索結果とインターネット検索結果を組み合わせて、クエリに答えるためのより広範なコンテキストを提供します。 無関係な
- :ワークフローのフォーカスとは無関係の質問を処理します
- ここにワークフローのエッジがあります。
- _取得→grade_documents _:検索されたドキュメントがグレーディングのために送信されます。
- _grade_documents→websearch _:取得されたドキュメントが無関係であるとみなされた場合、Web検索が呼び出されます。 _
- grade_documents→生成_:検索されたドキュメントが関連する場合、応答生成に進みます。
- webearch→生成 :応答生成のWeb検索の結果に合格します。 _get_contact_tool、get_tax info
- 、_get_Registrationinfo、_get_licensinginfo→生成:これらの4つのツールから>へのエッジ生成ノードは、応答生成のために特定の信頼できるソースから取得した情報を渡します。 _hybridsearch →
- 生成:応答生成のために合計結果(vectorstore webearch)を渡します。 無関係な→ 生成
- :無関係な質問のフォールバック応答を提供します。 グラフ状態構造は、ワークフローの状態を維持するための容器として機能し、次の要素を含みます。 質問
:ワークフローを駆動するユーザーのクエリまたは入力。
- Generation :処理後に入力されるユーザーのクエリに対する最終生成された応答。 _ web_search_needed
- _:取得されたドキュメントの関連性に基づいてWeb検索が必要かどうかを示すフラグ。 ドキュメント :クエリに関連する取得または処理されたドキュメントのリスト。
- _Answer_style _:「Concise」、「Moderate」、または「説明」など、希望する答えのスタイルを指定します。
- グラフ状態構造は、次のように定義されています 次のルーター関数はクエリを分析し、処理のために関連するノードにルーティングします。ツール選択辞書とクエリからツール/ノードを選択するためのプロンプトを含むチェーンが作成されます。チェーンはルーターLLMを呼び出して、関連するツールを選択します。 ワークフローに関連していない質問は、_handle
- generateノードを介してフォールバック応答を提供する_handle ノードにルーティングされます。

検索とグレーディング
retiveノードは、ベクターストアから関連する情報のチャンクを取得するために、質問とともにレトリーバーを呼び出します。これらのチャンク( "
WebおよびHybrid Search")は、_grade ドキュメントに送信され、関連性を評価するためにノードノードに送信されます。格付けされたチャンク( "_filtereddocs ")に基づいて、_route_aftergradingnodeは、取得した情報を生成するか、Web検索を呼び出すかを決定します。ヘルパー関数_initialize_graderチェーングレーダーチェーンを初期化して、各チャンクの関連性を評価するようにグレーダーLLMを導くプロンプトを使用します。 _grade ドキュメントノードは、各チャンクを分析して、質問に関連するかどうかを判断します。チャンクごとに、チャンクが質問に関連しているかどうかに応じて、 "yes"または "no"を出力します。You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format. If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text. Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7]. Include the document name and page number at the start and end of each extracted page.
ログイン後にコピーログイン後にコピーログイン後にコピーログイン後にコピー_Web
検索ノードは、_route_aftergradingnodeのいずれかで到達します。どちらかの_internet_searchenabled状態フラグは "true"(selectedユーザーインターフェイスのラジオボタンによって)、またはルーター関数は、クエリを_WEBSEARCINGにルーティングすることを決定し、最近のより関連性のある情報を取得します。 タビリー検索エンジンの無料APIは、ウェブサイトでアカウントを作成することで取得できます。無料プランでは、1か月あたり1000のクレジットポイントが提供されます。タビリーの検索結果は、状態変数「document」に追加されます。これは、状態変数でノードを生成する
ノードに渡されます。ハイブリッド検索では、レトリバーとタビリー検索の両方の結果を組み合わせて、「document」状態変数を検索し、「question> question 」状態変数でノードを生成するために渡されます。 ツールの呼び出し
このエージェントワークフローで使用されるツールは、事前に定義された信頼できるURLから情報を取得するための廃棄関数です。 Tavilyとこれらのツールの違いは、多様なソースからの結果をもたらすために、より広範なインターネット検索を実行することです。一方、これらのツールはPythonの美しいスープWebスクラッピングライブラリを使用して、信頼できるソース(事前定義されたURL)から情報を抽出します。このようにして、特定のクエリに関する情報が、既知の信頼できるソースから抽出されていることを確認します。さらに、この情報検索は完全に無料ですここに、_get_taxinfoノードがいくつかのヘルパー関数で動作する方法があります。このタイプの他のツール(ノード)も同じ方法で機能します。
You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format. If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text. Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7]. Include the document name and page number at the start and end of each extracted page.
