

このブログでは、Llama 3.3の機能、特に推論、指示、コーディング、多言語サポートの強みを紹介する多言語コード説明アプリを構築します。
このアプリは、ユーザーが
を許可しますプログラミング言語でコードスニペットを入力します
retramit。
hugging顔のllama 3.3へのアクセス
hugging hugging faceアカウント。
正しい権限を備えたAPIトークン。
バックエンドを書きます
最初に、リクエストライブラリをインポートする必要があります。このライブラリを使用すると、HTTPリクエストをAPIに送信できます。 app.pyファイルの上部で、書き込み:
APIアクセスを設定します
mkdir multilingual-code-explanation cd multilingual-code-explanation
APIエンドポイント(モデルがホストされている場合)。
python3 -m venv venv source venv/bin/activate’
ヘッダー辞書にはAPIキーが含まれているため、顔を抱き締めることは、エンドポイントを使用することが許可されていることを知っています。
応答を処理し、生成された説明を抽出します
pip install streamlit requests transformers huggingface-hub
フロントエンドは、ユーザーがアプリと対話する場所です。 Streamlitは、Pythonコードのみを備えたインタラクティブなWebアプリを作成し、このプロセスをシンプルで直感的にするライブラリです。これは、アプリのフロントエンドを構築するために使用するものです。私はDemosとPOCを構築するためにRiremlitが本当に好きです!
ImpontRietLiT
app.pyファイルの上部で、add:
mkdir multilingual-code-explanation cd multilingual-code-explanation
python3 -m venv venv source venv/bin/activate’
St.SideBar.Title():SideBarのタイトルを作成します
St.SideBar.MarkDown():簡単な指示でテキストを追加しますpip install streamlit requests transformers huggingface-hub
text_area():貼り付けコード用の大きなボックスを作成します
text_input():ユーザーが言語を入力できるようにします。import requests
HUGGINGFACE_API_KEY = "hf_your_api_key_here" # Replace with your actual API key
API_URL = "https://api-inference.huggingface.co/models/meta-llama/Llama-3.3-70B-Instruct"
HEADERS = {"Authorization": f"Bearer {HUGGINGFACE_API_KEY}"}入力が欠落している場合の生成された説明または警告を示します。
def query_llama3(input_text, language):
# Create the prompt
prompt = (
f"Provide a simple explanation of this code in {language}:\n\n{input_text}\n"
f"Only output the explanation and nothing else. Make sure that the output is written in {language} and only in {language}"
)
# Payload for the API
payload = {
"inputs": prompt,
"parameters": {"max_new_tokens": 500, "temperature": 0.3},
}
# Make the API request
response = requests.post(API_URL, headers=HEADERS, json=payload)
if response.status_code == 200:
result = response.json()
# Extract the response text
full_response = result[0]["generated_text"] if isinstance(result, list) else result.get("generated_text", "")
# Clean up: Remove the prompt itself from the response
clean_response = full_response.replace(prompt, "").strip()
# Further clean any leading colons or formatting
if ":" in clean_response:
