

Deepseekの画期的なオープンソースリリース:Flashmla、Cuda Kernel Accelerating LLMS。 この最適化された多輝度注意(MLA)デコードカーネルは、ホッパーGPU用に特別に設計されており、AIモデルホスティングの速度と効率を大幅に向上させます。 主な改善には、BF16サポートとページKVキャッシュ(64ブロックサイズ)が含まれ、印象的なパフォーマンスベンチマークが生まれます。
? #opensourceweekの1日目:flashmlaDeepseekは、Hopper GPUの高効率MLAデコードカーネルであるFlashmlaを誇らしげに発表します。可変長シーケンス用に最適化され、現在は生産されています。
✅BF16サポート
paged kvキャッシュ(ブロックサイズ64)
- deepseek(@deepseek_ai)2025年2月24日
ページ ⚡3000 gb/sメモリバウンド&580 tflops…
主要な機能:
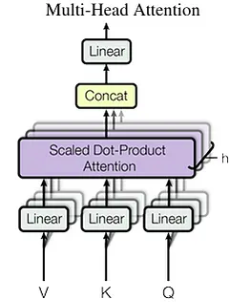
flashmlaとは?とは何ですか
マルチヘッドの潜在的注意(MLA)ハードウェアとソフトウェアの要件:
ホッパーアーキテクチャgpus(例:H800 SXM5)
cuda 12.3
pytorch 2.0メモリ帯域幅:
最大3000 GB/s(H800 SXM5理論ピークに近づいています)。 計算スループット:MLAは、低ランク式因数分解投影マトリックスを使用して、標準的なマルチヘッド注意(MHA)のメモリ制限に対処します。グループクエリの注意のような方法とは異なり、MLAはメモリオーバーヘッドを減らしながらパフォーマンスを向上させます。
標準的なマルチヘッド注意制限:
MHAのKVキャッシュは、シーケンスの長さで直線的にスケーリングし、長いシーケンスのメモリボトルネックを作成します。 キャッシュサイズは次のように計算されます。seq_len * n_h * d_hmlaのメモリ最適化:n_h d_h
MLAは、キーと値をより小さな潜在ベクトル(
)に圧縮し、kVキャッシュサイズを(ここで潜在的なベクトル寸法)に減らします。 これにより、メモリの使用量が大幅に削減されます(DeepSeek-V2の最大93.3%の減少)。
c_t
seq_len * d_cKVキャッシュは、以前に計算されたキー価値ペアを再利用することにより、自己回帰解読を加速します。 ただし、これによりメモリの使用量が増加します。d_c
メモリの課題への対処: マルチクエリの注意(MQA)やグループ化されたクエリの注意(GQA)などのテクニックは、KVキャッシングに関連するメモリの問題を軽減します。
deepseekモデルにおけるflashmlaの役割:
Flashmlaは、DeepseekのR1およびV3モデルをパワーし、効率的な大規模AIアプリケーションを可能にします。
nvidiaホッパーアーキテクチャNvidia Hopperは、AIおよびHPCワークロード向けに設計された高性能GPUアーキテクチャです。 トランスエンジンや第2世代MIGなどのその革新により、例外的な速度とスケーラビリティが可能になります。 パフォーマンスの分析と意味
Flashmlaは、BF16マトリックス増殖のために580 TFLOPSを達成し、H800 GPUの理論的ピークの2倍以上になります。 これは、GPUリソースの非常に効率的な利用率を示しています
結論
Flashmlaは、特にホッパーGPUのAI推論効率の大きな進歩を表しています。 そのMLAの最適化は、BF16サポートとページングKVキャッシングと組み合わされて、驚くべきパフォーマンスの改善を実現します。 これにより、大規模なAIモデルがよりアクセスしやすく、費用対効果が高くなり、モデル効率のための新しいベンチマークを設定します。
以上がDeepseekはFlashmlaを起動しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