ログイン後にコピーログイン後にコピーログイン後にコピーログイン後にコピー応答の生成
ノード、Generateは、以下に説明する事前定義されたプロンプト(Langchainの prospttemplateclass)を使用してチェーンを呼び出すことにより最終応答を作成します。 _ragpromptは、状態変数を受信します_
nodeが最初に状態変数を取得します "n "、" context "、および" Answer_styl_e "をガイドし、全体をガイドします。応答スタイル、会話トーン、フォーマットガイドライン、引用ルール、ハイブリッドコンテキスト処理、コンテキストのみのフォーカスに関する指示を含む応答生成の動作。 generate questionimport os from llama_parse import LlamaParse from llama_index.core import SimpleDirectoryReader # Define parsing instructions parsing_instructions = """ Extract the text from the document using proper structure. """ def save_to_markdown(output_path, content): """ Save extracted content to a markdown file. Parameters: output_path (str): The path where the markdown file will be saved. content (list): The extracted content to be saved. """ with open(output_path, "w", encoding="utf-8") as md_file: for document in content: # Extract the text content from the Document object md_file.write(document.text + "nn") # Access the 'text' attribute def extract_document(input_path): # Initialize the LlamaParse parser parsing_instructions = """You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format. If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text. Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7]. Include the document name and page number at the start and end of each extracted page. """ parser = LlamaParse( result_type="markdown", parsing_instructions=parsing_instructions, premium_mode=True, api_key=LLAMA_CLOUD_API_KEY, verbose=True ) file_extractor = {".pdf": parser} documents = SimpleDirectoryReader( input_path, file_extractor=file_extractor ).load_data() return documents input_path = r"C:Usersh02317Downloadsdocs" # Replace with your document path output_file = r"C:Usersh02317Downloadsextracted_document.md" # Output markdown file name # Extract the document extracted_content = extract_document(input_path) save_to_markdown(output_file, extracted_content)ログイン後にコピーログイン後にコピー"、 "documents"、および「_answerstyle」およびフォーマット「ドキュメント」は、コンテキストとして機能する単一の文字列に入ります。その後、_ragpromptおよび応答生成LLM _を使用して生成チェーンを呼び出して、 "generatio_n" state変数に入力される最終回答を生成します。この状態変数は、_app.p_yによって使用されて、 retrylitユーザーインターフェイスに生成された応答を表示します。 GROQの無料APIを使用すると、モデルのレートまたはコンテキストウィンドウの制限に達する可能性があります。その場合、私はノードを生成して、モデル名のリストから円形のファッションでモデルを動的に切り替え、応答を生成した後の現在のモデルに戻すようにモデルを動的に切り替えました。 ヘルパー関数
アプリケーション、LLM、埋め込みモデル、およびセッション変数を初期化するために、_Agenticrag.pyには他の支援関数があります。関数_Initialize
appは、アプリの初期化中に[Creativity and Business, page 8] # How to use this book 1. The book is divided into six chapters and sub-sections dealing with different topics. You can read the book through one chapter and topic at a time, or you can use the checklist of the table of contents to select sections on topics in which you need more information and support. 2. Each section opens with a creative entrepreneur's thought on the topic. 3. The introduction gives a brief description of the topic. 