

コンテンツ用の頂点ai&geminiを使用したマルチモーダルラグのマスター

マルチモーダル検索拡張生成(RAG)は、言語モデル(LLM)アクセスと外部データにどのようにアクセスし、利用し、従来のテキストのみの制限を超えて移動するかに革命をもたらしました。 マルチモーダルデータの有病率の増加には、特に金融や科学研究などの複雑なドメインにおいて、包括的な分析のためにテキストと視覚情報を統合する必要があります。 Multimodal RAGは、LLMがテキストと画像の両方を処理できるようにすることでこれを達成し、知識の検索とより微妙な推論を改善します。この記事では、GoogleのGeminiモデル、Vertex AI、およびLangchainを使用してマルチモーダルRAGシステムの構築を詳しく説明します。各ステップをご覧ください:環境セットアップ、データの前処理、生成の埋め込み、堅牢なドキュメント検索エンジンの作成。
重要な学習目標- マルチモーダルラグの概念と、データ検索機能の強化におけるその重要性を把握してください。
- ジェミニがテキストデータと視覚データをどのように処理および統合するかを理解してください。 リアルタイムアプリケーションに適したスケーラブルなAIモデルを構築するための頂点AIの機能を活用することを学ぶ。 LLMを外部データソースとシームレスに統合する際のLangchainの役割を探索します。
- テキスト情報と視覚情報の両方を使用して、正確でコンテキスト対応の応答を利用する効果的なフレームワークを開発します。 これらの手法を、コンテンツ生成、パーソナライズされた推奨事項、AIアシスタントなどの実際のユースケースに適用します。
- この記事は、データサイエンスブログの一部です
- 目次
マルチモーダルrag:包括的な概要 採用されたコアテクノロジー システムアーキテクチャは説明しました
頂点AI、Gemini、およびLangchainを使用したマルチモーダルRAGシステムの構築ステップ1:環境構成
ステップ2:Google Cloudプロジェクトの詳細- ステップ3:Vertex AI SDK初期化
- ステップ4:必要なライブラリのインポート
- ステップ5:モデル仕様
- ステップ6:データ摂取
- ステップ7:頂点AIベクトル検索インデックスとエンドポイントの作成と展開
- ステップ8:Retriverの作成とドキュメントの読み込み
- ステップ9:レトリバーとジェミニLLM を備えたチェーン構造
- ステップ10:モデルテスト
- 実際のアプリケーション
- 結論
- よくある質問
- マルチモーダルrag:包括的な概要
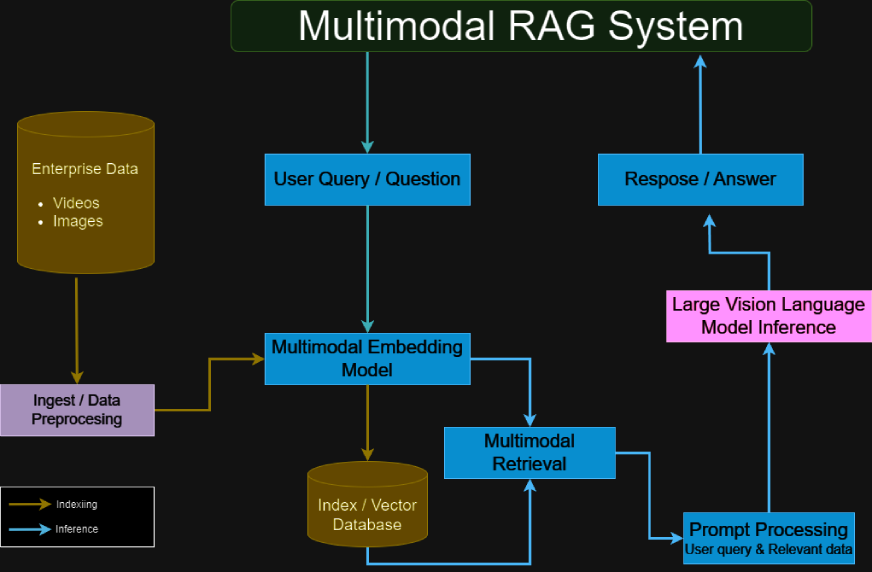
マルチモーダルRAGシステムを視覚情報とテキスト情報を組み合わせて、より豊かでコンテキストに関連する出力を提供します。従来のテキストベースのLLMとは異なり、マルチモーダルRAGシステムは、チャート、グラフ、画像などの視覚コンテンツを摂取および処理するように設計されています。このデュアル処理機能は、財務報告、科学出版物、技術マニュアルなど、視覚要素がテキストと同じくらい有益である複雑なデータセットを分析するのに特に有益です。
テキストと画像の両方を処理することにより、モデルはデータをより深く理解し、より正確で洞察に満ちた応答をもたらします。この統合は、誤解を招くまたは事実上誤った情報(機械学習の一般的な問題)を生成するリスクを軽減し、意思決定と分析のためのより信頼性の高い出力につながります。
採用されたコアテクノロジー このセクションでは、使用される主要なテクノロジーを要約しています:
- Google Deepmind's Gemini:
- マルチモーダルタスク向けに設計された強力な生成AIスイート。テキストと画像の両方をシームレスに処理して生成できます。
