

大規模な言語モデル(LLMS)の背後にある魔法を発表する:2部構成の探索
大規模な言語モデル(LLM)はしばしば魔法のように見えますが、その内部の仕組みは驚くほど体系的です。この2部構成のシリーズは、LLMSを分裂させ、今日使用しているAIシステムへの構築、トレーニング、および改良を説明しています。 Andrej Karpathyの洞察力に富んだ(そして長い!)YouTubeビデオに触発されたこのコンデンスバージョンは、よりアクセスしやすい形式でコアコンセプトを提供します。 Karpathyのビデオは強くお勧めしますが(わずか10日で800,000回の視聴!)、この10分間の読み取りでは、最初の1.5時間から重要なポイントが蒸留されます。
パート1:生データからベースモデル
LLM開発には、トレーニング前とトレーニング後の2つの重要なフェーズが含まれます。
1。トレーニング前:言語の指導
テキストを生成する前に、LLMは言語構造を学習する必要があります。この計算的に集中的にトレーニング前プロセスには、いくつかのステップが含まれます
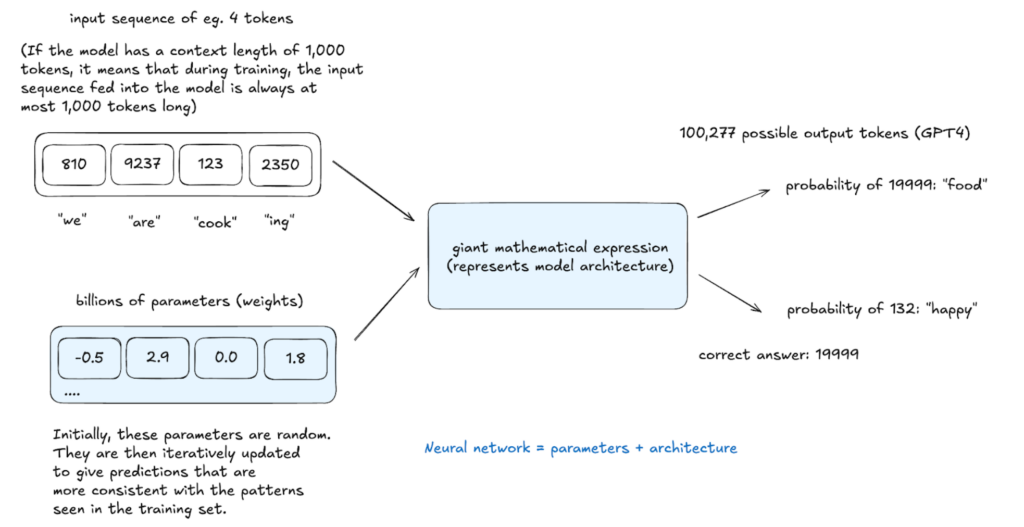
 ニューラルネットワークトレーニング:
ニューラルネットワークトレーニング:
 2。訓練後:実用用の精製
2。訓練後:実用用の精製
ベースモデルは、小型の特殊なデータセットを使用して、トレーニング後に洗練されています。 これは明示的なプログラミングではなく、構造化された例による暗黙の指示です。 トレーニング後の方法は
を含みます
任意の段階で実行される
推論は、モデル学習を評価します。 このモデルは、この分布の潜在的なトークンとサンプルに確率を割り当て、トレーニングデータに明示的にテキストを作成しますが、統計的に一致しています。この確率的プロセスは、同じ入力からのさまざまな出力を可能にします。 幻覚:誤った情報への対処
幻覚は、LLMが誤った情報を生成すると、確率的な性質から生じます。 彼らは事実を「知らない」が、可能性のある単語シーケンスを予測します。 緩和戦略には以下が含まれます
「わからない」トレーニング:
モデルを明示的にトレーニングして、自己傍観と自動化された質問生成を通じて知識のギャップを認識しています。 Web Search Integration:以上がLLMSの仕組み:トレーニング後、ニューラルネットワーク、幻覚、推論への事前トレーニングの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



