

大規模な言語モデルのトレーニング:TRPOからGRPOまで

deepseek:LLMS
の補強学習に深く潜りますDeepseekの最近の成功は、低コストで印象的なパフォーマンスを達成し、大規模な言語モデル(LLM)トレーニング方法の重要性を強調しています。この記事では、TRPO、PPO、および新しいGRPOアルゴリズムを調査する強化学習(RL)の側面に焦点を当てています。 機械学習、ディープラーニング、およびLLMに基本的に精通していると仮定して、複雑な数学を最小限に抑えてアクセスしやすくします。
LLMトレーニングの3つの柱
- 事前トレーニング:モデルは、大規模なデータセットを使用して、前のトークンからのシーケンスで次のトークンを予測することを学びます。 監視された微調整(SFT):
- ターゲットデータはモデルを改良し、特定の指示に合わせてモデルを調整します。 強化学習(RLHF): この段階であるこの記事の焦点は、直接的なフィードバックを通じて人間の好みに合わせてよりよく一致するための応答をさらに改善します。
- 強化学習基礎
補強学習には、
環境と相互作用する エージェント
エージェント
状態に存在し、アクションを取得して新しい状態に移行します。各アクションは、環境からの報酬を導き出し、エージェントの将来の行動を導きます。 迷路をナビゲートするロボットを考えてみてください。その位置は状態であり、動きは行動であり、出口に到達すると肯定的な報酬が得られます。 LLMSの rl:詳細な外観 LLMトレーニングでは、コンポーネントは次のとおりです
- エージェント: LLM自体。
- 環境:ユーザープロンプト、フィードバックシステム、コンテキスト情報などの外部要因。
- アクション:クエリに応じてLLMが生成するトークン。 state:
- 現在のクエリと生成されたトークン(部分的な応答)。 報酬: 通常は、人間が発表したデータでトレーニングされた別の
- 報酬モデル、スコアの割り当てのランキング応答によって決定されます。高品質の応答は、より高い報酬を受け取ります。 Deepseekmathなどの特定の場合には、よりシンプルなルールベースの報酬が可能です。 ポリシー>どのアクションを実行するかを決定します。 LLMの場合、次のトークンをサンプリングするために使用される可能性のあるトークン上の確率分布です。 RLトレーニングにより、ポリシーのパラメーター(モデル重量)が調整され、高度なトークンが優先されます。 多くの場合、ポリシーは次のように表されます
RLのコアは、最適なポリシーを見つけることです。 監視された学習とは異なり、私たちは報酬を使用してポリシーの調整をガイドします。 TRPO(信頼地域のポリシーの最適化)
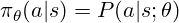
TRPOは、監視された学習の損失関数に類似したアドバンテージ関数を使用しますが、報酬から派生しました。
TRPOは、以前の反復からの大きなポリシーの逸脱を防ぎ、安定性を確保するために制約された代理目標を最大化します。

PPO(近位のポリシーの最適化)
ChatGptやGeminiなどのLLMよりも希望されている
grpo(グループ相対ポリシーの最適化)
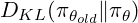
GRPOは、個別の値モデルを排除することにより、トレーニングを合理化します。クエリごとに、応答のグループを生成し、報酬に基づいてZスコアとして利点を計算します。
これにより、プロセスが簡素化され、複数の応答を生成するLLMSの能力に適しています。 GRPOには、現在のポリシーを参照ポリシーと比較して、KL Divergence用語も組み込まれています。最終的なGRPOの定式化は次のとおりです

補強学習、特にPPOと新しいGRPOは、最新のLLMトレーニングにとって重要です。 各方法はRLの基礎に基づいて構築され、安定性、効率、および人間のアラインメントのバランスをとるさまざまなアプローチを提供します。 Deepseekの成功は、他の革新とともにこれらの進歩を活用しています。 強化学習は、LLM機能の進歩においてますます支配的な役割を果たす態勢が整っています。 参考文献:
(参照は同じままで、より良い読みやすさのために再フォーマットされただけです) [1]「大規模な言語モデルの基礎」、2025年
[2]「強化学習」。エナリス。入手可能:- https://www.php.cn/link/20e169b48c8f869887e2bbe1c5c3ea65
- [3] Y. Gokhale。 「LLMSおよび生成AIパート5:RLHFの紹介」、 Medium
- 、2023。 [4] L. Weng。 「強化学習の概要」2018年 [5] "Deepseek-R1:補強学習によるLLMSの推論能力を奨励する"、2025。 [6]「Deepseekmath:オープン言語モデルの数学的推論の限界を押し上げる」、2025年。
- [7]「信頼地域のポリシーの最適化」、2017年
以上が大規模な言語モデルのトレーニング:TRPOからGRPOまでの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7889
7889
 15
1650
14
1411
52
1302
25
1248
29
15
1650
14
1411
52
1302
25
1248
29