4. Each section contains exercises that help you reflect on your own skills and business idea and develop your business idea further. ## What is your business idea "I would like to launch a touring theatre company." Do you have an idea about a product or service you would like to sell? Or do you have a bunch of ideas you have been mull- ing over for some time? This section will help you get a better understanding about your business idea and what competen- cies you already have that could help you implement it, and what types of competencies you still need to gain. ### EXTRA Business idea development in a nutshell I found a great definition of what business idea development is from the My Coach online service (Youtube 27 May 2014). It divides the idea development process into three stages: the thinking - stage, the (subconscious) talking - stage, and the customer feedback stage. It is important that you talk about your business idea, as it is very easy to become stuck on a particular path and ignore everything else. You can bounce your idea around with all sorts of people: with a local business advisor; an experienced entrepreneur; or a friend. As you talk about your business idea with others, your subconscious will start working on the idea, and the feedback from others will help steer the idea in the right direction. ### Recommended reading Taivas + helvetti (Terho Puustinen & Mika Mäkeläinen: One on One Publishing Oy 2013) ### Keywords treasure map; business idea; business idea development ## EXERCISE: Identifying your personal competencies Write down the various things you have done in your life and think what kind of competencies each of these things has given you. The idea is not just to write down your education, training and work experience like in a CV; you should also include hobbies, encounters with different types of people, and any life experiences that may have contributed to you being here now with your business idea. The starting circle can be you at any age, from birth to adulthood, depending on what types of experiences you have had time to accumulate. The final circle can be you at this moment. PERSONAL CAREER PATH SUPPLEMENTARY PERSONAL DEVELOPMENT (e.g. training courses; literature; seminars) Fill in the "My Competencies" section of the Creative Business Model Canvas: 5. Each section also includes an EXTRA box with interesting tidbits about the topic at hand. 6. For each topic, tips on further reading are given in the grey box. 7. The second grey box contains recommended keywords for searching more information about the topic online. 