Vertex AI:
効率的なマルチモーダルデータ取得のための堅牢なベクトル検索機能を備えた機械学習モデルを開発、展開、およびスケーリングするための包括的なプラットフォーム。 - langchain:LLMのさまざまなツールやデータソースとの統合を簡素化し、モデル、埋め込み、および外部リソース間の接続を促進するフレームワーク。 検索された生成(RAG)フレームワーク:
- 検索ベースのモデルと生成ベースのモデルを組み合わせて、出力を生成する前に外部ソースから関連するコンテキストを取得することにより、応答の精度を向上させるフレームワーク、マルチモーダルコンテンツの処理に最適です。 OpenaiのDall・e: (オプション)テキストプロンプトを視覚的なコンテンツに変換する画像生成モデルで、コンテキストに関連する画像でマルチモーダルラグ出力を強化します。 マルチモーダル処理のための
- 変圧器:混合入力タイプを処理するための基礎となるアーキテクチャ、テキストと視覚データの両方を含む効率的な処理と応答生成を可能にします。
- システムアーキテクチャが説明しました マルチモーダルRAGシステムは通常、 で構成されています
-
マルチモーダル処理用の
- gemini:テキストと画像入力の両方を処理し、各モダリティから詳細情報を抽出します。
- vertex aiベクトル検索:効率的な埋め込み管理とデータ取得のためのベクトルデータベースを提供します。 langchain multivectorretriever:
- 仲介者として機能し、ユーザークエリに基づいてベクターデータベースから関連データを取得します。 RAGフレームワークの統合: 取得したデータとLLMの生成機能を組み合わせて、正確でコンテキストが豊富な応答を作成します。
- マルチモーダルエンコーダーデコーダー:プロセスと融合のテキストコンテンツと視覚コンテンツを使用して、両方のデータ型が出力に効果的に貢献するようにします。 ハイブリッドデータ処理用の
- 変圧器:注意メカニズムを利用して、さまざまなモダリティから情報を調整および統合します。 微調整パイプライン:
- (オプション)特定のマルチモーダルデータセットに基づいてモデルパフォーマンスを最適化するカスタマイズされたトレーニング手順を改善して、精度とコンテキスト理解を向上させます。
- (残りのセクション、ステップ1〜10、実用的なアプリケーション、結論、およびFAQは、逐語的な繰り返しを避けながら、元の意味を維持するために、リパーシングと再構築の同様のパターンに従います。画像は元の形式と位置にとどまります。
以上がコンテンツ用の頂点ai&geminiを使用したマルチモーダルラグのマスターの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7909
7909
 15
1652
14
1411
52
1303
25
1248
29
15
1652
14
1411
52
1303
25
1248
29

 クリエイティブプロジェクトのための最高のAIアートジェネレーター(無料&有料)
Apr 02, 2025 pm 06:10 PM
クリエイティブプロジェクトのための最高のAIアートジェネレーター(無料&有料)
Apr 02, 2025 pm 06:10 PM
この記事では、トップAIアートジェネレーターをレビューし、その機能、創造的なプロジェクトへの適合性、価値について説明します。 Midjourneyを専門家にとって最高の価値として強調し、高品質でカスタマイズ可能なアートにDall-E 2を推奨しています。
 Meta Llama 3.2を始めましょう - 分析Vidhya
Apr 11, 2025 pm 12:04 PM