 クリエイティブプロジェクトのための最高のAIアートジェネレーター(無料&有料)
Apr 02, 2025 pm 06:10 PM
クリエイティブプロジェクトのための最高のAIアートジェネレーター(無料&有料)
Apr 02, 2025 pm 06:10 PM
この記事では、トップAIアートジェネレーターをレビューし、その機能、創造的なプロジェクトへの適合性、価値について説明します。 Midjourneyを専門家にとって最高の価値として強調し、高品質でカスタマイズ可能なアートにDall-E 2を推奨しています。
 Meta Llama 3.2を始めましょう - 分析Vidhya
Apr 11, 2025 pm 12:04 PM
Meta Llama 3.2を始めましょう - 分析Vidhya
Apr 11, 2025 pm 12:04 PM
メタのラマ3.2:マルチモーダルとモバイルAIの前進 メタは最近、ラマ3.2を発表しました。これは、モバイルデバイス向けに最適化された強力なビジョン機能と軽量テキストモデルを特徴とするAIの大幅な進歩です。 成功に基づいてo
 ベストAIチャットボットが比較されました(chatgpt、gemini、claude& more)
Apr 02, 2025 pm 06:09 PM
ベストAIチャットボットが比較されました(chatgpt、gemini、claude& more)
Apr 02, 2025 pm 06:09 PM
この記事では、ChatGpt、Gemini、ClaudeなどのトップAIチャットボットを比較し、自然言語の処理と信頼性における独自の機能、カスタマイズオプション、パフォーマンスに焦点を当てています。
 トップAIライティングアシスタントは、コンテンツの作成を後押しします
Apr 02, 2025 pm 06:11 PM
トップAIライティングアシスタントは、コンテンツの作成を後押しします
Apr 02, 2025 pm 06:11 PM
この記事では、Grammarly、Jasper、Copy.ai、Writesonic、RytrなどのトップAIライティングアシスタントについて説明し、コンテンツ作成のためのユニークな機能に焦点を当てています。 JasperがSEOの最適化に優れているのに対し、AIツールはトーンの維持に役立つと主張します
 10生成AIコーディング拡張機能とコードのコードを探る必要があります
Apr 13, 2025 am 01:14 AM
10生成AIコーディング拡張機能とコードのコードを探る必要があります
Apr 13, 2025 am 01:14 AM
ねえ、忍者をコーディング!その日はどのようなコーディング関連のタスクを計画していますか?このブログにさらに飛び込む前に、コーディング関連のすべての問題について考えてほしいです。 終わり? - &#8217を見てみましょう
 AVバイト:Meta' s llama 3.2、GoogleのGemini 1.5など
Apr 11, 2025 pm 12:01 PM
AVバイト:Meta' s llama 3.2、GoogleのGemini 1.5など
Apr 11, 2025 pm 12:01 PM
今週のAIの風景:進歩、倫理的考慮、規制の議論の旋風。 Openai、Google、Meta、Microsoftのような主要なプレーヤーは、画期的な新しいモデルからLEの重要な変化まで、アップデートの急流を解き放ちました
 従業員へのAI戦略の販売:Shopify CEOのマニフェスト
Apr 10, 2025 am 11:19 AM
従業員へのAI戦略の販売:Shopify CEOのマニフェスト
Apr 10, 2025 am 11:19 AM
Shopify CEOのTobiLütkeの最近のメモは、AIの能力がすべての従業員にとって基本的な期待であると大胆に宣言し、会社内の重大な文化的変化を示しています。 これはつかの間の傾向ではありません。これは、pに統合された新しい運用パラダイムです
 最高のAI音声ジェネレーターの選択:レビューされたトップオプション
Apr 02, 2025 pm 06:12 PM
最高のAI音声ジェネレーターの選択:レビューされたトップオプション
Apr 02, 2025 pm 06:12 PM
この記事では、Google Cloud、Amazon Polly、Microsoft Azure、IBM Watson、DecriptなどのトップAI音声ジェネレーターをレビューし、機能、音声品質、さまざまなニーズへの適合性に焦点を当てています。