8. By completing each section of the one-page business plan or "Creative Business Model Canvas" (page 74), by the end of the book you will have a complete business plan. 9. By writing down your business start-up costs (e.g. marketing or logistics) in the price tag box of each section, by the time you get to the Finance and Administration section you will already know your start-up costs and you can enter them in the receipt provided in the Finance and Administration section (page 57). This book is based on Finnish practices. The authors and the publisher are not responsible for the applicability of factual information to other countries. Readers are advised to check country-specific information on business structures, support organisations, taxation, legislation, etc. Factual information about Finnish practices should also be checked in case of differing interpretations by authorities. [Creativity and Business, page 8]
ログイン後にコピーログイン後にコピーapp.py
から呼び出され、モデルまたは状態変数がretrylitアプリを介して変更されるたびに__がトリガーされます。コンポーネントを再活性化し、更新された状態を保存します。この機能は、さまざまなセッション変数を追跡し、冗長な初期化を防ぎます。 次のヘルパー関数は、回答LLM、埋め込みモデル、ルーターLLM、およびグレーディングLLMを初期化します。モデル名のリスト、_model リストは、 generatenode。
ワークフローの確立def staticChunker(folder_path): docs = [] print(f"Creating chunks. CHUNK_SIZE: {CHUNK_SIZE}, CHUNK_OVERLAP: {CHUNK_OVERLAP}") # Loop through all .md files in the folder for file_name in os.listdir(folder_path): if file_name.endswith(".md"): file_path = os.path.join(folder_path, file_name) print(f"Processing file: {file_path}") # Load documents from the Markdown file loader = UnstructuredMarkdownLoader(file_path) documents = loader.load() # Add file-specific metadata (optional) for doc in documents: doc.metadata["source_file"] = file_name # Split loaded documents into chunks text_splitter = RecursiveCharacterTextSplitter(chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP) chunked_docs = text_splitter.split_documents(documents) docs.extend(chunked_docs) return docsログイン後にコピーログイン後にコピーグラフ状態、ノード、_routequestionを使用した条件付きエントリポイント、およびエッジは、ノード間の流れを確立するために定義されています。最後に、ワークフローは実行可能ファイルAPPにコンパイルされており、
Streamlitインターフェイス内で使用されます。ワークフローの条件エントリポイントは、_routedef load_or_create_vs(persist_directory): # Check if the vector store directory exists if os.path.exists(persist_directory): print("Loading existing vector store...") # Load the existing vector store vectorstore = Chroma( persist_directory=persist_directory, embedding_function=st.session_state.embed_model, collection_name=collection_name ) else: print("Vector store not found. Creating a new one...n") docs = staticChunker(DATA_FOLDER) print("Computing embeddings...") # Create and persist a new Chroma vector store vectorstore = Chroma.from_documents( documents=docs, embedding=st.session_state.embed_model, persist_directory=persist_directory, collection_name=collection_name ) print('Vector store created and persisted successfully!') return vectorstoreログイン後にコピーquestion
関数を使用して、クエリに基づいてワークフローの最初のノードを選択します。条件付きエッジ(_WorkFlow.Add_Conditionalエッジ)は、
>>に移行するか、 によって決定されたチャンクの関連性に基づいてノードを生成するかを説明します。ドキュメントnode。 You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format. If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text. Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7]. Include the document name and page number at the start and end of each extracted page.