Meta Llama 3.2を始めましょう - 分析Vidhya
Apr 11, 2025 pm 12:04 PM
メタのラマ3.2:マルチモーダルとモバイルAIの前進 メタは最近、ラマ3.2を発表しました。これは、モバイルデバイス向けに最適化された強力なビジョン機能と軽量テキストモデルを特徴とするAIの大幅な進歩です。 成功に基づいてo
 ベストAIチャットボットが比較されました(chatgpt、gemini、claude& more)
Apr 02, 2025 pm 06:09 PM
ベストAIチャットボットが比較されました(chatgpt、gemini、claude& more)
Apr 02, 2025 pm 06:09 PM
この記事では、ChatGpt、Gemini、ClaudeなどのトップAIチャットボットを比較し、自然言語の処理と信頼性における独自の機能、カスタマイズオプション、パフォーマンスに焦点を当てています。
 10生成AIコーディング拡張機能とコードのコードを探る必要があります
Apr 13, 2025 am 01:14 AM
10生成AIコーディング拡張機能とコードのコードを探る必要があります
Apr 13, 2025 am 01:14 AM
ねえ、忍者をコーディング!その日はどのようなコーディング関連のタスクを計画していますか?このブログにさらに飛び込む前に、コーディング関連のすべての問題について考えてほしいです。 終わり? - &#8217を見てみましょう
 トップAIライティングアシスタントは、コンテンツの作成を後押しします
Apr 02, 2025 pm 06:11 PM
トップAIライティングアシスタントは、コンテンツの作成を後押しします
Apr 02, 2025 pm 06:11 PM
この記事では、Grammarly、Jasper、Copy.ai、Writesonic、RytrなどのトップAIライティングアシスタントについて説明し、コンテンツ作成のためのユニークな機能に焦点を当てています。 JasperがSEOの最適化に優れているのに対し、AIツールはトーンの維持に役立つと主張します
 AVバイト:Meta' s llama 3.2、GoogleのGemini 1.5など
Apr 11, 2025 pm 12:01 PM
AVバイト:Meta' s llama 3.2、GoogleのGemini 1.5など
Apr 11, 2025 pm 12:01 PM
今週のAIの風景:進歩、倫理的考慮、規制の議論の旋風。 Openai、Google、Meta、Microsoftのような主要なプレーヤーは、画期的な新しいモデルからLEの重要な変化まで、アップデートの急流を解き放ちました
 従業員へのAI戦略の販売:Shopify CEOのマニフェスト
Apr 10, 2025 am 11:19 AM
従業員へのAI戦略の販売:Shopify CEOのマニフェスト
Apr 10, 2025 am 11:19 AM
Shopify CEOのTobiLütkeの最近のメモは、AIの能力がすべての従業員にとって基本的な期待であると大胆に宣言し、会社内の重大な文化的変化を示しています。 これはつかの間の傾向ではありません。これは、pに統合された新しい運用パラダイムです
 最高のAI音声ジェネレーターの選択:レビューされたトップオプション
Apr 02, 2025 pm 06:12 PM
最高のAI音声ジェネレーターの選択:レビューされたトップオプション
Apr 02, 2025 pm 06:12 PM
この記事では、Google Cloud、Amazon Polly、Microsoft Azure、IBM Watson、DecriptなどのトップAI音声ジェネレーターをレビューし、機能、音声品質、さまざまなニーズへの適合性に焦点を当てています。
