

reft:微調整llms
への革新的なアプローチ スタンフォードの2024年5月の論文で導入されたreft(表現Finetuning)は、効率的に微調整する大規模な言語モデル(LLMS)の画期的な方法を提供します。 その可能性はすぐに明らかになり、Oxen.AIの2024年7月の実験でさらに強調されました。14分で単一のNVIDIA A10 GPUでLLAMA3(8B)を微調整しました。
モデルの重みや入力を変更するLORAなどの既存のパラメーター効率の高い微調整(PEFT)メソッドとは異なり、REFTは分散インターチェンジ介入(DII)メソッドを活用します。 DIIは、このサブスペースを微調整できるように、埋め込みをより低次元のサブスペースにプロジェクトします。 この記事は、最初に人気のあるPEFTアルゴリズム(LORA、プロンプトチューニング、プレフィックスチューニング)をレビューし、次にDIIを説明し、REFTとその実験結果を掘り下げてください。
パラメーター効率の高い微調整(PEFT)テクニック
 huggingフェイスは、PEFTテクニックの包括的な概要を提供します。 重要な方法を簡単に要約してみましょう:
huggingフェイスは、PEFTテクニックの包括的な概要を提供します。 重要な方法を簡単に要約してみましょう:
2021年に導入されたLoraのシンプルさと一般化により、LLMSと拡散モデルの微調整のための主要なテクニックになりました。 すべての層の重みを調整する代わりに、LORAは低ランクマトリックスを追加し、トレーニング可能なパラメーター(多くの場合0.3%未満)を大幅に削減し、トレーニングを加速し、GPUメモリの使用量を最小化します。
プロンプトチューニング:
このメソッドは、「ソフトプロンプト」(解放可能なタスク固有の埋め込み)を使用し、各タスクのモデルを複製せずに効率的なマルチタスク予測を可能にします。

プレフィックスチューニング(p調整V2):
迅速なチューニングの制限のアドレス指定、プレフィックスチューニングは、さまざまなレベルでトレーニング可能なプロンプトの埋め込みを追加し、さまざまなレベルでタスク固有の学習を可能にします。 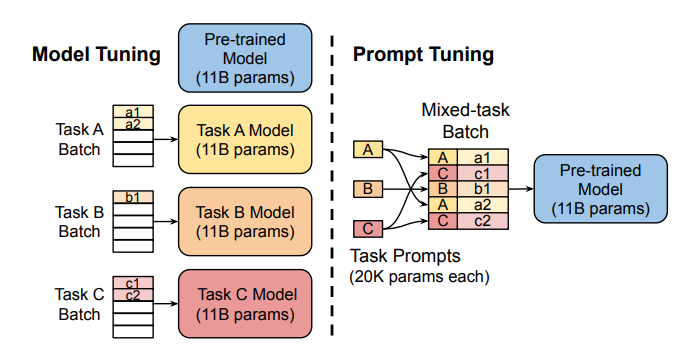
loraの堅牢性と効率により、LLMSで最も広く使用されているPEFTメソッドになります。 詳細な経験的比較は、この論文
ここ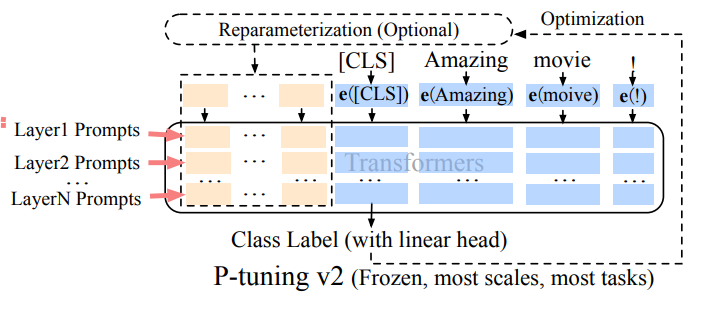 。
。
DIIプロセスは、数学的に次のように表現できます
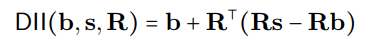
は直交投影を表し、分散アライメント検索(DAS)がサブスペースを最適化して、介入後に予想される反事実出力の確率を最大化します。
Rreft - 表現Finetuning
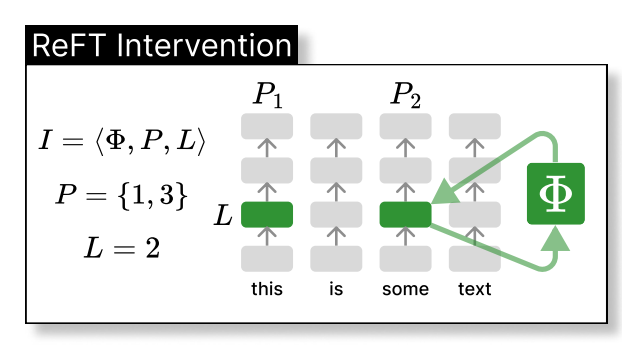 loreft(低ランク線形サブスペースreft)は、学習された投影ソースを紹介します:
loreft(低ランク線形サブスペースreft)は、学習された投影ソースを紹介します:
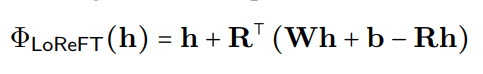 ここで、
ここで、
heditsRshR
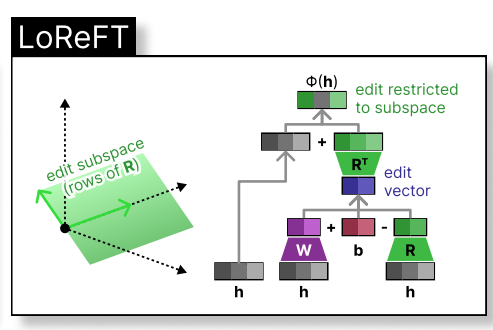
LLM微調整中、LLMパラメーターは凍結されたままで、投影パラメータ(phi={R, W, b})のみが訓練されています。
 ディスカッション
ディスカッション
以上がreftは必要なすべてですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