ログイン後にコピーログイン後にコピーログイン後にコピーログイン後にコピー流線インターフェイス
App.pyのretremlitアプリケーションは、モデル選択、回答スタイル、クエリ固有のツールの動的設定を使用して、質問をして回答を表示するインタラクティブなインターフェイスを提供します。 _agenticapp 関数、_agenticrag.pyからインポートされている
を関数、すべてのLLM、埋め込みモデル、および左サイドバーから選択されたその他のオプションを含むすべてのセッション変数を初期化します。 sys.stdout io.stringioバッファーにリダイレクトすることによってキャプチャされます。このバッファーの内容は、_text 領域コンポーネントを使用してデバッグプレースホルダーに表示されます。 ここに、retrylitインターフェイスのスナップショットがあります:
次の画像は、「import os from llama_parse import LlamaParse from llama_index.core import SimpleDirectoryReader # Define parsing instructions parsing_instructions = """ Extract the text from the document using proper structure. """ def save_to_markdown(output_path, content): """ Save extracted content to a markdown file. Parameters: output_path (str): The path where the markdown file will be saved. content (list): The extracted content to be saved. """ with open(output_path, "w", encoding="utf-8") as md_file: for document in content: # Extract the text content from the Document object md_file.write(document.text + "nn") # Access the 'text' attribute def extract_document(input_path): # Initialize the LlamaParse parser parsing_instructions = """You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format. If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text. Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7]. Include the document name and page number at the start and end of each extracted page. """ parser = LlamaParse( result_type="markdown", parsing_instructions=parsing_instructions, premium_mode=True, api_key=LLAMA_CLOUD_API_KEY, verbose=True ) file_extractor = {".pdf": parser} documents = SimpleDirectoryReader( input_path, file_extractor=file_extractor ).load_data() return documents input_path = r"C:Usersh02317Downloadsdocs" # Replace with your document path output_file = r"C:Usersh02317Downloadsextracted_document.md" # Output markdown file name # Extract the document extracted_content = extract_document(input_path) save_to_markdown(output_file, extracted_content)ログイン後にコピーログイン後にコピーllama-3.3–70b-ververatile
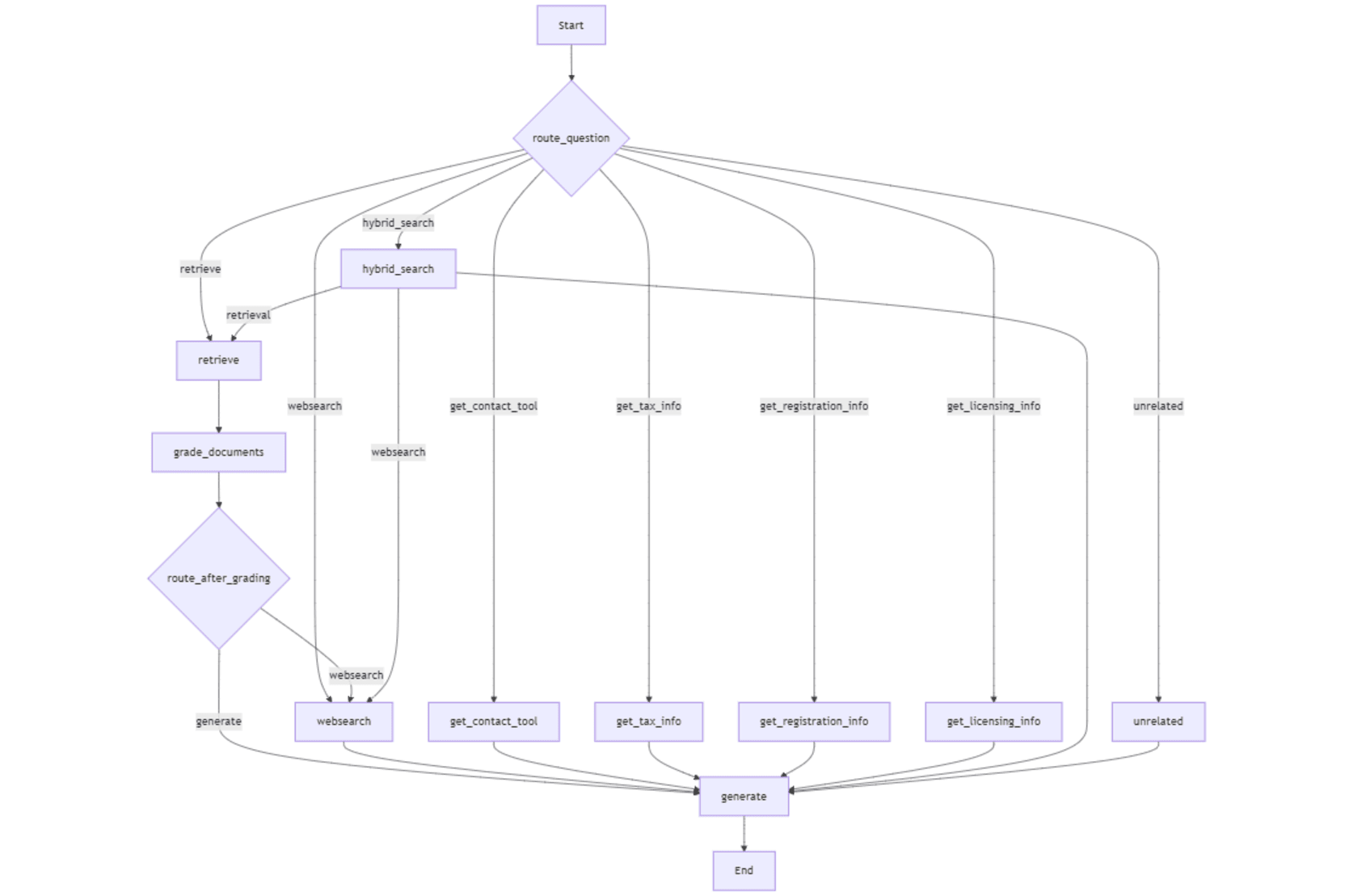
によって生成された答えを示しています。クエリルーター(_routequestion)はレトリバー(ベクトル検索)を呼び出し、グレーダー関数はすべての検索されたチャンクが関連するものを見つけます。したがって、生成ノードを介して回答を生成する決定は、_route_aftergradingnode。によって実行されます。 次の画像は、「説明」の回答スタイルを使用して、同じ質問に対する答えを示しています。 _ragPrompt
で指示されているように、LLMはより多くの説明で答えを詳しく述べています。
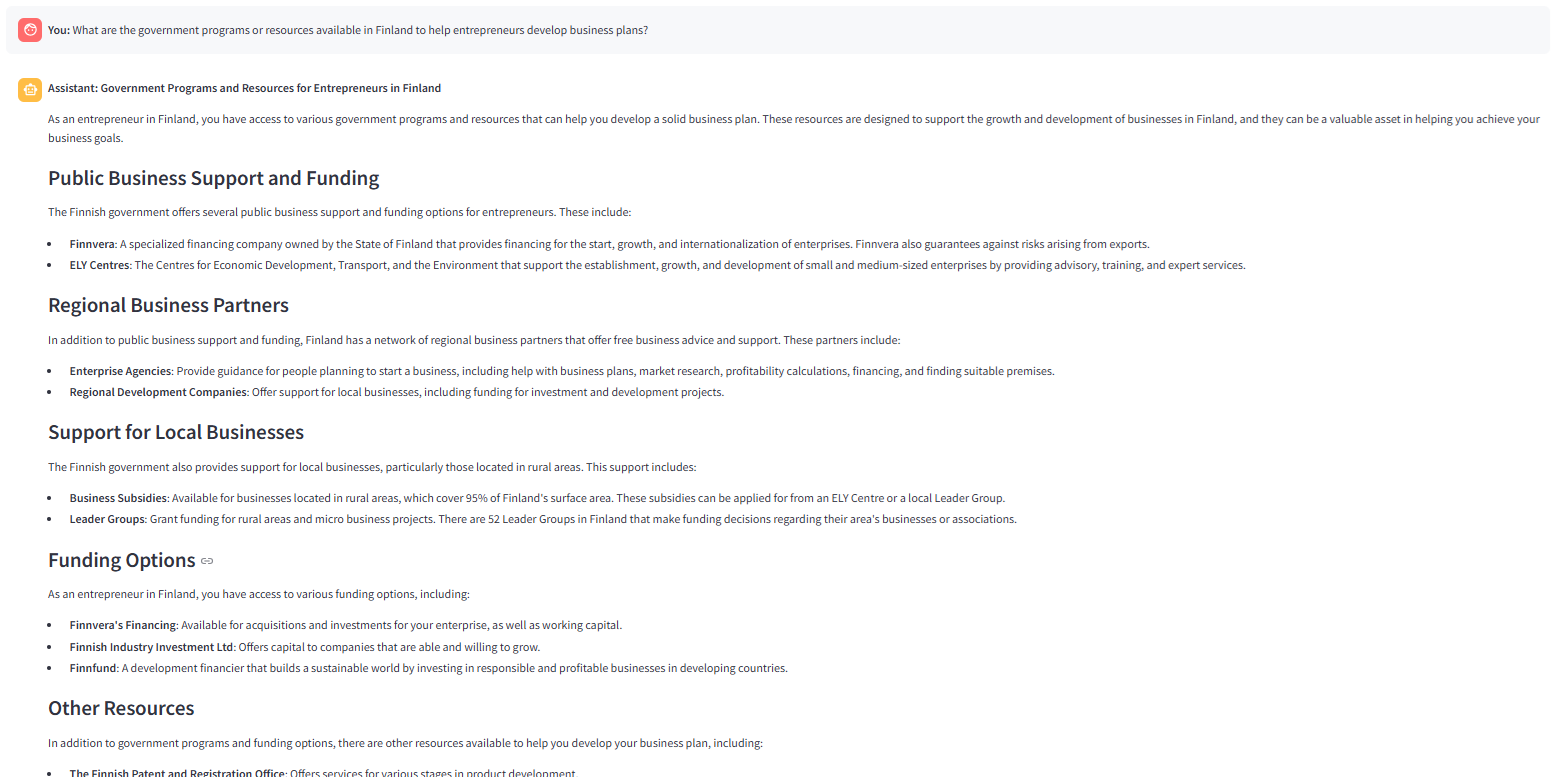
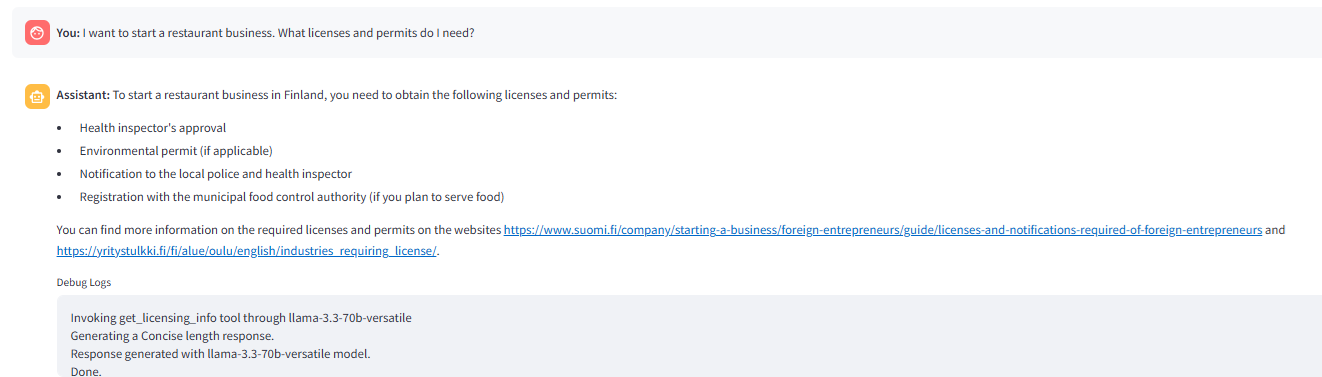
次の画像は、質問に応じて_get_license infoツールをトリガーするルーターを示しています。 次の画像は、ベクター検索で関連するチャンクが見つからない場合、_route_after
gradingnodeによって呼び出されたWeb検索を示しています。
次の画像は、 retrylit
アプリケーションで選択されたハイブリッド検索オプションで生成された応答を示しています。 _routequstion nodeは、_internet_searchinabledstate flag '
true’を見つけて、_hybrid searchnode。に質問をルーティングします。
このアプリケーションは、いくつかの方向、たとえばで強化できます - 音声対応の検索と質問を複数の言語で回答する(例:ロシア語、エストニア語、アラビア語など)
- 応答のさまざまな部分を選択し、詳細または説明を求めています。 最後の
- nメッセージの数のメモリを追加します。 問題の回答の他のモダリティ(画像など)を含む ブレーンストーミング、ライティング、およびアイデア生成のためのエージェントの追加
- それはすべての人です!