clean_response = clean_response.split(":", 1)[-1].strip()
return clean_response or "No explanation available."
else:
return f"Error: {response.status_code} - {response.text}"まとめるには、フッターを追加しましょう:
llama 3.3のテスト
import streamlit as st
の要因関数
最初のテストでは、再帰を使用して数値の要因を計算するPythonスクリプトから始めましょう。使用するコードは次のとおりですst.set_page_config(page_title="Multilingual Code Explanation Assistant", layout="wide")
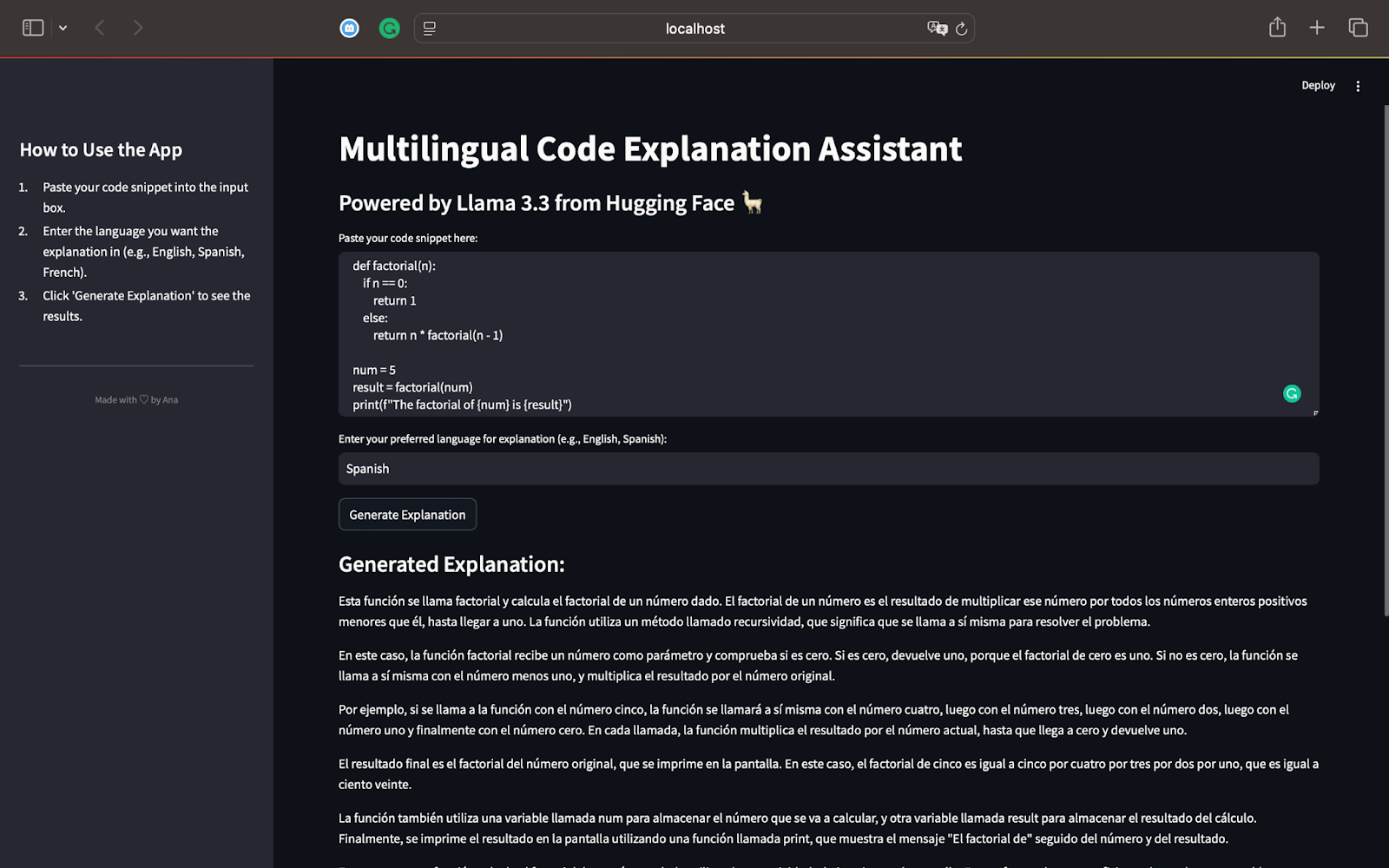

スペイン語話者として、説明がコードが再帰を使用して数値の要因を計算することを正しく識別していることを確認できます。再帰がどのように段階的に機能するかを説明し、簡単な用語に分解します。
モデルは再帰プロセスを説明し、0に達するまでnの値を減少させて関数がどのように呼び出すかを示します。説明は、要求されているように完全にスペイン語で、Llama 3.3の多言語機能を示しています。
単純なフレーズを使用すると、プログラミングに不慣れな読者にとっても、再帰の概念が簡単に従うことができます。3などの他の入力や、プログラミングにおける効率的な問題解決概念としての再帰の重要性に対して再帰がどのように機能するかをまとめて言及しています。
この最初のテストでは、llama 3.3:の力を強調しています
段階的な方法でコードを正確に説明します。
説明は要求された言語に適応します(この場合はスペイン語)。
指示に従って、結果は詳細で明確で、初心者に優しいです。
これを翻訳した後、私は説明が関数x(a)が再帰的であることを正しく識別していると結論付けました。再帰の仕組みを分解し、基本ケース(a === 1)と再帰ケース(a * x(a -1))を説明します。説明は、関数が6の因子を計算する方法を明示的に示し、y(入力値)とz(結果)の役割に言及しています。また、結果を表示するためにconsole.logを使用する方法も注目しています。
要求されているように、説明は完全にフランス語です。 「履歴書」(再帰)、「ファクターエル」(要因)、「プロダイ」(製品)などの技術用語が正しく使用されます。そして、それだけでなく、このコードが再帰的な方法で数値の要因を計算することを識別します。
この説明は、過度に技術的な専門用語を避け、再帰を簡素化し、プログラミングに新しい読者がアクセスできるようにします。このテストは、llama 3.3:
であることを示しています再帰を含むJavaScriptコードを正確に説明します
説明ボタンを押した後、これが私たちが得るものです:
生成された説明は簡潔で正確で、十分に構造化されています。各キーSQL句(Select、From、Join、Where、Group、Have、and Order)を明確に説明します。また、この説明はSQLの実行順序と一致します。これは、読者がクエリロジックを段階的にフォローするのに役立ちます。
mkdir multilingual-code-explanation cd multilingual-code-explanation
キーSQL用語(例: "filtert"、 "gruppiert"、 "sortiert")は、コンテキストで正確に使用されます。この説明は、グループ化された結果をフィルタリングするために使用されていることを特定しています。これは初心者にとって一般的な混乱の原因です。また、明確にするためにテーブルと列の名前を変更するためのエイリアスの使用(AS)も説明しています。
説明は、過度に複雑な用語を回避し、各句の機能に焦点を当てています。これにより、初心者がクエリの仕組みを簡単に理解できるようになります。
このテストは、llama 3.3:であることを示しています
モデルは、強力な推論スキルと多言語サポートを実証しました
このテストでは、私たちが構築したアプリが多用途で信頼性が高く、さまざまなプログラミング言語や自然言語にわたってコードを説明するのに効果的であることを確認しました。llama 3.3 APIを使用してコードスニペットを説明する方法。
API応答をクリーンアップしてユーザーフレンドリーなアプリを作成する方法このプロジェクトは、コード推論、多言語サポート、および指導コンテンツのLlama 3.3の機能を調査するための素晴らしい出発点です。このモデルの強力な機能を調査し続けるために、独自のアプリを自由に作成してください!
以上がLlama 3.3:デモプロジェクトのステップバイステップチュートリアルの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