?)を叩き、コメントを書いて、MediumとLinkedInで私をフォローしてください。
Smart Business Guide(sbg) -
ビジネスおよび起業家精神は、ビジネス計画、起業家精神、会社の登録、課税、ビジネスのアイデア、規則と規制、ビジネス機会、ライセンスと許可、ビジネスガイドラインなどに関する情報を含む知識ベースとしてガイドします。
Web検索で、ソースを使用して最近の情報を取得します- 信頼できるソースから情報を取得するための知識抽出ツール。この情報には、関連当局の連絡先、最近の課税規則、最近の事業登録規則、最近のライセンス規制が含まれています。
)**、およびプロポンテリーモデルs _(gpt -4o、gpt-4o-min_i)エージェントワークフロー全体。オープンソースモデルはローカルで実行されないため、強力で高価なコンピューティングマシンを必要としません。代わりに、彼らは groqクラウドのplatfor
mで実行されます。そして、はい、これにより- cost-fre ** eエージェントラグになります。 GPTモデルは、OpenaiのAPIキーで選択することもできます。
ナレッジベースの検索、Web検索、ハイブリッド検索を実施するためのオプション。
それに飛び込もう。 SBGの知識ベースは、フィンランドの機関が発行した本物のビジネスと起業家精神ガイドで構成されています。これらのガイドは膨大であり、それらから必要な情報を見つけることは些細なことではないため、目的は、これらのガイドから正確な情報を提供できるだけでなく、Web検索や他の信頼できるソースでそれらを増強できるエージェントRAGを開発することです。更新された情報についてはフィンランド。 llamaparseは、LLMSで構築されたLLMユースケース用に構築されたGenai-Nativeドキュメント解析プラットフォームです。上記の記事でLlamaparseの使用を説明しました。今回は、Lamacloudでドキュメントを直接解析しました。 Llamaparseは、1日あたり1000の無料クレジットを提供しています。これらのクレジットの使用は、解析モードに依存します。テキストのみのPDFの場合、「fast」モード(1クレジット / 3ページ)がうまく機能し、OCR、画像抽出、テーブル /見出しの識別をスキップします。ページごとにより多くのクレジットポイントを備えた、他にも高度なモードが利用可能です。 OCR、画像抽出、およびテーブル/見出しの識別を実行する「プレミアム」モードを選択しました。画像のある複雑なドキュメントに最適です。
このページの解析出力は次のとおりです。 Lamaparseは、ページ内のすべての構造から情報を効率的に抽出しました。ページに示されているノートブックは画像形式です。
を使用してチャンクに分割されます。
All-Minilm-L6-V2モデルまたはOpenaiのText-Embedding-3-Large などの埋め込みモデルを使用して、VectorStoreがChromaデータベースに作成されます。 。 エージェントワークフローの作成
AIエージェントは、ワークフローと意思決定ロジックの組み合わせであり、質問にインテリジェントに答えたり、より単純なサブタスクに分割する必要がある他の複雑なタスクを実行したりします。
ランググラフを使用して、グラフの形で一連のアクションまたは決定のためにAIエージェント用のワークフローを設計しました。私たちのエージェントは、Vectorデータベース(ナレッジベース)、Web検索、ハイブリッド検索、またはツールを使用して質問に答えるかどうかを決定する必要があります。
自動インターネット検索で無料のAIエージェントを開発する方法決定を下すためのワークフローを表すグラフ エッジで接続されており、決定と行動の流れを定義します(たとえば、検索後の次の状態は何ですか)。グラフ状態は、情報がグラフを介して移動するときに情報を追跡し、エージェントが各ステップに正しいデータを使用するようにします。
ワークフローのエントリポイントは、ユーザーのクエリを分析してワークフローで実行する初期ノードを決定するルーター関数です。ワークフロー全体には、次のノードが含まれています
取得LlamaparsingとLangchainを使用して知識ベースを構築します
You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format.
If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text.
Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7].
Include the document name and page number at the start and end of each extracted page.
 recursiveCharacterTextSplitter
recursiveCharacterTextSplitter[Creativity and Business, page 8]
# How to use this book
1. The book is divided into six chapters and sub-sections dealing with different topics. You can read the book through one chapter and topic at a time, or you can use the checklist of the table of contents to select sections on topics in which you need more information and support.
2. Each section opens with a creative entrepreneur's thought on the topic.
3. The introduction gives a brief description of the topic.
4. Each section contains exercises that help you reflect on your own skills and business idea and develop your business idea further.
## What is your business idea
"I would like to launch
a touring theatre company."
Do you have an idea about a product or service you would like
to sell? Or do you have a bunch of ideas you have been mull-
ing over for some time? This section will help you get a better
understanding about your business idea and what competen-
cies you already have that could help you implement it, and
what types of competencies you still need to gain.
### EXTRA
Business idea development
in a nutshell
I found a great definition of what business idea development
is from the My Coach online service (Youtube 27 May 2014).
It divides the idea development process into three stages:
the thinking - stage, the (subconscious) talking - stage, and the
customer feedback stage. It is important that you talk about
your business idea, as it is very easy to become stuck on a
particular path and ignore everything else. You can bounce
your idea around with all sorts of people: with a local business
advisor; an experienced entrepreneur; or a friend. As you talk
about your business idea with others, your subconscious will
start working on the idea, and the feedback from others will
help steer the idea in the right direction.
### Recommended reading
Taivas + helvetti
(Terho Puustinen & Mika Mäkeläinen:
One on One Publishing Oy 2013)
### Keywords
treasure map; business idea; business idea development
## EXERCISE: Identifying your personal competencies
Write down the various things you have done in your life and think what kind of competencies each of these things has
given you. The idea is not just to write down your education,
training and work experience like in a CV; you should also
include hobbies, encounters with different types of people, and any life experiences that may have contributed to you
being here now with your business idea. The starting circle can be you at any age, from birth to adulthood, depending
on what types of experiences you have had time to accumulate. The final circle can be you at this moment.
PERSONAL CAREER PATH
SUPPLEMENTARY
PERSONAL DEVELOPMENT
(e.g. training courses;
literature; seminars)
Fill in the
"My Competencies"
section of the
Creative Business
Model Canvas:
5. Each section also includes an EXTRA box with interesting tidbits about the topic at hand.
6. For each topic, tips on further reading are given in the grey box.
7. The second grey box contains recommended keywords for searching more information about the topic online.
8. By completing each section of the one-page business plan or "Creative Business Model Canvas" (page 74),
by the end of the book you will have a complete business plan.
9. By writing down your business start-up costs (e.g. marketing or logistics) in the price tag box of each section,
by the time you get to the Finance and Administration section you will already know your start-up costs
and you can enter them in the receipt provided in the Finance and Administration section (page 57).
This book is based on Finnish practices. The authors and the publisher are not responsible for the applicability of factual information to other
countries. Readers are advised to check country-specific information on business structures, support organisations, taxation, legislation, etc.
Factual information about Finnish practices should also be checked in case of differing interpretations by authorities.
[Creativity and Business, page 8]
def staticChunker(folder_path):
docs = []
print(f"Creating chunks. CHUNK_SIZE: {CHUNK_SIZE}, CHUNK_OVERLAP: {CHUNK_OVERLAP}")
# Loop through all .md files in the folder
for file_name in os.listdir(folder_path):
if file_name.endswith(".md"):
file_path = os.path.join(folder_path, file_name)
print(f"Processing file: {file_path}")
# Load documents from the Markdown file
loader = UnstructuredMarkdownLoader(file_path)
documents = loader.load()
# Add file-specific metadata (optional)
for doc in documents:
doc.metadata["source_file"] = file_name
# Split loaded documents into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP)
chunked_docs = text_splitter.split_documents(documents)
docs.extend(chunked_docs)
return docs
を作成する必要があります(例:Web検索またはベクトルデータベース検索)。ノードは、:VectorStoreからセマンティックに似た類似の情報の塊を取得します。
 question
question
 nodeによって呼び出されたWeb検索を示しています。
nodeによって呼び出されたWeb検索を示しています。
 qustion
qustion 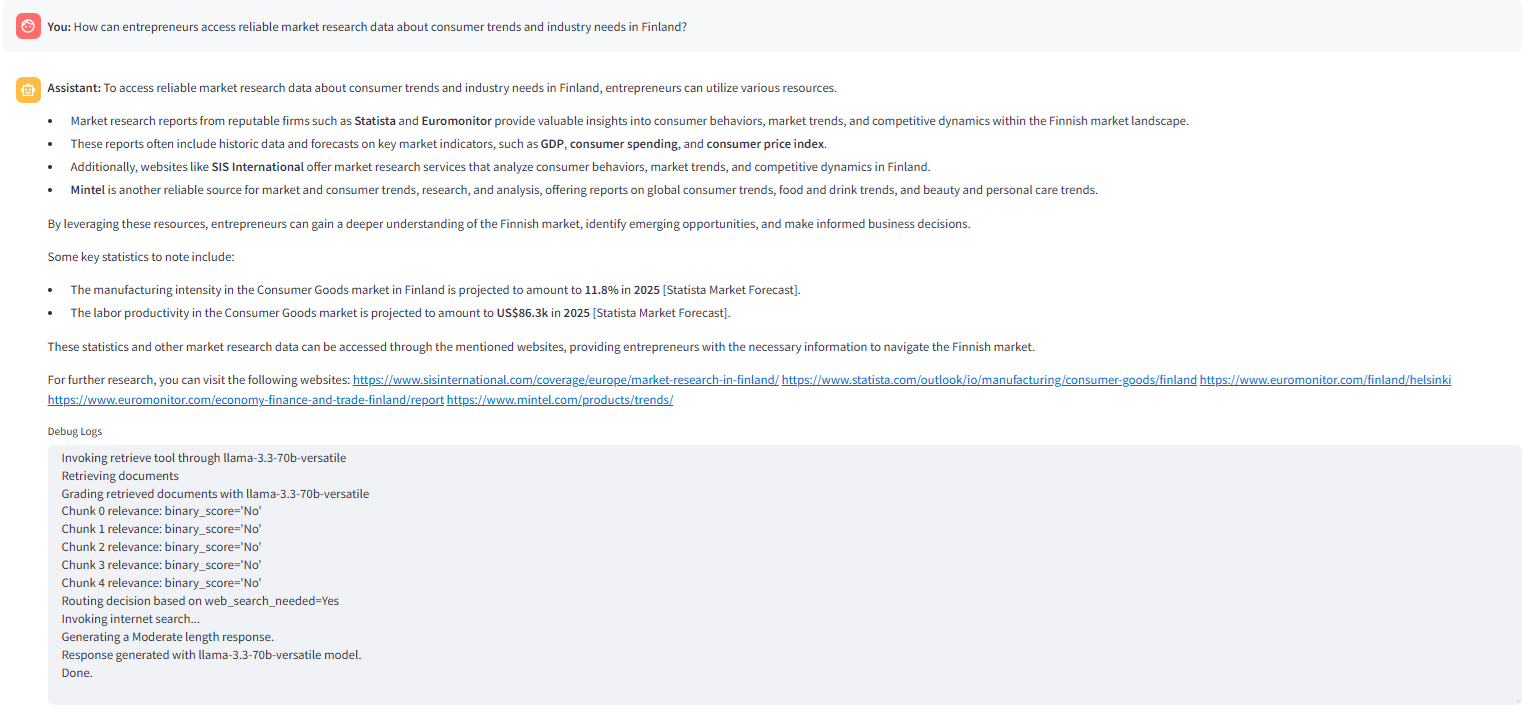 ’を見つけて、_hybrid
’を見つけて、_hybrid 以上が事業計画と起業家精神のためのAI駆動のスマートガイドの開発の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1666
1666
 14
1426
52
1328
25
1273
29
1253
24
14
1426
52
1328
25
1273
29
1253
24

 10生成AIコーディング拡張機能とコードのコードを探る必要があります
Apr 13, 2025 am 01:14 AM
10生成AIコーディング拡張機能とコードのコードを探る必要があります
Apr 13, 2025 am 01:14 AM
ねえ、忍者をコーディング!その日はどのようなコーディング関連のタスクを計画していますか?このブログにさらに飛び込む前に、コーディング関連のすべての問題について考えてほしいです。 終わり? - &#8217を見てみましょう
 GPT-4o vs Openai O1:新しいOpenaiモデルは誇大広告に値しますか?
Apr 13, 2025 am 10:18 AM
GPT-4o vs Openai O1:新しいOpenaiモデルは誇大広告に値しますか?
Apr 13, 2025 am 10:18 AM
導入 Openaiは、待望の「Strawberry」アーキテクチャに基づいて新しいモデルをリリースしました。 O1として知られるこの革新的なモデルは、推論能力を強化し、問題を通じて考えられるようになりました
 SQLに列を追加する方法は? - 分析Vidhya
Apr 17, 2025 am 11:43 AM
SQLに列を追加する方法は? - 分析Vidhya
Apr 17, 2025 am 11:43 AM
SQLの変更テーブルステートメント:データベースに列を動的に追加する データ管理では、SQLの適応性が重要です。 その場でデータベース構造を調整する必要がありますか? Alter Tableステートメントはあなたの解決策です。このガイドの詳細は、コルを追加します
 PIXTRAL -12B:Mistral AI'の最初のマルチモーダルモデル-Analytics Vidhya
Apr 13, 2025 am 11:20 AM
PIXTRAL -12B:Mistral AI'の最初のマルチモーダルモデル-Analytics Vidhya
Apr 13, 2025 am 11:20 AM
導入 Mistralは、最初のマルチモーダルモデル、つまりPixtral-12B-2409をリリースしました。このモデルは、Mistralの120億個のパラメーターであるNemo 12bに基づいて構築されています。このモデルを際立たせるものは何ですか?これで、画像とTexの両方を採用できます
 AGNOフレームワークを使用してマルチモーダルAIエージェントを構築する方法は?
Apr 23, 2025 am 11:30 AM
AGNOフレームワークを使用してマルチモーダルAIエージェントを構築する方法は?
Apr 23, 2025 am 11:30 AM
エージェントAIに取り組んでいる間、開発者は速度、柔軟性、リソース効率の間のトレードオフをナビゲートすることがよくあります。私はエージェントAIフレームワークを探索していて、Agnoに出会いました(以前はPhi-でした。
 ラマドラマを超えて:大規模な言語モデル用の4つの新しいベンチマーク
Apr 14, 2025 am 11:09 AM
ラマドラマを超えて:大規模な言語モデル用の4つの新しいベンチマーク
Apr 14, 2025 am 11:09 AM
問題のあるベンチマーク:ラマのケーススタディ 2025年4月上旬、MetaはLlama 4スイートのモデルを発表し、GPT-4oやClaude 3.5 Sonnetなどの競合他社に対して好意的に位置付けた印象的なパフォーマンスメトリックを誇っています。ラウンクの中心
 ADHDゲーム、ヘルスツール、AIチャットボットがグローバルヘルスを変える方法
Apr 14, 2025 am 11:27 AM
ADHDゲーム、ヘルスツール、AIチャットボットがグローバルヘルスを変える方法
Apr 14, 2025 am 11:27 AM
ビデオゲームは不安を緩和したり、ADHDの子供を焦点を合わせたり、サポートしたりできますか? ヘルスケアの課題が世界的に急増しているため、特に若者の間では、イノベーターはありそうもないツールであるビデオゲームに目を向けています。現在、世界最大のエンターテイメントインダスの1つです
 OpenaiはGPT-4.1でフォーカスをシフトし、コーディングとコスト効率を優先します
Apr 16, 2025 am 11:37 AM
OpenaiはGPT-4.1でフォーカスをシフトし、コーディングとコスト効率を優先します
Apr 16, 2025 am 11:37 AM
このリリースには、GPT-4.1、GPT-4.1 MINI、およびGPT-4.1 NANOの3つの異なるモデルが含まれており、大規模な言語モデルのランドスケープ内のタスク固有の最適化への動きを示しています。これらのモデルは、ようなユーザー向けインターフェイスをすぐに置き換えません
